Gerir bibliotecas para conjuntos do Apache Spark no Azure Synapse Analytics
Depois de identificar os pacotes Scala, Java, R (Pré-visualização) ou Python que pretende utilizar ou atualizar para a sua aplicação Spark, pode instalá-los ou removê-los num conjunto do Spark. As bibliotecas ao nível do conjunto estão disponíveis para todos os blocos de notas e tarefas em execução no conjunto.
Existem duas formas principais de instalar uma biblioteca num conjunto do Spark:
- Instale uma biblioteca de área de trabalho que tenha sido carregada como um pacote de área de trabalho.
- Para atualizar bibliotecas python, forneça uma especificação de ambiente requirements.txt ou Conda environment.yml para instalar pacotes a partir de repositórios como PyPI, Conda-Forge e muito mais. Leia a secção sobre a especificação do ambiente para obter mais informações.
Depois de guardar as alterações, uma tarefa do Spark executará a instalação e colocará em cache o ambiente resultante para reutilização posterior. Assim que a tarefa estiver concluída, as novas tarefas do Spark ou as sessões de blocos de notas utilizarão as bibliotecas de conjuntos atualizadas.
Importante
- Se o pacote que está a instalar for grande ou demorar muito tempo a instalar, isso afetará o tempo de arranque da instância do Spark.
- A alteração da versão do PySpark, Python, Scala/Java, .NET, R ou Spark não é suportada.
- A instalação de pacotes a partir de repositórios externos, como pyPI, Conda-Forge ou canais Conda predefinidos, não é suportada nas áreas de trabalho ativadas pela proteção de exfiltração de dados.
Gerir pacotes a partir de Synapse Studio ou portal do Azure
As bibliotecas de conjuntos do Spark podem ser geridas a partir do Synapse Studio ou portal do Azure.
Para atualizar ou adicionar bibliotecas a um conjunto do Spark:
Navegue para a área de trabalho do Azure Synapse Analytics a partir do portal do Azure.
Se estiver a atualizar a partir do portal do Azure:
Na secção Recursos do Synapse, selecione o separador Conjuntos do Apache Spark e selecione um conjunto do Spark na lista.
Selecione os Pacotes na secção Definições do conjunto do Spark.
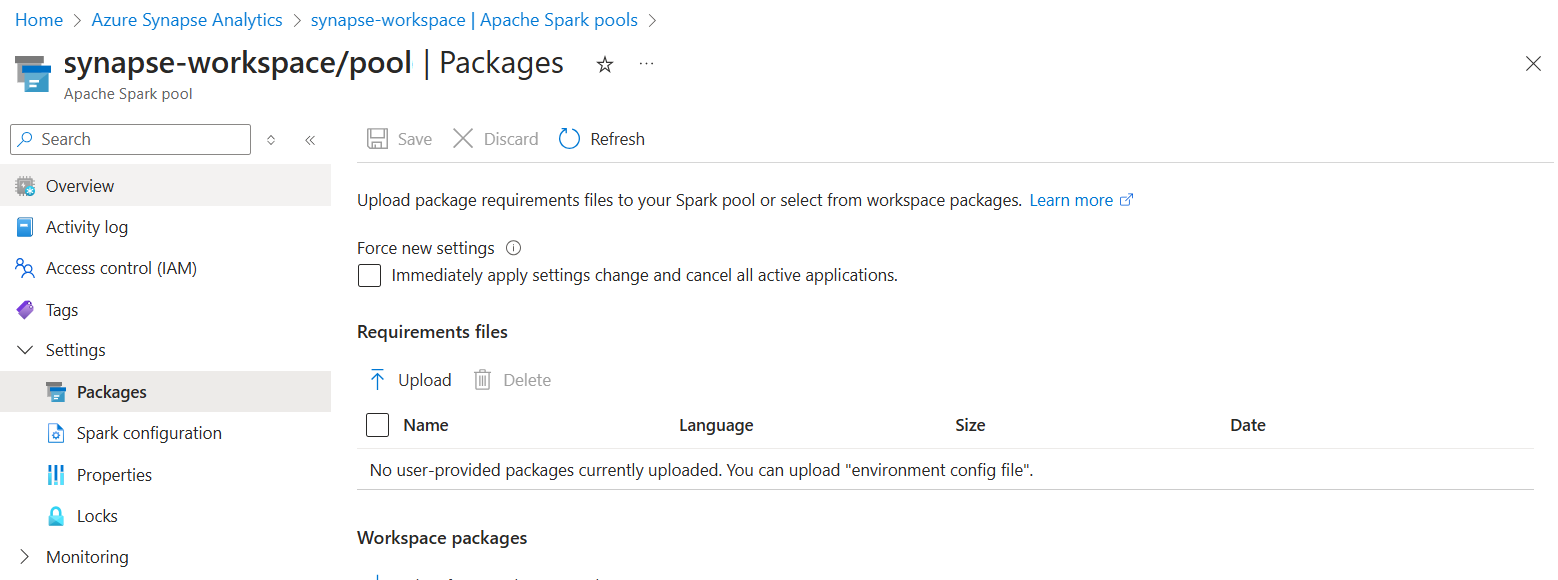
Se estiver a atualizar a partir do Synapse Studio:
Selecione Gerir no painel de navegação principal e, em seguida, selecione Conjuntos do Apache Spark.
Selecione a secção Pacotes para um conjunto específico do Spark.

Para bibliotecas de feed Python, carregue o ficheiro de configuração do ambiente com o seletor de ficheiros na secção Pacotes da página.
Também pode selecionar pacotes de áreas de trabalho adicionais para adicionar ficheiros Jar, Wheel ou Tar.gz ao conjunto.
Também pode remover os pacotes preteridos da secção Pacotes da Área de Trabalho . O conjunto deixará de anexar estes pacotes.
Assim que guardar as alterações, será acionada uma tarefa de sistema para instalar e colocar em cache as bibliotecas especificadas. Este processo ajuda a reduzir o tempo de arranque geral da sessão.
Assim que a tarefa tiver sido concluída com êxito, todas as novas sessões irão recolher as bibliotecas de conjuntos atualizadas.


Importante
Ao selecionar a opção para Forçar novas definições, terminará todas as sessões atuais para o conjunto do Spark selecionado. Assim que as sessões terminarem, terá de aguardar que o conjunto seja reiniciado.
Se esta definição estiver desmarcada, terá de aguardar que a sessão atual do Spark termine ou pare-a manualmente. Assim que a sessão terminar, terá de deixar o conjunto reiniciar.
Controlar o progresso da instalação
É iniciada uma tarefa do Spark reservada do sistema sempre que um conjunto é atualizado com um novo conjunto de bibliotecas. Esta tarefa do Spark ajuda a monitorizar o estado da instalação da biblioteca. Se a instalação falhar devido a conflitos de bibliotecas ou outros problemas, o conjunto do Spark reverterá para o estado anterior ou predefinido.
Além disso, os utilizadores também podem inspecionar os registos de instalação para identificar conflitos de dependência ou ver que bibliotecas foram instaladas durante a atualização do conjunto.
Para ver estes registos:
- Navegue para a lista de aplicações do Spark no separador Monitor .
- Selecione a tarefa da aplicação Spark do sistema que corresponde à atualização do conjunto. Estas tarefas de sistema são executadas no título SystemReservedJob-LibraryManagement .

- Mude para ver os registos de controlador e stdout .
- Nos resultados, verá os registos relacionados com a instalação das suas dependências.



Formatos de especificação do ambiente
PIP requirements.txt
Um ficheiro derequirements.txt (saída do pip freeze comando) pode ser utilizado para atualizar o ambiente. Quando um conjunto é atualizado, os pacotes listados neste ficheiro são transferidos a partir do PyPI. Em seguida, as dependências completas são colocadas em cache e guardadas para reutilização posterior do conjunto.
O fragmento seguinte mostra o formato do ficheiro de requisitos. O nome do pacote PyPI está listado juntamente com uma versão exata. Este ficheiro segue o formato descrito na documentação de referência pip freeze .
Este exemplo afixa uma versão específica.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Formato YML
Além disso, também pode fornecer um ficheiro environment.yml para atualizar o ambiente do conjunto. Os pacotes listados neste ficheiro são transferidos a partir dos canais Conda predefinidos, Conda-Forge e PyPI. Pode especificar outros canais ou remover os canais predefinidos com as opções de configuração.
Este exemplo especifica os canais e as dependências conda/PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Para obter detalhes sobre como criar um ambiente a partir deste ficheiro environment.yml, veja Criar um ambiente a partir de um ficheiro environment.yml.
Passos seguintes
- Ver as bibliotecas predefinidas: suporte da versão do Apache Spark
- Resolver erros de instalação da biblioteca: Resolver erros da biblioteca