Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Sugestão
Este conteúdo é um excerto do eBook Architecting Cloud Native .NET Applications for Azure, disponível no .NET Docs ou como um PDF transferível gratuito que pode ser lido offline.

O mantra favorito dos consultores de software é responder "depende" a qualquer pergunta feita. Não é porque os consultores de software gostam de não tomar posição. É porque não há uma resposta verdadeira para quaisquer perguntas no software. Não há certo e errado absolutos, mas sim um equilíbrio entre opostos.
Tomemos, por exemplo, as duas principais escolas de desenvolvimento de aplicações Web: Single Page Applications (SPAs) versus aplicações do lado do servidor. Por um lado, a experiência do usuário tende a ser melhor com SPAs e a quantidade de tráfego para o servidor web pode ser minimizada, tornando possível hospedá-los em algo tão simples como hospedagem estática. Por outro lado, as ZPE tendem a ser de desenvolvimento mais lento e mais difíceis de testar. Qual é a escolha certa? Bem, depende da sua situação.
Os aplicativos nativos da nuvem não são imunes a essa mesma dicotomia. Eles têm vantagens claras em termos de velocidade de desenvolvimento, estabilidade e escalabilidade, mas gerenciá-los pode ser um pouco mais difícil.
Anos atrás, não era incomum que o processo de mover um aplicativo do desenvolvimento para a produção levasse um mês, ou até mais. As empresas lançaram software numa cadência de 6 meses ou mesmo todos os anos. Não é preciso ir além do Microsoft Windows para ter uma ideia da cadência de lançamentos que eram aceitáveis antes dos dias sempre verdes do Windows 10. Passaram-se cinco anos entre o Windows XP e o Vista, mais três entre o Vista e o Windows 7.
Agora está bastante bem estabelecido que ser capaz de lançar software rapidamente dá às empresas em rápida evolução uma enorme vantagem de mercado sobre seus concorrentes mais preguiçosos. É por essa razão que as principais atualizações para o Windows 10 agora são aproximadamente a cada seis meses.
Os padrões e práticas que permitem versões mais rápidas e confiáveis para agregar valor aos negócios são conhecidos coletivamente como DevOps. Eles consistem em uma ampla gama de ideias que abrangem todo o ciclo de vida de desenvolvimento de software, desde a especificação de um aplicativo até a entrega e operação desse aplicativo.
O DevOps surgiu antes dos microsserviços e é provável que o movimento em direção a serviços menores e mais adequados à finalidade não teria sido possível sem o DevOps para facilitar o lançamento e a operação não apenas de um, mas de muitos aplicativos em produção.
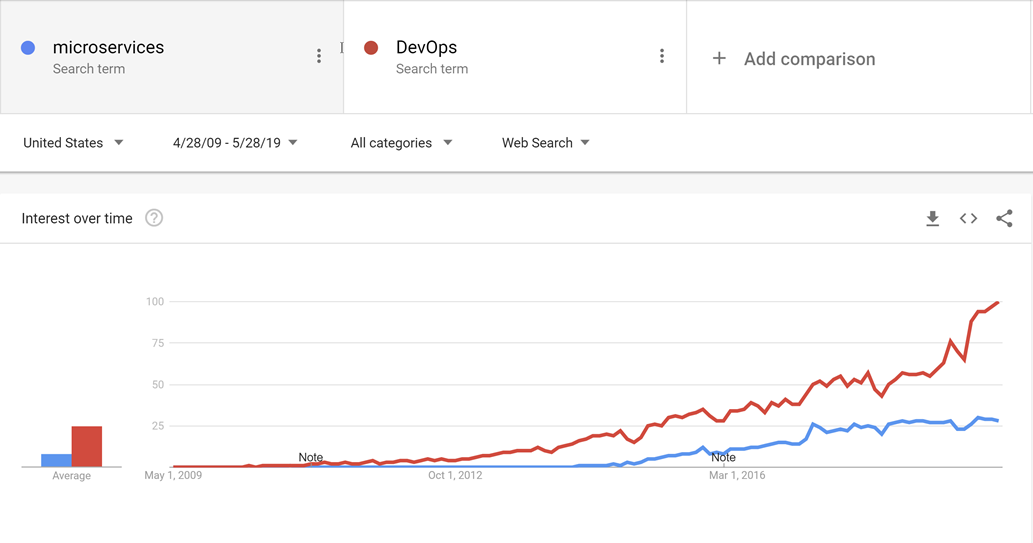
Figura 10-1 - DevOps e microsserviços.
Através de boas práticas de DevOps, é possível perceber as vantagens dos aplicativos nativos da nuvem sem sufocar sob uma montanha de trabalho realmente operando os aplicativos.
