Considerações sobre a plataforma de aplicativos para cargas de trabalho de missão crítica no Azure
O Azure fornece muitos serviços de computação para hospedar aplicativos altamente disponíveis. Os serviços diferem em capacidade e complexidade. Recomendamos que escolha os serviços com base em:
- Requisitos não funcionais de confiabilidade, disponibilidade, desempenho e segurança.
- Fatores de decisão como escalabilidade, custo, operabilidade e complexidade.
A escolha de uma plataforma de hospedagem de aplicativos é uma decisão crítica que afeta todas as outras áreas de design. Por exemplo, o software de desenvolvimento legado ou proprietário pode não ser executado em serviços PaaS ou aplicativos em contêineres. Essa limitação influenciaria sua escolha da plataforma de computação.
Um aplicativo de missão crítica pode usar mais de um serviço de computação para dar suporte a várias cargas de trabalho compostas e microsserviços, cada um com requisitos distintos.
Esta área de design fornece recomendações relacionadas à seleção de computação, design e opções de configuração. Também recomendamos que você se familiarize com a árvore de decisão de computação.
Importante
Este artigo faz parte da série de carga de trabalho de missão crítica do Azure Well-Architected Framework. Se você não está familiarizado com esta série, recomendamos que comece com O que é uma carga de trabalho de missão crítica?.
Distribuição global dos recursos da plataforma
Um padrão típico para uma carga de trabalho de missão crítica inclui recursos globais e recursos regionais.
Os serviços do Azure, que não estão restritos a uma região específica do Azure, são implantados ou configurados como recursos globais. Alguns casos de uso incluem a distribuição de tráfego em várias regiões, o armazenamento de estado permanente para um aplicativo inteiro e o armazenamento em cache de dados estáticos globais. Se você precisar acomodar uma arquitetura de unidade de escala e uma distribuição global, considere como os recursos são distribuídos ou replicados de forma ideal entre as regiões do Azure.
Outros recursos são implantados regionalmente. Esses recursos, que são implantados como parte de um carimbo de implantação, normalmente correspondem a uma unidade de escala. No entanto, uma região pode ter mais de um carimbo, e um carimbo pode ter mais de uma unidade. A confiabilidade dos recursos regionais é crucial porque eles são responsáveis pela execução da carga de trabalho principal.
A imagem a seguir mostra o design de alto nível. Um usuário acessa o aplicativo por meio de um ponto de entrada global central que, em seguida, redireciona as solicitações para um carimbo de implantação regional adequado:
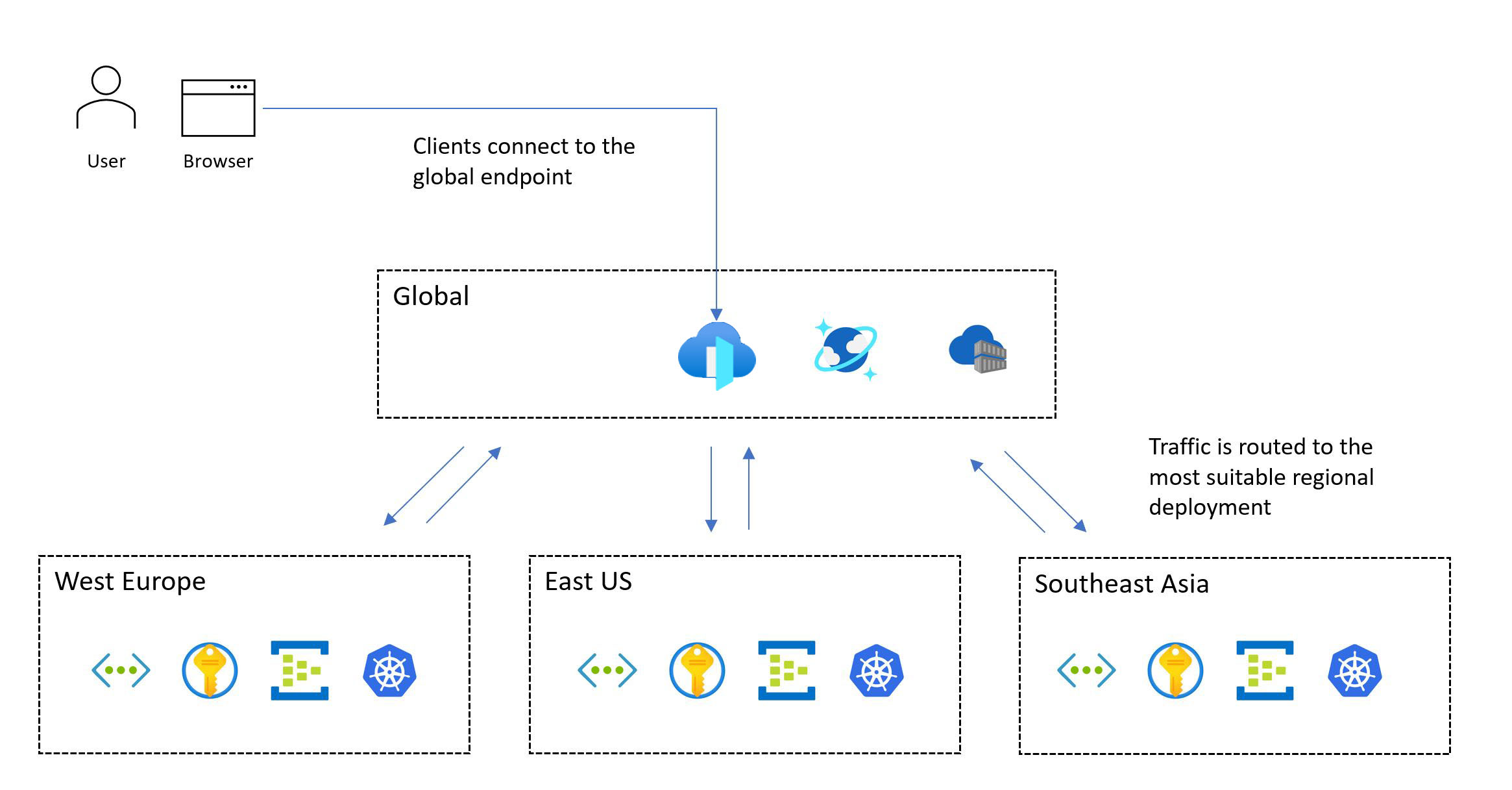
A metodologia de projeto de missão crítica requer uma implantação em várias regiões. Esse modelo garante tolerância a falhas regionais, para que o aplicativo permaneça disponível mesmo quando uma região inteira fica inativa. Ao projetar um aplicativo de várias regiões, considere diferentes estratégias de implantação, como ativo/ativo e ativo/passivo, juntamente com os requisitos do aplicativo, pois há compensações significativas para cada abordagem. Para cargas de trabalho de missão crítica, recomendamos vivamente o modelo ativo/ativo.
Nem toda carga de trabalho suporta ou requer a execução de várias regiões simultaneamente. Você deve ponderar os requisitos específicos do aplicativo em relação às compensações para determinar uma decisão de projeto ideal. Para determinados cenários de aplicação com metas de confiabilidade mais baixas, ativo/passivo ou fragmentação podem ser alternativas adequadas.
