Assistente do Apache Spark no Azure Synapse Analytics (Pré-visualização)
O assistente do Apache Spark analisa comandos e código executados pelo Spark e apresenta conselhos em tempo real para execuções do Bloco de Notas. O assistente do Spark tem padrões incorporados para ajudar os utilizadores a evitar erros comuns, oferecer recomendações para otimização de código, realizar análise de erros e localizar a causa principal das falhas.
Conselhos incorporados
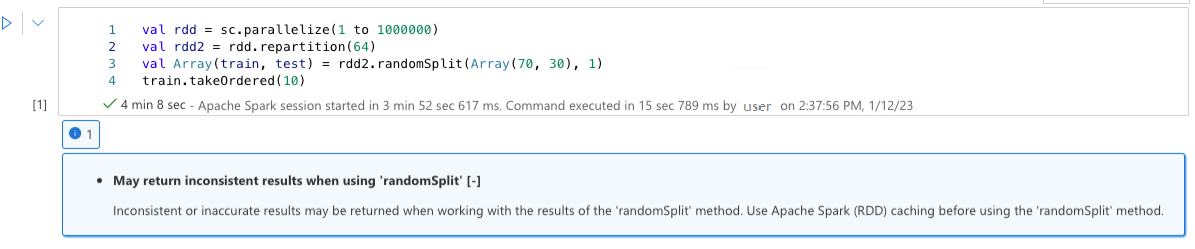
Pode devolver resultados inconsistentes ao utilizar "randomSplit"
Podem ser devolvidos resultados inconsistentes ou imprecisos ao trabalhar com os resultados do método "randomSplit". Utilize a colocação em cache do Apache Spark (RDD) antes de utilizar o método "randomSplit".
O método randomSplit() é equivalente à execução de exemplo() no seu pacote de dados várias vezes, com cada amostra a refetching, a criação de partições e a ordenação da moldura de dados dentro de partições. A distribuição de dados entre partições e sequência de ordenação é importante para randomSplit() e sample(). Se as alterações aos dados forem recortados, poderão existir duplicados ou valores em falta entre divisões e a mesma amostra que utiliza a mesma semente poderá produzir resultados diferentes.
Estas inconsistências podem não ocorrer em todas as execuções, mas para eliminá-las completamente, colocar em cache o seu fotograma de dados, dividir novamente numa(s) coluna(s) ou aplicar funções agregadas, como groupBy.
O nome da tabela/vista já está a ser utilizado
Já existe uma vista com o mesmo nome que a tabela criada ou já existe uma tabela com o mesmo nome que a vista criada. Quando este nome é utilizado em consultas ou aplicações, apenas a vista será devolvida independentemente da vista criada primeiro. Para evitar conflitos, mude o nome da tabela ou da vista.
Não é possível reconhecer uma sugestão
A consulta selecionada contém uma sugestão que não é reconhecida. Verifique se a sugestão está escrita corretamente.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Não é possível localizar um(s) nome(s) de relação especificado(s)
Não é possível localizar as relações especificadas na sugestão. Verifique se as relações estão escritas corretamente e acessíveis no âmbito da sugestão.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Uma sugestão na consulta impede que outra sugestão seja aplicada
A consulta selecionada contém uma sugestão que impede a aplicação de outra sugestão.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Ative "spark.advise.divisionExprConvertRule.enable" para reduzir a propagação de erros de arredondamento
Esta consulta contém a expressão com Tipo duplo. Recomendamos que ative a configuração "spark.advise.divisionExprConvertRule.enable", que pode ajudar a reduzir as expressões de divisão e a reduzir a propagação de erros de arredondamento.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Ative "spark.advise.nonEqJoinConvertRule.enable" para melhorar o desempenho das consultas
Esta consulta contém uma associação demorada devido à condição "Ou" na consulta. Recomendamos que ative a configuração "spark.advise.nonEqJoinConvertRule.enable", que pode ajudar a converter a associação acionada pela condição "Ou" em SMJ ou BHJ para acelerar esta consulta.
Otimizar a tabela delta com compactação de ficheiros pequenos
Esta consulta encontra-se numa tabela delta com muitos ficheiros pequenos. Para melhorar o desempenho das consultas, execute o comando OTIMIZAR na tabela delta. Pode encontrar mais detalhes neste artigo.
Otimizar a tabela Delta com zOrder
Esta consulta encontra-se numa tabela Delta e contém um filtro altamente seletivo. Para melhorar o desempenho das consultas, execute o comando OPTIMIZE ZORDER BY na tabela delta. Pode encontrar mais detalhes neste artigo.
