Tutorial: Treinar um modelo em Python com aprendizado de máquina automatizado (preterido)
O Azure Machine Learning é um ambiente baseado na nuvem que lhe permite treinar, implementar, automatizar, gerir e acompanhar modelos de aprendizagem automática.
Neste tutorial, você usa o aprendizado de máquina automatizado no Aprendizado de Máquina do Azure para criar um modelo de regressão para prever os preços das tarifas de táxi. Esse processo chega ao melhor modelo aceitando dados de treinamento e definições de configuração e iterando automaticamente através de combinações de diferentes métodos, modelos e configurações de hiperparâmetros.
Neste tutorial, irá aprender a:
- Baixe os dados usando o Apache Spark e o Azure Open Datasets.
- Transforme e limpe dados usando o Apache Spark DataFrames.
- Treine um modelo de regressão em aprendizado de máquina automatizado.
- Calcule a precisão do modelo.
Antes de começar
- Crie um pool do Apache Spark 2.4 sem servidor seguindo o início rápido Criar um pool do Apache Spark sem servidor.
- Conclua o tutorial de configuração do espaço de trabalho do Azure Machine Learning se não tiver um espaço de trabalho existente do Azure Machine Learning.
Aviso
- A partir de 29 de setembro de 2023, o Azure Synapse descontinuará o suporte oficial para o Spark 2.4 Runtimes. Após 29 de setembro de 2023, não abordaremos nenhum tíquete de suporte relacionado ao Spark 2.4. Não haverá pipeline de lançamento para bugs ou correções de segurança para o Spark 2.4. A utilização do Spark 2.4 após a data de corte do suporte é realizada por sua conta e risco. Desencorajamos fortemente o seu uso continuado devido a potenciais preocupações de segurança e funcionalidade.
- Como parte do processo de substituição do Apache Spark 2.4, gostaríamos de notificá-lo de que o AutoML no Azure Synapse Analytics também será preterido. Isso inclui a interface low code e as APIs usadas para criar avaliações do AutoML por meio do código.
- Observe que a funcionalidade AutoML estava disponível exclusivamente através do tempo de execução do Spark 2.4.
- Para os clientes que desejam continuar aproveitando os recursos do AutoML, recomendamos salvar seus dados em sua conta do Azure Data Lake Storage Gen2 (ADLSg2). A partir daí, você pode acessar diretamente a experiência do AutoML por meio do Azure Machine Learning (AzureML). Mais informações sobre essa solução alternativa estão disponíveis aqui.
Compreender os modelos de regressão
Os modelos de regressão predizem valores numéricos de saída com base em preditores independentes. Na regressão, o objetivo é ajudar a estabelecer a relação entre essas variáveis preditoras independentes, estimando como uma variável afeta as outras.
Exemplo baseado em dados de táxi da cidade de Nova York
Neste exemplo, você usa o Spark para executar algumas análises em dados de dicas de viagem de táxi da cidade de Nova York (NYC). Os dados estão disponíveis através dos Conjuntos de Dados Abertos do Azure. Este subconjunto do conjunto de dados contém informações sobre viagens de táxi amarelo, incluindo informações sobre cada viagem, a hora e os locais de início e fim e o custo.
Importante
Pode haver cobranças adicionais para extrair esses dados de seu local de armazenamento. Nas etapas a seguir, você desenvolve um modelo para prever os preços das tarifas de táxi de Nova York.
Faça o download e prepare os dados
Saiba como:
Crie um bloco de anotações usando o kernel do PySpark. Para obter instruções, consulte Criar um bloco de anotações.
Nota
Devido ao kernel do PySpark, você não precisa criar nenhum contexto explicitamente. O contexto do Spark é criado automaticamente para você quando você executa a primeira célula de código.
