Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial baseado numa base de data lake, com uma arquitetura pronta para o futuro, IA incorporada e novas funcionalidades. Se és novo no data warehousing, começa pelo Fabric Data Warehouse. As cargas de trabalho existentes de pool SQL dedicado podem atualizar para o Fabric para acessar novas capacidades em ciência de dados, análise em tempo real e relatórios.
Este artigo explica a instrução CREATE TABLE AS SELECT (CTAS) T-SQL no pool SQL dedicado (anteriormente SQL DW) para o desenvolvimento de soluções. O artigo também fornece exemplos de código.
CRIAR TABELA COMO SELECIONAR
A instrução CREATE TABLE AS SELECT (CTAS) é um dos recursos T-SQL mais importantes disponíveis. CTAS é uma operação paralela que cria uma nova tabela com base na saída de uma instrução SELECT. O CTAS é a maneira mais simples e rápida de criar e inserir dados em uma tabela com um único comando.
SELECIONAR... INTO vs. CTAS
CTAS é uma versão mais personalizável da instrução SELECT...INTO.
Segue um exemplo de um SELECT...INTO:
SELECT *
INTO [dbo].[FactInternetSales_new]
FROM [dbo].[FactInternetSales]
SELECIONAR... O INTO não permite alterar o método de distribuição ou o tipo de índice como parte da operação. Você cria [dbo].[FactInternetSales_new] usando o tipo de distribuição padrão de ROUND_ROBIN e a estrutura de tabela padrão de CLUSTERED COLUMNSTORE INDEX.
Com o CTAS, por outro lado, você pode especificar a distribuição dos dados da tabela, bem como o tipo de estrutura da tabela. Para converter o exemplo anterior em CTAS:
CREATE TABLE [dbo].[FactInternetSales_new]
WITH
(
DISTRIBUTION = ROUND_ROBIN
,CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT *
FROM [dbo].[FactInternetSales];
Nota
Se você estiver apenas tentando alterar o índice em sua operação CTAS e a tabela de origem for distribuída por hash, mantenha a mesma coluna de distribuição e o mesmo tipo de dados. Isso evita a movimentação de dados entre distribuições durante a operação, o que é mais eficiente.
Usar CTAS para copiar uma tabela
Talvez um dos usos mais comuns do CTAS seja criar uma cópia de uma tabela para alterar a DDL. Digamos que você criou originalmente sua tabela como ROUND_ROBIN, e agora deseja alterá-la para uma tabela distribuída em uma coluna. CTAS é a forma como se altera a coluna de distribuição. Você também pode usar o CTAS para alterar o particionamento, a indexação ou os tipos de coluna.
Digamos que você criou esta tabela especificando HEAP e usando o tipo de distribuição padrão de ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey int NOT NULL,
OrderDateKey int NOT NULL,
DueDateKey int NOT NULL,
ShipDateKey int NOT NULL,
CustomerKey int NOT NULL,
PromotionKey int NOT NULL,
CurrencyKey int NOT NULL,
SalesTerritoryKey int NOT NULL,
SalesOrderNumber nvarchar(20) NOT NULL,
SalesOrderLineNumber tinyint NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderQuantity smallint NOT NULL,
UnitPrice money NOT NULL,
ExtendedAmount money NOT NULL,
UnitPriceDiscountPct float NOT NULL,
DiscountAmount float NOT NULL,
ProductStandardCost money NOT NULL,
TotalProductCost money NOT NULL,
SalesAmount money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
CarrierTrackingNumber nvarchar(25),
CustomerPONumber nvarchar(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Agora você deseja criar uma nova cópia desta tabela, com um Clustered Columnstore Index, para que possa aproveitar o desempenho das tabelas Clustered Columnstore. Você também deseja distribuir esta tabela no ProductKey, porque está antecipando junções nesta coluna e deseja evitar a movimentação de dados durante as junções no ProductKey. Por fim, você também deseja adicionar particionamento no OrderDateKey, para que você possa excluir rapidamente dados antigos descartando partições antigas. Aqui está a instrução CTAS, que copia sua tabela antiga para uma nova tabela.
