Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Microsoft Fabric Eventstream é um serviço totalmente gerido de ingestão e streaming de eventos que permite o processamento e análise de dados em tempo real. Pode integrar o Eventstream com portáteis Microsoft Fabric usando o Spark Structured Streaming para processar e analisar dados em streaming em tempo real.
Esta integração permite-lhe explorar Eventstreams e outras fontes em tempo real através do hub Real-Time, diretamente a partir dos seus cadernos Fabric. Também pode criar novos Eventstreams e começar a ingressar dados de quase 30 fontes de streaming, que continuam a crescer, incluindo bases de dados compatíveis com CDC, brokers de mensagens, serviços de streaming e feeds públicos. O novo modelo de programação permite ligar-se facilmente ao Eventstream, ler dados em streaming e realizar análises em tempo real usando APIs Spark familiares, sem quaisquer strings de ligação ou credenciais, tornando mais seguro a construção de aplicações em tempo real
Pré-requisitos
Antes de começar, certifique-se de que tem os seguintes pré-requisitos estabelecidos:
- Um espaço de trabalho Microsoft Fabric com o Eventstream ativado.
- Um ambiente de notebook configurado no Microsoft Fabric.
- Conhecimentos básicos de Spark Structured Streaming e PySpark ou Scala.
Passos para consultar o Eventstream a partir de um caderno
Descubra e adicione o eventstream ao Caderno:
Abra o seu caderno Microsoft Fabric.
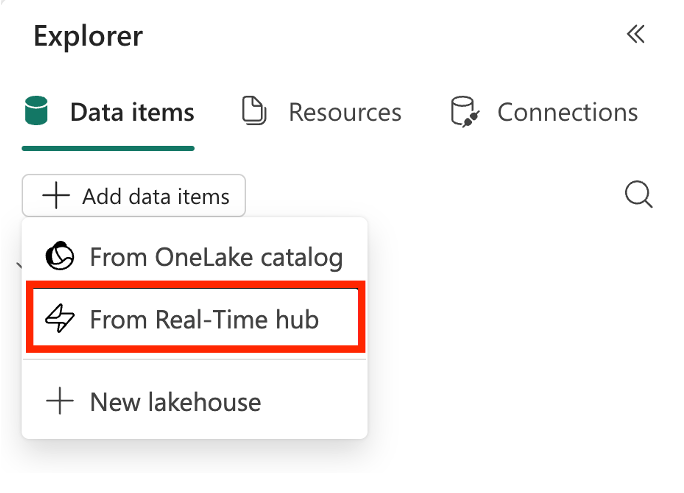
Selecione Adicionar itens de dados no separador Itens de dados, depois selecione A partir de Real-Time hub no menu suspenso.
No diálogo Real-Time hub, localiza o fluxo de eventos alvo que queres consultar com diferentes opções de pesquisa e filtro.
Adiciona o eventstream ao ambiente do teu notebook.
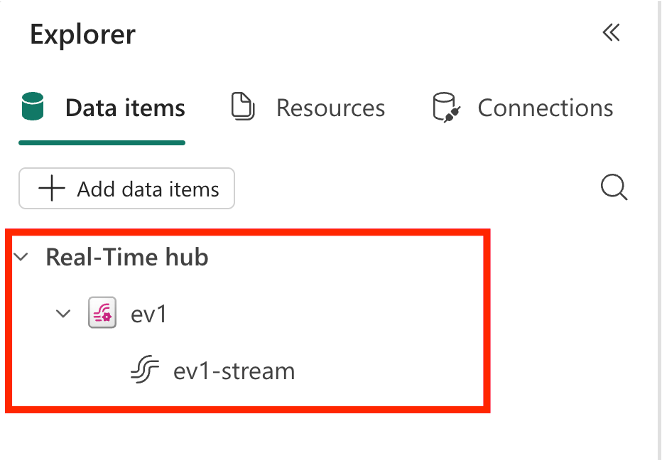
Depois de adicionar o elemento de fluxo de eventos, ele aparecerá no nó hub Real-Time no explorador de objetos do teu caderno com o nome do item; ao expandir o nó, verás o fluxo padrão ou derivado dentro do item de fluxo de eventos.
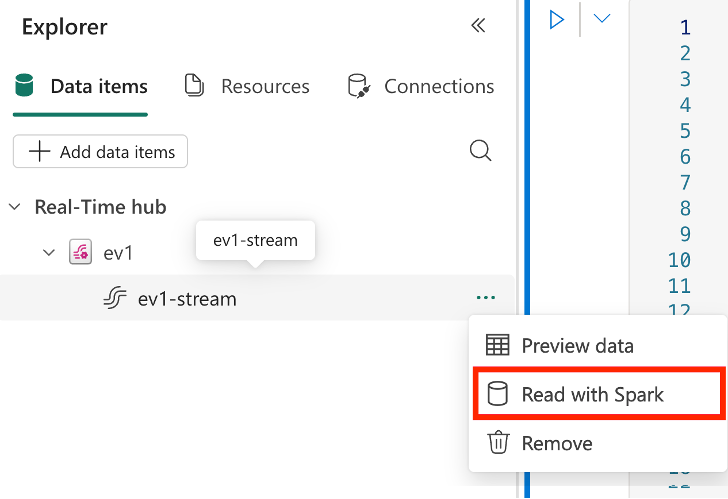
Leia dados em streaming do eventstream:
No menu de contexto do elemento do fluxo de eventos no explorador de objetos, selecione Ler com Spark para criar uma célula de código pré-configurada para ler do fluxo de eventos selecionado.
Na célula de código recém-criada, pode usar o seguinte excerto de código PySpark para ler dados em streaming do fluxo de eventos:
from pyspark.sql import SparkSession from pyspark.sql.functions import col from pyspark.sql.types import StringType from pyspark.sql.dataframe import DataFrame eventstream_options = { "eventstream.itemid": __in_eventstream_item_id, "eventstream.datasourceid": __in_eventstream_datasource_id } # Read from Kafka using the config map df_raw = spark.readStream.format("kafka").options(**eventstream_options).load() decoded_df = df_raw.select( col("key").cast(StringType()).alias("key"), col("value").cast(StringType()).alias("value"), col("partition"), col("offset") ) def showDf(x:DataFrame, y:int): x.show() # Print messages to the console query = decoded_df.writeStream.foreachBatch(showDf).outputMode("append").start() query.awaitTermination()Os valores das opções
eventstream.itemideeventstream.datasourceidsão automaticamente preenchidos na célula de código de parâmetro acima desta célula de código.Observação
Para cada seleção em Ler com o Spark, é gerada uma nova célula de código com os parâmetros necessários preenchidos automaticamente, e é criado um novo destino do Caderno para o item do Fluxo de Eventos, onde o
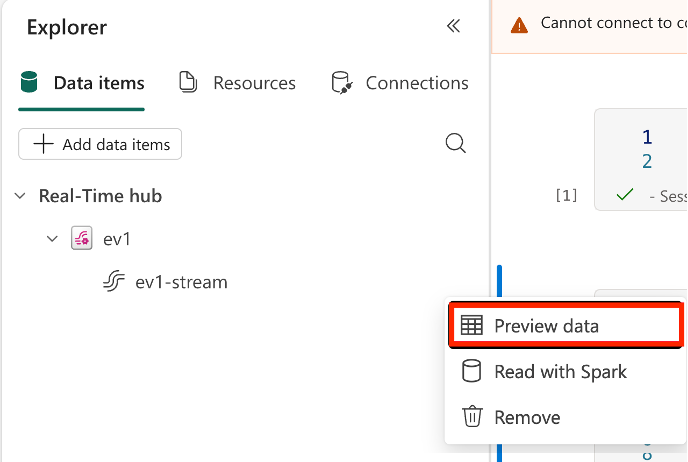
eventstream.datasourceidé único para cada destino do Caderno. Para um item do caderno, recomendamos que o definas uma vez como destino para um item do Eventstream para evitar criar múltiplos destinos.Antes de executar qualquer trabalho, pode também pré-visualizar os dados em streaming clicando no botão Pré-visualização de dados no menu contextual do item Eventstream. Um painel lateral abre-se para mostrar uma fotografia dos dados em streaming ao lado do caderno.
Adicionar caderno como destino: Também pode adicionar o caderno como destino para o Eventstream começar a ingerir dados dentro do caderno. Para mais informações, consulte Adicionar um destino do Spark Notebook a um fluxo de eventos.




Conclusion
A integração do Microsoft Fabric Eventstream com notebooks usando o Spark Structured Streaming permite-lhe processar e analisar dados em tempo real de forma fluida. Ao seguir os passos descritos neste artigo, pode facilmente ligar-se ao Eventstream, ler dados em streaming e realizar análises em tempo real usando APIs Spark familiares. Esta integração abre novas possibilidades para construir aplicações em tempo real e obter insights através do streaming de dados dentro do ecossistema Microsoft Fabric.
Conteúdo relacionado
Para saber mais sobre como trabalhar com Eventstreams e notebooks no Microsoft Fabric, consulte os seguintes recursos