Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
Este recurso está em pré-visualização.
O Fabric Runtime proporciona uma integração fluida dentro do ecossistema Microsoft Fabric, proporcionando um ambiente robusto para projetos de engenharia de dados e ciência de dados alimentados pelo Apache Spark.
Este artigo apresenta o Fabric Runtime 2.0 Public Preview, o mais recente runtime concebido para cálculos de big data no Microsoft Fabric. Destaca as principais funcionalidades e componentes que tornam este lançamento um avanço significativo para análises escaláveis e cargas de trabalho avançadas.
O Fabric Runtime 2.0 incorpora os seguintes componentes e atualizações concebidos para melhorar as suas capacidades de processamento de dados:
- Apache Spark 4.1
- Sistema operativo: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,1
- R: 4.5.2
Importante
O Fabric Runtime 2.0 foi atualizado para Spark 4.1, Delta Lake 4.1 e Python 3.13. A versão do Fabric Runtime exibida no portal (definições de Workspace e opção de Runtime no Environment UX) não muda.
| Componente | Versão anterior | Versão atual |
|---|---|---|
| Spark | 4.0 | 4.1 |
| Lago Delta | 4.0 | 4.1 |
| Python | 3.12 | 3.13 |

Alteração urgente: A atualização Python exige que republiques todos os Ambientes que tenham bibliotecas. Enquanto não voltares a publicar, os separadores Bibliotecas públicas e Bibliotecas personalizadas aparecem vazios e os trabalhos do Spark que têm como alvo o ambiente afetado falham com os erros "Módulo não encontrado" ou "Classe não encontrada".
Ações obrigatórias
- Grava ou exporta a tua lista de bibliotecas de cada Ambiente.
- Adiciona novamente as bibliotecas e seleciona Publicar para as reconstruir contra o Spark 4.1.
Sugestão
O Fabric Runtime 2.0 inclui suporte para o Native Execution Engine, que pode melhorar significativamente o desempenho sem custos adicionais. Pode ativar o motor de execução nativo ao nível do ambiente para que todos os trabalhos e notebooks herdem automaticamente as capacidades de desempenho melhoradas.
Ativar o Runtime 2.0
Podes ativar o Runtime 2.0 tanto ao nível do workspace como ao nível do item do ambiente. Usa a definição workspace para aplicar o Runtime 2.0 como padrão para todas as cargas de trabalho do Spark no teu espaço de trabalho. Alternativamente, crie um item de ambiente com Runtime 2.0 para usar com notebooks específicos ou definições de jobs do Spark, substituindo o padrão do workspace.
Ativar o Runtime 2.0 nas definições do Workspace
Para definir o Runtime 2.0 como padrão para todo o seu espaço de trabalho:
Navega para a página de definições do Workspace dentro do teu Fabric Workspace.
