Ligar a tabelas do Common Data Model no Azure Data Lake Storage
Nota
O Azure Active Directory é agora Microsoft Entra ID. Mais informações
Ingerir dados para o Dynamics 365 Customer Insights - Data através da sua conta do Azure Data Lake Storage com tabelas do Common Data Model. A ingestão de dados pode ser total ou incremental.
Pré-requisitos
A conta do Azure Data Lake Storage têm de ter um espaço de nomes hierárquico ativado. Os dados têm de ser armazenados num formato de pasta hierárquica que defina a pasta raiz e que tenha subpastas para cada tabela. As subpastas podem ter pastas de dados totais ou incrementais.
Para autenticar com um principal de serviço do Microsoft Entra, certifique-se de que está configurado no seu inquilino. Para mais informações, consulte Ligar a uma conta do Azure Data Lake Storage com um principal de serviço do Microsoft Entra.
O Azure Data Lake Storage de onde pretende ligar e ingerir dados tem de estar na mesma região do Azure que o ambiente do Dynamics 365 Customer Insights e as subscrições têm de estar no mesmo inquilino. As ligações a uma pasta Common Data Model a partir de um data lake numa região do Azure diferente não são suportadas. Para saber qual a região do Azure do ambiente, aceda a Definições>Sistema>Acerca de no Customer Insights - Data.
Os dados armazenados em serviços online podem ser armazenados numa localização diferente do local onde os dados são tratados ou armazenados. Ao importar, ou ligar a, os dados armazenados em serviços online, concorda que os dados podem ser transferidos. Saiba mais no Centro de Confiança da Microsoft.
O principal de serviço do Customer Insights - Data tem de ter uma das funções que seguem para aceder à conta de armazenamento. Para mais informações, consulte Conceder permissões ao principal de serviço para aceder à conta de armazenamento.
- Leitor de Dados de Blobs de Armazenamento
- Proprietário de Dados de Blobs de Armazenamento
- Contribuidor de Dados de Blobs de Armazenamento
Ao ligar-se ao armazenamento do Azure através da opção Subscrição do Azure, o utilizador que configura a ligação à origem de dados precisa de, pelo menos, permissões de Contribuidor de Dados de Blob de Armazenamento na conta de armazenamento.
Ao ligar-se ao armazenamento do Azure através da opção Recurso do Azure, o utilizador que configura a ligação à origem de dados precisa de, pelo menos, a permissão a ação Microsoft.Storage/storageAccounts/read na conta de armazenamento. Uma Função incorporada do Azure que inclui esta ação é a função Leitor. Para limitar o acesso apenas à ação necessária, crie uma função personalizada do Azure que inclua apenas esta ação.
Para um desempenho excelente, o tamanho de uma partição deve ser de 1 GB ou menos e o número de ficheiros de partição numa pasta não pode exceder 1000.
Os dados no Data Lake Storage devem seguir o padrão do Common Data Model para armazenamento dos seus dados e ter o manifesto do Common Data Model para representar o esquema dos ficheiros de dados (*.csv ou *.parquet). O manifesto tem de fornecer os detalhes das tabelas, tais como colunas de tabela e tipos de dados, bem como a localização do ficheiro de dados e o tipo de ficheiro. Para mais informações, consulte sobre O manifesto do Common Data Model. Se o manifesto não estiver presente, os Utilizadores administradores com o acesso de Proprietário de Dados de Blob de Armazenamento ou de Contribuidor de Dados de Blob de Armazenamento podem definir o esquema durante a ingestão dos dados.
Nota
Se qualquer um dos campos nos ficheiros .parquet tiver o tipo de dados Int96, os dados poderão não ser apresentados na página Tabelas. Recomendamos a utilização de tipos de dados padrão, como o formato de data/hora Unix (que representa a hora como o número de segundos desde 1 de janeiro de 1970, à meia-noite UTC).
Limitações
- O Customer Insights - Data não suporta colunas do tipo decimal com precisão superior a 16.
Ligar ao Azure Data Lake Storage
Aceda a Dados>Origens de dados.
Selecione Adicionar uma origem de dados.
Selecione Tabelas do Common Data Model do Azure Data Lake.

Introduza um Nome de origem de dados e uma Descrição opcional. O nome é referenciado em processos a jusante e não é possível alterá-lo depois de criar a origem de dados.
Escolha uma das seguintes opções para Ligar o armazenamento utilizando. Para mais informações, consulte Ligar a uma conta do Azure Data Lake Storage com um principal de serviço do Microsoft Entra.
- Recurso do Azure: introduza o ID do Recurso. (private-link.md).
- Subscrição do Azure: selecione a Subscrição e, em seguida, o Grupo de recursos e a Conta de armazenamento.
