Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Sugestão
Este conteúdo é um excerto do eBook, Architect Modern Web Applications with ASP.NET Core e Azure, disponível no .NET Docs ou como um PDF transferível gratuito que pode ser lido offline.

"Se os construtores construíssem edifícios como os programadores escreviam programas, então o primeiro pica-pau que aparecesse destruiria a civilização."
- Gerald Weinberg
Você deve arquitetar e projetar soluções de software com a manutenção em mente. Os princípios descritos nesta seção podem ajudar a guiá-lo para decisões de arquitetura que resultarão em aplicativos limpos e fáceis de manter. Geralmente, esses princípios irão guiá-lo para a criação de aplicativos a partir de componentes discretos que não estão fortemente acoplados a outras partes do seu aplicativo, mas se comunicam por meio de interfaces explícitas ou sistemas de mensagens.
Princípios comuns de conceção
Separação de responsabilidades
Um princípio orientador ao desenvolver é a Separação de Responsabilidades. Este princípio afirma que o software deve ser separado com base nos tipos de trabalho que executa. Por exemplo, considere um aplicativo que inclua lógica para identificar itens notáveis para exibir ao usuário e que formate esses itens de uma maneira específica para torná-los mais percetíveis. O comportamento responsável pela escolha de quais itens formatar deve ser mantido separado do comportamento responsável pela formatação dos itens, uma vez que esses comportamentos são preocupações separadas que só coincidentemente estão relacionadas entre si.
Arquitetonicamente, os aplicativos podem ser logicamente criados para seguir esse princípio, separando o comportamento comercial principal da lógica de infraestrutura e interface do usuário. Idealmente, as regras de negócios e a lógica devem residir em um projeto separado, que não deve depender de outros projetos no aplicativo. Essa separação ajuda a garantir que o modelo de negócios seja fácil de testar e possa evoluir sem estar fortemente acoplado a detalhes de implementação de baixo nível (também ajuda se as preocupações com a infraestrutura dependerem de abstrações definidas na camada de negócios). A separação de preocupações é uma consideração fundamental por trás do uso de camadas em arquiteturas de aplicativos.
Encapsulamento
Diferentes partes de um aplicativo devem usar encapsulamento para isolá-las de outras partes do aplicativo. Os componentes e camadas do aplicativo devem ser capazes de ajustar sua implementação interna sem quebrar seus colaboradores, desde que os contratos externos não sejam violados. O uso adequado do encapsulamento ajuda a alcançar acoplamento flexível e modularidade em projetos de aplicativos, uma vez que objetos e pacotes podem ser substituídos por implementações alternativas, desde que a mesma interface seja mantida.
Nas classes, o encapsulamento é obtido limitando o acesso externo ao estado interno da classe. Se um ator externo quiser manipular o estado do objeto, ele deve fazê-lo através de uma função bem definida (ou setter de propriedade), em vez de ter acesso direto ao estado privado do objeto. Da mesma forma, os próprios componentes de aplicativos e aplicativos devem expor interfaces bem definidas para seus colaboradores usarem, em vez de permitir que seu estado seja modificado diretamente. Esta abordagem liberta a estrutura interna da aplicação para evoluir ao longo do tempo sem preocupações de que isto prejudicará a colaboração, desde que os contratos públicos sejam mantidos.
O estado global mutável é contrário ao encapsulamento. Um valor obtido do estado global mutável em uma função não pode ser considerado para ter o mesmo valor em outra função (ou ainda mais na mesma função). Compreender as preocupações com o estado global mutável é uma das razões pelas quais linguagens de programação como C# têm suporte para diferentes regras de escopo, que são usadas em todos os lugares, de instruções a métodos e classes. Vale a pena notar que as arquiteturas orientadas por dados que dependem de um banco de dados central para integração dentro e entre aplicativos estão, elas próprias, optando por depender do estado global mutável representado pelo banco de dados. Uma consideração importante no design controlado por domínio e na arquitetura limpa é como encapsular o acesso aos dados e como garantir que o estado do aplicativo não seja invalidado pelo acesso direto ao seu formato de persistência.
Inversão de dependência
A direção da dependência dentro do aplicativo deve ser na direção da abstração, não detalhes da implementação. A maioria dos softwares é desenvolvida de forma que as dependências de compilação fluam na direção das dependências de execução, produzindo um gráfico de dependências diretas. Ou seja, se a classe A chama um método da classe B e a classe B chama um método da classe C, então, em tempo de compilação, a classe A dependerá da classe B, e a classe B dependerá da classe C, como mostra a Figura 4-1.