As zonas de disponibilidade podem fornecer implantações regionais altamente disponíveis em diferentes datacenters dentro de uma região. Quase todos os serviços do Azure estão disponíveis em uma configuração zonal, em que o serviço é delegado a uma zona específica, ou em uma configuração redundante de zona, em que a plataforma garante automaticamente que o serviço se estenda por zonas e possa resistir a uma interrupção de zona. Essas configurações fornecem tolerância a falhas até o nível do datacenter.
Considerações de design
Capacidades regionais e zonais. Nem todos os serviços e recursos estão disponíveis em todas as regiões do Azure. Essa consideração pode afetar as regiões escolhidas. Além disso, as zonas de disponibilidade não estão disponíveis em todas as regiões.
Pares regionais. As regiões do Azure são agrupadas em pares regionais que consistem em duas regiões em uma única geografia. Alguns serviços do Azure usam regiões emparelhadas para garantir a continuidade dos negócios e fornecer um nível de proteção contra perda de dados. Por exemplo, o armazenamento com redundância geográfica (GRS) do Azure replica dados para uma região emparelhada secundária automaticamente, garantindo que os dados sejam duráveis se a região primária não for recuperável. Se uma interrupção afetar várias regiões do Azure, pelo menos uma região em cada par será priorizada para recuperação.
Consistência dos dados. Para desafios de consistência, considere o uso de um armazenamento de dados distribuído globalmente, uma arquitetura regional carimbada e uma implantação parcialmente ativa/ativa. Em uma implantação parcial, alguns componentes estão ativos em todas as regiões, enquanto outros estão localizados centralmente na região primária.
Implantação segura. A estrutura SDP (prática de implantação segura) do Azure garante que todas as alterações de código e configuração (manutenção planejada) na plataforma Azure passem por uma distribuição em fases. A saúde é analisada quanto à degradação durante a liberação. Após a conclusão bem-sucedida das fases canário e piloto, as atualizações da plataforma são serializadas em pares regionais, portanto, apenas uma região em cada par é atualizada em um determinado momento.
Capacidade da plataforma. Como qualquer provedor de nuvem, o Azure tem recursos finitos. A indisponibilidade pode ser o resultado de limitações de capacidade nas regiões. Se houver uma interrupção regional, haverá um aumento na demanda por recursos à medida que a carga de trabalho tenta se recuperar dentro da região emparelhada. A interrupção pode criar um problema de capacidade, onde a oferta temporariamente não atende à demanda.
Recomendações de design
Implante sua solução em pelo menos duas regiões do Azure para ajudar a proteger contra interrupções regionais. Implante-o em regiões que tenham os recursos e características que a carga de trabalho exige. Os recursos devem atender às metas de desempenho e disponibilidade e, ao mesmo tempo, cumprir os requisitos de residência e retenção de dados.
Por exemplo, alguns requisitos de conformidade de dados podem restringir o número de regiões disponíveis e potencialmente forçar comprometimentos de projeto. Nesses casos, recomendamos que você adicione investimento extra em wrappers operacionais para prever, detetar e responder a falhas. Suponha que você esteja restrito a uma geografia com duas regiões e apenas uma dessas regiões ofereça suporte a zonas de disponibilidade (modelo de datacenter 3 + 1). Crie um padrão de implantação secundário usando o isolamento de domínio de falha para permitir que ambas as regiões sejam implantadas em uma configuração ativa e garantir que a região primária hospede vários carimbos de implantação.