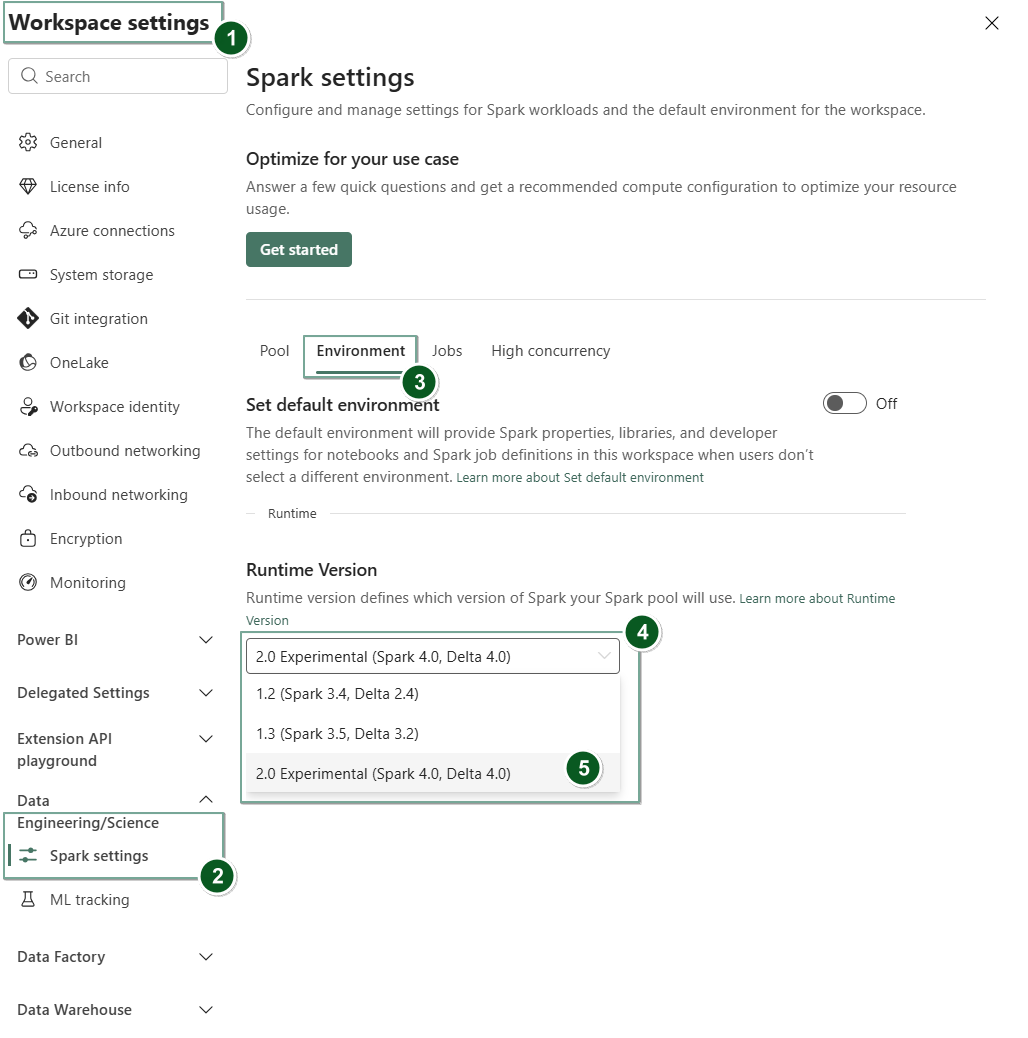
Seleciona o separador Engenharia de Dados/Ciência e depois seleciona as definições do Spark.
Selecione o separador Ambiente.
No menu suspenso da versão Runtime , selecione Pré-visualização Pública 2.0 (Spark 4.1, Delta 4.1) e guarde as suas alterações.
O tempo de execução 2.0 está definido como o tempo de execução padrão para o teu espaço de trabalho.

Ativar o Tempo de Execução 2.0 num item de Ambiente
Para usar o Runtime 2.0 com notebooks específicos ou definições de funções Spark:
Crie um novo item de Ambiente ou abra um existente.
Na lista pendente Tempo de execução, selecione 2.0 Pré-visualização pública (Spark 4.1, Delta 4.1), Guardar e Publicar as suas alterações.