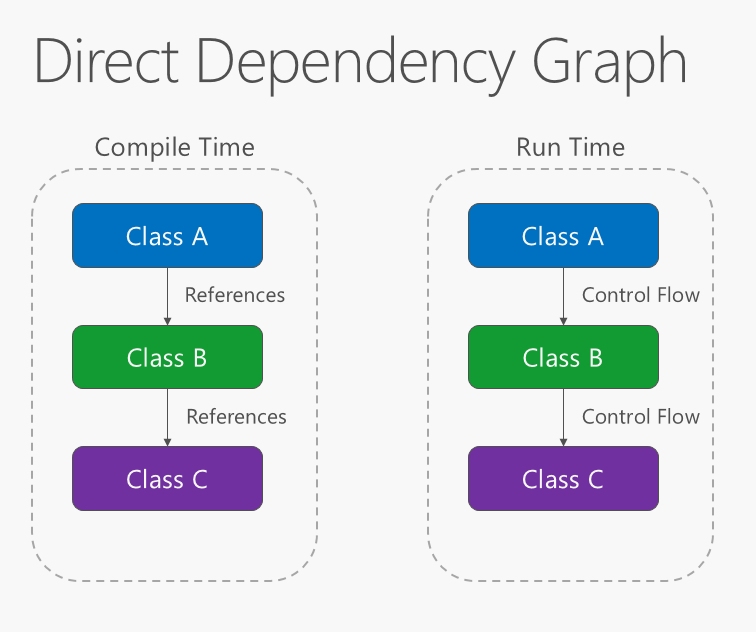
Figura 4-1. Gráfico de dependência direta.
A aplicação do princípio de inversão de dependência permite que A chame métodos em uma abstração que B implementa, tornando possível para A chamar B em tempo de execução, mas para B depender de uma interface controlada por A em tempo de compilação (assim, invertendo a dependência típica em tempo de compilação). Em tempo de execução, o fluxo de execução do programa permanece inalterado, mas a introdução de interfaces significa que diferentes implementações dessas interfaces podem ser facilmente conectadas.
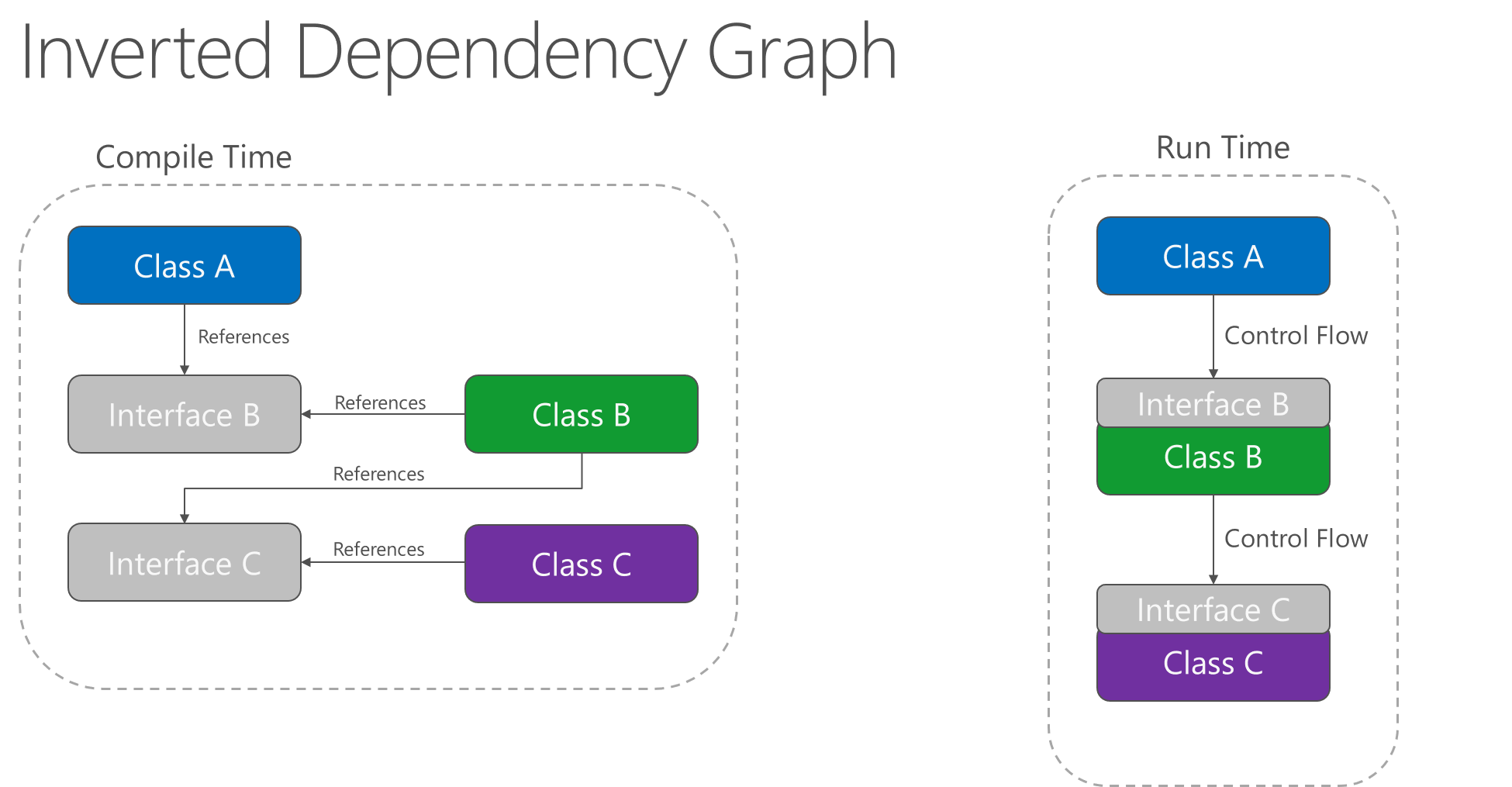
Figura 4-2. Gráfico de dependência invertida.
Inversão de dependências é uma parte fundamental da criação de aplicativos com baixo acoplamento, uma vez que os detalhes da implementação podem ser projetados para depender de e implementar abstrações de nível mais alto, em vez do contrário. Como resultado, os aplicativos resultantes são mais testáveis, modulares e fáceis de manter. A prática da injeção de dependência é possível seguindo o princípio da inversão de dependência.
Dependências explícitas
Métodos e classes devem exigir explicitamente quaisquer objetos de colaboração necessários para funcionar corretamente. É o chamado Princípio das Dependências Explícitas. Os construtores de classe fornecem uma oportunidade para as classes identificarem as coisas de que precisam para estar em um estado válido e funcionar corretamente. Se você definir classes que podem ser construídas e chamadas, mas que só funcionarão corretamente se determinados componentes globais ou de infraestrutura estiverem em