Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Sugestão
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no do .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Em sistemas distribuídos, como aplicativos baseados em microsserviços, há um risco sempre presente de falha parcial. Por exemplo, um único microsserviço/contêiner pode falhar ou pode não estar disponível para responder por um curto período de tempo, ou uma única VM ou servidor pode falhar. Como clientes e serviços são processos separados, um serviço pode não ser capaz de responder em tempo hábil à solicitação de um cliente. O serviço pode estar sobrecarregado e responder muito lentamente às solicitações ou pode simplesmente não estar acessível por um curto período de tempo devido a problemas de rede.
Por exemplo, considere a página de Detalhes do Pedido na aplicação de exemplo eShopOnContainers. Se o microsserviço de pedidos não responder quando o utilizador tentar submeter um pedido, uma má implementação do processo do cliente (a aplicação Web MVC) — por exemplo, se o código do cliente utilizar RPCs síncronas sem tempos limite — bloquearia indefinidamente as threads à espera de uma resposta. Além de criar uma má experiência do usuário, cada espera sem resposta consome ou bloqueia um thread, e os threads são extremamente valiosos em aplicativos altamente escaláveis. Se houver muitos threads bloqueados, eventualmente o tempo de execução do aplicativo pode ficar sem threads. Nesse caso, o aplicativo pode ficar globalmente sem resposta em vez de apenas parcialmente sem resposta, como mostra a Figura 8-1.
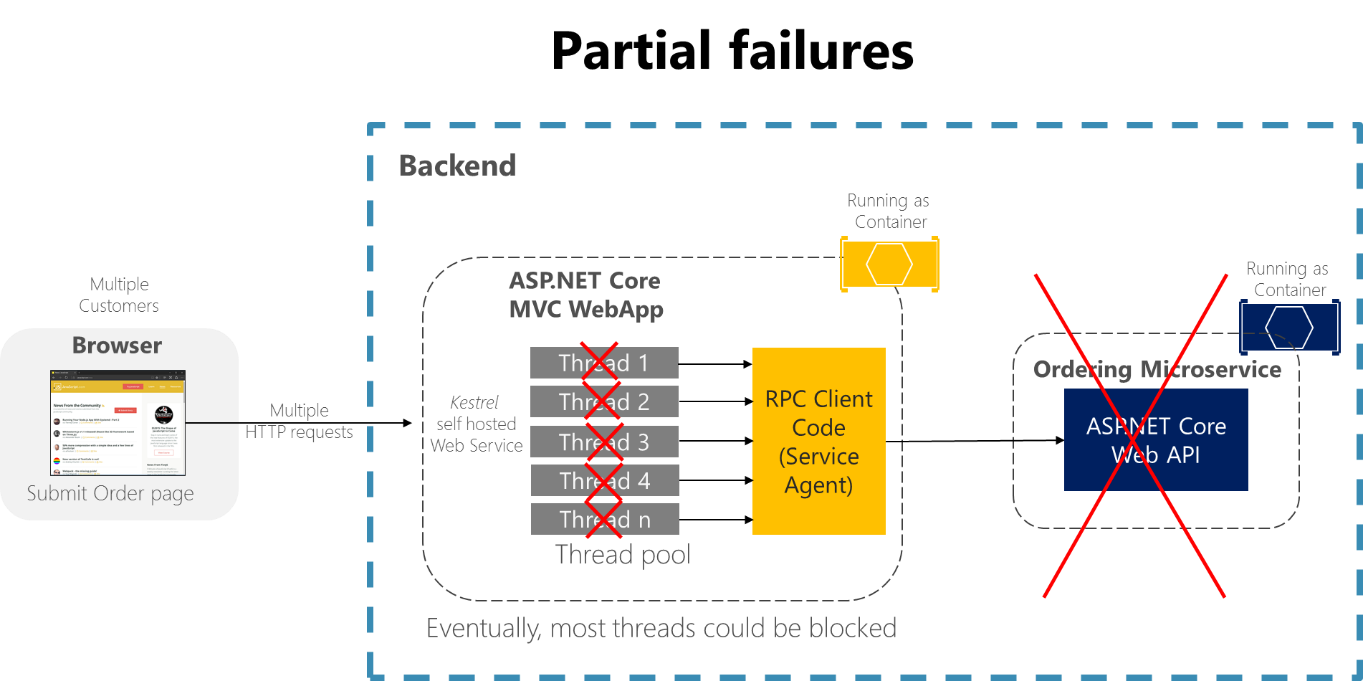
Figura 8-1. Falhas parciais devido a dependências que afetam a disponibilidade do thread de serviço
Em um grande aplicativo baseado em microsserviços, qualquer falha parcial pode ser amplificada, especialmente se a maior parte da interação interna de microsserviços for baseada em chamadas HTTP síncronas (o que é considerado um antipadrão). Pense num sistema que recebe milhões de chamadas por dia. Se o seu sistema tiver um design incorreto baseado em longas cadeias de chamadas HTTP síncronas, essas chamadas de entrada podem resultar em muitos mais milhões de chamadas de saída (vamos supor uma proporção de 1:4) para dezenas de microsserviços internos como dependências síncronas. Essa situação é mostrada na Figura 8-2, especialmente na dependência #3, que inicia uma cadeia, invocando a dependência #4, que por sua vez invoca a #5.
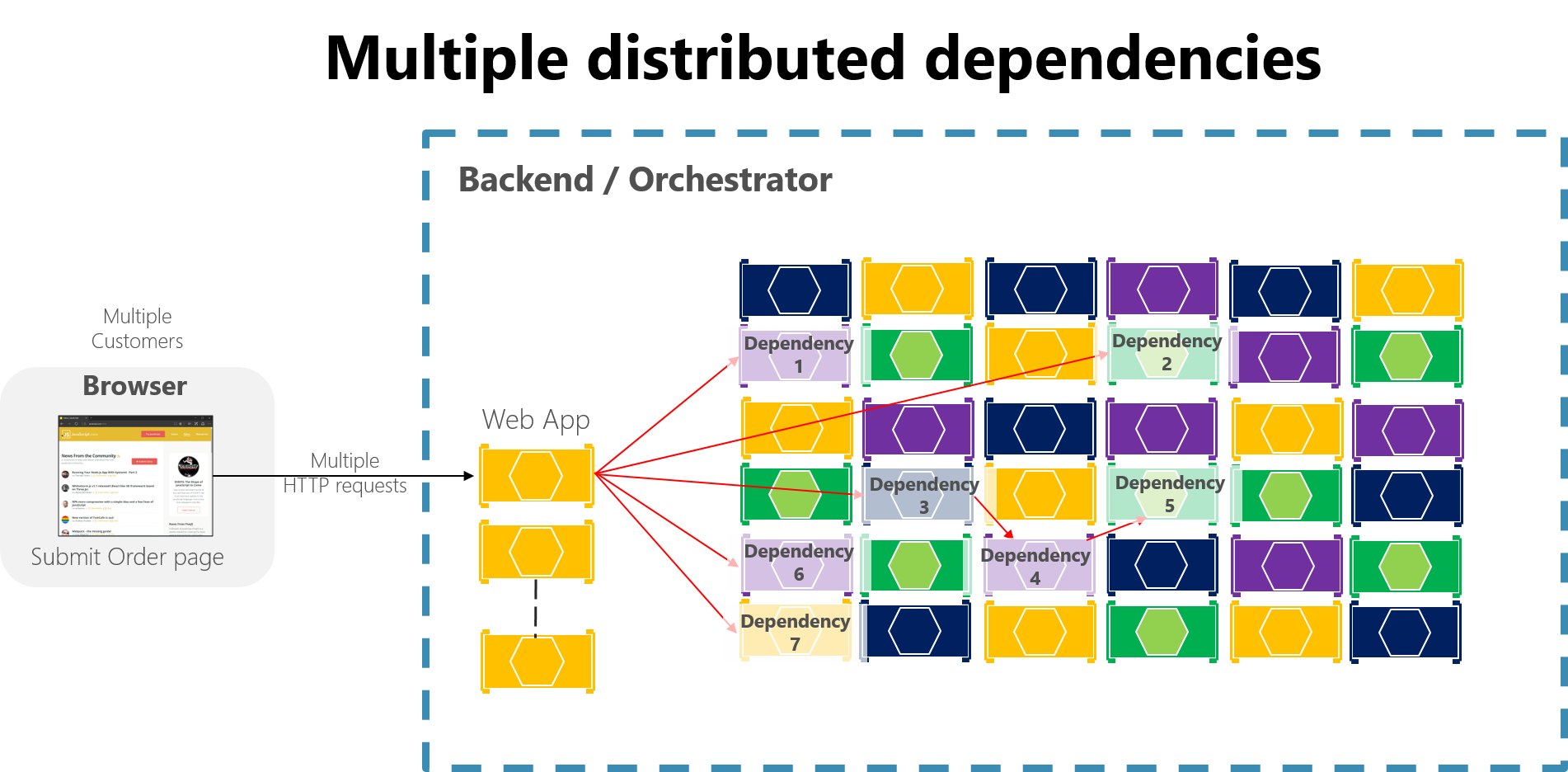
Figura 8-2. O impacto de ter um design incorreto com longas cadeias de solicitações HTTP
A falha intermitente é garantida em um sistema distribuído e baseado em nuvem, mesmo que cada dependência em si tenha excelente disponibilidade. É um fato que você precisa considerar.