Não há martelo de ouro quando se trata de DevOps. Ninguém pode vender uma solução completa e abrangente para lançar e operar aplicações de alta qualidade. Isso ocorre porque cada aplicativo é muito diferente de todos os outros. No entanto, existem ferramentas que podem tornar o DevOps uma proposta muito menos assustadora. Uma dessas ferramentas é conhecida como Azure DevOps.
Azure DevOps
O Azure DevOps tem um longo pedigree. Ele pode rastrear suas raízes até quando o Team Foundation Server se moveu online pela primeira vez e através das várias alterações de nome: Visual Studio Online e Visual Studio Team Services. Ao longo dos anos, no entanto, tornou-se muito mais do que os seus antecessores.
O Azure DevOps está dividido em cinco componentes principais:

Figura 10-2 - Azure DevOps.
Azure Repos - Gerenciamento de código-fonte que dá suporte ao venerável Controle de Versão do Team Foundation (TFVC) e ao Git favorito do setor. As solicitações pull fornecem uma maneira de habilitar a codificação social, promovendo a discussão das alterações à medida que são feitas.
Azure Boards - Fornece uma ferramenta de controle de problemas e itens de trabalho que se esforça para permitir que os usuários escolham os fluxos de trabalho que funcionam melhor para eles. Ele vem com uma série de modelos pré-configurados, incluindo aqueles para suportar os estilos de desenvolvimento SCRUM e Kanban.
Azure Pipelines - Um sistema de gerenciamento de compilação e liberação que oferece suporte à integração total com o Azure. As compilações podem ser executadas em várias plataformas, do Windows ao Linux e ao macOS. Os agentes de compilação podem ser provisionados na nuvem ou no local.
Planos de Teste do Azure - Nenhuma pessoa de QA será deixada para trás com o suporte de gerenciamento de teste e teste exploratório oferecido pelo recurso Planos de Teste.
Artefatos do Azure - Um feed de artefatos que permite que as empresas criem suas próprias versões internas do NuGet, npm e outros. Ele serve a um duplo propósito de atuar como um cache de pacotes upstream se houver uma falha de um repositório centralizado.
A unidade organizacional de nível superior no Azure DevOps é conhecida como um Projeto. Dentro de cada projeto, os vários componentes, como Artefatos do Azure, podem ser ativados e desativados. Cada um desses componentes oferece vantagens diferentes para aplicativos nativos da nuvem. Os três mais úteis são repositórios, placas e pipelines. Se os usuários quiserem gerenciar seu código-fonte em outra pilha de repositório, como o GitHub, mas ainda assim aproveitarem os Pipelines do Azure e outros componentes, isso é perfeitamente possível.
Felizmente, as equipes de desenvolvimento têm muitas opções ao selecionar um repositório. Um deles é o GitHub.
Ações do GitHub
Fundado em 2009, o GitHub é um repositório baseado na web amplamente popular para hospedar projetos, documentação e código. Muitas grandes empresas de tecnologia, como Apple, Amazon, Google e grandes corporações usam o GitHub. O GitHub usa o sistema de controle de versão distribuído de código aberto chamado Git como sua base. Além disso, ele adiciona seu próprio conjunto de recursos, incluindo rastreamento de defeitos, solicitações de recurso e pull, gerenciamento de tarefas e wikis para cada base de código.
À medida que o GitHub evolui, ele também está adicionando recursos de DevOps. Por exemplo, o GitHub tem seu próprio pipeline de integração contínua/entrega contínua (CI/CD), chamado GitHub Actions. O GitHub Actions é uma ferramenta de automação de fluxo de trabalho alimentada pela comunidade. Ele permite que as equipes de DevOps se integrem com suas ferramentas existentes, misturem e combinem novos produtos e se conectem ao ciclo de vida do software, incluindo parceiros de CI/CD existentes."
O GitHub tem mais de 40 milhões de usuários, tornando-se o maior host de código-fonte do mundo. Em outubro de 2018, a Microsoft comprou o GitHub. A Microsoft prometeu que o GitHub continuará sendo uma plataforma aberta que qualquer desenvolvedor pode conectar e ampliar. Continua a operar como uma empresa independente. O GitHub oferece planos para contas corporativas, de equipe, profissionais e gratuitas.
Controlo de origem
Organizar o código para um aplicativo nativo da nuvem pode ser um desafio. Em vez de um único aplicativo gigante, os aplicativos nativos da nuvem tendem a ser compostos por uma rede de aplicativos menores que conversam entre si. Como acontece com todas as coisas na computação, o melhor arranjo de código permanece uma questão em aberto. Existem exemplos de aplicações bem-sucedidas usando diferentes tipos de layouts, mas duas variantes parecem ter a maior popularidade.
Antes de entrar no controle do código-fonte em si, provavelmente vale a pena decidir quantos projetos são apropriados. Em um único projeto, há suporte para vários repositórios e pipelines de construção. Os quadros são um pouco mais complicados, mas também lá as tarefas podem ser facilmente atribuídas a várias equipes dentro de um único projeto. É possível dar suporte a centenas, até milhares de desenvolvedores, a partir de um único projeto de DevOps do Azure. Fazer isso é provavelmente a melhor abordagem, pois fornece um único lugar para todos os desenvolvedores trabalharem e reduz a confusão de encontrar esse aplicativo quando os desenvolvedores não têm certeza em qual projeto ele reside.
Dividir o código para microsserviços dentro do projeto Azure DevOps pode ser um pouco mais desafiador.
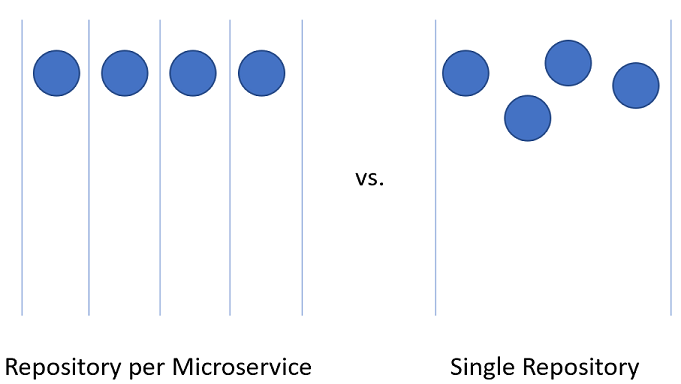
Figura 10-3 - Um vs. muitos repositórios.
Repositório por microsserviço
À primeira vista, essa abordagem parece ser a mais lógica para dividir o código-fonte para microsserviços. Cada repositório pode conter o código necessário para criar um microsserviço. As vantagens desta abordagem são facilmente visíveis:
- As instruções para criar e manter o aplicativo podem ser adicionadas a um arquivo LEIA-ME na raiz de cada repositório. Ao folhear os repositórios, é fácil encontrar essas instruções, reduzindo o tempo de rotação para os desenvolvedores.
- Cada serviço está localizado em um lugar lógico, facilmente encontrado por saber o nome do serviço.
- As compilações podem ser facilmente configuradas de forma que só sejam acionadas quando uma alteração é feita no repositório proprietário.
- O número de alterações que entram em um repositório é limitado ao pequeno número de desenvolvedores que trabalham no projeto.
- A segurança é fácil de configurar, restringindo os repositórios para os quais os desenvolvedores têm permissões de leitura e gravação.
- As configurações de nível de repositório podem ser alteradas pela equipe proprietária com um mínimo de discussão com outras pessoas.
Uma das ideias-chave por trás dos microsserviços é que os serviços devem ser isolados e separados uns dos outros. Ao usar o Design Controlado por Domínio para decidir sobre os limites dos serviços, os serviços atuam como limites transacionais. As atualizações de banco de dados não devem abranger vários serviços. Esta recolha de dados relacionados é referida como um contexto limitado. Esta ideia reflete-se no isolamento dos dados de microsserviços numa base de dados separada e autónoma dos restantes serviços. Faz muito sentido levar essa ideia até o código-fonte.
No entanto, esta abordagem não está isenta de problemas. Um dos problemas de desenvolvimento mais difíceis do nosso tempo é a gestão das dependências. Considere o número de arquivos que compõem o diretório médio node_modules . Uma nova instalação de algo parecido create-react-app provavelmente trará milhares de pacotes. A questão de como gerir estas dependências é difícil.
Se uma dependência for atualizada, os pacotes downstream também deverão atualizar essa dependência. Infelizmente, isso requer trabalho de desenvolvimento, então, invariavelmente, o node_modules diretório acaba com várias versões de um único pacote, cada uma uma dependência de algum outro pacote que é versionado em uma cadência ligeiramente diferente. Ao implantar um aplicativo, qual versão de uma dependência deve ser usada? A versão que está atualmente em produção? A versão que está atualmente em Beta, mas provavelmente estará em produção no momento em que o consumidor chegar à produção? Problemas difíceis que não são resolvidos apenas usando microsserviços.
Há bibliotecas que dependem de uma grande variedade de projetos. Ao dividir os microsserviços com um em cada repositório, as dependências internas podem ser melhor resolvidas usando o repositório interno, Azure Artifacts. As compilações para bibliotecas enviarão suas versões mais recentes para os Artefatos do Azure para consumo interno. O projeto a jusante ainda deve ser atualizado manualmente para depender dos pacotes recém-atualizados.
Outra desvantagem se apresenta ao mover o código entre serviços. Embora seja bom acreditar que a primeira divisão de um aplicativo em microsserviços é 100% correta, a realidade é que raramente somos tão prescientes a ponto de não cometer erros de divisão de serviço. Assim, a funcionalidade e o código que a conduz terão de passar de serviço para serviço: repositório para repositório. Ao saltar de um repositório para outro, o código perde seu histórico. Há muitos casos, especialmente no caso de uma auditoria, em que ter um histórico completo em um pedaço de código é inestimável.
A última e mais importante desvantagem é a coordenação das mudanças. Em um aplicativo de microsserviços verdadeiro, não deve haver dependências de implantação entre serviços. Deve ser possível implantar os serviços A, B e C em qualquer ordem, pois eles têm acoplamento flexível. Na realidade, no entanto, há momentos em que é desejável fazer uma alteração que cruze vários repositórios ao mesmo tempo. Alguns exemplos incluem a atualização de uma biblioteca para fechar uma falha de segurança ou a alteração de um protocolo de comunicação usado por todos os serviços.
Para fazer uma alteração entre repositórios, é necessário que cada repositório seja confirmado sucessivamente. Cada alteração em cada repositório precisará ser solicitada e revisada separadamente. Esta atividade pode ser difícil de coordenar.
Uma alternativa ao uso de muitos repositórios é colocar todo o código-fonte junto em um repositório gigante, todos sabendo, único.
Repositório único
Nessa abordagem, às vezes chamada de monorepositório, todo o código-fonte de cada serviço é colocado no mesmo repositório. A princípio, essa abordagem parece uma péssima ideia que provavelmente tornará complicado lidar com o código-fonte. Existem, no entanto, algumas vantagens marcantes em trabalhar desta forma.
A primeira vantagem é que é mais fácil gerenciar dependências entre projetos. Em vez de depender de algum feed de artefatos externos, os projetos podem importar diretamente uns aos outros. Isso significa que as atualizações são instantâneas e é provável que versões conflitantes sejam encontradas no momento da compilação na estação de trabalho do desenvolvedor. Na verdade, mudando alguns dos testes de integração para a esquerda.
Ao mover o código entre projetos, agora é mais fácil preservar o histórico, pois os arquivos serão detetados como tendo sido movidos em vez de serem reescritos.
Outra vantagem é que mudanças abrangentes que cruzam os limites do serviço podem ser feitas em uma única confirmação. Essa atividade reduz a sobrecarga de ter potencialmente dezenas de alterações para revisar individualmente.
Existem muitas ferramentas que podem executar a análise estática de código para detetar práticas de programação inseguras ou uso problemático de APIs. Em um mundo com vários repositórios, cada repositório precisará ser iterado para encontrar os problemas neles. O repositório único permite executar a análise em um só lugar.
Há também muitas desvantagens na abordagem de repositório único. Uma das mais preocupantes é que ter um único repositório levanta preocupações de segurança. Se o conteúdo de um repositório for vazado em um repositório por modelo de serviço, a quantidade de código perdido será mínima. Com um único repositório, tudo o que a empresa possui pode ser perdido. Houve muitos exemplos no passado de que isso aconteceu e inviabilizou esforços inteiros de desenvolvimento de jogos. Ter vários repositórios expõe menos área de superfície, o que é uma característica desejável na maioria das práticas de segurança.
É provável que o tamanho do repositório único se torne incontrolável rapidamente. Isto apresenta algumas implicações interessantes em termos de desempenho. Pode ser necessário usar ferramentas especializadas, como o Virtual File System for Git, que foi originalmente projetado para melhorar a experiência dos desenvolvedores da equipe do Windows.
Frequentemente, o argumento para usar um único repositório se resume a um argumento de que o Facebook ou o Google usam esse método para a organização do código-fonte. Se a abordagem é boa o suficiente para essas empresas, então, certamente, é a abordagem correta para todas as empresas. A verdade é que poucas empresas operam na escala do Facebook ou do Google. Os problemas que ocorrem nessas escalas são diferentes daqueles que a maioria dos desenvolvedores enfrentará. O que é bom para o ganso pode não ser bom para o ganso.
No final, qualquer uma das soluções pode ser usada para hospedar o código-fonte dos microsserviços. No entanto, na maioria dos casos, a sobrecarga de gerenciamento e engenharia de operar em um único repositório não vale as escassas vantagens. A divisão do código em vários repositórios incentiva uma melhor separação de preocupações e incentiva a autonomia entre as equipes de desenvolvimento.
Estrutura de diretórios padrão
Independentemente do debate entre repositórios únicos e múltiplos, cada serviço terá seu próprio diretório. Uma das melhores otimizações para permitir que os desenvolvedores cruzem projetos rapidamente é manter uma estrutura de diretórios padrão.
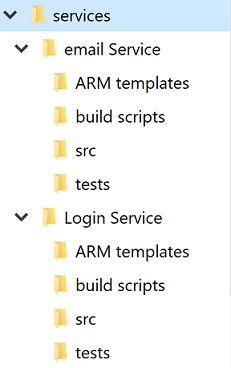
Figura 10-4 - Estrutura de diretórios padrão.
Sempre que um novo projeto é criado, um modelo que coloca em prática a estrutura correta deve ser usado. Este modelo também pode incluir itens úteis como um arquivo LEIA-ME esqueleto e um azure-pipelines.ymlarquivo . Em qualquer arquitetura de microsserviços, um alto grau de variação entre projetos torna as operações em massa em relação aos serviços mais difíceis.
Há muitas ferramentas que podem fornecer modelos para um diretório inteiro, contendo vários diretórios de código-fonte. Yeoman é popular no mundo JavaScript e o GitHub lançou recentemente Repository Templates, que fornecem grande parte da mesma funcionalidade.
Gestão de tarefas
Gerenciar tarefas em qualquer projeto pode ser difícil. Lá na frente, há inúmeras perguntas a serem respondidas sobre o tipo de fluxos de trabalho a serem configurados para garantir a produtividade ideal do desenvolvedor.
Os aplicativos nativos da nuvem tendem a ser menores do que os produtos de software tradicionais ou, pelo menos, são divididos em serviços menores. O acompanhamento de problemas ou tarefas relacionadas a esses serviços continua sendo tão importante quanto em qualquer outro projeto de software. Ninguém quer perder o controle de algum item de trabalho ou explicar a um cliente que seu problema não foi registrado corretamente. Os quadros são configurados no nível do projeto, mas dentro de cada projeto, as áreas podem ser definidas. Estes permitem decompor os problemas em vários componentes. A vantagem de manter todo o trabalho para todo o aplicativo em um só lugar é que é fácil mover itens de trabalho de uma equipe para outra à medida que são melhor compreendidos.
O Azure DevOps vem com vários modelos populares pré-configurados. Na configuração mais básica, tudo o que é necessário saber é o que está na lista de pendências, no que as pessoas estão trabalhando e o que é feito. É importante ter essa visibilidade no processo de construção de software, para que o trabalho possa ser priorizado e as tarefas concluídas relatadas ao cliente. Claro, poucos projetos de software se apegam a um processo tão simples como to do, doing, e done. Não demora muito para que as pessoas comecem a adicionar etapas como QA ou Detailed Specification ao processo.
Uma das partes mais importantes das metodologias ágeis é a autointrospecção em intervalos regulares. Essas avaliações têm como objetivo fornecer informações sobre os problemas que a equipe está enfrentando e como eles podem ser melhorados. Frequentemente, isso significa alterar o fluxo de problemas e recursos ao longo do processo de desenvolvimento. Assim, é perfeitamente saudável expandir os layouts das placas com estágios adicionais.
As etapas nos conselhos não são a única ferramenta organizacional. Dependendo da configuração da placa, há uma hierarquia de itens de trabalho. O item mais granular que pode aparecer em um quadro é uma tarefa. Fora da caixa, uma tarefa contém campos para um título, descrição, uma prioridade, uma estimativa da quantidade de trabalho restante e a capacidade de vincular a outros itens de trabalho ou itens de desenvolvimento (ramificações, confirmações, solicitações pull, compilações e assim por diante). Os itens de trabalho podem ser classificados em diferentes áreas da aplicação e diferentes iterações (sprints) para facilitar a sua localização.