Nota
Necessita de uma das seguintes funções para o contentor para criar a origem de dados:
- O Leitor de Dados de Blobs de Armazenamento é suficiente para ler a partir de uma conta de armazenamento e ingerir os dados para o Customer Insights - Data.
- É necessário o Contribuidor ou Proprietário de Dados de Blobs de Armazenamento se quiser editar os ficheiros de manifesto diretamente no Customer Insights - Data.
Ter a função na conta de armazenamento fornecerá a mesma função em todos os seus contentores.
Opcionalmente, se pretender ingerir dados de uma conta de armazenamento através de uma Azure Private Link, selecione Ativar Private Link. Para obter mais informações, consulte Private Links.
Escolha o nome do Contentor que contém os dados e o esquema (ficheiro model.json ou manifest.json) a partir do qual os dados serão importados e selecione Seguinte.
Nota
Qualquer ficheiro model.json ou manifest.json associado a outra origem de dados no ambiente não aparecerá na lista. No entanto, o mesmo ficheiro model.json ou manifest.json pode ser usado para origens de dados em vários ambientes.
Para criar um novo esquema, aceda a Criar um novo ficheiro de esquema.
Para utilizar um esquema existente, navegue para a pasta que contém o ficheiro model.json ou manifest.cdm.json. Pode pesquisar num diretório para encontrar o ficheiro.
Selecione o ficheiro json e selecione Seguinte. É apresentada uma lista de tabelas disponíveis.
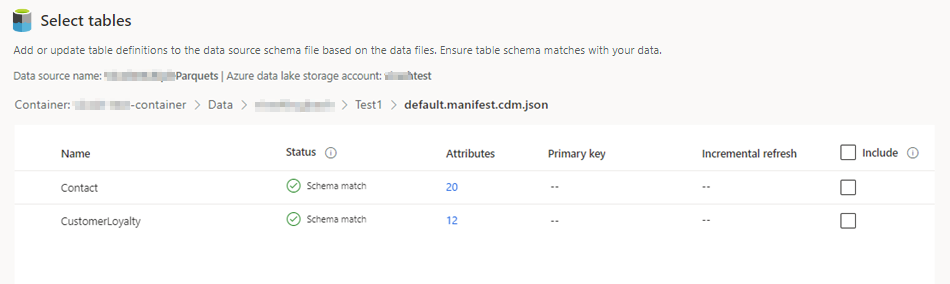
Selecione as tabelas que pretende incluir.
Sugestão
Para editar uma tabela numa interface de edição JSON, selecione a tabela e, em seguida, Editar ficheiro de esquema. Efetue as alterações e selecione Guardar.
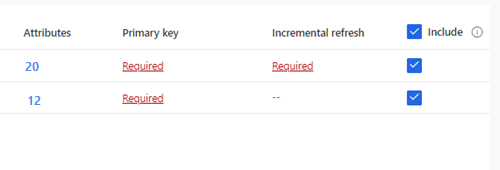
Para as tabelas selecionadas que necessitam de ingestão incremental, é apresentado Obrigatório sob Atualização incremental. Para cada uma destas tabelas, consulte Configurar uma atualização incremental para origens de dados do Azure Data Lake.
Para tabelas selecionadas onde uma chave primária não tenha sido definida, é apresentado Obrigatório sob Chave primária. Para cada uma destas tabelas:
- Selecione Obrigatória. É apresentado o painel Editar tabela.
- Escolha a Chave primária. A chave primária é um atributo exclusivo da tabela. Para que um atributo seja uma chave primária válida, não deve incluir valores duplicados, valores em falta ou valores nulos. Os atributos de cadeia, número inteiro e tipo de dados GUID são suportados como chaves primárias.
- Opcionalmente, altere o padrão de partição.
- Selecione Fechar para guardar e fechar o painel.
Selecione o número de Colunas para cada tabela incluída. É apresentada a página Gerir atributos.
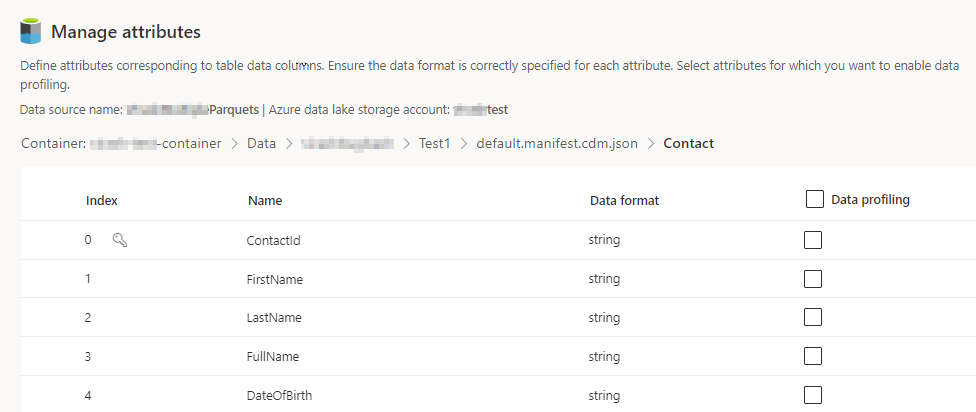
- Crie novas colunas, edite ou elimine as colunas existentes. Pode alterar o nome, o formato de dados ou adicionar um tipo de semântica.