Se você não projetar e implementar técnicas para garantir a tolerância a falhas, até mesmo pequenos períodos de inatividade podem ser amplificados. Como exemplo, 50 dependências cada uma com 99,99% de disponibilidade resultariam em várias horas de inatividade por mês devido a esse efeito cascata. Quando uma dependência de microsserviço falha ao lidar com um grande volume de solicitações, essa falha pode saturar rapidamente todos os threads de solicitação disponíveis em cada serviço e travar todo o aplicativo.
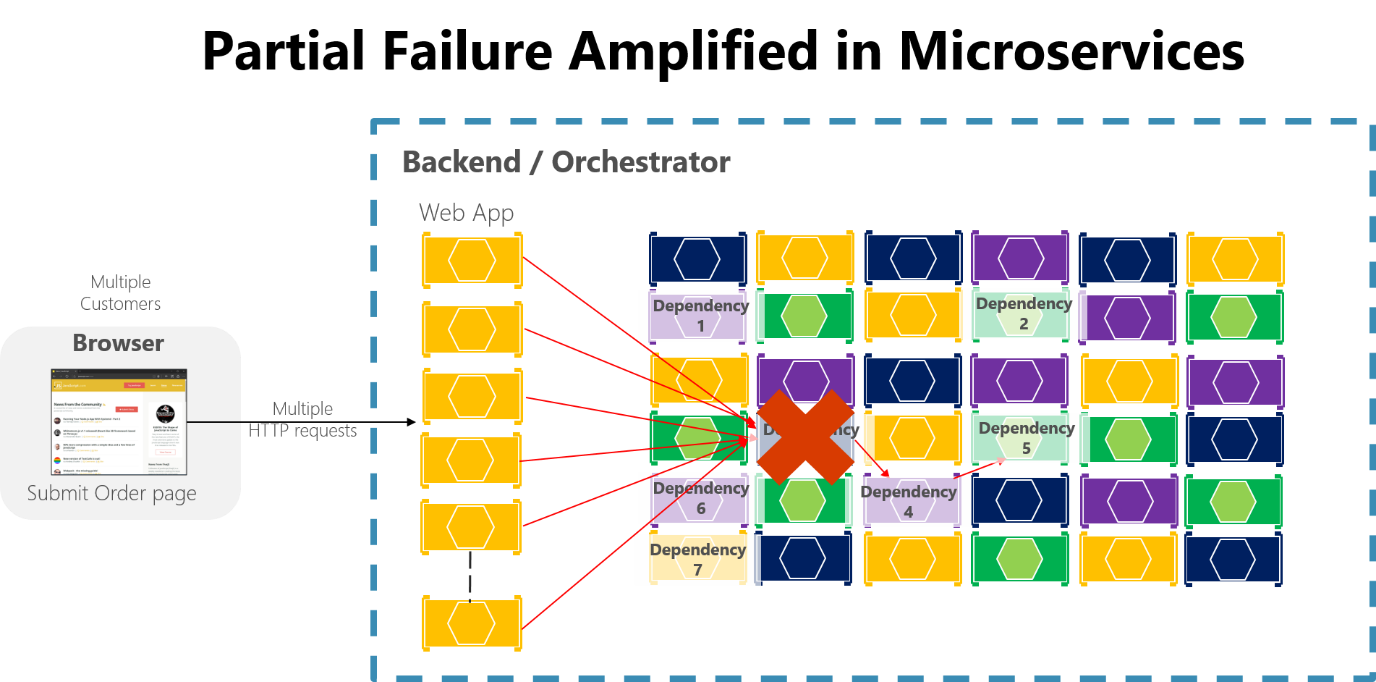
Figura 8-3. Falha parcial amplificada por microsserviços com longas cadeias de chamadas HTTP síncronas
Para minimizar esse problema, na seção A integração assíncrona de microsserviços impõe a autonomia do microsserviço, este guia incentiva o uso de comunicação assíncrona entre os microsserviços internos.
Além disso, é essencial que você projete seus microsserviços e aplicativos cliente para lidar com falhas parciais, ou seja, para criar microsserviços resilientes e aplicativos cliente.
Colabore connosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever issues e pull requests. Para mais informações, consulte o nosso guia para colaboradores.