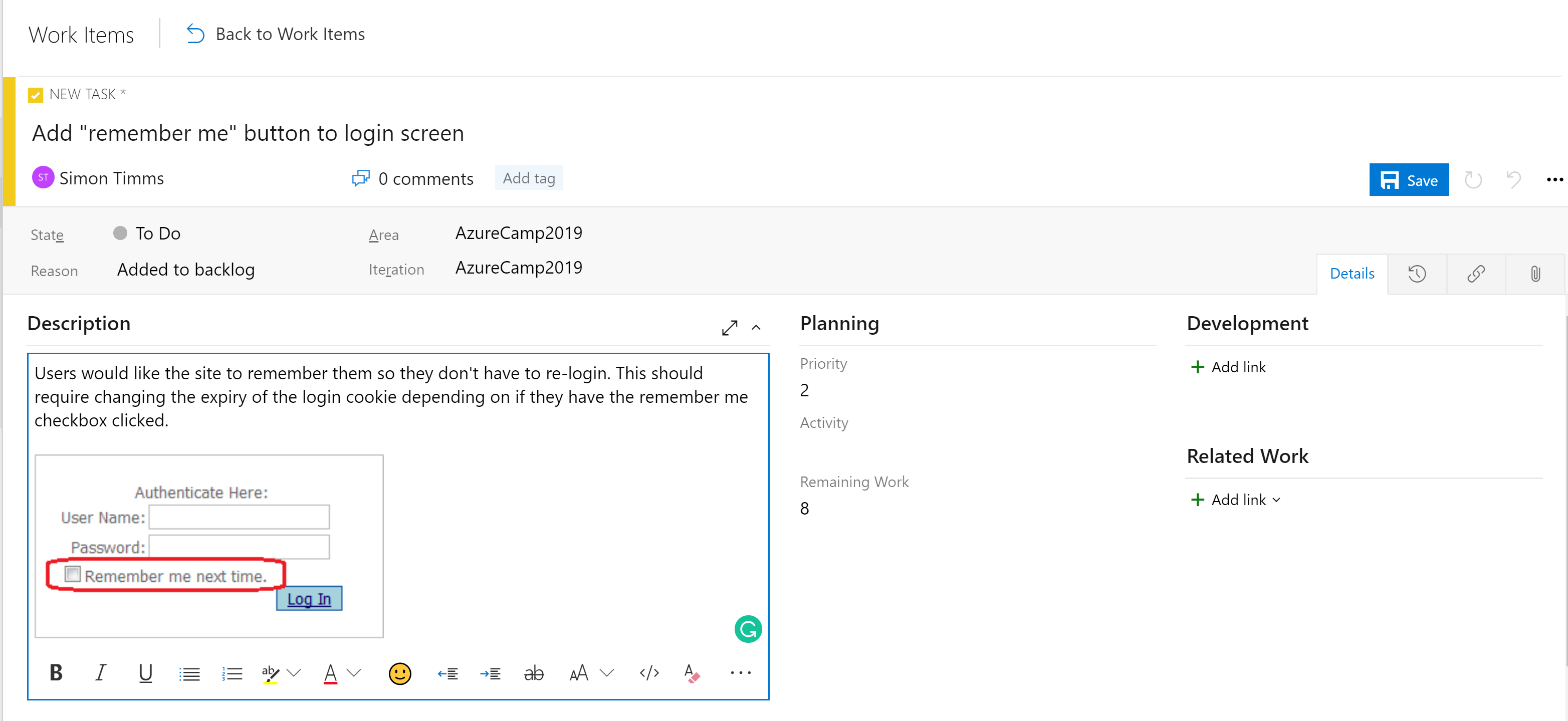
Figura 10-5 - Tarefa no Azure DevOps.
O campo de descrição suporta os estilos normais que você esperaria (negrito, itálico, sublinhado e riscado) e a capacidade de inserir imagens. Isso o torna uma ferramenta poderosa para uso ao especificar trabalho ou bugs.
As tarefas podem ser agrupadas em recursos, que definem uma unidade maior de trabalho. Os recursos, por sua vez, podem ser enrolados em épicos. A classificação de tarefas nessa hierarquia torna muito mais fácil entender o quão próximo um recurso grande está da implantação.

Figura 10-6 - Item de trabalho no Azure DevOps.
Há diferentes tipos de modos de exibição sobre os problemas nos Painéis do Azure. Os itens que ainda não estão agendados aparecem na lista de pendências. A partir daí, eles podem ser atribuídos a um sprint. Um sprint é uma caixa de tempo durante a qual se espera que alguma quantidade de trabalho seja concluída. Este trabalho pode incluir tarefas, mas também a resolução de tickets. Uma vez lá, todo o sprint pode ser gerenciado a partir da seção Sprint board. Esta vista mostra como o trabalho está a progredir e inclui um gráfico de burndown para fornecer uma estimativa sempre atualizada de se o sprint será bem-sucedido.
