Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial baseado numa base de data lake, com uma arquitetura pronta para o futuro, IA incorporada e novas funcionalidades. Se és novo no data warehousing, começa pelo Fabric Data Warehouse. As cargas de trabalho existentes de pool SQL dedicado podem atualizar para o Fabric para acessar novas capacidades em ciência de dados, análise em tempo real e relatórios.
Neste artigo, vai aprender como consultar um único ficheiro CSV usando um pool SQL serverless no Azure Synapse Analytics. Os ficheiros CSV podem ter formatos diferentes:
- Com e sem linha de cabeçalho
- Valores delimitados por vírgulas e tabulações
- Terminações de linhas ao estilo Windows e Unix
- Valores não citados e citados, e personagens que escapam
Todas as variações acima serão abordadas abaixo.
Exemplo de início rápido
OPENROWSET permite ler o conteúdo do ficheiro CSV fornecendo o URL do seu ficheiro.
Leia um ficheiro csv
A forma mais fácil de ver o conteúdo do teu CSV ficheiro é fornecer o URL do ficheiro para a função OPENROWSET, especificar csv FORMAT, e 2.0 PARSER_VERSION. Se o ficheiro estiver disponível publicamente ou se a sua identidade Microsoft Entra puder aceder a este ficheiro, deverá conseguir ver o conteúdo do ficheiro usando a consulta, tal como mostrada no exemplo seguinte:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
A opção firstrow é usada para saltar a primeira linha do ficheiro CSV que representa o cabeçalho neste caso. Certifique-se de que pode aceder a este ficheiro. Se o seu ficheiro estiver protegido por uma chave SAS ou uma identidade personalizada, terá de configurar a credencial de nível de servidor para o login SQL.
Importante
Se o seu ficheiro CSV contiver caracteres UTF-8, certifique-se de que está a usar uma compilação de base de dados UTF-8 (por exemplo Latin1_General_100_CI_AS_SC_UTF8).
Uma incompatibilidade entre a codificação de texto no ficheiro e a colação pode causar erros inesperados de conversão.
Pode facilmente alterar a colocação padrão da base de dados atual usando a seguinte instrução T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Utilização de fontes de dados
O exemplo anterior usa o caminho completo até ao ficheiro. Como alternativa, pode criar uma fonte de dados externa com a localização que aponta para a pasta raiz do armazenamento:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Depois de criar uma fonte de dados, pode usar essa fonte e o caminho relativo para o ficheiro na OPENROWSET função:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Se uma fonte de dados estiver protegida com uma chave SAS ou uma identidade personalizada, pode configurar a fonte de dados utilizando uma credencial com escopo de base de dados.
Especificar explicitamente o esquema
OPENROWSET Permite-lhe especificar explicitamente que colunas quer ler do ficheiro usando WITH a cláusula:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Os números após um tipo de dado na WITH cláusula representam o índice da coluna no ficheiro CSV.
Importante
Se o seu ficheiro CSV contiver caracteres UTF-8, certifique-se de especificar explicitamente alguma colação UTF-8 (por exemplo Latin1_General_100_CI_AS_SC_UTF8) para todas as colunas da WITH cláusula ou defina alguma colação UTF-8 ao nível da base de dados.
A incompatibilidade entre a codificação de texto no ficheiro e a colação pode causar erros inesperados de conversão.
Pode facilmente alterar a colocação padrão da base de dados atual usando a seguinte instrução T-SQL:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Pode facilmente definir a colação nos tipos de colunas usando a seguinte definição: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Nas secções seguintes pode ver como consultar vários tipos de ficheiros CSV.
Prerequisites
O seu primeiro passo é criar uma base de dados onde as tabelas serão criadas. Depois inicialize os objetos executando o script setup nessa base de dados. Este script de configuração criará as fontes de dados, credenciais com âmbito de base de dados e formatos de ficheiro externos usados nestes exemplos.
