Elevada disponibilidade do IBM DB2 LUW nas VMs do Azure no Red Hat Enterprise Linux Server
O IBM Db2 para Linux, UNIX e Windows (LUW) na configuração de alta disponibilidade e recuperação de desastres (HADR) consiste em um nó que executa uma instância de banco de dados primária e pelo menos um nó que executa uma instância de banco de dados secundária. As alterações na instância do banco de dados primário são replicadas para uma instância de banco de dados secundária de forma síncrona ou assíncrona, dependendo da sua configuração.
Nota
Este artigo contém referências a termos que a Microsoft já não utiliza. Quando estes termos forem removidos do software, iremos removê-los deste artigo.
Este artigo descreve como implementar e configurar as máquinas virtuais (VMs) do Azure, instalar a estrutura de cluster e instalar o IBM Db2 LUW com configuração HADR.
O artigo não aborda como instalar e configurar o IBM Db2 LUW com HADR ou instalação de software SAP. Para ajudá-lo a realizar essas tarefas, fornecemos referências aos manuais de instalação SAP e IBM. Este artigo se concentra em partes que são específicas para o ambiente do Azure.
As versões suportadas do IBM Db2 são 10.5 e posteriores, conforme documentado na nota 1928533 do SAP.
Antes de iniciar uma instalação, consulte as seguintes notas e documentação do SAP:
| Nota SAP | Description |
|---|---|
| 1928533 | Aplicativos SAP no Azure: produtos suportados e tipos de VM do Azure |
| 2015553 | SAP no Azure: pré-requisitos de suporte |
| 2178632 | Principais métricas de monitoramento para SAP no Azure |
| 2191498 | SAP no Linux com Azure: monitoramento aprimorado |
| 2243692 | Linux on Azure (IaaS) VM: Problemas de licença SAP |
| 2002167 | Red Hat Enterprise Linux 7.x: Instalação e atualização |
| 2694118 | Complemento Red Hat Enterprise Linux HA no Azure |
| 1999351 | Solução de problemas de monitoramento avançado do Azure para SAP |
| 2233094 | DB6: Aplicativos SAP no Azure que usam IBM Db2 para Linux, UNIX e Windows - informações adicionais |
| 1612105 | DB6: Perguntas frequentes sobre o DB2 com HADR |
Descrição geral
Para obter alta disponibilidade, o IBM Db2 LUW com HADR é instalado em pelo menos duas máquinas virtuais do Azure, que são implementadas em um conjunto de escala de máquina virtual com orquestração flexível entre zonas de disponibilidade ou em um conjunto de disponibilidade.
Os gráficos a seguir exibem uma configuração de duas VMs do Azure do servidor de banco de dados. Ambas as VMs do Azure do servidor de banco de dados têm seu próprio armazenamento anexado e estão em execução. No HADR, uma instância de banco de dados em uma das VMs do Azure tem a função da instância primária. Todos os clientes estão conectados à instância principal. Todas as alterações nas transações do banco de dados são persistidas localmente no log de transações do DB2. Como os registros de log de transações são persistentes localmente, os registros são transferidos via TCP/IP para a instância de banco de dados no segundo servidor de banco de dados, o servidor em espera ou a instância em espera. A instância em espera atualiza o banco de dados local rolando para frente os registros de log de transações transferidos. Desta forma, o servidor em espera é mantido em sincronia com o servidor primário.
O HADR é apenas uma funcionalidade de replicação. Ele não tem deteção de falhas e nenhuma tomada automática ou instalações de failover. Uma aquisição ou transferência para o servidor em espera deve ser iniciada manualmente por um administrador de banco de dados. Para obter uma aquisição automática e deteção de falhas, você pode usar o recurso de cluster Linux Pacemaker. O Pacemaker monitora as duas instâncias do servidor de banco de dados. Quando a instância do servidor de banco de dados primário falha, o Pacemaker inicia uma aquisição automática de HADR pelo servidor em espera. O Pacemaker também garante que o endereço IP virtual seja atribuído ao novo servidor primário.