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Finalmente, pode renomear as suas tabelas, substituí-las pela sua nova tabela e, em seguida, eliminar a sua tabela antiga.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Declarar explicitamente o tipo de dados e a anulabilidade da saída
Ao migrar o código, você pode encontrar este tipo de padrão de codificação.
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f;
Você pode pensar que deve migrar esse código para o CTAS, e você estaria correto. No entanto, há uma questão oculta aqui.
O código a seguir não produz o mesmo resultado:
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result;
Observe que a coluna "result" transporta para frente o tipo de dados e os valores de anulabilidade da expressão. Levar o tipo de dados adiante pode levar a variações sutis nos valores se você não tiver cuidado.
Experimente este exemplo:
SELECT result,result*@d
from result;
SELECT result,result*@d
from ctas_r;
O valor armazenado para o resultado é diferente. Como o valor persistente na coluna de resultados é usado em outras expressões, o erro se torna ainda mais significativo.
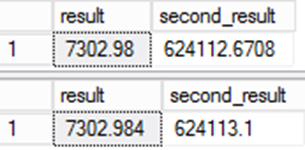
Isso é importante para migrações de dados. Embora a segunda consulta seja indiscutivelmente mais precisa, há um problema. Os dados seriam diferentes em comparação com o sistema de origem, e isso leva a questões de integridade na migração. Este é um daqueles raros casos em que a resposta "errada" é realmente a certa!
A razão pela qual vemos uma disparidade entre os dois resultados é devido à conversão de tipo implícita. No primeiro exemplo, a tabela define a definição de coluna. Quando a linha é inserida, ocorre uma conversão de tipo implícita. No segundo exemplo, não há conversão de tipo implícita, pois a expressão define o tipo de dados da coluna.
Observe também que a coluna no segundo exemplo foi definida para permitir valores NULL, enquanto no primeiro exemplo não foi. Quando a tabela foi criada no primeiro exemplo, a anulabilidade da coluna foi explicitamente definida. No segundo exemplo, foi deixado para a expressão e, por padrão, resultaria em uma definição NULL.
Para resolver esses problemas, você deve definir explicitamente a conversão de tipo e a anulabilidade na parte SELECT da instrução CTAS. Não é possível definir essas propriedades em 'CREATE TABLE'. O exemplo a seguir demonstra como corrigir o código:
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Tenha em atenção o seguinte:
- Você pode usar CAST ou CONVERT.
- Use ISNULL, não COALESCE, para garantir a possibilidade de nulidade. Ver nota seguinte.
- ISNULL é a função mais externa.
- A segunda parte do ISNULL é uma constante, 0.
Nota
Para que a anulabilidade seja definida corretamente, é vital usar ISNULL e não COALESCE. COALESCE não é uma função determinística e, portanto, o resultado da expressão será sempre passível de ser NULL. ISNULL é diferente. É determinista. Portanto, quando a segunda parte da função ISNULL é uma constante ou um literal, o valor resultante será "NOT NULL".
Garantir a integridade dos seus cálculos também é importante para a comutação de partições de tabelas. Imagine que você tem esta tabela definida como uma tabela de fatos:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
);
No entanto, o campo de quantidade é uma expressão calculada. Não faz parte dos dados de origem.
Para criar seu conjunto de dados particionado, convém usar o seguinte código:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
A consulta funcionaria perfeitamente bem. O problema surge quando tenta mudar a partição. As definições da tabela não correspondem. Para fazer com que as definições de tabela correspondam, modifique o CTAS para adicionar uma ISNULL função para preservar o atributo de anulabilidade da coluna.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Você pode ver que a consistência de tipo e a manutenção de propriedades de anulabilidade em um CTAS são práticas recomendadas de engenharia. Ajuda a manter a integridade nos seus cálculos e também garante que a comutação de partições é possível.
CTAS é uma das instruções mais importantes no Synapse SQL. Certifique-se de compreendê-lo completamente. Consulte a documentação do CTAS.
Conteúdos relacionados
Para obter mais dicas de desenvolvimento, consulte a visão geral do desenvolvimento.