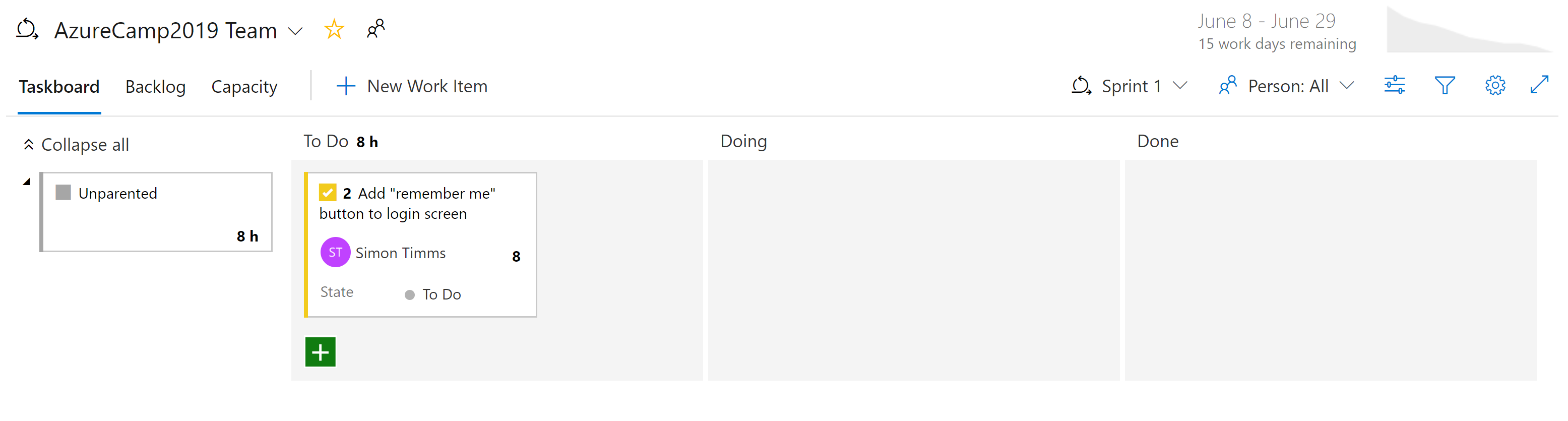
Figura 10-7 - Quadro no Azure DevOps.
Até agora, deve ser aparente que há muito poder nos Painéis no Azure DevOps. Para os desenvolvedores, há visualizações fáceis do que está sendo trabalhado. Para visões de gerentes de projeto sobre o trabalho futuro, bem como uma visão geral do trabalho existente. Para os gestores, há muitos relatórios sobre recursos e capacidade. Infelizmente, não há nada mágico em aplicativos nativos da nuvem que eliminam a necessidade de rastrear o trabalho. Mas se você precisar acompanhar o trabalho, há alguns lugares onde a experiência é melhor do que no Azure DevOps.
Pipelines de CI/CD
Quase nenhuma mudança no ciclo de vida de desenvolvimento de software foi tão revolucionária quanto o advento da integração contínua (CI) e da entrega contínua (CD). Construir e executar testes automatizados em relação ao código-fonte de um projeto assim que uma alteração é verificada deteta erros precocemente. Antes do advento das compilações de integração contínua, não seria incomum extrair código do repositório e descobrir que ele não passava nos testes ou nem sequer podia ser construído. Isso resultou no rastreamento da origem da quebra.
Tradicionalmente, o envio de software para o ambiente de produção exigia documentação extensa e uma lista de etapas. Cada uma dessas etapas precisava ser concluída manualmente em um processo muito propenso a erros.

Figura 10-8 - Lista de verificação.
A irmã da integração contínua é a entrega contínua, na qual os pacotes recém-construídos são implantados em um ambiente. O processo manual não pode ser dimensionado para corresponder à velocidade de desenvolvimento, por isso a automação se torna mais importante. As listas de verificação são substituídas por scripts que podem executar as mesmas tarefas com mais rapidez e precisão do que qualquer ser humano.
O ambiente para o qual a entrega contínua fornece pode ser um ambiente de teste ou, como está sendo feito por muitas grandes empresas de tecnologia, pode ser o ambiente de produção. Este último requer um investimento em testes de alta qualidade que possam dar confiança de que uma mudança não vai quebrar a produção para os usuários. Da mesma forma que a integração contínua detetou problemas no código: a entrega contínua deteta problemas no processo de implantação antecipadamente.
A importância de automatizar o processo de compilação e entrega é acentuada pelos aplicativos nativos da nuvem. As implantações acontecem com mais frequência e em mais ambientes, portanto, a implantação manual é impossível.
Compilações do Azure
O Azure DevOps fornece um conjunto de ferramentas para tornar a integração e a implantação contínuas mais fáceis do que nunca. Essas ferramentas estão localizadas em Pipelines do Azure. O primeiro deles é o Azure Builds, que é uma ferramenta para executar definições de compilação baseadas em YAML em escala. Os usuários podem trazer suas próprias máquinas de compilação (ótimo para se a compilação exigir um ambiente meticulosamente configurado) ou usar uma máquina de um pool constantemente atualizado de máquinas virtuais hospedadas do Azure. Esses agentes de compilação hospedados vêm pré-instalados com uma ampla gama de ferramentas de desenvolvimento não apenas para desenvolvimento .NET, mas para tudo, de Java a Python e desenvolvimento para iPhone.
