Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
XML (Extensible Markup Language) é um formato baseado em texto para a troca de dados estruturados. Este artigo descreve como configurar o formato XML como fonte numa pipeline de atividade de cópia no Data Factory no Microsoft Fabric.
Capacidades suportadas
O formato XML é suportado para as seguintes atividades e conectores como origem.
| Categoria | Conector/Atividade |
|---|---|
| Conector suportado | Amazon S3 |
| Compatível com Amazon S3 | |
| Armazenamento de Blobs do Azure | |
| Azure Data Lake Storage Gen2 | |
| Ficheiros do Azure | |
| Sistema de ficheiros | |
| FTP | |
| Armazenamento em nuvem do Google | |
| HTTP | |
| Arquivos Lakehouse | |
| Armazenamento em nuvem Oracle | |
| SFTP | |
| Atividade apoiada | Atividade de cópia (fonte/-) |
| Atividade de Pesquisa | |
| Atividade GetMetadata | |
| Excluir atividade |
Formato XML na atividade de cópia
Para configurar o formato XML, escolha sua conexão na origem de uma atividade de cópia de pipeline e selecione XML na lista suspensa de Formato de arquivo. Selecione Configurações para configuração adicional deste formato.
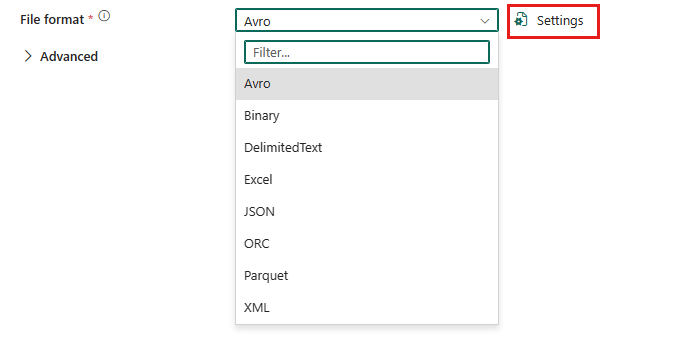
XML como fonte
Depois de selecionar Configurações na seção Formato de arquivo , as seguintes propriedades são mostradas na caixa de diálogo pop-up Configurações de formato de arquivo.
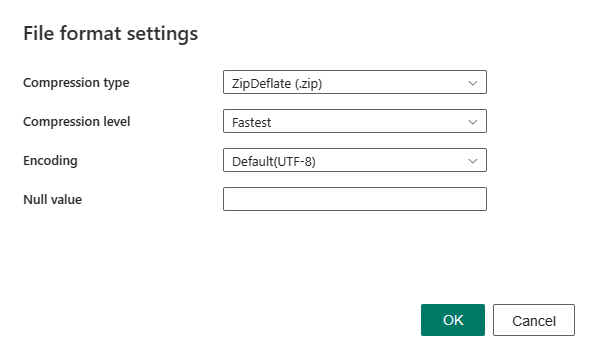
Tipo de compactação: O codec de compactação usado para ler arquivos XML. Você pode escolher entre None, bzip2, gzip, deflate, ZipDeflate, TarGZip ou tar type na lista suspensa.
Se você selecionar ZipDeflate como o tipo de compactação, Preservar nome de arquivo zip como pasta será exibido nas Configurações avançadas na guia Origem .
-
Preservar o nome do arquivo zip como pasta: indica se o nome do arquivo zip de origem deve ser preservado como uma estrutura de pasta durante a cópia.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
<specified file path>/<folder named as source zip file>/. - Se esta caixa estiver desmarcada, o serviço gravará os arquivos descompactados diretamente no
<specified file path>. Certifique-se de que não tem nomes de ficheiros duplicados em ficheiros zip de origem diferentes para evitar corridas ou comportamentos inesperados.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
Se você selecionar TarGZip/tar como o tipo de compactação, Preservar nome do arquivo de compactação como pasta será exibido nas Configurações avançadas na guia Origem .
-
Preservar o nome do arquivo de compactação como pasta: indica se o nome do arquivo compactado de origem deve ser preservado como uma estrutura de pasta durante a cópia.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
<specified file path>/<folder named as source compressed file>/. - Se essa caixa estiver desmarcada, o serviço grava arquivos descompactados diretamente no
<specified file path>. Certifique-se de que não tem nomes de ficheiro duplicados em ficheiros de origem diferentes para evitar corridas ou comportamentos inesperados.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
-
Preservar o nome do arquivo zip como pasta: indica se o nome do arquivo zip de origem deve ser preservado como uma estrutura de pasta durante a cópia.