Se as regiões adequadas do Azure não oferecerem todos os recursos de que você precisa, esteja preparado para comprometer a consistência dos selos de implantação regional para priorizar a distribuição geográfica e maximizar a confiabilidade. Se apenas uma única região do Azure for adequada, implante vários carimbos de implantação (unidades de escala regional) na região selecionada para reduzir alguns riscos e use zonas de disponibilidade para fornecer tolerância a falhas no nível do datacenter. No entanto, um compromisso tão significativo na distribuição geográfica restringe drasticamente o SLO composto alcançável e a confiabilidade geral.
Importante
Para cenários destinados a um SLO maior ou igual a 99,99%, recomendamos um mínimo de três regiões de implantação. Calcule o SLO composto para todos os fluxos de usuário. Certifique-se de que essas metas estejam alinhadas com as metas de negócios.
Para cenários de aplicativos de alta escala com volumes significativos de tráfego, projete a solução para ser dimensionada em várias regiões para navegar por possíveis restrições de capacidade em uma única região. Carimbos de implantação regionais adicionais podem alcançar um SLO composto mais alto. Para obter mais informações, consulte como implementar destinos multirregionais.
Defina e valide seus RPOs (Recovery Point Objetives, objetivos de ponto de recuperação) e RTOs (Recovery Time Objetives, objetivos de tempo de recuperação).
Dentro de uma única geografia, priorize o uso de pares regionais para se beneficiar de distribuições serializadas SDP para manutenção planejada e priorização regional para manutenção não planejada.
Colocalize geograficamente os recursos do Azure com os usuários para minimizar a latência da rede e maximizar o desempenho de ponta a ponta.
- Você também pode usar soluções como uma Rede de Distribuição de Conteúdo (CDN) ou cache de borda para direcionar a latência de rede ideal para bases de usuários distribuídos. Para obter mais informações, consulte Roteamento de tráfego global, Serviços de entrega de aplicativos e Armazenamento em cache e entrega de conteúdo estático.
Alinhe a disponibilidade atual do serviço com os roteiros do produto ao escolher regiões de implantação. Alguns serviços podem não estar imediatamente disponíveis em todas as regiões.
Contentorização
Um contêiner inclui o código do aplicativo e os arquivos de configuração, bibliotecas e dependências relacionados que o aplicativo precisa executar. A conteinerização fornece uma camada de abstração para o código do aplicativo e suas dependências e cria separação da plataforma de hospedagem subjacente. O pacote de software único é altamente portátil e pode ser executado de forma consistente em várias plataformas de infraestrutura e provedores de nuvem. Os desenvolvedores não precisam reescrever o código e podem implantar aplicativos de forma mais rápida e confiável.
Importante
Recomendamos que você use contêineres para pacotes de aplicativos de missão crítica. Eles melhoram a utilização da infraestrutura porque você pode hospedar vários contêineres na mesma infraestrutura virtualizada. Além disso, como todo o software está incluído no contêiner, você pode mover o aplicativo entre vários sistemas operacionais, independentemente dos tempos de execução ou das versões da biblioteca. O gerenciamento também é mais fácil com contêineres do que com hospedagem virtualizada tradicional.
Os aplicativos de missão crítica precisam ser dimensionados rapidamente para evitar gargalos de desempenho. Como as imagens de contêiner são pré-criadas, você pode limitar a inicialização para ocorrer somente durante a inicialização do aplicativo, o que fornece escalabilidade rápida.
Considerações de design
Monitorização. Pode ser difícil para os serviços de monitoramento acessar aplicativos que estão em contêineres. Normalmente, você precisa de software de terceiros para coletar e armazenar indicadores de estado do contêiner, como o uso de CPU ou RAM.
Segurança. O kernel do sistema operacional da plataforma de hospedagem é compartilhado em vários contêineres, criando um único ponto de ataque. No entanto, o risco de acesso à máquina virtual (VM) do host é limitado porque os contêineres são isolados do sistema operacional subjacente.
Estado. Embora seja possível armazenar dados no sistema de arquivos de um contêiner em execução, os dados não persistirão quando o contêiner for recriado. Em vez disso, persista os dados montando armazenamento externo ou usando um banco de dados externo.
Recomendações de design
Contentor de todos os componentes da aplicação. Use imagens de contêiner como o modelo principal para pacotes de implantação de aplicativos.
Priorize tempos de execução de contêiner baseados em Linux quando possível. As imagens são mais leves, e novos recursos para nós/contêineres Linux são lançados com frequência.
Torne os contentores imutáveis e substituíveis, com ciclos de vida curtos.
Certifique-se de reunir todos os logs e métricas relevantes do contêiner, do host do contêiner e do cluster subjacente. Envie os logs e métricas coletados para um coletor de dados unificado para processamento e análise adicionais.
Armazene imagens de contêiner no Registro de Contêiner do Azure. Use a replicação geográfica para replicar imagens de contêiner em todas as regiões. Habilite o Microsoft Defender para registros de contêiner para fornecer verificação de vulnerabilidade para imagens de contêiner. Certifique-se de que o acesso ao registo é gerido pelo Microsoft Entra ID.
