Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Sugestão
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no do .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Como observado anteriormente, você deve lidar com falhas que podem levar uma quantidade variável de tempo para se recuperar, como pode acontecer quando você tenta se conectar a um serviço ou recurso remoto. Lidar com esse tipo de falha pode melhorar a estabilidade e a resiliência de um aplicativo.
Em um ambiente distribuído, as chamadas para recursos e serviços remotos podem falhar devido a falhas transitórias, como conexões de rede lentas e tempos limites, ou se os recursos estiverem respondendo lentamente ou temporariamente indisponíveis. Essas falhas normalmente se corrigem após um curto período de tempo, e um aplicativo de nuvem robusto deve estar preparado para lidar com elas usando uma estratégia como o "padrão de repetição".
No entanto, também pode haver situações em que as falhas são devidas a eventos imprevistos que podem levar muito mais tempo para serem corrigidos. Estas falhas podem variar em termos de gravidade, de uma perda parcial de conectividade à falha total de um serviço. Nessas situações, pode ser inútil para um aplicativo tentar continuamente uma operação que provavelmente não terá êxito.
Em vez disso, o aplicativo deve ser codificado para aceitar que a operação falhou e lidar com a falha de acordo.
Usar repetições de Http de forma descuidada pode resultar na criação de um ataque de negação de serviço (DoS) dentro do seu próprio software. Como um microsserviço falha ou executa lentamente, vários clientes podem repetir repetidamente solicitações com falha. Isso cria um risco perigoso de aumentar exponencialmente o tráfego direcionado para o serviço com falha.
Portanto, você precisa de algum tipo de barreira de defesa para que os pedidos excessivos parem quando não vale a pena continuar tentando. Essa barreira de defesa é precisamente o disjuntor.
O padrão Circuit Breaker tem uma finalidade diferente do padrão "Retry". O "Padrão de repetição" permite que um aplicativo tente novamente uma operação na expectativa de que a operação seja bem-sucedida. O padrão Disjuntor impede que um aplicativo execute uma operação que provavelmente falhará. Um aplicativo pode combinar esses dois padrões. No entanto, a lógica de repetição deve ser sensível a qualquer exceção retornada pelo disjuntor e deve abandonar as tentativas de repetição se o disjuntor indicar que uma falha não é transitória.
Implementar padrão de disjuntor com IHttpClientFactory e Polly
Assim como na implementação de tentativas, a abordagem recomendada para "circuit breakers" é tirar vantagem de bibliotecas .NET comprovadas, como Polly, e sua integração nativa com IHttpClientFactory.
Adicionar uma política de disjuntor ao pipeline de middleware de saída IHttpClientFactory é tão simples quanto acrescentar uma pequena porção de código incremental ao que já tem ao utilizar IHttpClientFactory.
A única adição aqui ao código usado para novas tentativas de chamada HTTP é o código em que você adiciona a política de disjuntor à lista de políticas a serem usadas, conforme mostrado no código incremental a seguir.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
O AddPolicyHandler() método é o que adiciona políticas aos HttpClient objetos que você usará. Neste caso, está adicionando uma política Polly para um disjuntor.
Para ter uma abordagem mais modular, a Política de Disjuntor é definida em um método separado chamado GetCircuitBreakerPolicy(), conforme mostrado no código a seguir:
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
No exemplo de código acima, a política do disjuntor é configurada para quebrar ou abrir o circuito quando houver cinco falhas consecutivas ao tentar novamente as solicitações Http. Quando isso acontece, o circuito será interrompido por 30 segundos: nesse período, as chamadas falharão imediatamente pelo disjuntor, em vez de serem efetuadas. A política interpreta automaticamente exceções relevantes e códigos de status HTTP como falhas.
Os disjuntores também devem ser usados para redirecionar solicitações para uma infraestrutura de fallback se você tiver problemas em um recurso específico implantado em um ambiente diferente do aplicativo cliente ou serviço que está executando a chamada HTTP. Dessa forma, se houver uma interrupção no datacenter que afete apenas os microsserviços de back-end, mas não os aplicativos cliente, os aplicativos cliente poderão redirecionar para os serviços de fallback. Polly está planejando uma nova política para automatizar esse cenário de política de failover .