Experiência do Utilizador
O assistente do Apache Spark apresenta os conselhos, incluindo informações, avisos e erros, na saída da célula do Bloco de Notas em tempo real.
Informações
Aviso

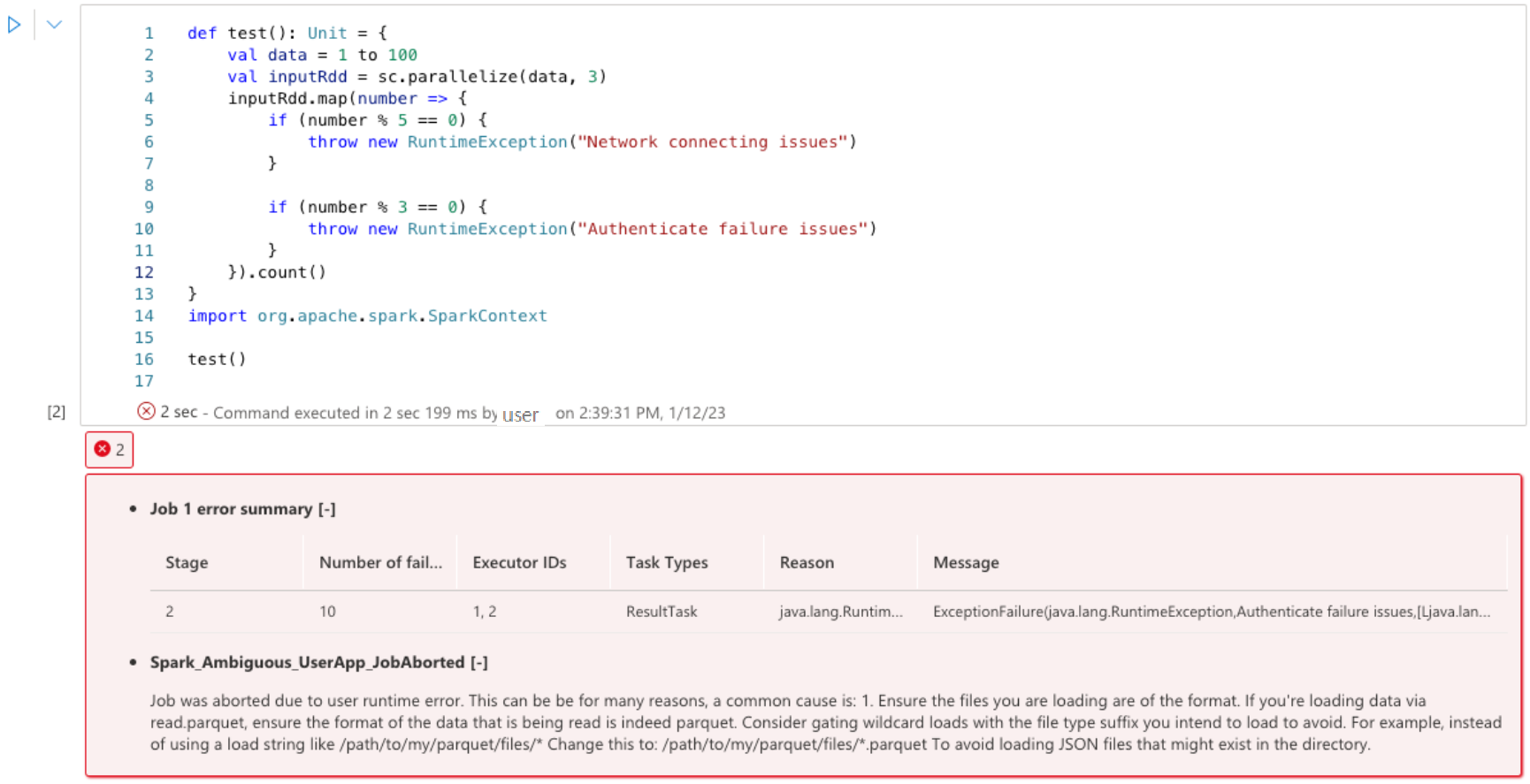
Erros
Passos seguintes
Para obter mais informações sobre como monitorizar aplicações do Apache Spark, veja o artigo Monitorizar aplicações do Apache Spark com Synapse Studio.
Para obter mais informações sobre como criar um bloco de notas, veja Como utilizar blocos de notas do Synapse