Cache inteligente no Azure Synapse Analytics
O Cache Inteligente funciona perfeitamente nos bastidores e armazena dados em cache para ajudar a acelerar a execução do Spark à medida que ele lê a partir do seu data lake ADLS Gen2. Ele também deteta automaticamente alterações nos arquivos subjacentes e atualizará automaticamente os arquivos no cache, fornecendo os dados mais recentes e, quando o tamanho do cache atingir seu limite, o cache liberará automaticamente os dados menos lidos para abrir espaço para os dados mais recentes. Esse recurso reduz o custo total de propriedade, melhorando o desempenho em até 65% nas leituras subsequentes dos arquivos armazenados no cache disponível para arquivos Parquet e 50% para arquivos CSV.
Ao consultar um arquivo ou tabela do seu data lake, o mecanismo Apache Spark no Synapse fará uma chamada para o armazenamento remoto ADLS Gen2 para ler os arquivos subjacentes. A cada solicitação de consulta para ler os mesmos dados, o mecanismo Spark deve fazer uma chamada para o armazenamento remoto do ADLS Gen2. Este processo redundante adiciona latência ao seu tempo total de processamento. O Spark fornece um recurso de cache que você deve definir manualmente o cache e liberá-lo para minimizar a latência e melhorar o desempenho geral. No entanto, isso pode fazer com que os resultados tenham dados obsoletos se os dados subjacentes forem alterados.
O Synapse Intelligent Cache simplifica esse processo armazenando automaticamente em cache cada leitura dentro do espaço de armazenamento de cache alocado em cada nó do Spark. Cada solicitação de um arquivo verificará se o arquivo existe no cache e comparará a tag do armazenamento remoto para determinar se o arquivo está obsoleto. Se o arquivo não existir ou se estiver obsoleto, o Spark lerá o arquivo e o armazenará no cache. Quando o cache ficar cheio, o arquivo com o último tempo de acesso mais antigo será removido do cache para permitir arquivos mais recentes.
O cache Synapse é um único cache por nó. Se você estiver usando um nó de tamanho médio e executar com dois pequenos executores em um único nó de tamanho médio, esses dois executores compartilharão o mesmo cache.
Habilitar ou desabilitar o cache
O tamanho do cache pode ser ajustado com base na porcentagem do tamanho total do disco disponível para cada pool do Apache Spark. Por padrão, o cache é definido como desativado, mas é tão fácil quanto mover a barra deslizante de 0 (desativado) para a porcentagem desejada para o tamanho do cache para habilitá-lo. Reservamos um mínimo de 20% do espaço disponível em disco para embaralhamento de dados. Para cargas de trabalho intensivas aleatórias, você pode minimizar o tamanho do cache ou desabilitar o cache. Recomendamos começar com um tamanho de cache de 50% e ajustar conforme necessário. É importante observar que, se sua carga de trabalho exigir muito espaço em disco no SSD local para armazenamento aleatório ou RDD, considere reduzir o tamanho do cache para reduzir a chance de falha devido ao armazenamento insuficiente. O tamanho real do armazenamento disponível e o tamanho do cache em cada nó dependerão da família de nós e do tamanho do nó.
Ativando o cache para novos pools do Spark
Ao criar um novo pool do Spark, navegue na guia Configurações adicionais para encontrar o controle deslizante Cache Inteligente que você pode mover para o tamanho preferido para ativar o recurso.

Ativando/desabilitando o cache para pools de faíscas existentes
Para pools Spark existentes, navegue até as configurações de Escala do pool Apache Spark de sua escolha para habilitar, movendo o controle deslizante para um valor maior que 0, ou desative-o, movendo o controle deslizante para 0.