Como os dados brutos estão em um formato Parquet, você pode usar o contexto do Spark para extrair o arquivo diretamente para a memória como um DataFrame. Crie um Spark DataFrame recuperando os dados por meio da API Open Datasets. Aqui, você usa as propriedades do Spark DataFrame
schema on readpara inferir os tipos de dados e o esquema.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)Dependendo do tamanho do pool do Spark, os dados brutos podem ser muito grandes ou levar muito tempo para operar. Você pode filtrar esses dados para algo menor, como um mês de dados, usando os
start_datefiltros eend_date. Depois de filtrar um DataFrame, você também executa a função no novo DataFrame para ver estatísticasdescribe()de resumo para cada campo.Com base nas estatísticas resumidas, é possível constatar que existem algumas irregularidades nos dados. Por exemplo, as estatísticas mostram que a distância mínima da viagem é inferior a 0. Você precisa filtrar esses pontos de dados irregulares.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()Gere recursos a partir do conjunto de dados selecionando um conjunto de colunas e criando vários recursos baseados no tempo a partir do campo de recebimento
datetime. Filtre os valores atípicos que foram identificados na etapa anterior e, em seguida, remova as últimas colunas porque elas são desnecessárias para treinamento.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)Como você pode ver, isso criará um novo DataFrame com colunas adicionais para o dia do mês, hora de coleta, dia da semana e tempo total de viagem.

Gerar conjuntos de dados de teste e validação
Depois de ter seu conjunto de dados final, você pode dividir os dados em conjuntos de treinamento e teste usando a random_ split função no Spark. Usando os pesos fornecidos, essa função divide aleatoriamente os dados no conjunto de dados de treinamento para treinamento de modelo e no conjunto de dados de validação para teste.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
Esta etapa garante que os pontos de dados para testar o modelo concluído não tenham sido usados para treinar o modelo.
Conectar-se a um espaço de trabalho do Azure Machine Learning
No Azure Machine Learning, um espaço de trabalho é uma classe que aceita sua assinatura do Azure e informações de recursos. Ele também cria um recurso de nuvem para monitorar e acompanhar as execuções do seu modelo. Nesta etapa, você cria um objeto de espaço de trabalho a partir do espaço de trabalho existente do Azure Machine Learning.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
Converter um DataFrame em um conjunto de dados do Azure Machine Learning
Para enviar um experimento remoto, converta seu conjunto de dados em uma instância do Azure Machine Learning TabularDatset . TabularDataset representa dados em um formato tabular analisando os arquivos fornecidos.
O código a seguir obtém o espaço de trabalho existente e o armazenamento de dados padrão do Azure Machine Learning. Em seguida, ele passa o armazenamento de dados e os locais de arquivo para o parâmetro path para criar uma nova TabularDataset instância.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

Enviar um experimento automatizado
As seções a seguir orientam você pelo processo de envio de um experimento automatizado de aprendizado de máquina.
Definir configurações de treinamento
Para enviar um experimento, você precisa definir o parâmetro do experimento e as configurações do modelo para treinamento. Para obter a lista completa de configurações, consulte Configurar experimentos automatizados de aprendizado de máquina em Python.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}Passe as configurações de treinamento definidas como um
kwargsparâmetro para umAutoMLConfigobjeto. Como você está usando o Spark, também deve passar o contexto do Spark, que é automaticamente acessível pelascvariável. Além disso, você especifica os dados de treinamento e o tipo de modelo, que é regressão neste caso.from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
Nota
As etapas automatizadas de pré-processamento do aprendizado de máquina tornam-se parte do modelo subjacente. Essas etapas incluem normalização de recursos, manipulação de dados ausentes e conversão de texto em numérico. Quando você está usando o modelo para previsões, as mesmas etapas de pré-processamento aplicadas durante o treinamento são aplicadas aos seus dados de entrada automaticamente.
Treinar o modelo de regressão automática
Em seguida, você cria um objeto de experimento em seu espaço de trabalho do Azure Machine Learning. Um experimento atua como um contêiner para suas execuções individuais.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
Quando o experimento terminar, a saída retornará detalhes sobre as iterações concluídas. Para cada iteração, você vê o tipo de modelo, a duração da execução e a precisão do treinamento. O BEST campo rastreia a melhor pontuação de treinamento com base no seu tipo de métrica.

Nota
Depois de enviar o experimento de aprendizado de máquina automatizado, ele executa várias iterações e tipos de modelo. Essa execução normalmente leva de 60 a 90 minutos.
Obter o melhor modelo
Para selecionar o melhor modelo de suas iterações, use a get_output função para retornar o melhor modelo executado e ajustado. O código a seguir recupera o melhor modelo de execução e ajuste para qualquer métrica registrada ou uma iteração específica.