vigor, essas classes estão sendo desonestas com seus clientes. O contrato do construtor está dizendo ao cliente que ele só precisa das coisas especificadas (possivelmente nada se a classe estiver apenas usando um construtor sem parâmetros), mas em tempo de execução acontece que o objeto realmente precisava de outra coisa.
Ao seguir o princípio das dependências explícitas, suas classes e métodos estão sendo honestos com seus clientes sobre o que eles precisam para funcionar. Seguir o princípio torna seu código mais auto-documentável e seus contratos de codificação mais fáceis de usar, uma vez que os usuários passarão a confiar que, desde que forneçam o que é necessário na forma de parâmetros de método ou construtor, os objetos com os quais estão trabalhando se comportarão corretamente em tempo de execução.
Responsabilidade única
O princípio da responsabilidade única aplica-se ao projeto orientado a objetos, mas também pode ser considerado como um princípio arquitetônico semelhante à separação de preocupações. Afirma que os objetos devem ter apenas uma responsabilidade e que devem ter apenas uma razão para mudar. Especificamente, a única situação em que o objeto deve mudar é se a maneira como ele executa sua única responsabilidade deve ser atualizada. Seguir este princípio ajuda a produzir sistemas mais flexíveis e modulares, uma vez que muitos tipos de novo comportamento podem ser implementados como novas classes, em vez de adicionar responsabilidade adicional às classes existentes. Adicionar novas classes é sempre mais seguro do que alterar classes existentes, uma vez que nenhum código ainda depende das novas classes.