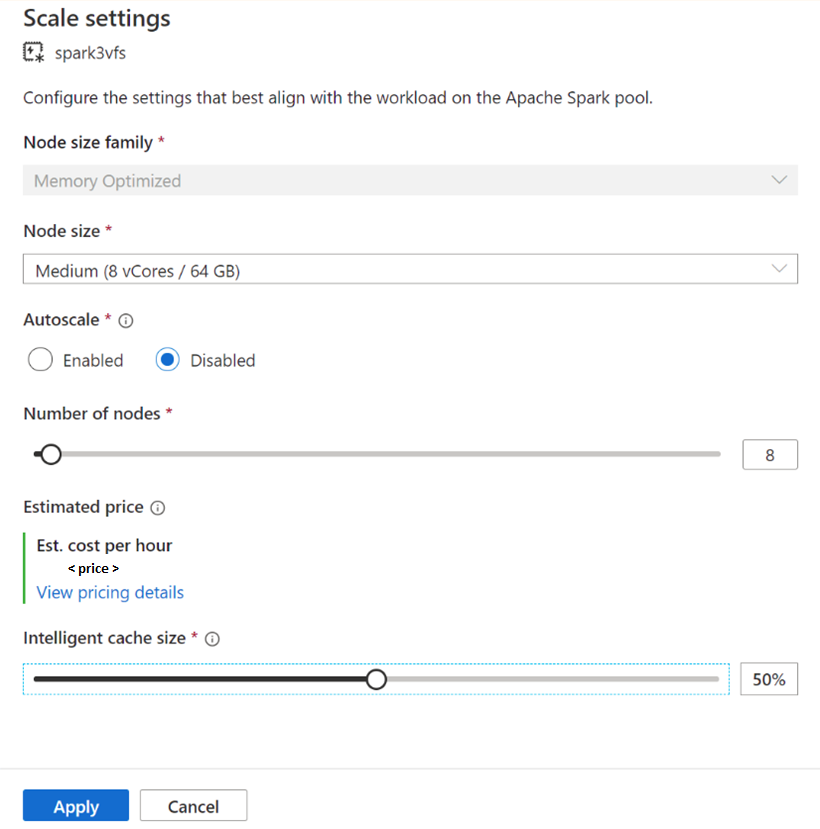
Alterando o tamanho do cache para pools Spark existentes
Para alterar o tamanho do Cache Inteligente de um pool, você deve forçar uma reinicialização se o pool tiver sessões ativas. Se o pool do Spark tiver uma sessão ativa, ele mostrará Forçar novas configurações. Clique na caixa de seleção e selecione Aplicar para reiniciar automaticamente a sessão.

Ativando e desativando o cache dentro da sessão
Desative facilmente o Cache Inteligente em uma sessão executando o seguinte código em seu bloco de anotações:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
E habilite executando:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Quando usar o Cache Inteligente e quando não?
Esta funcionalidade irá beneficiá-lo se:
Sua carga de trabalho requer a leitura do mesmo arquivo várias vezes e o tamanho do arquivo pode caber no cache.
Sua carga de trabalho usa tabelas Delta, formatos de arquivo parquet e arquivos CSV.
Você está usando o Apache Spark 3 ou superior no Azure Synapse.
Você não verá o benefício desse recurso se:
Você está lendo um arquivo que excede o tamanho do cache porque o início dos arquivos pode ser removido e as consultas subsequentes terão que buscar novamente os dados do armazenamento remoto. Nesse caso, você não verá nenhum benefício do Cache Inteligente e talvez queira aumentar o tamanho do cache e/ou o tamanho do nó.
Sua carga de trabalho requer grandes quantidades de embaralhamento e, em seguida, desativar o Cache Inteligente liberará espaço disponível para evitar que seu trabalho falhe devido a espaço de armazenamento insuficiente.
Você está usando um pool do Spark 3.1, você precisará atualizar seu pool para a versão mais recente do Spark.
Saber mais
Para saber mais sobre o Apache Spark, consulte os seguintes artigos:
- O que é o Apache Spark
- Conceitos principais do Apache Spark
- Azure Synapse Runtime para Apache Spark 3.2
- Tamanhos e configurações de pool do Apache Spark
Para saber mais sobre como definir as configurações de sessão do Spark
- Definir configurações de sessão do Spark
- Como definir configurações personalizadas do Spark / Pyspark
Próximos passos
Um pool do Apache Spark fornece recursos de computação de big data de código aberto onde os dados podem ser carregados, modelados, processados e distribuídos para uma visão analítica mais rápida. Para saber mais sobre como criar um para executar suas cargas de trabalho do Spark, visite os seguintes tutoriais: