Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial baseado numa base de data lake, com uma arquitetura pronta para o futuro, IA incorporada e novas funcionalidades. Se és novo no data warehousing, começa pelo Fabric Data Warehouse. As cargas de trabalho existentes de pool SQL dedicado podem atualizar para o Fabric para acessar novas capacidades em ciência de dados, análise em tempo real e relatórios.
Uma tabela externa aponta para dados localizados no Hadoop, no blob de Armazenamento do Azure ou no Azure Data Lake Storage (ADLS).
Você pode usar tabelas externas para ler dados de arquivos ou gravar dados em arquivos no Armazenamento do Azure. Com o Azure Synapse SQL, você pode usar tabelas externas para ler dados externos usando pool SQL dedicado ou pool SQL sem servidor.
Dependendo do tipo de fonte de dados externa, você pode usar dois tipos de tabelas externas:
- Tabelas externas do Hadoop que você pode usar para ler e exportar dados em vários formatos de dados, como CSV, Parquet e ORC. As tabelas externas do Hadoop estão disponíveis em pools SQL dedicados, mas não estão disponíveis em pools SQL sem servidor.
- Tabelas externas nativas que você pode usar para ler e exportar dados em vários formatos de dados, como CSV e Parquet. Tabelas externas nativas estão disponíveis em pools SQL sem servidor e em pools SQL dedicados. A gravação/exportação de dados usando o CETAS e as tabelas externas nativas está disponível apenas no pool SQL sem servidor, mas não nos pools SQL dedicados.
As principais diferenças entre o Hadoop e as tabelas externas nativas:
| Tipo de tabela externa | Hadoop | Nativa |
|---|---|---|
| Conjunto de SQL dedicado | Disponível | Apenas parquet |
| Conjunto de SQL sem servidor | Não disponível | Disponível |
| Formatos suportados | Delimitado/CSV, Parquet, ORC, Hive RC e RC | Pool SQL sem servidor: Delimitado/CSV, Parquet e Delta Lake Pool de SQL dedicado: Parquet |
| Eliminação de partição de pasta | Não | A eliminação de partições está disponível apenas nas tabelas particionadas criadas nos formatos Parquet ou CSV sincronizadas a partir de pools do Apache Spark. Você pode criar tabelas externas em pastas particionadas do Parquet, mas as colunas de particionamento são inacessíveis e ignoradas, enquanto a eliminação de partições não será aplicada. Não crie tabelas externas em pastas Delta Lake porque elas não são suportadas. Utilize visões particionadas Delta se precisar consultar dados particionados do Delta Lake. |
| Eliminação de ficheiros (otimização de predicados) | Não | Sim no pool SQL sem servidor. Para o pushdown de cadeia de caracteres, precisas usar o Latin1_General_100_BIN2_UTF8 agrupamento nas colunas para ativar o pushdown. Para obter mais informações sobre agrupamentos, consulte Suporte de agrupamento de banco de dados para Synapse SQL no Azure Synapse Analytics. |
| Formato personalizado para localização | Não | Sim, usando curingas como /year=*/month=*/day=* para os formatos Parquet ou CSV. Os caminhos de pasta personalizados não estão disponíveis no Delta Lake. No pool SQL sem servidor, você também pode usar curingas /logs/** recursivos para fazer referência a arquivos Parquet ou CSV em qualquer subpasta abaixo da pasta referenciada. |
| Varredura de pasta recursiva | Sim | Sim. Nos pools SQL sem servidor, deve ser especificado /** no final do caminho da localização. No pool dedicado, as pastas são sempre verificadas recursivamente. |
| Autenticação de armazenamento | Chave de acesso de armazenamento (SAK), autenticação transitória do Microsoft Entra, identidade gerenciada, identidade do Microsoft Entra para aplicação personalizada | Assinatura de Acesso Compartilhado (SAS),passagem direta do Microsoft Entra,identidade gerida,identidade personalizada da aplicação Microsoft Entra. |
| Mapeamento de colunas | Ordinal - as colunas na definição da tabela externa são mapeadas para as colunas nos arquivos Parquet subjacentes por posição. | Pool sem servidor: por nome. As colunas na definição de tabela externa são mapeadas para as colunas nos arquivos Parquet subjacentes por correspondência de nome de coluna. Piscina dedicada: correspondência ordinal. As colunas na definição da tabela externa são correspondidas às colunas dos ficheiros Parquet subjacentes com base na sua posição. |
| CETAS (exportação/transformação) | Sim | O CETAS com as tabelas nativas como destino funciona apenas no pool SQL sem servidor. Não é possível usar os pools SQL dedicados para exportar dados usando tabelas nativas. |
Nota
As mesas externas nativas são a solução recomendada nas piscinas onde estão geralmente disponíveis. Se você precisar acessar dados externos, sempre use as tabelas nativas em pools sem servidor ou dedicados. Use as tabelas Hadoop somente se precisar acessar alguns tipos que não são suportados em tabelas externas nativas (por exemplo, ORC, RC) ou se a versão nativa não estiver disponível.