Todos esses recursos são para casos em que você está gerenciando o failover de dentro do código .NET, em vez de tê-lo gerenciado automaticamente para você pelo Azure, com transparência de local.
Do ponto de vista do uso, ao usar HttpClient, não há necessidade de adicionar nada de novo aqui, porque o código é o mesmo que ao usar HttpClient com IHttpClientFactory, como mostrado nas seções anteriores.
Teste novas tentativas de Http e disjuntores no eShopOnContainers
Sempre que você inicia a solução eShopOnContainers em um host Docker, ela precisa iniciar vários contêineres. Alguns dos contêineres são mais lentos para iniciar e inicializar, como o contêiner do SQL Server. Isso é especialmente verdadeiro na primeira vez que você implanta o aplicativo eShopOnContainers no Docker, porque ele precisa configurar as imagens e o banco de dados. O fato de que alguns contêineres começam mais lentamente do que outros pode fazer com que o restante dos serviços lance inicialmente exceções HTTP, mesmo se você definir dependências entre contêineres no nível docker-compose, conforme explicado nas seções anteriores. Essas dependências do docker-compose entre containers estão apenas no nível do processo. O processo de ponto de entrada do contêiner pode ser iniciado, mas o SQL Server pode não estar pronto para consultas. O resultado pode ser uma cascata de erros, e o aplicativo pode obter uma exceção ao tentar consumir esse contêiner específico.
Você também pode ver esse tipo de erro na inicialização quando o aplicativo está sendo implantado na nuvem. Nesse caso, os orquestradores podem estar movendo contentores de um nó ou de uma VM para outra (ou seja, iniciando novas instâncias) quando equilibram o número de contentores entre os nós do cluster.
A maneira como 'eShopOnContainers' resolve esses problemas ao iniciar todos os contêineres é usando o padrão Retry ilustrado anteriormente.
Teste o disjuntor no eShopOnContainers
Existem algumas maneiras de interromper/abrir o circuito e testá-lo com o eShopOnContainers.
Uma opção é reduzir o número permitido de novas tentativas para 1 na política de disjuntor e reimplantar toda a solução no Docker. Com uma única tentativa, há uma boa chance de que uma solicitação HTTP falhe durante a implantação, o disjuntor seja aberto e você obtenha um erro.
Outra opção é usar middleware personalizado que é implementado no microsserviço Basket . Quando esse middleware está habilitado, ele captura todas as solicitações HTTP e retorna o código de status 500. Você pode habilitar o middleware fazendo uma solicitação GET para o URI com falha, da seguinte forma:
GET http://localhost:5103/failing
Essa solicitação retorna o estado atual do middleware. Se o middleware estiver habilitado, a solicitação retornará o código de status 500. Se o middleware estiver desativado, não haverá resposta.GET http://localhost:5103/failing?enable
Essa solicitação habilita o middleware.GET http://localhost:5103/failing?disable
Esta solicitação desativa o middleware.
Por exemplo, quando o aplicativo estiver em execução, você poderá habilitar o middleware fazendo uma solicitação usando o seguinte URI em qualquer navegador. Observe que o microsserviço de pedido usa a porta 5103.
http://localhost:5103/failing?enable
Em seguida, você pode verificar o status usando o URI http://localhost:5103/failing, como mostra a Figura 8-5.
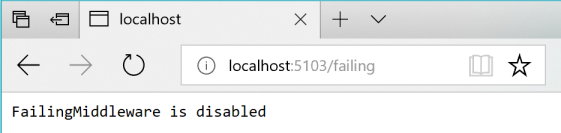
Figura 8-5. Verificando o estado do middleware ASP.NET "Falha" – Neste caso, desativado.
Neste ponto, o microsserviço Basket responde com o código de status 500 sempre que você o chama.