Hospedagem e orquestração de contêineres
Várias plataformas de aplicativos do Azure podem efetivamente hospedar contêineres. Existem vantagens e desvantagens associadas a cada uma destas plataformas. Compare as opções no contexto dos seus requisitos de negócios. No entanto, sempre otimize a confiabilidade, a escalabilidade e o desempenho. Para mais informações, consulte estes artigos:
Importante
O Serviço Kubernetes do Azure (AKS) e os Aplicativos de Contêiner do Azure devem estar entre suas primeiras opções para gerenciamento de contêineres, dependendo de suas necessidades. Embora o Serviço de Aplicativo do Azure não seja um orquestrador, como uma plataforma de contêiner de baixo atrito, ainda é uma alternativa viável ao AKS.
Considerações de design e recomendações para o Serviço Kubernetes do Azure
O AKS, um serviço Kubernetes gerenciado, permite o provisionamento rápido de clusters sem exigir atividades complexas de administração de cluster e oferece um conjunto de recursos que inclui recursos avançados de rede e identidade. Para obter um conjunto completo de recomendações, consulte Revisão do Azure Well-Architected Framework - AKS.
Importante
Há algumas decisões de configuração fundamentais que você não pode alterar sem reimplantar o cluster AKS. Os exemplos incluem a escolha entre clusters AKS públicos e privados, habilitando a Política de Rede do Azure, a integração do Microsoft Entra e o uso de identidades gerenciadas para AKS em vez de entidades de serviço.
Fiabilidade
O AKS gerencia o plano de controle nativo do Kubernetes. Se o plano de controle não estiver disponível, a carga de trabalho enfrentará tempo de inatividade. Aproveite os recursos de confiabilidade oferecidos pelo AKS:
Implante clusters AKS em diferentes regiões do Azure como uma unidade de escala para maximizar a confiabilidade e a disponibilidade. Use zonas de disponibilidade para maximizar a resiliência em uma região do Azure distribuindo o plano de controle AKS e os nós do agente em datacenters fisicamente separados. No entanto, se a latência de colocation for um problema, você pode fazer a implantação do AKS em uma única zona ou usar grupos de posicionamento de proximidade para minimizar a latência do internode.
Use o SLA de tempo de atividade do AKS para clusters de produção para maximizar as garantias de disponibilidade de endpoint da API do Kubernetes.
Escalabilidade
Leve em consideração os limites de escala do AKS, como o número de nós, pools de nós por cluster e clusters por assinatura.
Se os limites de escala forem uma restrição, aproveite a estratégia de unidade de escala e implante mais unidades com clusters.
Habilite o autoscaler de cluster para ajustar automaticamente o número de nós de agente em resposta a restrições de recursos.
Use o autoscaler de pod horizontal para ajustar o número de pods em uma implantação com base na utilização da CPU ou em outras métricas.
Para cenários de alta escala e intermitência, considere o uso de nós virtuais para escala extensa e rápida.
Defina solicitações de recursos de pod e limites em manifestos de implantação de aplicativos. Se não o fizer, poderá ter problemas de desempenho.
Isolamento
Mantenha limites entre a infraestrutura usada pela carga de trabalho e as ferramentas do sistema. O compartilhamento de infraestrutura pode levar a uma alta utilização de recursos e cenários vizinhos barulhentos.
Use pools de nós separados para serviços de sistema e carga de trabalho. Os pools de nós dedicados para componentes de carga de trabalho devem ser baseados em requisitos para recursos de infraestrutura especializados, como VMs de GPU de alta memória. Em geral, para reduzir a sobrecarga de gerenciamento desnecessária, evite implantar um grande número de pools de nós.
Use manchas e tolerâncias para fornecer nós dedicados e limitar aplicativos que consomem muitos recursos.
Avalie os requisitos de afinidade e antiafinidade do aplicativo e configure a colocalização apropriada de contêineres nos nós.
Segurança
O Kubernetes baunilha padrão requer uma configuração significativa para garantir uma postura de segurança adequada para cenários de missão crítica. O AKS aborda vários riscos de segurança imediatamente. Os recursos incluem clusters privados, auditoria e login no Log Analytics, imagens de nó reforçadas e identidades gerenciadas.
Aplique as orientações de configuração fornecidas na linha de base de segurança do AKS.
Use os recursos do AKS para lidar com o gerenciamento de identidade e acesso do cluster para reduzir a sobrecarga operacional e aplicar um gerenciamento de acesso consistente.
Use identidades gerenciadas em vez de entidades de serviço para evitar o gerenciamento e a rotação de credenciais. Você pode adicionar identidades gerenciadas no nível do cluster. No nível do pod, você pode usar identidades gerenciadas por meio do ID de carga de trabalho do Microsoft Entra.
Use a integração do Microsoft Entra para gerenciamento centralizado de contas e senhas, gerenciamento de acesso a aplicativos e proteção de identidade aprimorada. Use o Kubernetes RBAC com o Microsoft Entra ID para obter privilégios mínimos e minimize a concessão de privilégios de administrador para ajudar a proteger a configuração e o acesso a segredos. Além disso, limite o acesso ao arquivo de configuração de cluster do Kubernetes usando o controle de acesso baseado em função do Azure. Limite o acesso a ações que os contêineres podem executar, forneça o menor número de permissões e evite o uso de escalonamento de privilégios raiz.
Atualizações
Clusters e nós precisam ser atualizados regularmente. O AKS suporta versões do Kubernetes em alinhamento com o ciclo de lançamento do Kubernetes nativo.
Assine o roteiro público do AKS e as notas de lançamento no GitHub para se manter atualizado sobre as próximas mudanças, melhorias e, mais importante, lançamentos e descontinuações da versão do Kubernetes.
Aplique as orientações fornecidas na lista de verificação do AKS para garantir o alinhamento com as melhores práticas.
Esteja ciente dos vários métodos suportados pelo AKS para atualizar nós e/ou clusters. Estes métodos podem ser manuais ou automatizados. Você pode usar a Manutenção Planejada para definir janelas de manutenção para essas operações. Novas imagens são divulgadas semanalmente. O AKS também suporta canais de atualização automática para atualizar automaticamente clusters AKS para versões mais recentes do Kubernetes e/ou imagens de nó mais recentes quando estiverem disponíveis.
Rede
Avalie os plugins de rede que melhor se adaptam ao seu caso de uso. Determine se você precisa de controle granular do tráfego entre pods. O Azure suporta kubenet, Azure CNI e traga a sua própria CNI para casos de utilização específicos.
Priorize o uso do Azure CNI depois de avaliar os requisitos de rede e o tamanho do cluster. O Azure CNI permite o uso de políticas de rede do Azure ou do Calico para controlar o tráfego dentro do cluster.
Monitorização
Suas ferramentas de monitoramento devem ser capazes de capturar logs e métricas de pods em execução. Você também deve coletar informações da API de métricas do Kubernetes para monitorar a integridade de recursos e cargas de trabalho em execução.
Use o Azure Monitor e o Application Insights para coletar métricas, logs e diagnósticos dos recursos do AKS para solução de problemas.
Habilite e revise os logs de recursos do Kubernetes.
Configure as métricas do Prometheus no Azure Monitor. O Container insights no Monitor fornece integração, permite recursos de monitoramento prontos para uso e habilita recursos mais avançados por meio do suporte integrado ao Prometheus.
Governação
Use políticas para aplicar salvaguardas centralizadas a clusters AKS de forma consistente. Aplique atribuições de política em um escopo de assinatura ou superior para aumentar a consistência entre as equipes de desenvolvimento.
Controle quais funções são concedidas aos pods e se a execução contradiz a política usando a Política do Azure. Esse acesso é definido por meio de políticas internas fornecidas pelo Complemento de Política do Azure para AKS.
Estabeleça uma linha de base de confiabilidade e segurança consistente para configurações de cluster e pod AKS usando a Política do Azure.
Use o Complemento de Política do Azure para AKS para controlar funções de pod, como privilégios de root, e para não permitir pods que não estejam em conformidade com a política.
Nota
Quando você implanta em uma zona de aterrissagem do Azure, as políticas do Azure para ajudá-lo a garantir confiabilidade e segurança consistentes devem ser fornecidas pela implementação da zona de aterrissagem.
As implementações de referência de missão crítica fornecem um conjunto de políticas de linha de base para impulsionar a confiabilidade e as configurações de segurança recomendadas.
Considerações de design e recomendações para o Serviço de Aplicativo do Azure
Para cenários de carga de trabalho baseados na Web e em API, o Serviço de Aplicativo pode ser uma alternativa viável ao AKS. Ele fornece uma plataforma de contêiner de baixo atrito sem a complexidade do Kubernetes. Para obter um conjunto completo de recomendações, consulte Considerações sobre confiabilidade para o Serviço de Aplicativo e Excelência operacional para o Serviço de Aplicativo.
Fiabilidade
Avalie o uso de portas TCP e SNAT. As conexões TCP são usadas para todas as conexões de saída. As portas SNAT são usadas para conexões de saída para endereços IP públicos. A exaustão da porta SNAT é um cenário de falha comum. Você deve detetar previsivelmente esse problema testando a carga ao usar o Diagnóstico do Azure para monitorar portas. Se ocorrerem erros de SNAT, você precisará dimensionar mais ou mais trabalhadores ou implementar práticas de codificação para ajudar a preservar e reutilizar portas SNAT. Exemplos de práticas de codificação que você pode usar incluem o pool de conexões e o carregamento lento de recursos.
O esgotamento da porta TCP é outro cenário de falha. Ocorre quando a soma das conexões de saída de um determinado trabalhador excede a capacidade. O número de portas TCP disponíveis depende do tamanho do trabalhador. Para obter recomendações, consulte Portas TCP e SNAT.
Escalabilidade
Planeje futuros requisitos de escalabilidade e crescimento de aplicativos para que você possa aplicar as recomendações apropriadas desde o início. Ao fazer isso, você pode evitar dívidas de migração técnica à medida que a solução cresce.
Habilite o dimensionamento automático para garantir que os recursos adequados estejam disponíveis para solicitações de serviço. Avalie o dimensionamento por aplicativo para hospedagem de alta densidade no Serviço de Aplicativo.
Lembre-se de que o Serviço de Aplicativo tem um limite flexível padrão de instâncias por plano do Serviço de Aplicativo.