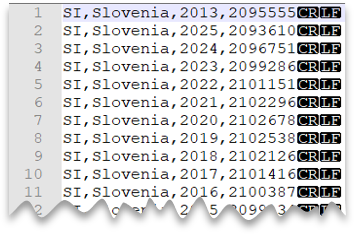
Nova linha ao estilo Windows
A consulta seguinte mostra como ler um ficheiro CSV sem uma linha de cabeçalho, com uma nova linha ao estilo do Windows e colunas delimitadas por vírgulas.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
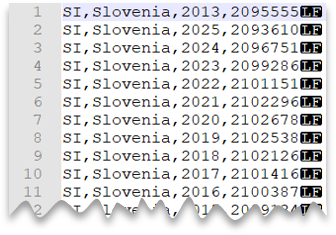
Nova linha ao estilo Unix
A consulta seguinte mostra como ler um ficheiro sem uma linha de cabeçalho, com uma nova linha ao estilo Unix e colunas delimitadas por vírgulas. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
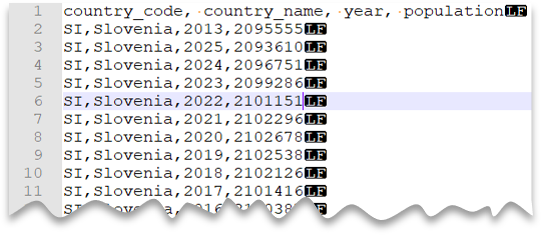
Linha de cabeçalho
A consulta seguinte mostra como ler um ficheiro com uma linha de cabeçalho, com uma nova linha ao estilo Unix e colunas delimitadas por vírgulas. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
A opção HEADER_ROW = TRUE resultará na leitura dos nomes das colunas da linha de cabeçalho no ficheiro. É ótimo para fins de exploração quando não estás familiarizado com o conteúdo dos ficheiros. Para melhor desempenho, consulte a secção Usar tipos de dados apropriados nas Melhores Práticas. Além disso, pode ler mais sobre a sintaxe do OPENROWSET aqui.
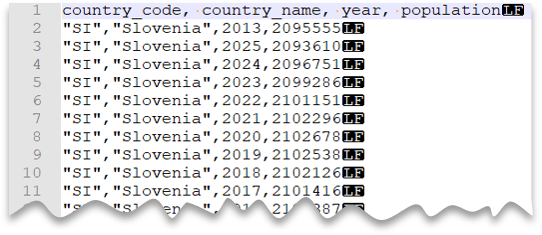
Carácter de citação personalizado
A consulta seguinte mostra como ler um ficheiro com uma linha de cabeçalho, com uma nova linha ao estilo Unix, colunas delimitadas por vírgulas e valores aspas. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nota
Esta consulta devolverá os mesmos resultados se omitir o parâmetro FIELDQUOTE, uma vez que o valor padrão de FIELDQUOTE é um par de aspas duplas.
Personagens de fuga
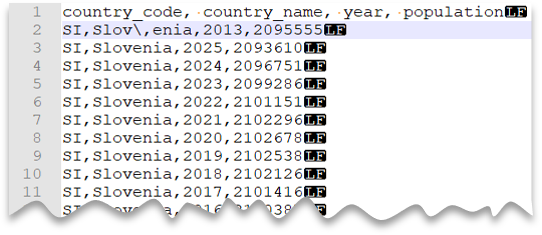
A consulta seguinte mostra como ler um ficheiro com uma linha de cabeçalho, com uma nova linha ao estilo Unix, colunas delimitadas por vírgulas e um carcaça de escape usado para o delimitador de campo (vírgula) dentro dos valores. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
Esta consulta falharia se o ESCAPECHAR não for especificado, já que a vírgula em "Slov,enia" seria tratada como delimitador de campo em vez de parte do nome do país/região. "Slov,enia" seria tratado como duas colunas. Portanto, a linha em questão teria uma coluna a mais do que as outras linhas, e uma coluna a mais do que definiste na cláusula WITH.