- Para ativar a análise e outras capacidades, selecione Análise para otimização de dados para toda a tabela ou para colunas específicas. Por predefinição, nenhuma tabela está ativada para a análise para otimização de dados.
- Selecione Concluído.
Selecione Guardar. A página Origens de dados é aberta a mostrar a origem de dados novas no estado A atualizar.
Sugestão
Existem estados para tarefas e processos. A maioria dos processos depende de outros processos de origem, tais como origens de dados e atualizações da criação de perfis de dados.
Selecione o estado para abrir o painel Detalhes do progresso e ver o progresso das tarefas. Para cancelar a tarefa, selecione Cancelar tarefa na parte inferior do painel.
Em cada tarefa, pode selecionar Ver detalhes para obter mais informações sobre o progresso, tais como o tempo de processamento, a data do último processamento, e quaisquer erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Ver estado do sistema na parte inferior do painel para ver outros processos no sistema.

O carregamento de dados pode levar tempo. Após uma atualização bem-sucedida, os dados ingeridos podem ser revistos na página Tabelas.
Criar um novo ficheiro de esquema
Selecione Criar ficheiro de esquema.
Introduza um nome para o ficheiro e selecione Guardar.
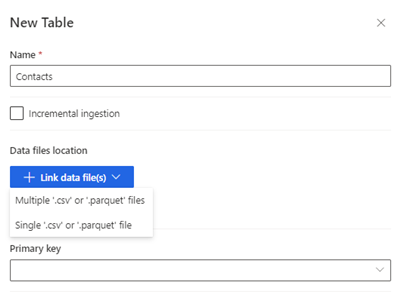
Selecione Nova tabela. É apresentado o painel Nova Tabela.
Introduza o nome da tabela e escolha a Localização dos ficheiros de dados.
- Vários ficheiros .csv ou .parquet: navegue para a pasta raiz, selecione o tipo de padrão e introduza a expressão.
- Ficheiros .csv ou .parquet únicos: navegue para o ficheiro .csv ou .parquet e selecione-o.
Selecione Guardar.
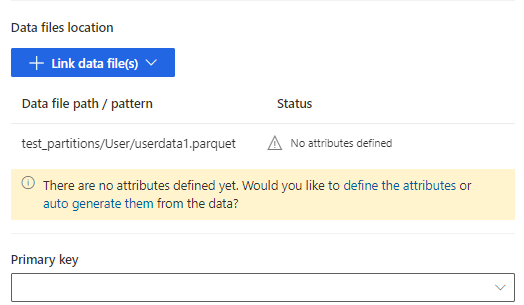
Selecione definir os atributos para adicionar manualmente os atributos ou selecione gerá-los automaticamente. Para definir os atributos, introduza um nome, selecione o formato de dados e o tipo de semântica opcional. Para atributos gerados automaticamente:
Depois de os atributos serem gerados automaticamente, selecione Rever atributos. É apresentada a página Gerir atributos.
Certifique-se de que o formato de dados está correto para cada atributo.
Para ativar a análise e outras capacidades, selecione Análise para otimização de dados para toda a tabela ou para colunas específicas. Por predefinição, nenhuma tabela está ativada para a análise para otimização de dados.
Selecione Concluído. A página Selecionar tabelas é apresentada.
Continue a adicionar tabelas e colunas, se aplicável.
Depois de todas as tabelas terem sido adicionadas, selecione Incluir para incluir as tabelas na ingestão de origem de dados.
Para as tabelas selecionadas que necessitam de ingestão incremental, é apresentado Obrigatório sob Atualização incremental. Para cada uma destas tabelas, consulte Configurar uma atualização incremental para origens de dados do Azure Data Lake.
Para tabelas selecionadas onde uma chave primária não tenha sido definida, é apresentado Obrigatório sob Chave primária. Para cada uma destas tabelas:
- Selecione Obrigatória. É apresentado o painel Editar tabela.