Aplique regras de dimensionamento automático. Um plano do Serviço de Aplicativo é dimensionado se qualquer regra dentro do perfil for atendida, mas só será dimensionado se todas as regras dentro do perfil forem atendidas. Use uma combinação de regras de expansão e expansão para garantir que o dimensionamento automático possa agir tanto para expandir quanto para aumentar a escala. Entenda o comportamento de várias regras de dimensionamento em um único perfil.
Lembre-se de que você pode habilitar o dimensionamento por aplicativo no nível do plano do Serviço de Aplicativo para permitir que um aplicativo seja dimensionado independentemente do plano do Serviço de Aplicativo que o hospeda. Os aplicativos são alocados aos nós disponíveis por meio de uma abordagem de melhor esforço para uma distribuição uniforme. Embora uma distribuição uniforme não seja garantida, a plataforma garante que duas instâncias do mesmo aplicativo não sejam hospedadas na mesma instância.
Monitorização
Monitore o comportamento do aplicativo e obtenha acesso a logs e métricas relevantes para garantir que seu aplicativo funcione conforme o esperado.
Você pode usar o log de diagnóstico para ingerir logs no nível do aplicativo e da plataforma no Log Analytics, no Armazenamento do Azure ou em uma ferramenta de terceiros por meio dos Hubs de Eventos do Azure.
O monitoramento de desempenho de aplicativos com o Application Insights fornece informações detalhadas sobre o desempenho de aplicativos.
Os aplicativos de missão crítica devem ter a capacidade de autorrecuperação se houver falhas. Habilite o Auto Heal para reciclar automaticamente trabalhadores insalubres.
Você precisa usar verificações de integridade apropriadas para avaliar todas as dependências críticas a jusante, o que ajuda a garantir a integridade geral. É altamente recomendável que você habilite a Verificação de integridade para identificar trabalhadores que não respondem.
Implementação
Para contornar o limite padrão de instâncias por plano do Serviço de Aplicativo, implante planos do Serviço de Aplicativo em várias unidades de escala em uma única região. Implante planos do Serviço de Aplicativo em uma configuração de zona de disponibilidade para garantir que os nós de trabalho sejam distribuídos entre zonas dentro de uma região. Considere abrir um tíquete de suporte para aumentar o número máximo de trabalhadores para o dobro da contagem de instâncias necessária para atender à carga de pico normal.
Registo de contentor
Os registros de contêiner hospedam imagens que são implantadas em ambientes de tempo de execução de contêiner, como o AKS. Você precisa configurar seus registros de contêiner para cargas de trabalho de missão crítica com cuidado. Uma interrupção não deve causar atrasos na extração de imagens, especialmente durante as operações de dimensionamento. As considerações e recomendações a seguir se concentram no Registro de Contêiner do Azure e exploram as compensações associadas a modelos de implantação centralizados e federados.
Considerações de design
Formato. Considere o uso de um registro de contêiner que dependa do formato e dos padrões fornecidos pelo Docker para operações push e pull. Estas soluções são compatíveis e, na sua maioria, intercambiáveis.
Modelo de implementação. Você pode implantar o registro de contêiner como um serviço centralizado que é consumido por vários aplicativos em sua organização. Ou você pode implantá-lo como um componente dedicado para uma carga de trabalho de aplicativo específica.
Registos públicos. As imagens de contêiner são armazenadas no Docker Hub ou em outros registros públicos que existem fora do Azure e de uma determinada rede virtual. Isso não é necessariamente um problema, mas pode levar a vários problemas relacionados à disponibilidade do serviço, limitação e exfiltração de dados. Para alguns cenários de aplicativo, você precisa replicar imagens de contêiner público em um registro de contêiner privado para limitar o tráfego de saída, aumentar a disponibilidade ou evitar possíveis limitações.
Recomendações de design
Use instâncias de registro de contêiner dedicadas à carga de trabalho do aplicativo. Evite criar uma dependência de um serviço centralizado, a menos que os requisitos de disponibilidade e confiabilidade organizacionais estejam totalmente alinhados com o aplicativo.
No padrão de arquitetura principal recomendado, os registros de contêiner são recursos globais de longa duração. Considere o uso de um único registro de contêiner global por ambiente. Por exemplo, use um registro de produção global.
Certifique-se de que o SLA para registro público esteja alinhado com suas metas de confiabilidade e segurança. Tome nota especial dos limites de limitação para casos de uso que dependem do Docker Hub.
Priorize o Registro de Contêiner do Azure para hospedar imagens de contêiner.
Considerações de design e recomendações para o Registro de Contêiner do Azure
Esse serviço nativo fornece uma variedade de recursos, incluindo replicação geográfica, autenticação do Microsoft Entra, criação automatizada de contêineres e aplicação de patches por meio de tarefas do Registro de Contêiner.
Fiabilidade
Configure a replicação geográfica para todas as regiões de implantação para remover dependências regionais e otimizar a latência. O Registro de Contêiner oferece suporte à alta disponibilidade por meio da replicação geográfica para várias regiões configuradas, fornecendo resiliência contra interrupções regionais. Se uma região ficar indisponível, as outras regiões continuarão a atender solicitações de imagem. Quando a região está online novamente, o Registro de Contêiner recupera e replica as alterações nela. Esse recurso também fornece colocation de registro dentro de cada região configurada, reduzindo a latência da rede e os custos de transferência de dados entre regiões.