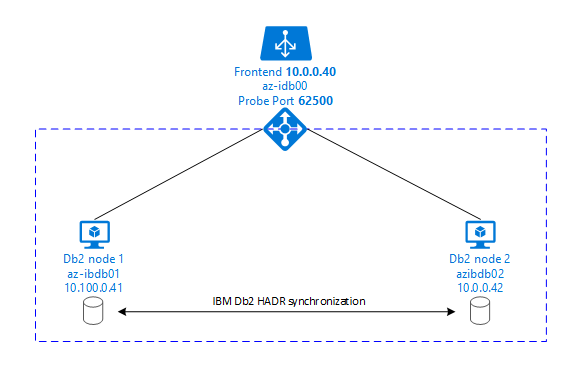
Para que os servidores de aplicativos SAP se conectem ao banco de dados primário, você precisa de um nome de host virtual e um endereço IP virtual. Após um failover, os servidores de aplicativos SAP se conectam à nova instância de banco de dados primária. Em um ambiente do Azure, um balanceador de carga do Azure é necessário para usar um endereço IP virtual da maneira necessária para o HADR do IBM DB2.
Para ajudá-lo a entender completamente como o IBM Db2 LUW com HADR e Pacemaker se encaixa em uma configuração de sistema SAP altamente disponível, a imagem a seguir apresenta uma visão geral de uma configuração altamente disponível de um sistema SAP baseado no banco de dados IBM DB2. Este artigo aborda apenas o IBM Db2, mas fornece referências a outros artigos sobre como configurar outros componentes de um sistema SAP.
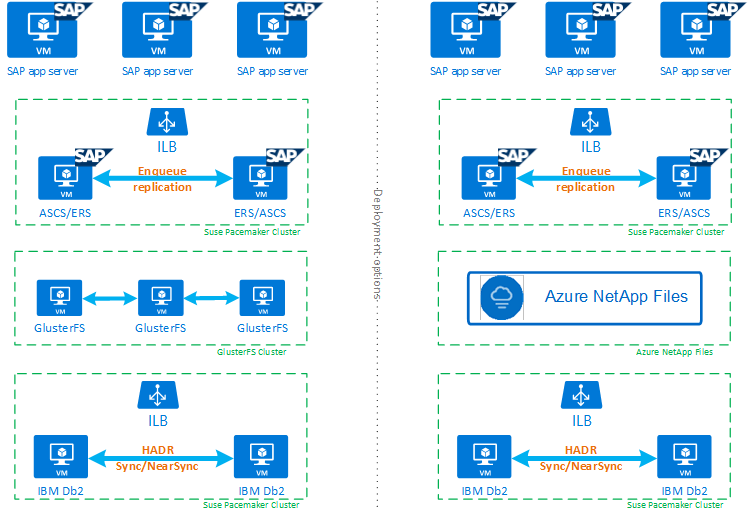
Visão geral de alto nível das etapas necessárias
Para implementar uma configuração do IBM DB2, é necessário seguir estas etapas:
- Planeje seu ambiente.
- Implante as VMs.
- Atualize o RHEL Linux e configure sistemas de arquivos.
- Instale e configure o Pacemaker.
- Configurar cluster glusterfs ou arquivos NetApp do Azure
- Instale o ASCS/ERS em um cluster separado.
- Instale o banco de dados IBM DB2 com a opção Distributed/High Availability (SWPM).
- Instale e crie um nó e uma instância de banco de dados secundários e configure o HADR.
- Confirme se o HADR está a funcionar.
- Aplique a configuração do Pacemaker para controlar o IBM DB2.
- Configure Azure Load Balancer.
- Instale servidores de aplicativos primários e de diálogo.
- Verifique e adapte a configuração dos servidores de aplicações SAP.
- Execute testes de failover e aquisição.
Planejar a infraestrutura do Azure para hospedar o IBM Db2 LUW com HADR
Conclua o processo de planejamento antes de executar a implantação. O planejamento cria a base para implantar uma configuração do DB2 com HADR no Azure. Os principais elementos que precisam fazer parte do planejamento do IMB Db2 LUW (parte do banco de dados do ambiente SAP) estão listados na tabela a seguir:
| Tópico | Breve descrição |
|---|---|
| Definir grupos de recursos do Azure | Grupos de recursos onde você implanta VM, rede virtual, Azure Load Balancer e outros recursos. Pode ser existente ou novo. |
| Definição de rede virtual / sub-rede | Onde VMs para IBM Db2 e Azure Load Balancer estão sendo implementadas. Pode ser existente ou recém-criado. |
| Máquinas virtuais que hospedam o IBM Db2 LUW | Tamanho da VM, armazenamento, rede, endereço IP. |
| Nome do host virtual e IP virtual para banco de dados IBM DB2 | O IP virtual ou nome de host é usado para conexão de servidores de aplicativos SAP. db-virt-hostname, db-virt-ip. |
| Esgrima do Azure | Método para evitar situações de divisão do cérebro é evitado. |
| Balanceador de Carga do Azure | Uso de Standard (recomendado), porta de sonda para banco de dados DB2 (nossa recomendação 62500) probe-port. |
| Resolução de nomes | Como funciona a resolução de nomes no ambiente. O serviço DNS é altamente recomendado. O arquivo de hosts locais pode ser usado. |
Para obter mais informações sobre o Linux Pacemaker no Azure, consulte Configurando o Pacemaker no Red Hat Enterprise Linux no Azure.