# Get best model
best_run, fitted_model = local_run.get_output()
Precisão do modelo de teste
Para testar a precisão do modelo, use o melhor modelo para executar previsões de tarifa de táxi no conjunto de dados de teste. A
predictfunção usa o melhor modelo e prevê os valores de (valor da tarifa) a partir do conjunto de dados deyvalidação.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)O erro raiz-médio-quadrado é uma medida frequentemente utilizada das diferenças entre os valores amostrais previstos por um modelo e os valores observados. Você calcula o erro raiz-média-quadrada dos resultados comparando o
y_testDataFrame com os valores previstos pelo modelo.A função
mean_squared_errorusa duas matrizes e calcula o erro quadrado médio entre elas. Em seguida, você pega a raiz quadrada do resultado. Esta métrica indica aproximadamente a distância entre as previsões da tarifa de táxi e os valores reais da tarifa.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151O erro raiz-média-quadrada é uma boa medida de quão precisamente o modelo prevê a resposta. A partir dos resultados, você vê que o modelo é bastante bom em prever tarifas de táxi a partir dos recursos do conjunto de dados, normalmente dentro de US $ 2,00.
Execute o código a seguir para calcular o erro média-absoluta-porcentagem. Essa métrica expressa a precisão como uma porcentagem do erro. Ele faz isso calculando uma diferença absoluta entre cada valor previsto e real e, em seguida, somando todas as diferenças. Em seguida, expressa essa soma como uma percentagem do total dos valores reais.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263A partir das duas métricas de precisão de previsão, você vê que o modelo é bastante bom em prever tarifas de táxi a partir dos recursos do conjunto de dados.
Depois de ajustar um modelo de regressão linear, agora você precisa determinar o quão bem o modelo se ajusta aos dados. Para fazer isso, você plota os valores reais da tarifa em relação à saída prevista. Além disso, você calcula a medida R-quadrada para entender o quão próximos os dados estão da linha de regressão ajustada.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()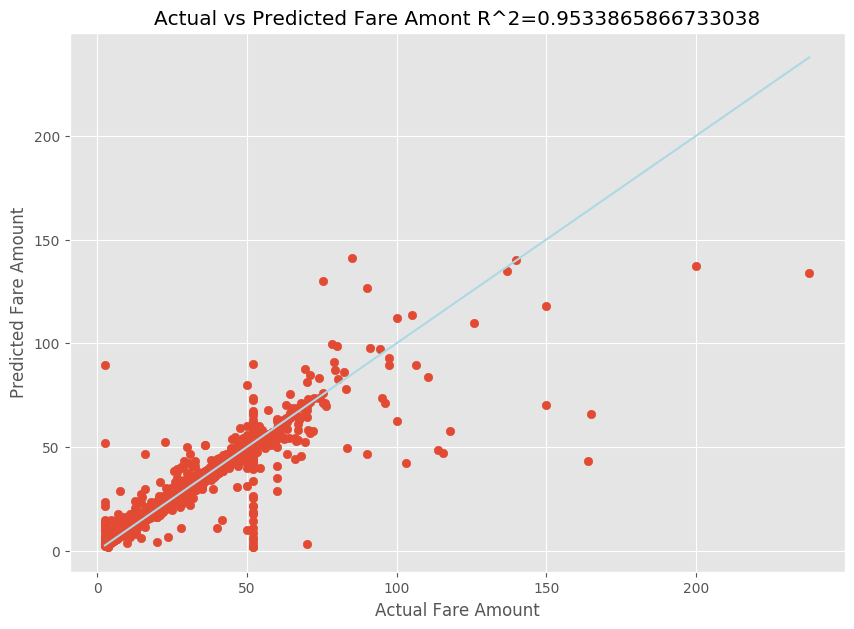
A partir dos resultados, você pode ver que a medida R-quadrado é responsável por 95% da variância. Isto também é validado pelo gráfico real versus o gráfico observado. Quanto mais variância o modelo de regressão contabilizar, mais próximos os pontos de dados cairão da linha de regressão ajustada.
Registrar o modelo no Azure Machine Learning
Depois de validar seu melhor modelo, você pode registrá-lo no Azure Machine Learning. Em seguida, você pode baixar ou implantar o modelo registrado e receber todos os arquivos que você registrou.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
Ver resultados no Azure Machine Learning
Você também pode acessar os resultados das iterações acessando o experimento em seu espaço de trabalho do Azure Machine Learning. Aqui, você pode obter detalhes adicionais sobre o status de sua corrida, modelos tentados e outras métricas de modelo.
Próximos passos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários