Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:✅ Engenharia de Dados de Tecido e Ciência de Dados
Quando crias um espaço de trabalho no Microsoft Fabric, um pool starter associado a esse espaço de trabalho é criado automaticamente. Com a configuração simplificada no Microsoft Fabric, não é necessário escolher o tamanho dos nós ou das máquinas, pois estas opções são geridas automaticamente nos bastidores. Essa configuração fornece uma experiência de início de sessão do Apache Spark mais rápida (5-10 segundos) para que os usuários iniciem e executem seus trabalhos do Apache Spark em muitos cenários comuns sem ter que se preocupar em configurar a computação. Para cenários avançados com requisitos de computação específicos, os usuários podem criar um pool Apache Spark personalizado e dimensionar os nós com base em suas necessidades de desempenho.
Para fazer alterações nas configurações do Apache Spark em um espaço de trabalho, você deve ter a função de administrador para esse espaço de trabalho. Para saber mais, consulte Funções em espaços de trabalho.
Para gerenciar as configurações do Spark para o pool associado ao seu espaço de trabalho:
Vá para as configurações do espaço de trabalho em seu espaço de trabalho e escolha a opção Engenharia de Dados/Ciência para expandir o menu:
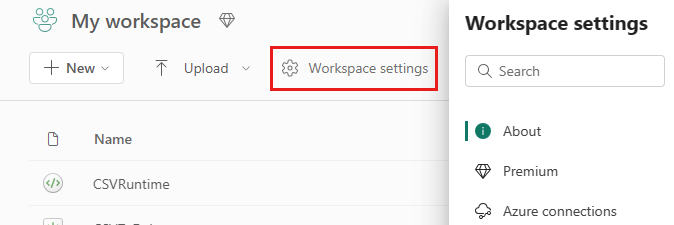
Você vê a opção Spark Compute no menu à esquerda:
Nota
Se você alterar o pool padrão de Starter Pool para um Custom Spark pool, poderá ver um início de sessão mais longo (~3 minutos).


Grupo
Pool padrão para o espaço de trabalho
Você pode usar o pool inicial criado automaticamente ou criar pools personalizados para o espaço de trabalho.
Piscina inicial: piscinas ao vivo pré-hidratadas criadas automaticamente para sua experiência mais rápida. Estes aglomerados são de tamanho médio. O pool inicial padrão é definido com base na SKU de capacidade do Fabric adquirida. Os administradores podem personalizar os nós máximos e executores com base em seus requisitos de escala de carga de trabalho do Spark. Para saber mais, consulte Configurar pools iniciais
Custom Spark Pool: pode dimensionar os nós, dimensionar automaticamente e alocar executores dinamicamente com base nos requisitos da tarefa Spark. Para criar um pool do Spark personalizado, o administrador de capacidade deve habilitar a opção Pools de espaços de trabalho personalizados na seção Computação do Spark das configurações do Administrador de capacidade.
Nota
O controle de nível de capacidade para pools de espaços de trabalho personalizados é habilitado por padrão. Para saber mais, consulte Configurar e gerir definições de engenharia e ciência de dados para capacidades Fabric.
Os administradores podem criar pools Spark personalizados com base em seus requisitos de computação selecionando a opção Novo Pool .

O Apache Spark para Microsoft Fabric suporta clusters de nó único, o que permite aos utilizadores selecionar uma configuração mínima de nó de 1, caso em que o driver e executor funcionam num único nó. Esses clusters de nó único oferecem alta disponibilidade restaurável durante falhas de nó e melhor confiabilidade de trabalho para cargas de trabalho com requisitos de computação menores. Você também pode habilitar ou desabilitar a opção de dimensionamento automático para seus pools Spark personalizados. Quando ativado com o dimensionamento automático, o pool adquiriria novos nós dentro do limite máximo de nós especificado pelo usuário e os retiraria após a execução do trabalho para um melhor desempenho.
Você também pode selecionar a opção para alocar dinamicamente executores para agrupar automaticamente o número ideal de executores dentro do limite máximo especificado com base no volume de dados para um melhor desempenho.

Saiba mais sobre o Apache Spark compute for Fabric.
- Personalizar a configuração de computação para itens: Como administrador de espaço de trabalho, você pode permitir que os usuários ajustem configurações de computação (propriedades de nível de sessão que incluem Driver/Executor Core, Driver/Executor Memory) para itens individuais, como blocos de anotações, definições de trabalho do Spark usando Ambiente.

Se a configuração for desativada pelo administrador do espaço de trabalho, o pool padrão e suas configurações de computação serão usados para todos os ambientes no espaço de trabalho.
Meio Ambiente
O ambiente fornece configurações flexíveis para executar seus trabalhos do Spark (blocos de anotações, definições de trabalho do Spark). Em um ambiente, você pode configurar propriedades de computação, selecionar tempo de execução diferente, configurar dependências de pacotes de biblioteca com base em seus requisitos de carga de trabalho.
Na guia ambiente, você tem a opção de definir o ambiente padrão. Você pode escolher qual versão do Spark deseja usar para o espaço de trabalho.
Como administrador do espaço de trabalho Fabric, você pode selecionar um Ambiente como Ambiente padrão do espaço de trabalho.
Você também pode criar um novo através do menu suspenso Ambiente .

Se desativar a opção de ter um ambiente padrão, tem a opção de selecionar a versão runtime do Fabric a partir das versões disponíveis listadas no menu suspenso.

Saiba mais sobre os tempos de execução do Apache Spark.
Tarefas
As configurações de trabalhos permitem que os administradores controlem a lógica de admissão de trabalho para todos os trabalhos do Spark no espaço de trabalho.

Por padrão, todos os espaços de trabalho vêm com Admissão de Tarefas Otimista habilitada. Saiba mais sobre Submissão de trabalhos para Spark em Microsoft Fabric.
Você pode ativar a opção Reservar núcleos máximos para trabalhos ativos do Spark para desativar a abordagem baseada em admissão otimista de trabalhos e reservar o número máximo de núcleos para os seus trabalhos com Spark.
Você pode também definir o tempo limite da sessão do Spark para personalizar a expiração da sessão para todas as sessões interativas do notebook.
Nota
A expiração da sessão padrão é definida como 20 minutos para as sessões interativas do Spark.
Alta simultaneidade
O modo de alta simultaneidade permite que os usuários compartilhem as mesmas sessões do Spark nas cargas de trabalho de engenharia de dados e ciência de dados do Apache Spark for Fabric. Um item como um bloco de anotações usa uma sessão do Spark para sua execução e, quando ativado, permite que os usuários compartilhem uma única sessão do Spark em vários blocos de anotações.

Saiba mais sobre Alta simultaneidade no Apache Spark for Fabric.
Registo automático para modelos e experiências de Machine Learning
Os administradores agora podem habilitar o registro automático para seus modelos e experimentos de aprendizado de máquina. Essa opção captura automaticamente os valores de parâmetros de entrada, métricas de saída e itens de saída de um modelo de aprendizado de máquina à medida que ele está sendo treinado. Saiba mais sobre o registo automático.

Conteúdos relacionados
- Leia sobre Apache Spark Runtimes in Fabric - Visão geral, versionamento, suporte a vários tempos de execução e atualização do protocolo Delta Lake.
- Saiba mais na documentação pública do Apache Spark .
- Encontre respostas para perguntas frequentes: Perguntas frequentes sobre as configurações de administração do espaço de trabalho do Apache Spark.