Importante
Para DB2 versões 11.5.6 e superiores, é altamente recomendável a solução integrada usando Pacemaker da IBM.
Implantação no Red Hat Enterprise Linux
O agente de recursos para IBM Db2 LUW está incluído no Red Hat Enterprise Linux Server HA Addon. Para a configuração descrita neste documento, você deve usar o Red Hat Enterprise Linux for SAP. O Azure Marketplace contém uma imagem para o Red Hat Enterprise Linux 7.4 for SAP ou superior que você pode usar para implantar novas máquinas virtuais do Azure. Esteja ciente dos vários modelos de suporte ou serviço oferecidos pela Red Hat por meio do Azure Marketplace ao escolher uma imagem de VM no Azure VM Marketplace.
Hosts: atualizações de DNS
Faça uma lista de todos os nomes de host, incluindo nomes de host virtual, e atualize seus servidores DNS para habilitar o endereço IP adequado para a resolução de nomes de host. Se um servidor DNS não existir ou você não puder atualizar e criar entradas DNS, será necessário usar os arquivos de host local das VMs individuais que estão participando desse cenário. Se você estiver usando entradas de arquivos host, certifique-se de que as entradas sejam aplicadas a todas as VMs no ambiente do sistema SAP. No entanto, recomendamos que você use seu DNS que, idealmente, se estende para o Azure
Implementação manual
Certifique-se de que o SO selecionado é suportado pelo IBM/SAP for IBM Db2 LUW. A lista de versões de SO suportadas para VMs do Azure e versões do DB2 está disponível na nota 1928533 do SAP. A lista de versões do SO por versão individual do DB2 está disponível na Matriz de disponibilidade de produtos SAP. É altamente recomendável um mínimo de Red Hat Enterprise Linux 7.4 for SAP devido às melhorias de desempenho relacionadas ao Azure nesta ou em versões posteriores do Red Hat Enterprise Linux.
- Crie ou selecione um grupo de recursos.
- Crie ou selecione uma rede virtual e uma sub-rede.
- Escolha um tipo de implementação adequado para máquinas virtuais SAP. Normalmente, um conjunto de dimensionamento de máquina virtual com orquestração flexível.
- Criar Máquina Virtual 1.
- Use a imagem do Red Hat Enterprise Linux for SAP no Azure Marketplace.
- Selecione o conjunto de escalas, a zona de disponibilidade ou o conjunto de disponibilidade criado na etapa 3.
- Criar Máquina Virtual 2.
- Use a imagem do Red Hat Enterprise Linux for SAP no Azure Marketplace.
- Selecione o conjunto de escalas, a zona de disponibilidade ou o conjunto de disponibilidade criado na etapa 3 (não a mesma zona da etapa 4).
- Adicione discos de dados às VMs e verifique a recomendação de uma configuração do sistema de arquivos no artigo IBM Db2 Azure Virtual Machines DBMS deployment for SAP workload.
Instale o ambiente IBM Db2 LUW e SAP
Antes de iniciar a instalação de um ambiente SAP baseado no IBM Db2 LUW, revise a seguinte documentação:
- Documentação do Azure.
- Documentação SAP.
- Documentação IBM.
Os links para esta documentação são fornecidos na seção introdutória deste artigo.
Consulte os manuais de instalação do SAP sobre como instalar aplicativos baseados em NetWeaver no IBM Db2 LUW. Você pode encontrar os guias no portal de Ajuda SAP usando o SAP Installation Guide Finder.
Você pode reduzir o número de guias exibidas no portal definindo os seguintes filtros:
- Quero: Instalar um novo sistema.