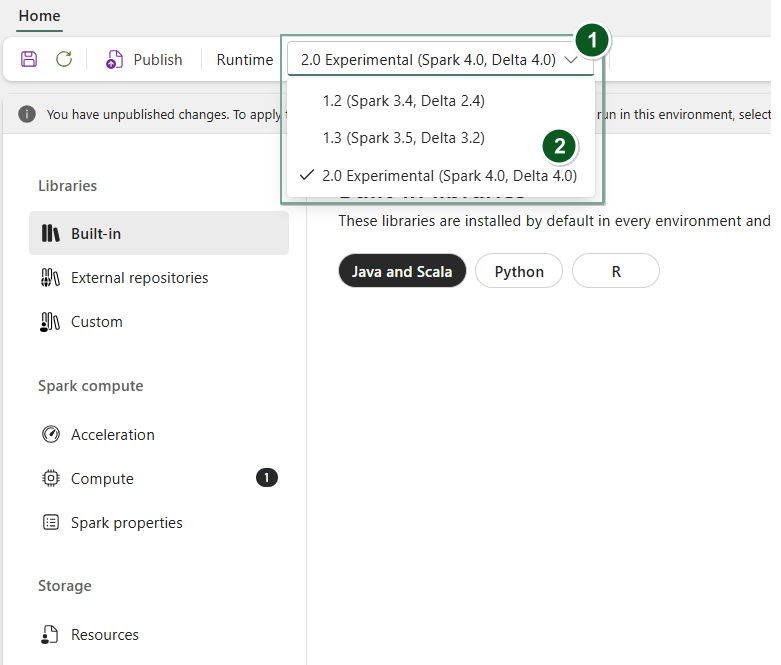
Em seguida, pode utilizar este item Ambiente com o seu Notebook ou a sua Definição de Tarefa Spark.

Agora podes começar a experimentar as mais recentes melhorias e funcionalidades introduzidas no Fabric Runtime 2.0 (Spark 4.1 e Delta Lake 4.1).
Observação
O protocolo WASB para contas Armazenamento do Azure de Uso Geral v2 (GPv2) está obsoleto. Deves usar o protocolo ABFS mais recente para ler e escrever em contas de armazenamento GPv2.
Pré-visualização pública
A fase de pré-visualização pública do Fabric Runtime 2.0 dá-lhe acesso a novas funcionalidades e APIs tanto do Spark 4.1 como do Delta Lake 4.1. A pré-visualização permite-lhe utilizar imediatamente as mais recentes melhorias baseadas em Spark e Delta, além de garantir uma prontidão e transição suaves para mudanças mais avançadas, como as versões mais recentes em Java, Scala e Python.
Sugestão
Para obter informações atualizadas, uma lista detalhada de alterações e notas de versão específicas para o runtime do Fabric, verifique e subscreva Spark Runtimes Releases and Updates.
Destaques chave
Melhorias no desempenho e no motor de execução
O Fabric Runtime 2.0 inclui o Native Execution Engine, que oferece melhorias significativas de desempenho em relação ao Spark open-source. O motor utiliza processamento vetorizado para acelerar consultas Spark na infraestrutura do lago sem exigir alterações de código.
Principais características de desempenho no Runtime 2.0:
- Até seis vezes mais rápido: Os benchmarks mostram até seis vezes mais desempenho em comparação com o Spark open-source em cargas de trabalho TPC-DS.
- Análise CSV vetorizada: O motor de execução nativo inclui um parser CSV vetorizado que acelera a ingestão e as cargas de consulta CSV. Estão planeados o suporte para análise JSON vetorializada e Spark Structured Streaming para futuras atualizações.
Para ativar o motor de execução nativo, veja Motor de execução nativo para Engenharia de Dados de Fabrico.
Apache Spark 4.1
Apache Spark 4.0 marcou um marco significativo como o lançamento inaugural da série 4.x, incorporando o esforço coletivo da vibrante comunidade open-source. Fabric Runtime 2.0 corre agora em Apache Spark 4.1, que se baseia nessa base com melhorias adicionais.
Nesta versão, o Spark SQL está significativamente enriquecido com novas funcionalidades poderosas concebidas para aumentar a expressividade e versatilidade para cargas de trabalho SQL, como suporte a tipos de dados VARIANT, funções definidas pelo utilizador SQL, variáveis de sessão, sintaxe de pipe e colação de strings. A PySpark demonstra dedicação contínua tanto à sua amplitude funcional como à experiência global dos programadores, trazendo uma API nativa de ploting, uma nova API de Fonte de Dados em Python, suporte para UDTFs em Python e perfilagem unificada para UDFs PySpark, juntamente com inúmeras outras melhorias. O Structured Streaming evolui com adições chave que proporcionam maior controlo e facilidade de depuração, nomeadamente a introdução da API de Estado Arbitrário v2 para uma gestão de estados mais flexível e da Fonte de Dados de Estado para facilitar a depuração.
Pode consultar a lista completa e as alterações detalhadas aqui:
Observação
No Spark 4.x, o SparkR está obsoleto e poderá ser removido numa versão futura.
Delta Lake 4.1
O Delta Lake 4.1 baseia-se no lançamento marco do Delta Lake 4.0, continuando o compromisso de tornar o Delta Lake interoperável entre formatos, mais fácil de trabalhar e mais eficiente. Inclui novas funcionalidades poderosas, otimizações de desempenho e melhorias fundamentais para o futuro dos lagos de dados abertos.
Pode consultar a lista completa e as alterações detalhadas introduzidas com Delta Lake 3.3, 4.0 e 4.1 aqui:
Disposição e otimização dos dados
O Runtime 2.0 suporta layout de dados e funcionalidades de otimização para tabelas Delta:
- Ordenação Z: Organize os dados dentro dos ficheiros de tabelas Delta por colunas especificadas para melhorar o desempenho das consultas filtradas.
- Cluster Líquido: Uma abordagem flexível de clustering que otimiza automaticamente o layout dos dados sem manutenção manual.
- Carregamento paralelo de snapshots Delta: O motor de execução nativo carrega snapshots de tabelas Delta em paralelo, reduzindo o tempo de arranque da consulta para tabelas grandes.
Importante
As funcionalidades específicas do Delta Lake 4.1 são experimentais e funcionam apenas em experiências Spark, como Cadernos e Definições de Funções Spark. Se precisares de usar as mesmas tabelas Delta Lake em várias cargas de trabalho do Microsoft Fabric, não atives essas funcionalidades. Para saber mais sobre quais as versões e funcionalidades dos protocolos são compatíveis em todas as experiências do Microsoft Fabric, leia interoperabilidade do formato de tabela Delta Lake.
Gestão de computação no Runtime 2.0
O Runtime 2.0 suporta as seguintes funcionalidades de gestão de computação:
- Perfis de recursos: Configure alocações pré-definidas de recursos para sessões Spark para corresponder aos requisitos de carga de trabalho e controlar custos.
- Pools ao vivo personalizados (pré-visualização): Crie pools Spark dedicados e pré-aquecidos que reduzam o tempo de início da sessão. Pools de sessões ao vivo personalizados estão disponíveis em pré-visualização para cargas de trabalho do Runtime 2.0.
Limitações e notas
- As funcionalidades específicas do Delta Lake 4.x são experimentais e funcionam apenas em experiências Spark, como cadernos e definições de funções no Spark. Se precisares de usar as mesmas tabelas Delta Lake em várias cargas de trabalho do Fabric, não atives essas funcionalidades. Para mais informações, consulte interoperabilidade no formato de tabela Delta Lake.
- Runtime 2.0 está em pré-visualização pública. Algumas funcionalidades e APIs podem mudar antes da disponibilidade geral.
- A extensão VS Code para Fabric Spark suporta o Runtime 2.0 para desenvolvimento de definições de notebooks e funções no Spark.
Conteúdo relacionado
- Ambientes de Execução do Apache Spark no Fabric - Visão Geral, Versionamento e Suporte a Múltiplos Ambientes de Execução
- Guia de migração do Spark Core
- Guias de migração SQL, Datasets e DataFrame
- Guia de migração do Streaming Estruturado
- Guia de migração MLlib (Machine Learning)
- Guia de migração do PySpark (Python on Spark)
- Guia de migração do SparkR (R on Spark)