Quando o middleware estiver em execução, você pode tentar fazer um pedido a partir do aplicativo Web MVC. Como as solicitações falham, o circuito será aberto.
No exemplo a seguir, pode-se ver que a aplicação Web MVC tem um bloco catch na lógica para efetuar um pedido. Se o código interceptar uma exceção de circuito aberto, ele mostra ao usuário uma mensagem amigável para que aguarde.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Aqui está um resumo. A política Repetir tenta várias vezes fazer a solicitação HTTP e obtém erros HTTP. Quando o número de tentativas de reexecução atinge o número máximo definido para a política de Circuit Breaker (neste caso, 5), a aplicação lança uma BrokenCircuitException. O resultado é uma mensagem amigável, como mostra a Figura 8-6.
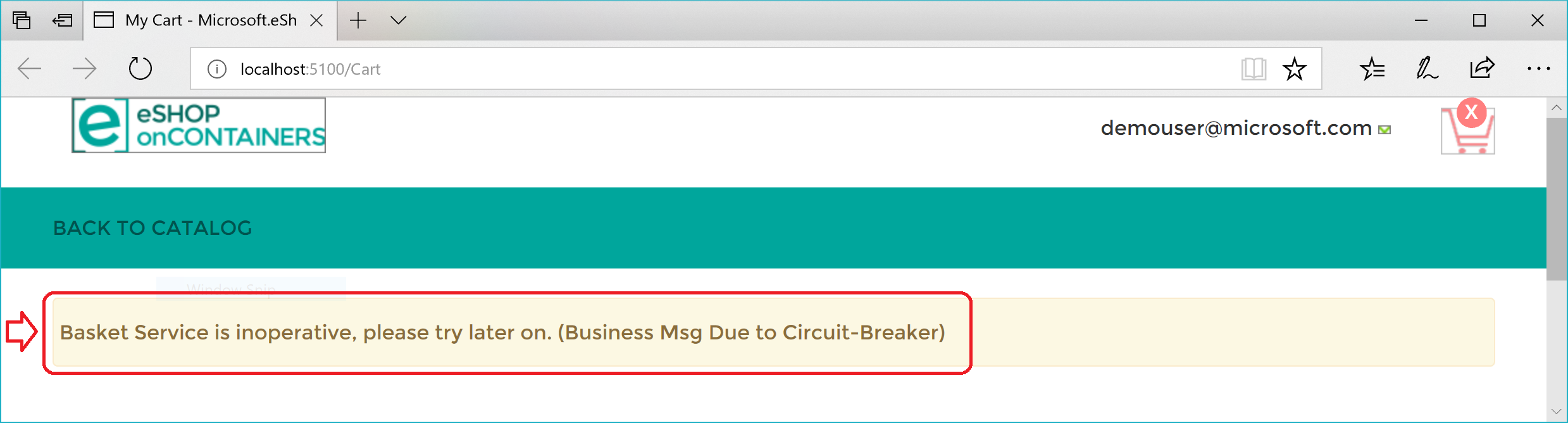
Figura 8-6. Disjuntor retornando um erro para a interface do usuário
Você pode implementar uma lógica diferente para quando abrir/quebrar o circuito. Ou você pode tentar uma solicitação HTTP em um microsserviço back-end diferente se houver um datacenter de fallback ou um sistema back-end redundante.
Finalmente, outra possibilidade para o CircuitBreakerPolicy é usar Isolate (que força a abertura e mantém aberto o circuito) e Reset (que o fecha novamente). Eles podem ser usados para criar um ponto de extremidade HTTP de utilidade que chame diretamente Isolar e Redefinir dentro da política. Este ponto de extremidade HTTP também pode ser usado, adequadamente protegido, no ambiente de produção para isolar temporariamente um sistema subsequente, como quando se pretende atualizá-lo. Ou pode acionar o circuito manualmente para proteger um sistema a jusante se suspeitar que esteja com defeito.
Recursos adicionais
-
Padrão Circuit Breaker
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.