- Meu Banco de Dados: IBM Db2 para Linux, Unix e Windows.
- Filtros adicionais para versões do SAP NetWeaver, configuração de pilha ou sistema operacional.
Regras de firewall da Red Hat
O Red Hat Enterprise Linux tem firewall ativado por padrão.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Dicas de instalação para configurar o IBM Db2 LUW com HADR
Para configurar a instância primária do banco de dados IBM Db2 LUW:
- Use a opção de alta disponibilidade ou distribuída.
- Instale a instância SAP ASCS/ERS e Banco de dados.
- Faça um backup do banco de dados recém-instalado.
Importante
Anote a "Porta de comunicação do banco de dados" definida durante a instalação. Deve ser o mesmo número de porta para ambas as instâncias de banco de dados.
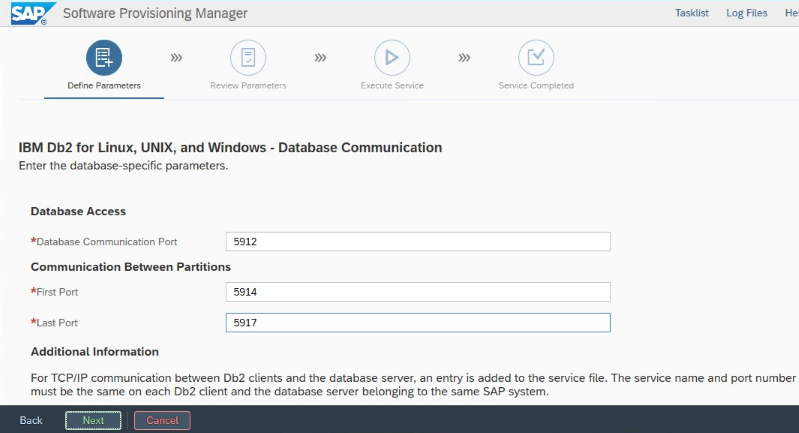
Configurações do IBM Db2 HADR para Azure
Quando você usa um agente de esgrima do Azure Pacemaker, defina os seguintes parâmetros:
- Duração da janela de pares HADR (segundos) (HADR_PEER_WINDOW) = 240
- Valor de tempo limite HADR (HADR_TIMEOUT) = 45
Recomendamos os parâmetros anteriores com base nos testes iniciais de failover/aquisição. É obrigatório que você teste a funcionalidade adequada de failover e aquisição com essas configurações de parâmetro. Como as configurações individuais podem variar, os parâmetros podem exigir ajustes.
Nota
Específico para IBM Db2 com configuração HADR com inicialização normal: A instância de banco de dados secundária ou em espera deve estar ativa e em execução antes que você possa iniciar a instância de banco de dados primária.
Nota
Para instalação e configuração específicas do Azure e do Pacemaker: Durante o procedimento de instalação por meio do SAP Software Provisioning Manager, há uma pergunta explícita sobre alta disponibilidade para o IBM Db2 LUW:
- Não selecione IBM Db2 pureScale.
- Não selecione Instalar IBM Tivoli System Automation for Multiplatforms.
- Não selecione Gerar arquivos de configuração de cluster.
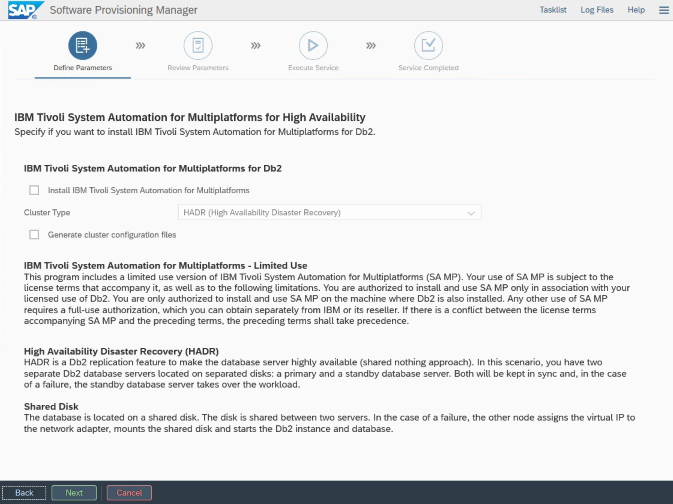
Para configurar o servidor de banco de dados em espera usando o procedimento de cópia homogênea do sistema SAP, execute estas etapas:
- Selecione a opção >Cópia do sistema Instância do banco de dados distribuído>dos sistemas>de destino.
- Como método de cópia, selecione Sistema homogêneo para que você possa usar o backup para restaurar um backup na instância do servidor em espera.
- Quando você chegar à etapa de saída para restaurar o banco de dados para cópia homogênea do sistema, saia do instalador. Restaure o banco de dados a partir de um backup do host primário. Todas as fases de instalação subsequentes já foram executadas no servidor de banco de dados primário.
Regras de firewall Red Hat para DB2 HADR
Adicione regras de firewall para permitir que o tráfego para o DB2 e entre o DB2 para HADR funcione:
- Porta de comunicação do banco de dados. Se estiver usando partições, adicione essas portas também.
- Porta HADR (valor do parâmetro DB2 HADR_LOCAL_SVC).
- Porta de sonda do Azure.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
Verificação do IBM Db2 HADR
Para fins de demonstração e os procedimentos descritos neste artigo, o SID do banco de dados é ID2.
Depois de configurar o HADR e o status for PEER e CONECTADO nos nós primário e em espera, execute a seguinte verificação:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Configurar o Balanceador de Carga do Azure
Durante a configuração da VM, você tem uma opção para criar ou selecionar o balanceador de carga de saída na seção de rede. Siga as etapas abaixo para configurar o balanceador de carga padrão para configuração de alta disponibilidade do banco de dados DB2.
Siga as etapas em Criar balanceador de carga para configurar um balanceador de carga padrão para um sistema SAP de alta disponibilidade usando o portal do Azure. Durante a configuração do balanceador de carga, considere os seguintes pontos:
- Configuração de IP Frontend: Crie um IP front-end. Selecione a mesma rede virtual e o mesmo nome de sub-rede que suas máquinas virtuais de banco de dados.
- Pool de back-end: crie um pool de back-end e adicione VMs de banco de dados.
- Regras de entrada: crie uma regra de balanceamento de carga. Siga as mesmas etapas para ambas as regras de balanceamento de carga.
- Endereço IP frontend: Selecione um IP front-end.
- Pool de back-end: selecione um pool de back-end.
- Portas de alta disponibilidade: selecione esta opção.
- Protocolo: Selecione TCP.
- Sonda de integridade: crie uma sonda de integridade com os seguintes detalhes:
- Protocolo: Selecione TCP.
- Porta: Por exemplo, 625<instância-não.>
- Intervalo: Digite 5.
- Limite da sonda: Digite 2.
- Tempo limite de inatividade (minutos): Digite 30.
- Ativar IP flutuante: selecione esta opção.
Nota
A propriedade numberOfProbesde configuração da sonda de integridade, também conhecida como Limite não íntegro no portal, não é respeitada. Para controlar o número de testes consecutivos bem-sucedidos ou com falha, defina a propriedade probeThreshold como 2. Atualmente, não é possível definir essa propriedade usando o portal do Azure, portanto, use a CLI do Azure ou o comando PowerShell.
Importante
O IP flutuante não é suportado em uma configuração de IP secundário da NIC em cenários de balanceamento de carga. Para obter mais informações, consulte Limitações do Balanceador de Carga do Azure. Se você precisar de outro endereço IP para a VM, implante uma segunda NIC.
Nota
Quando VMs sem endereços IP públicos são colocadas no pool de back-end de uma instância interna (sem endereço IP público) do Balanceador de Carga do Azure Padrão, não há conectividade de saída com a Internet, a menos que mais configuração seja executada para permitir o roteamento para pontos de extremidade públicos. Para obter mais informações sobre como obter conectividade de saída, consulte Conectividade de ponto de extremidade público para VMs usando o Azure Standard Load Balancer em cenários de alta disponibilidade SAP.
Importante
Não habilite carimbos de data/hora TCP em VMs do Azure colocadas atrás do Balanceador de Carga do Azure. Habilitar carimbos de data/hora TCP pode fazer com que os testes de integridade falhem. Defina o parâmetro net.ipv4.tcp_timestamps como 0. Para obter mais informações, consulte Sondas de integridade do balanceador de carga.
[A] Adicionar regra de firewall para porta de sonda:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Criar o cluster Pacemaker
Para criar um cluster Pacemaker básico para este servidor IBM DB2, consulte Configurando o Pacemaker no Red Hat Enterprise Linux no Azure.
Configuração do Pacemaker DB2
Ao usar o Pacemaker para failover automático no caso de uma falha de nó, você precisa configurar suas instâncias do DB2 e o Pacemaker de acordo. Esta seção descreve esse tipo de configuração.
Os seguintes itens são prefixados com:
- [A]: Aplicável a todos os nós
- [1]: Aplicável apenas ao nó 1
- [2]: Aplicável apenas ao nó 2
[A] Pré-requisito para a configuração do Pacemaker:
Desligue ambos os servidores de banco de dados com o usuário db2<sid> com db2stop.
Altere o ambiente de shell para db2<sid> user para /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Configuração do pacemaker
[1] Configuração do Pacemaker específica do IBM DB2 HADR:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Criar recursos IBM Db2:
Se estiver criando um cluster no RHEL 7.x, certifique-se de atualizar os agentes de recursos do pacote para a versão
resource-agents-4.1.1-61.el7_9.15ou superior. Use os seguintes comandos para criar os recursos do cluster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Se estiver criando um cluster no RHEL 8.x, certifique-se de atualizar os agentes de recursos do pacote para a versão
resource-agents-4.1.1-93.el8ou superior. Para obter detalhes, consulte Red Hat KBAdb2resource with HADR fails promote with statePRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Use os seguintes comandos para criar os recursos do cluster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Inicie os recursos do IBM Db2:
Coloque o Pacemaker fora do modo de manutenção.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Certifique-se de que o estado do cluster está OK e que todos os recursos foram iniciados. Não é importante em qual nó os recursos estão sendo executados.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Importante
Você deve gerenciar a instância Db2 clusterizada do Pacemaker usando as ferramentas do Pacemaker. Se você usar comandos db2, como db2stop, o Pacemaker detetará a ação como uma falha de recurso. Se estiver executando a manutenção, você pode colocar os nós ou recursos no modo de manutenção. O Pacemaker suspende os recursos de monitoramento e você pode usar comandos normais de administração do db2.
Fazer alterações nos perfis SAP para usar IP virtual para conexão
Para se conectar à instância primária da configuração HADR, a camada de aplicativo SAP precisa usar o endereço IP virtual que você definiu e configurou para o Balanceador de Carga do Azure. São necessárias as seguintes alterações:
/sapmnt/<SID>/profile/DEFAULT. PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
Instalar servidores de aplicativos primários e de diálogo
Ao instalar servidores de aplicativos primários e de diálogo em uma configuração do DB2 HADR, use o nome do host virtual escolhido para a configuração.
Se você executou a instalação antes de criar a configuração do DB2 HADR, faça as alterações conforme descrito na seção anterior e da seguinte forma para pilhas SAP Java.
Verificação de URL JDBC de sistemas ABAP+Java ou Java
Use a ferramenta J2EE Config para verificar ou atualizar a URL JDBC. Como a ferramenta J2EE Config é uma ferramenta gráfica, você precisa ter o servidor X instalado:
Entre no servidor de aplicativos primário da instância J2EE e execute:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shNo quadro esquerdo, escolha armazenamento de segurança.
No quadro certo, escolha a chave
jdbc/pool/\<SAPSID>/url.Altere o nome do host na URL JDBC para o nome do host virtual.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Selecione Adicionar.
Para salvar as alterações, selecione o ícone de disco no canto superior esquerdo.
Feche a ferramenta de configuração.
Reinicie a instância Java.
Configurar o arquivamento de logs para a configuração do HADR
Para configurar o arquivamento de log do DB2 para a configuração do HADR, recomendamos que você configure o banco de dados primário e o banco de dados em espera para ter capacidade de recuperação automática de log de todos os locais de arquivamento de log. O banco de dados primário e o banco de dados em espera devem ser capazes de recuperar arquivos de log de todos os locais de arquivamento de log para os quais qualquer uma das instâncias de banco de dados pode arquivar arquivos de log.
O arquivamento de logs é executado somente pelo banco de dados primário. Se você alterar as funções HADR dos servidores de banco de dados ou se ocorrer uma falha, o novo banco de dados primário será responsável pelo arquivamento de logs. Se você configurou vários locais de arquivamento de logs, seus logs podem ser arquivados duas vezes. No caso de uma recuperação local ou remota, também pode ser necessário copiar manualmente os logs arquivados do servidor primário antigo para o local de log ativo do novo servidor primário.
Recomendamos configurar um compartilhamento NFS comum ou GlusterFS, onde os logs são gravados de ambos os nós. A partilha NFS ou GlusterFS tem de estar altamente disponível.
Você pode usar compartilhamentos NFS altamente disponíveis existentes ou GlusterFS para transportes ou um diretório de perfil. Para obter mais informações, consulte:
- GlusterFS em VMs do Azure no Red Hat Enterprise Linux for SAP NetWeaver.
- Alta disponibilidade para SAP NetWeaver em VMs do Azure no Red Hat Enterprise Linux com Azure NetApp Files for SAP Applications.
- Arquivos NetApp do Azure (para criar compartilhamentos NFS).
Testar a configuração do cluster
Esta seção descreve como você pode testar sua configuração do DB2 HADR. Cada teste pressupõe que o IBM Db2 primary está sendo executado na máquina virtual az-idb01 . Usuário com privilégios sudo ou root (não recomendado) deve ser usado.
O status inicial para todos os casos de teste é explicado aqui: (crm_mon -r ou pcs status)
- O status do pcs é um instantâneo do status do Pacemaker no momento da execução.
- crm_mon -r é a saída contínua do status do marcapasso.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
O status original em um sistema SAP está documentado em Transaction DBACOCKPIT > Configuration > Overview, conforme mostrado na imagem a seguir:
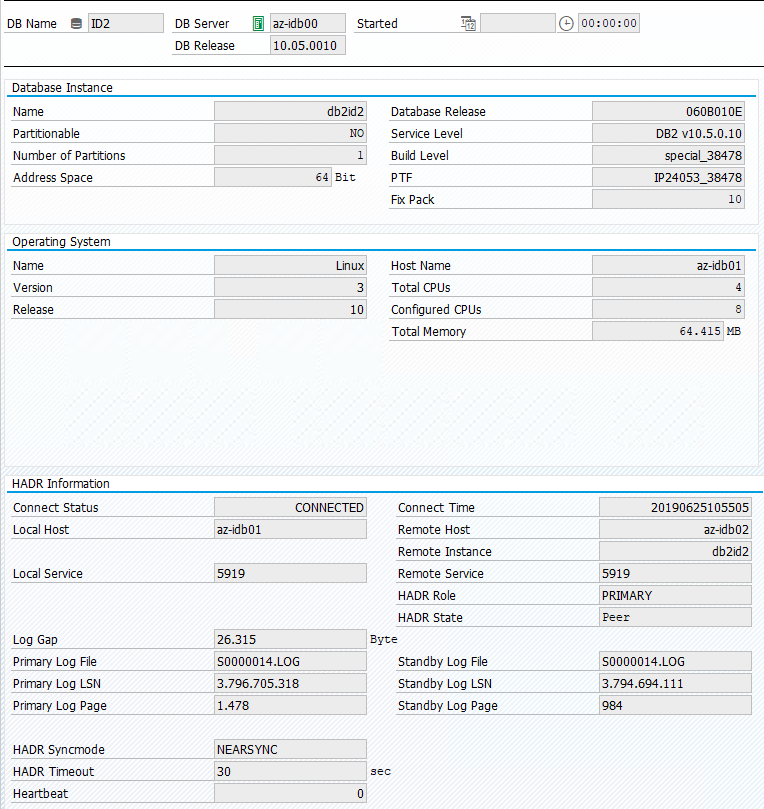
Aquisição de teste do IBM DB2
Importante
Antes de iniciar o teste, certifique-se de que:
Pacemaker não tem nenhuma ação falhada (status pcs).
Não há restrições de localização (sobras do teste de migração).
A sincronização do IBM Db2 HADR está funcionando. Verifique com o usuário db2<sid>.
db2pd -hadr -db <DBSID>
Migre o nó que está executando o banco de dados DB2 primário executando o seguinte comando:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Depois que a migração for concluída, a saída de status do crm terá a seguinte aparência:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
O status original em um sistema SAP está documentado em Transaction DBACOCKPIT > Configuration > Overview, conforme mostrado na imagem a seguir:
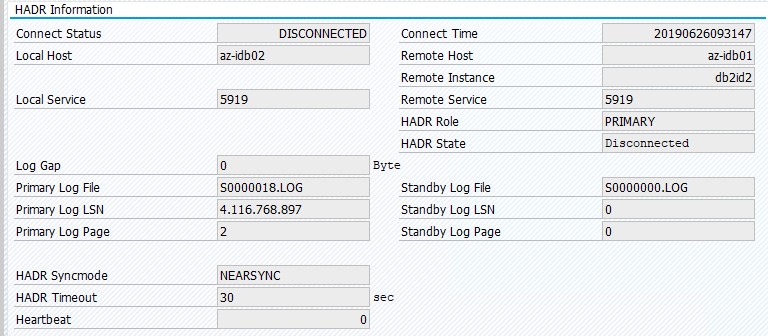
A migração de recursos com "pcs resource move" cria restrições de localização. As restrições de localização, neste caso, estão impedindo a execução da instância IBM Db2 no az-idb01. Se as restrições de local não forem excluídas, o recurso não poderá fazer failback.
Remova a restrição de localização e o nó de espera seria iniciado em az-idb01.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
E o status do cluster muda para:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
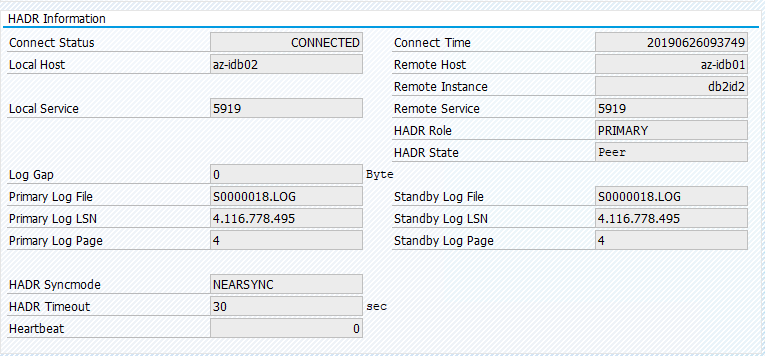
Migre o recurso de volta para az-idb01 e limpe as restrições de local
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- No RHEL 7.x -
pcs resource move <resource_name> <host>: Cria restrições de localização e pode causar problemas com a aquisição - No RHEL 8.x -
pcs resource move <resource_name> --master: Cria restrições de localização e pode causar problemas com a aquisição pcs resource clear <resource_name>: Limpa restrições de localizaçãopcs resource cleanup <resource_name>: Limpa todos os erros do recurso
Testar uma aquisição manual
Você pode testar uma aquisição manual interrompendo o serviço Pacemaker no nó az-idb01 :
systemctl stop pacemaker
Status em AZ-IBDB02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Após o failover, você pode iniciar o serviço novamente em az-idb01.
systemctl start pacemaker
Matar o processo DB2 no nó que executa o banco de dados primário HADR
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
A instância do DB2 falhará e o Pacemaker moverá o nó mestre e relatará o seguinte status:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
O Pacemaker reinicia a instância do banco de dados primário DB2 no mesmo nó ou faz failover para o nó que está executando a instância secundária do banco de dados e um erro é relatado.
Mate o processo DB2 no nó que executa a instância secundária do banco de dados
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
O nó entra em falha declarada e erro relatado.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
A instância do DB2 é reiniciada na função secundária atribuída anteriormente.
Pare o banco de dados via força db2stop no nó que executa a instância do banco de dados primário HADR
Como usuário db2<sid> execute command db2stop force:
az-idb01:db2ptr> db2stop force
Falha detetada:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
A instância de banco de dados secundária do Db2 HADR foi promovida para a função principal.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Travar a VM que executa a instância do banco de dados primário HADR com "parar"
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
Nesse caso, o Pacemaker deteta que o nó que está executando a instância do banco de dados primário não está respondendo.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
O próximo passo é verificar se há uma situação cerebral dividida. Depois que o nó sobrevivente determinar que o nó que executou pela última vez a instância do banco de dados primário está inativo, um failover de recursos é executado.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
No caso de um pânico no kernel, o nó com falha será reiniciado pelo agente de esgrima. Depois que o nó com falha estiver online novamente, você deve iniciar o cluster de marcapasso por
sudo pcs cluster start
ele inicia a instância do DB2 na função secundária.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02