Em regiões do Azure que fornecem suporte à zona de disponibilidade, a camada do Registro de Contêiner Premium dá suporte à redundância de zona para fornecer proteção contra falha zonal. A camada Premium também suporta pontos de extremidade privados para ajudar a impedir o acesso não autorizado ao registro, o que pode levar a problemas de confiabilidade.
Hospede imagens próximas aos recursos de computação que consomem energia, dentro das mesmas regiões do Azure.
Bloqueio de imagem
As imagens podem ser apagadas, como resultado, por exemplo, de erro manual. O Registro de Contêiner suporta o bloqueio de uma versão de imagem ou de um repositório para evitar alterações ou exclusões. Quando uma versão de imagem implantada anteriormente é alterada, implantações de mesma versão podem fornecer resultados diferentes antes e depois da alteração.
Se você quiser proteger a instância do Registro de Contêiner contra exclusão, use bloqueios de recursos.
Imagens marcadas
As imagens do Registro de contêiner marcadas são mutáveis por padrão, o que significa que a mesma tag pode ser usada em várias imagens enviadas para o registro. Em cenários de produção, isso pode levar a um comportamento imprevisível que pode afetar o tempo de atividade do aplicativo.
Gestão de identidades e acessos
Use a autenticação integrada do Microsoft Entra para enviar e extrair imagens em vez de depender de chaves de acesso. Para maior segurança, desative totalmente o uso da chave de acesso de administrador.
Computação sem servidor
A computação sem servidor fornece recursos sob demanda e elimina a necessidade de gerenciar a infraestrutura. O provedor de nuvem provisiona, dimensiona e gerencia automaticamente os recursos necessários para executar o código do aplicativo implantado. O Azure fornece várias plataformas de computação sem servidor:
Funções do Azure. Quando você usa o Azure Functions, a lógica do aplicativo é implementada como blocos distintos de código, ou funções, que são executados em resposta a eventos, como uma solicitação HTTP ou uma mensagem de fila. Cada função é dimensionada conforme necessário para atender à demanda.
Azure Logic Apps. O Logic Apps é mais adequado para criar e executar fluxos de trabalho automatizados que integram vários aplicativos, fontes de dados, serviços e sistemas. Como o Azure Functions, os Aplicativos Lógicos usam gatilhos internos para processamento controlado por eventos. No entanto, em vez de implantar o código do aplicativo, você pode criar aplicativos lógicos usando uma interface gráfica do usuário que ofereça suporte a blocos de código, como condicionais e loops.
Gerenciamento de API do Azure. Você pode usar o Gerenciamento de API para publicar, transformar, manter e monitorar APIs de segurança aprimorada usando a camada Consumo.
Power Apps e Power Automate. Essas ferramentas fornecem uma experiência de desenvolvimento low-code ou no-code, com lógica de fluxo de trabalho simples e integrações que são configuráveis por meio de conexões em uma interface de usuário.
Para aplicativos de missão crítica, as tecnologias sem servidor fornecem desenvolvimento e operações simplificados, que podem ser valiosos para casos de uso de negócios simples. No entanto, essa simplicidade tem o custo da flexibilidade em termos de escalabilidade, confiabilidade e desempenho, e isso não é viável para a maioria dos cenários de aplicativos de missão crítica.
As seções a seguir fornecem considerações de design e recomendações para usar o Azure Functions e os Aplicativos Lógicos como plataformas alternativas para cenários de fluxo de trabalho não críticos.
Considerações de design e recomendações para o Azure Functions
As cargas de trabalho de missão crítica têm fluxos de sistema críticos e não críticos. O Azure Functions é uma escolha viável para fluxos que não têm os mesmos requisitos de negócios rigorosos que os fluxos críticos do sistema. É adequado para fluxos orientados a eventos que têm processos de curta duração, porque as funções executam operações distintas que são executadas o mais rápido possível.
Escolha uma opção de hospedagem do Azure Functions apropriada para a camada de confiabilidade do aplicativo. Recomendamos o plano Premium porque ele permite configurar o tamanho da instância de computação. O plano dedicado é a opção menos sem servidor. Ele fornece escala automática, mas essas operações de escala são mais lentas do que as dos outros planos. Recomendamos que você use o plano Premium para maximizar a confiabilidade e o desempenho.
Existem algumas considerações de segurança. Quando você usa um gatilho HTTP para expor um ponto de extremidade externo, use um firewall de aplicativo Web (WAF) para fornecer um nível de proteção para o ponto de extremidade HTTP contra vetores de ataque externos comuns.
Recomendamos o uso de pontos de extremidade privados para restringir o acesso a redes virtuais privadas. Eles também podem reduzir os riscos de exfiltração de dados, como cenários de administração mal-intencionados.
Você precisa usar ferramentas de verificação de código no código do Azure Functions e integrar essas ferramentas com pipelines de CI/CD.
Considerações e recomendações de design para Aplicativos Lógicos do Azure
Como o Azure Functions, os Aplicativos Lógicos usam gatilhos internos para processamento controlado por eventos. No entanto, em vez de implantar o código do aplicativo, você pode criar aplicativos lógicos usando uma interface gráfica do usuário que ofereça suporte a blocos como condicionais, loops e outras construções.