Personagens que citam Escape
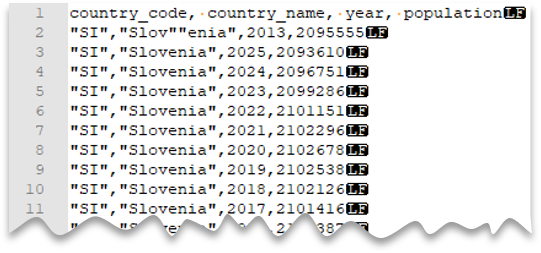
A consulta seguinte mostra como ler um ficheiro com uma linha de cabeçalho, com uma nova linha ao estilo Unix, colunas delimitadas por vírgulas e um caráter de aspas duplas escapado dentro dos valores. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
O caractere de citação deve ser precedido por outro caractere de citação. O carácter de citação só pode aparecer dentro do valor da coluna se o valor estiver encapsulado com caracteres de aspas.
Ficheiros delimitados por tabulação
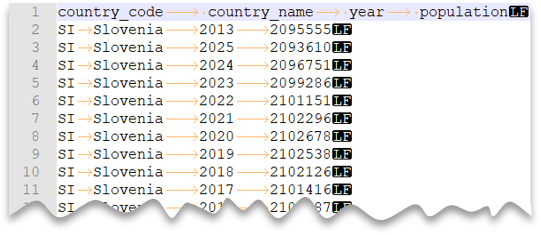
A consulta seguinte mostra como ler um ficheiro com uma linha de cabeçalho, com uma nova linha ao estilo Unix e colunas delimitadas por tabuladores. Note a localização diferente do ficheiro em comparação com os outros exemplos.
Pré-visualização do ficheiro:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Devolver um subconjunto de colunas
Até agora, especificaste o esquema de ficheiros CSV usando WITH e listando todas as colunas. Só pode especificar as colunas que realmente precisa na sua consulta usando um número ordinal para cada coluna necessária. Também vais omitir colunas sem interesse.
A consulta seguinte devolve o número de nomes distintos de países/regiões num ficheiro, especificando apenas as colunas necessárias:
Nota
Veja a cláusula WITH na consulta abaixo e note que há "2" (sem aspas) no final da linha onde define a coluna [country_name ]. Significa que a coluna [country_name] é a segunda coluna do ficheiro. A consulta ignora todas as colunas do ficheiro, exceto a segunda.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Consulta de ficheiros passíveis de anexação
Os ficheiros CSV usados na consulta não devem ser alterados enquanto a consulta está a correr. Na consulta de longa duração, o pool SQL pode tentar novamente leituras, ler partes dos ficheiros ou até ler o ficheiro várias vezes. Alterações no conteúdo do ficheiro causariam resultados errados. Portanto, o pool SQL falha a consulta se detetar que o tempo de modificação de qualquer ficheiro é alterado durante a execução da consulta.
Em alguns cenários, pode querer ler os ficheiros que são constantemente anexados. Para evitar falhas de consulta devido a ficheiros constantemente anexados, pode permitir que a OPENROWSET função ignore leituras potencialmente inconsistentes usando a ROWSET_OPTIONS definição.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
A ALLOW_INCONSISTENT_READS opção de leitura desativa a verificação do tempo de modificação do ficheiro durante o ciclo de vida da consulta e lê tudo o que estiver disponível no ficheiro. Nos arquivos anexáveis, o conteúdo existente não é atualizado e apenas novas linhas são adicionadas. Assim, a probabilidade de resultados errados é minimizada em comparação com os ficheiros atualizáveis. Esta opção pode permitir-lhe ler os ficheiros frequentemente adicionados sem lidar com os erros. Na maioria dos cenários, o pool SQL simplesmente ignora algumas linhas que são anexadas aos ficheiros durante a execução da consulta.
Conteúdo relacionado
Os próximos artigos vão mostrar-lhe como:
- Consulta de ficheiros de Parquet
- Consulta de pastas e múltiplos ficheiros