O DevOps inclui uma ampla gama de definições de compilação prontas para uso que podem ser personalizadas para qualquer compilação. As definições de compilação são definidas em um arquivo chamado azure-pipelines.yml e verificado no repositório para que possam ser versionadas junto com o código-fonte. Isso torna muito mais fácil fazer alterações no pipeline de construção em uma ramificação, pois as alterações podem ser verificadas apenas nessa ramificação. Um exemplo azure-pipelines.yml para criar um aplicativo Web ASP.NET em full framework é mostrado na Figura 10-9.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Figura 10-9 - Uma amostra azure-pipelines.yml
Esta definição de construção usa uma série de tarefas internas que tornam a criação de compilações tão simples quanto construir um conjunto de Lego (mais simples do que o gigante Millennium Falcon). Por exemplo, a tarefa NuGet restaura pacotes NuGet, enquanto a tarefa VSBuild chama as ferramentas de compilação do Visual Studio para executar a compilação real. Há centenas de tarefas diferentes disponíveis no Azure DevOps, com milhares de outras que são mantidas pela comunidade. É provável que, independentemente das tarefas de compilação que você está procurando executar, alguém já tenha construído uma.
As compilações podem ser acionadas manualmente, por um check-in, em um cronograma ou pela conclusão de outra compilação. Na maioria dos casos, é desejável aproveitar cada check-in. As compilações podem ser filtradas para que diferentes compilações sejam executadas em diferentes partes do repositório ou em ramificações diferentes. Isso permite cenários como a execução de compilações rápidas com testes reduzidos em solicitações pull e a execução de um conjunto de regressão completo no tronco todas as noites.
O resultado final de uma compilação é uma coleção de arquivos conhecidos como artefatos de compilação. Esses artefatos podem ser passados para a próxima etapa do processo de compilação ou adicionados a um feed de Artefatos do Azure, para que possam ser consumidos por outras compilações.
Versões do Azure DevOps
As compilações cuidam da compilação do software em um pacote expedido, mas os artefatos ainda precisam ser enviados para um ambiente de teste para concluir a entrega contínua. Para isso, o Azure DevOps usa uma ferramenta separada chamada Releases. A ferramenta Releases faz uso da mesma biblioteca de tarefas que estavam disponíveis para o Build, mas introduz um conceito de "estágios". Um estágio é um ambiente isolado no qual o pacote é instalado. Por exemplo, um produto pode fazer uso de um desenvolvimento, um controle de qualidade e um ambiente de produção. O código é continuamente entregue no ambiente de desenvolvimento, onde testes automatizados podem ser executados em relação a ele. Uma vez que esses testes são aprovados, a liberação passa para o ambiente de controle de qualidade para testes manuais. Finalmente, o código é enviado para a produção, onde é visível para todos.

Figura 10-10 - Pipeline de liberação
Cada etapa da compilação pode ser automaticamente acionada pela conclusão da fase anterior. Em muitos casos, no entanto, isso não é desejável. Mover o código para a produção pode exigir a aprovação de alguém. A ferramenta Releases suporta isso, permitindo que os aprovadores em cada etapa do pipeline de lançamento. Regras podem ser estabelecidas de modo que uma pessoa ou grupo específico de pessoas deve assinar uma liberação antes que ela entre em produção. Estes portões permitem verificações manuais de qualidade e também o cumprimento de quaisquer requisitos regulamentares relacionados com o controlo do que entra em produção.
Todo mundo recebe um pipeline de construção
Não há custo para configurar muitos pipelines de compilação, portanto, é vantajoso ter pelo menos um pipeline de compilação por microsserviço. Idealmente, os microsserviços são implantáveis de forma independente em qualquer ambiente, portanto, ter cada um capaz de ser liberado por meio de seu próprio pipeline sem liberar uma massa de código não relacionado é perfeito. Cada pipeline pode ter seu próprio conjunto de aprovações, permitindo variações no processo de compilação para cada serviço.
Versões de controle de versão
Uma desvantagem de usar a funcionalidade Releases é que ela não pode ser definida em um arquivo com check-in azure-pipelines.yml . Há muitas razões pelas quais você pode querer fazer isso, desde ter definições de versão por ramificação até incluir um esqueleto de versão em seu modelo de projeto. Felizmente, o trabalho está em andamento para transferir alguns dos estágios de suporte para o componente Build. Isso será conhecido como construção de vários estágios e a primeira versão já está disponível!
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.