Tabelas externas no pool SQL dedicado e no pool SQL sem servidor
Você pode usar tabelas externas para:
- Consulte o Armazenamento de Blobs do Azure e o ADLS Gen2 com instruções Transact-SQL.
- Armazene os resultados da consulta em arquivos no Armazenamento de Blobs do Azure ou no Armazenamento do Azure Data Lake usando o CETAS com Synapse SQL.
- Importe dados do Armazenamento de Blobs do Azure e do Armazenamento do Azure Data Lake e armazene-os em um pool SQL dedicado (somente tabelas Hadoop no pool dedicado).
Nota
Quando usado com a instrução CREATE TABLE AS SELECT, selecionar de uma tabela externa importa dados para uma tabela dentro do pool SQL dedicado.
Se o desempenho das tabelas externas do Hadoop nos pools dedicados não satisfizer as suas metas de desempenho, considere a possibilidade de carregar dados externos para as tabelas do armazenamento de dados usando a instrução COPY.
Para obter um tutorial de carregamento, consulte Usar o PolyBase para carregar dados do Armazenamento de Blobs do Azure.
Você pode criar tabelas externas em pools Synapse SQL através das seguintes etapas:
- CREATE EXTERNAL DATA SOURCE para fazer referência a um armazenamento externo do Azure e especificar a credencial que deve ser usada para acessar o armazenamento.
- CREATE EXTERNAL FILE FORMAT para definir o formato de ficheiros CSV ou Parquet.
- CREATE EXTERNAL TABLE em cima dos arquivos colocados na fonte de dados com o mesmo formato de arquivo.
Eliminação de partições de pastas
As tabelas externas nativas nos pools Synapse são capazes de ignorar os arquivos colocados nas pastas que não são relevantes para as consultas. Se os seus ficheiros estiverem armazenados numa hierarquia de pastas (por exemplo - /year=2020/month=03/day=16) e os valores para year, monthe day forem expostos como as colunas, as consultas que contêm filtros como lerão os ficheiros apenas year=2020 a partir das subpastas colocadas dentro da year=2020 pasta. Os ficheiros e pastas colocados noutras pastas (year=2021 ou year=2022) serão ignorados nesta consulta. Esta eliminação é conhecida como eliminação de partição.
A eliminação de partições de pastas está disponível nas tabelas externas nativas que são sincronizadas nos pools do Synapse Spark. Se você tiver um conjunto de dados particionado e quiser usar a eliminação de partições com as tabelas externas criadas, use as exibições particionadas em vez das tabelas externas.
Eliminação de ficheiros
Alguns formatos de dados, como Parquet e Delta, contêm estatísticas de arquivo para cada coluna (por exemplo, valores min/max para cada coluna). As consultas que filtram dados não lerão os arquivos onde os valores de coluna necessários não existem. A consulta primeiro explorará valores min/max para as colunas usadas no predicado de consulta para localizar os arquivos que não contêm os dados necessários. Esses arquivos são ignorados e eliminados do plano de consulta.
Essa técnica também é conhecida como aplicação de filtros a nível de predicados e pode melhorar o desempenho das consultas. A otimização de filtros está disponível nos pools SQL sem servidor para os formatos Parquet e Delta. Para aplicar pushdown de filtro para os tipos de strings, use o tipo VARCHAR com a ordenação Latin1_General_100_BIN2_UTF8. Para obter mais informações sobre agrupamentos, consulte Suporte de agrupamento de banco de dados para Synapse SQL no Azure Synapse Analytics.
Segurança
O usuário deve ter SELECT permissão em uma tabela externa para ler os dados.