Em uma aplicação monolítica, podemos aplicar o princípio de responsabilidade única em alto nível às camadas da aplicação. A responsabilidade de apresentação deve permanecer no projeto de interface do usuário, enquanto a responsabilidade de acesso a dados deve ser mantida dentro de um projeto de infraestrutura. A lógica de negócios deve ser mantida no projeto principal do aplicativo, onde pode ser facilmente testada e pode evoluir independentemente de outras responsabilidades.
Quando esse princípio é aplicado à arquitetura de aplicativos e levado ao seu ponto de extremidade lógico, você obtém microsserviços. Um determinado microsserviço deve ter uma única responsabilidade. Se você precisar estender o comportamento de um sistema, geralmente é melhor fazê-lo adicionando microsserviços adicionais, em vez de adicionar responsabilidade a um existente.
Saiba mais sobre a arquitetura de microsserviços
Não se repita (DRY)
O aplicativo deve evitar especificar o comportamento relacionado a um determinado conceito em vários lugares, pois essa prática é uma fonte frequente de erros. Em algum momento, uma mudança nos requisitos exigirá a mudança desse comportamento. É provável que pelo menos uma instância do comportamento não seja atualizada e o sistema se comporte de forma inconsistente.
Em vez de duplicar a lógica, encapsula-a em uma construção de programação. Faça dessa construção a única autoridade sobre esse comportamento e faça com que qualquer outra parte do aplicativo que exija esse comportamento use a nova construção.
Observação
Evite ligar comportamentos que são apenas coincidentemente repetitivos. Por exemplo, só porque duas constantes diferentes têm o mesmo valor, isso não significa que você deva ter apenas uma constante, se conceitualmente elas estão se referindo a coisas diferentes. A duplicação é sempre preferível ao acoplamento à abstração errada.
Ignorância persistente
A ignorância de persistência (PI) refere-se a tipos que precisam ser persistentes, mas cujo código não é afetado pela escolha da tecnologia de persistência. Esses tipos no .NET às vezes são chamados de POCOs (Plain Old CLR Objects), porque eles não precisam herdar de uma classe base específica ou implementar uma interface específica. A ignorância persistente é valiosa porque permite que o mesmo modelo de negócios seja persistido de várias maneiras, oferecendo flexibilidade adicional ao aplicativo. As opções de persistência podem mudar ao longo do tempo, de uma tecnologia de banco de dados para outra, ou formas adicionais de persistência podem ser necessárias além do que o aplicativo começou com (por exemplo, usando um cache Redis ou Azure Cosmos DB além de um banco de dados relacional).
Alguns exemplos de violações deste princípio incluem:
Uma classe base necessária.
Uma implementação de interface necessária.
Classes responsáveis por se salvarem (como o padrão Active Record).
É necessário um construtor sem parâmetros.
Propriedades que requerem palavra-chave virtual.
Atributos específicos necessários para a persistência.
O requisito de que as classes tenham qualquer um dos recursos ou comportamentos acima adiciona acoplamento entre os tipos a serem persistidos e a escolha da tecnologia de persistência, dificultando a adoção de novas estratégias de acesso a dados no futuro.
Contextos delimitados
Contextos delimitados são um padrão central no Domain-Driven Design. Eles fornecem uma maneira de lidar com a complexidade em grandes aplicativos ou organizações, dividindo-a em módulos conceituais separados. Cada módulo conceitual representa um contexto que é separado de outros contextos (portanto, limitado) e pode evoluir independentemente. Idealmente, cada contexto delimitado deve ser livre para escolher seus próprios nomes para conceitos dentro dele, e deve ter acesso exclusivo ao seu próprio repositório de persistência.
No mínimo, as aplicações web individuais devem esforçar-se por ser o seu próprio contexto delimitado, com o seu próprio repositório de persistência para o seu modelo de negócios, em vez de partilharem uma base de dados com outras aplicações. A comunicação entre contextos limitados ocorre por meio de interfaces programáticas, em vez de por meio de um banco de dados compartilhado, o que permite que a lógica de negócios e os eventos ocorram em resposta às mudanças que ocorrem. Os contextos limitados correspondem estreitamente aos microsserviços, que também são idealmente implementados como os seus próprios contextos limitados individuais.
Recursos adicionais
Colabore connosco no GitHub
A origem deste conteúdo pode ser encontrada no GitHub, onde também pode criar e rever problemas e pedidos Pull. Para mais informações, consulte o nosso guia do contribuidor.