Remover duplicados de cada tabela para unificação de dados
O passo da unificação Regras de duplicação encontra e remove registos duplicados de um cliente a partir de uma tabela de origem, para que cada cliente seja representado por uma única linha em cada tabela. Cada tabela tem os duplicados removidos separadamente com regras para identificar os registos de um determinado cliente.
As regras são processadas por ordem. Depois de todas as regras terem sido executadas em todos os registos numa tabela, os grupos de correspondência que partilham uma linha comum são combinados num único grupo de correspondência.
Definir regras de eliminação de duplicados
Uma boa regra identifica um cliente exclusivo. Considere os seus dados. Pode ser suficiente identificar clientes com base num campo como o e-mail. No entanto, se pretender diferenciar os clientes que partilham um e-mail, pode optar por ter uma regra com duas condições, que correspondam em E-mail + Nome Próprio. Para obter mais informações, consulte Conceitos e cenários de eliminação de duplicados.
Na página Regras de duplicação, selecione uma tabela e selecione Adicionar regra para definir as regras de duplicação.
Sugestão
Se tiver melhorado tabelas ao nível origem de dados para ajudar a melhorar os resultados de unificação, selecione Utilizar tabelas melhoradas no topo da página. Para obter mais informações, consulte Melhoramento para origens de dados.
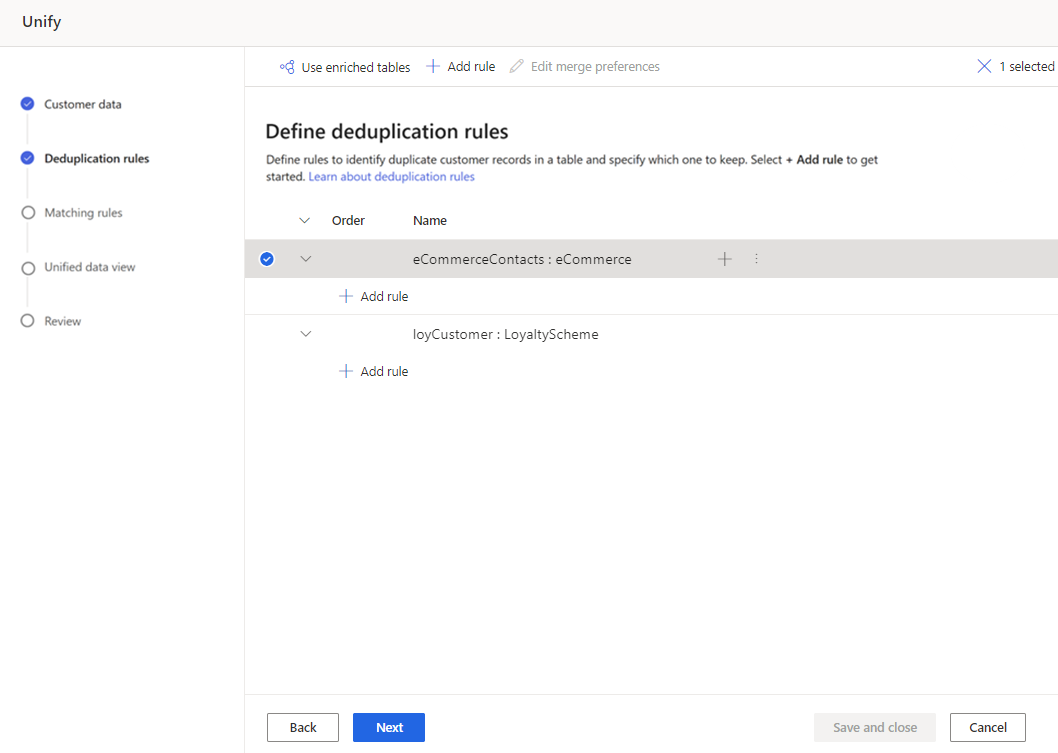
No painel Adicionar regra, introduza as seguintes informações:
- Selecionar campo: escolha a partir da lista de campos disponíveis na tabela que pretende verificar a existência de duplicados. Escolha os campos que sejam provavelmente únicos para cada cliente. Por exemplo, um endereço de e-mail ou a combinação de nome, cidade e número de telefone.
- Normalizar: selecione as opções de normalização para a coluna. A normalização só afeta o passo correspondente e não altera os dados.
- Numerais: converte muitos símbolos Unicode que representam números em números simples.
- Símbolos: remove muitos símbolos comuns, tais como !"#$%&'()*+,-./:;<=>?@[]^_`{|}~. Por exemplo, Cabeça&Ombro torna-se CabeçaOmbro.
- Texto para minúscula: converte todos os caracteres em minúsculas. "TODAS MAIÚSCULAS e Iniciais Maiúsculas" torna-se "todas maiúsculas e iniciais maiúsculas".
- Tipo (Telefone, Nome, Endereço, Organização): padroniza nomes, títulos, números de telefone, endereços, etc.
- Unicode para ASCII: converte caracteres Unicode para o respetivo equivalente ASCII. Por exemplo, o ề acentuado é convertido no caráter e.
- Espaço em branco: remove todos os espaços. Hello World torna-se HelloWorld.
- Precisão: defina o nível de precisão. A precisão é utilizada com a correspondência difusa e determina quão próximas precisam de estar duas cadeias para ser considerado uma correspondência.
- Básico: escolha entre Baixo (30%), Médio (60%), Alto (80%) e Exato (100%). Selecione Exato para corresponder apenas registos que correspondam a 100 por cento.
- Personalizar: defina uma percentagem que os registos têm de corresponder. O sistema só corresponde os registos que ultrapassam este limiar.
- Nome: nome da regra.
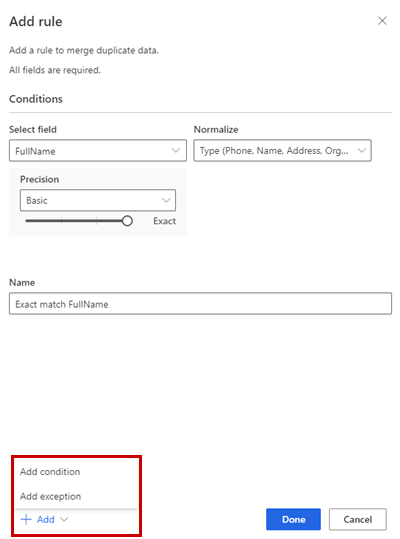
Opcionalmente, selecione Adicionar>Adicionar condição para adicionar mais condições à regra. As condições estão ligadas a um operador E lógico e, portanto, só são executadas se todas as condições forem satisfeitas.
Opcionalmente, Adicionar>Adicionar exceção para adicionar exceções à regra. As exceções são utilizadas para resolver casos raros de falsos positivos e falsos negativos.
Selecione Concluído para criar a regra.
Opcionalmente, adicione mais regras.
Selecione uma tabela e, em seguida, Editar preferências de união.
No painel Unir preferências:
Escolha uma de três opções para determinar que registo manter se forem encontrados duplicados:
- Mais preenchido: identifica o registo com as colunas mais preenchidas como registo vencedor. É a opção de intercalação predefinida.
- Mais recentes: Identifica o registo vencedor com base no mais recente. Requer uma data ou um campo numérico para definir a atualidade.
- Menos recente: Identifica o registo vencedor com base no menos recente. Requer uma data ou um campo numérico para definir a atualidade.
No caso de empate, o registo vencedor é aquele com o MAX(PK) ou valor da chave primária maior.
Opcionalmente, para definir as preferências de união em colunas individuais de uma tabela, selecione Avançadas na parte inferior do painel. Por exemplo, pode optar por manter o e-mail mais recente e o endereço mais completo de diferentes registos. Expanda a tabela para ver todas as suas colunas e defina que opção utilizar para colunas individuais. Se escolher uma opção baseada em recência, também precisa de especificar um campo de data/hora que defina a recência.
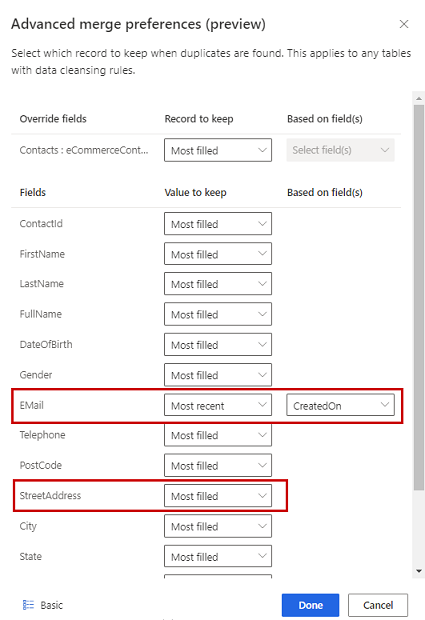
Selecione Concluído para aplicar preferências de união
Depois de definir as regras de eliminação de duplicados e as preferências de união selecione Seguinte.