As tabelas externas acessam o armazenamento subjacente do Azure usando a credencial de escopo do banco de dados definida na fonte de dados usando as seguintes regras:
- A fonte de dados sem credencial permite que tabelas externas acessem arquivos disponíveis publicamente no armazenamento do Azure.
- A fonte de dados pode ter uma credencial que permite que tabelas externas acedam apenas aos ficheiros no armazenamento do Azure usando um token SAS ou uma Identidade Gerida do espaço de trabalho - Para ver exemplos, consulte o artigo "Desenvolver o controlo de acesso ao armazenamento de ficheiros".
Observações
Para garantir a execução confiável da consulta, os arquivos e pastas de origem referenciados por tabelas externas devem permanecer inalterados durante toda a duração da operação.
- Modificar, excluir ou substituir quaisquer arquivos ou pastas referenciados enquanto a consulta está em execução pode causar falhas ou levar a resultados inconsistentes.
- Antes de consultar tabelas externas em um pool SQL dedicado, verifique se todos os dados de origem são estáveis e não serão alterados durante a execução.
Exemplo para o comando CREATE EXTERNAL DATA SOURCE
O exemplo a seguir cria uma fonte de dados externa do Hadoop no pool SQL dedicado para ADLS Gen2 apontando para o conjunto de dados público de Nova York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
O exemplo a seguir cria uma fonte de dados externa para o ADLS Gen2 apontando para o conjunto de dados de Nova York disponível publicamente:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Exemplo para CREATE EXTERNAL FILE FORMAT
O exemplo a seguir cria um formato de arquivo externo para arquivos de censo:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Exemplo de utilização do comando CREATE EXTERNAL TABLE
O exemplo a seguir cria uma tabela externa. Retorna a primeira linha:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Criar e consultar tabelas externas a partir de um arquivo no Azure Data Lake
Usando os recursos de exploração do Data Lake do Synapse Studio, agora você pode criar e consultar uma tabela externa usando o pool Synapse SQL com um clique com o botão direito do mouse no arquivo. O gesto de um único clique para criar tabelas externas a partir da conta de armazenamento ADLS Gen2 apenas é suportado para ficheiros Parquet.
Pré-requisitos
Você deve ter acesso ao espaço de trabalho com pelo menos o papel de acesso
Storage Blob Data Contributorà conta ADLS Gen2 ou às Listas de Controle de Acesso (ACL) que permitem que consulte os arquivos.Você deve ter pelo menos permissões para criar uma tabela externa e consultar tabelas externas no pool SQL Synapse (dedicado ou sem servidor).
No painel Dados, selecione o arquivo a partir do qual deseja criar a tabela externa:

Será aberta uma janela de diálogo. Selecione pool SQL dedicado ou pool SQL sem servidor, dê um nome à tabela e selecione script aberto:
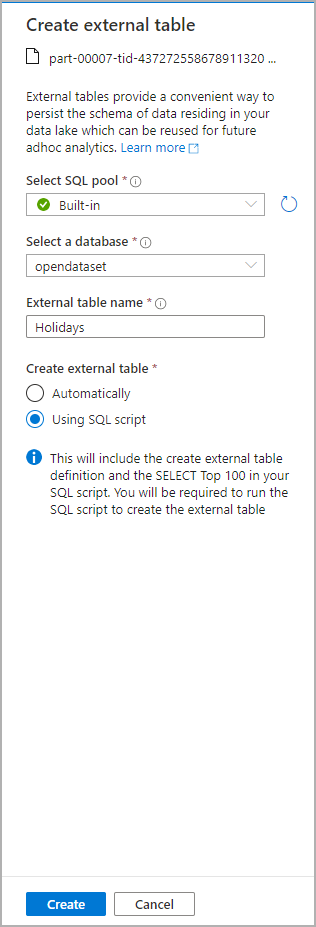
O Script SQL é gerado automaticamente inferindo o esquema do arquivo:

Executar o script. O script executará automaticamente um SELECT TOP 100 *:

A tabela externa foi agora criada. Agora você pode consultar a tabela externa diretamente do painel Dados.
Conteúdos relacionados
Consulte o artigo CETAS para saber como salvar os resultados da consulta em uma tabela externa no Armazenamento do Azure. Ou você pode começar a consultar tabelas externas do Apache Spark for Azure Synapse.