- Escolha a Chave primária. A chave primária é um atributo exclusivo da tabela. Para que um atributo seja uma chave primária válida, não deve incluir valores duplicados, valores em falta ou valores nulos. Os atributos de cadeia, número inteiro e tipo de dados GUID são suportados como chaves primárias.
- Opcionalmente, altere o padrão de partição.
- Selecione Fechar para guardar e fechar o painel.
Selecione Guardar. A página Origens de dados é aberta a mostrar a origem de dados novas no estado A atualizar.
Sugestão
Existem estados para tarefas e processos. A maioria dos processos depende de outros processos de origem, tais como origens de dados e atualizações da criação de perfis de dados.
Selecione o estado para abrir o painel Detalhes do progresso e ver o progresso das tarefas. Para cancelar a tarefa, selecione Cancelar tarefa na parte inferior do painel.
Em cada tarefa, pode selecionar Ver detalhes para obter mais informações sobre o progresso, tais como o tempo de processamento, a data do último processamento, e quaisquer erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Ver estado do sistema na parte inferior do painel para ver outros processos no sistema.
O carregamento de dados pode levar tempo. Após uma atualização bem-sucedida, os dados ingeridos podem ser revistos na página Dados>Tabelas.
Editar uma origem de dados do Azure Data Lake Storage
Pode atualizar a opção Ligar a conta de armazenamento utilizando. Para mais informações, consulte Ligar a uma conta do Azure Data Lake Storage com um principal de serviço do Microsoft Entra. Para ligar a um contentor diferente da conta de armazenamento ou alterar o nome da conta, tem de criar uma nova ligação à origem de dados.
Aceda a Dados>Origens de dados. Junto da origem de dados que pretende atualizar, selecione Editar.
Altere quaisquer das seguintes informações:
Descrição
Ligar o armazenamento utilizando e informações de ligação. Não é possível alterar as informações do Recipiente ao atualizar a ligação.
Nota
Uma das seguintes funções tem de ser atribuída à conta ou armazenamento ou contentor:
- Leitor de Dados de Blobs de Armazenamento
- Proprietário de Dados de Blobs de Armazenamento
- Contribuidor de Dados de Blobs de Armazenamento
Utilizar identidades geridas para o Azure com o seu Azure Data Lake Storage ???
Ativar Private Link se pretender ingerir dados de uma conta de armazenamento através de uma Azure Private Link. Para obter mais informações, consulte Private Links.
Selecione Seguinte.
Altere qualquer um dos seguintes:
Navegue para um ficheiro model.json ou manifest.json diferente com um conjunto diferente de tabelas do contentor.
Para adicionar tabelas adicionais a ingerir, selecione Nova tabela.
Para remover quaisquer tabelas já selecionadas, se não existirem dependências, selecione a tabela e selecione Eliminar.
Importante
Se houver dependências do ficheiro model.json ou manifest.json existente e do conjunto de tabelas, verá uma mensagem de erro e não poderá selecionar um ficheiro model.json ou manifest.json diferente. Remova essas dependências antes de alterar o ficheiro model.json ou manifest.json ou criar uma nova origem de dados com o ficheiro model.json ou manifest.json que pretende utilizar para evitar a remoção das dependências.
Para alterar a localização do ficheiro de dados ou a chave primária, selecione Editar.
Para alterar os dados de ingestão incremental, consulte Configurar uma atualização incremental para origens de dados do Azure Data Lake.
Altere apenas o nome de tabela para corresponder ao nome de tabela no ficheiro .json.
Nota
Mantenha sempre o mesmo nome da tabela que o nome da tabela no ficheiro model.json ou manifest.json após a ingestão. O Customer Insights - Data valida todos os nomes de tabela com o model.json ou manifest.json durante cada atualização de sistema. Se um nome de tabela for alterado, ocorre um erro porque o Customer Insights - Data não consegue encontrar o novo nome de tabela no ficheiro .json. Se um nome de tabela ingerido foi alterado acidentalmente, edite o nome da tabela para corresponder ao nome no ficheiro .json.
Selecione Colunas para as adicionar ou alterar, ou para ativar a análise para otimização de dados. Em seguida, selecione Concluir.
Selecione Guardar para aplicar as alterações e regressar à página Origens de dados.
Sugestão
Existem estados para tarefas e processos. A maioria dos processos depende de outros processos de origem, tais como origens de dados e atualizações da criação de perfis de dados.
Selecione o estado para abrir o painel Detalhes do progresso e ver o progresso das tarefas. Para cancelar a tarefa, selecione Cancelar tarefa na parte inferior do painel.
Em cada tarefa, pode selecionar Ver detalhes para obter mais informações sobre o progresso, tais como o tempo de processamento, a data do último processamento, e quaisquer erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Ver estado do sistema na parte inferior do painel para ver outros processos no sistema.