Vários modos de implantação estão disponíveis. Recomendamos o modo Standard para garantir uma implantação de locatário único e mitigar cenários vizinhos barulhentos. Esse modo usa o tempo de execução dos Aplicativos Lógicos de locatário único em contêiner, que se baseia no Azure Functions. Nesse modo, o aplicativo lógico pode ter vários fluxos de trabalho com e sem monitoração de estado. Você deve estar ciente dos limites de configuração.
Migrações restritas via IaaS
Muitos aplicativos que têm implantações locais existentes usam tecnologias de virtualização e hardware redundante para fornecer níveis críticos de confiabilidade. A modernização é muitas vezes prejudicada por restrições de negócios que impedem o alinhamento total com o padrão de arquitetura de linha de base nativa da nuvem (North Star) recomendado para cargas de trabalho de missão crítica. É por isso que muitos aplicativos adotam uma abordagem em fases, com implantações iniciais na nuvem usando virtualização e Máquinas Virtuais do Azure como o principal modelo de hospedagem de aplicativos. O uso de VMs de infraestrutura como serviço (IaaS) pode ser necessário em determinados cenários:
- Os serviços de PaaS disponíveis não fornecem o desempenho ou o nível de controle necessários.
- A carga de trabalho requer acesso ao sistema operacional, drivers específicos ou configurações de rede e sistema.
- A carga de trabalho não suporta a execução em contêineres.
- Não há suporte do fornecedor para cargas de trabalho de terceiros.
Esta seção se concentra nas melhores maneiras de usar máquinas virtuais e serviços associados para maximizar a confiabilidade da plataforma de aplicativos. Ele destaca os principais aspetos da metodologia de design de missão crítica que transpõe cenários de migração IaaS e nativos da nuvem.
Considerações de design
Os custos operacionais do uso de VMs IaaS são significativamente mais altos do que os custos do uso de serviços PaaS devido aos requisitos de gerenciamento das VMs e dos sistemas operacionais. O gerenciamento de VMs requer a distribuição frequente de pacotes e atualizações de software.
O Azure fornece recursos para aumentar a disponibilidade de VMs:
- As zonas de disponibilidade podem ajudá-lo a alcançar níveis ainda mais altos de confiabilidade distribuindo VMs entre datacenters fisicamente separados dentro de uma região.
- Os conjuntos de dimensionamento de máquina virtual do Azure fornecem funcionalidade para dimensionar automaticamente o número de VMs em um grupo. Eles também fornecem recursos para monitorar a integridade da instância e reparar automaticamente instâncias não íntegras.
- Dimensionar conjuntos com orquestração flexível pode ajudar a proteger contra falhas de rede, disco e energia, distribuindo automaticamente VMs entre domínios de falha.
Recomendações de design
Importante
Use serviços e contêineres de PaaS quando possível para reduzir a complexidade operacional e os custos. Use VMs IaaS somente quando precisar.
Tamanhos de SKU de VM de tamanho certo para garantir a utilização eficaz de recursos.
Implante três ou mais VMs em zonas de disponibilidade para obter tolerância a falhas no nível do datacenter.
- Se você estiver implantando software comercial pronto para uso, consulte o fornecedor do software e teste adequadamente antes de implantar o software na produção.
Para cargas de trabalho que você não pode implantar em zonas de disponibilidade, use conjuntos flexíveis de dimensionamento de máquina virtual que contenham três ou mais VMs. Para obter mais informações sobre como configurar o número correto de domínios de falha, consulte Gerenciar domínios de falha em conjuntos de escala.
Priorize o uso de Conjuntos de Dimensionamento de Máquina Virtual para escalabilidade e redundância de zona. Este ponto é particularmente importante para cargas de trabalho com cargas variáveis. Por exemplo, se o número de usuários ativos ou solicitações por segundo for uma carga variável.
Não acesse VMs individuais diretamente. Use balanceadores de carga na frente deles sempre que possível.
Para proteger contra interrupções regionais, implante VMs de aplicativos em várias regiões do Azure.
- Consulte a área de design de rede e conectividade para obter detalhes sobre como rotear o tráfego de forma otimizada entre regiões de implantação ativas.
Para cargas de trabalho que não oferecem suporte a implantações ativas/ativas em várias regiões, considere implementar implantações ativas/passivas usando VMs em espera ativa/quente para failover regional.
Use imagens padrão do Azure Marketplace em vez de imagens personalizadas que precisam ser mantidas.
Implemente processos automatizados para implantar e implantar alterações em VMs, evitando qualquer intervenção manual. Para obter mais informações, consulte Considerações sobre IaaS na área Design de procedimentos operacionais.
Implemente experimentos de caos para injetar falhas de aplicativos em componentes de VM e observe a mitigação de falhas. Para obter mais informações, consulte Validação e teste contínuos.
Monitore VMs e garanta que os logs e métricas de diagnóstico sejam ingeridos em um coletor de dados unificado.
Implemente práticas de segurança para cenários de aplicativos de missão crítica, quando aplicável, e as práticas recomendadas de segurança para cargas de trabalho IaaS no Azure.
Próximo passo
Analise as considerações para a plataforma de dados.