Nível de compactação: especifique a taxa de compactação ao selecionar um tipo de compactação. Você pode escolher entre Fastest ou Optimal.
- Mais rápido: A operação de compressão deve ser concluída o mais rápido possível, mesmo que o arquivo resultante não seja compactado de forma ideal.
- Ideal: A operação de compressão deve ser compactada de forma ideal, mesmo que a operação demore mais tempo para ser concluída. Para obter mais informações, consulte o tópico Nível de compactação.
Codificação: Especifique o tipo de codificação usado para ler ficheiros de texto. Selecione um tipo na lista suspensa. O valor padrão é UTF-8.
Valor nulo: Especifica a representação da cadeia de caracteres do valor nulo. O valor padrão é cadeia de caracteres vazia.
Em Configurações avançadas na guia Origem , as seguintes propriedades relacionadas ao formato XML são exibidas.
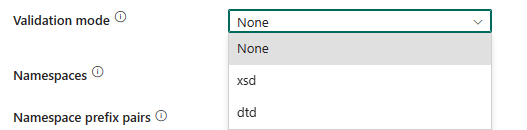
Modo de validação: especifica se o esquema XML deve ser validado. Selecione um modo na lista suspensa.
- Nenhum: Selecione esta opção para não usar o modo de validação.
- xsd: Selecione esta opção para validar o esquema XML usando XSD.
- dtd: Selecione esta opção para validar o esquema XML usando DTD.
Namespaces: especifique se deseja habilitar o namespace ao analisar os arquivos XML. Ele é selecionado por padrão.
Pares de prefixos de namespace: Se os Namespaces estiverem habilitados, selecione + Novo e especifique a URL e o Prefixo. Você pode adicionar mais pares selecionando + Novo.
O URI do namespace para mapeamento de prefixo é usado para nomear campos ao analisar o arquivo XML. Se um arquivo XML tiver namespace e o namespace estiver habilitado, por padrão, o nome do campo será o mesmo que no documento XML. Se houver um item definido para o URI do namespace neste mapa, o nome do campo seráprefix:fieldName.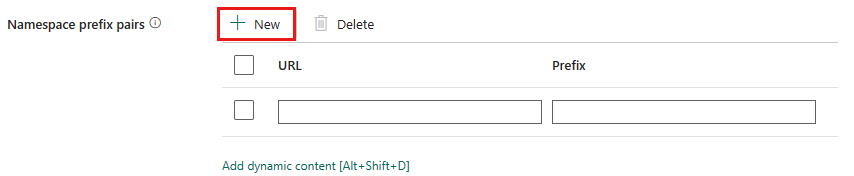
Detetar tipo de dados: especifique se deseja detetar tipos de dados inteiros, duplos e booleanos. Ele é selecionado por padrão.
Propriedades da atividade de cópia XML
XML como fonte
As seguintes propriedades são suportadas na seção Fonte da atividade de cópia ao usar o formato XML.
| Nome | Descrição | Valor | Necessário | Propriedade de script JSON |
|---|---|---|---|---|
| Formato do ficheiro | O formato de ficheiro que pretende utilizar. | XML | Sim | tipo (em datasetSettings):Xml |
| Tipo de compressão | O codec de compressão usado para ler arquivos XML. |
Nenhuma bzip2 gzip deflacionar ZipDeflate TarGZip tar |
Não | tipo (em compression): bzip2 gzip deflacionar ZipDeflate TarGZip tar |
| Nível de compressão | A taxa de compressão. |
Mais rápido Ótimo |
Não | nível (em compression): Mais rápido Ótimo |
| Encoding (Codificação) | O tipo de codificação usado para ler ficheiros de texto. | "UTF-8" (por padrão),"UTF-8 sem BOM", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Não | nomeDeCodificação |
| Preservar o nome do arquivo zip como pasta | Indica se o nome do arquivo zip de origem deve ser preservado como uma estrutura de pastas durante a cópia. | Selecionado (padrão) ou desmarcado | Não | preservarNomeDoArquivoZipComoPasta (em compressionProperties->type como ZipDeflateReadSettings):verdadeiro (true) (padrão) ou falso (false) |
| Preservar o nome do arquivo de compactação como pasta | Indica se o nome do arquivo compactado de origem deve ser preservado como uma estrutura de pastas durante a cópia. | Selecionado (padrão) ou desmarcado | Não | preservarNomeDoFicheiroDeCompressãoComoPasta (em compressionProperties->type como TarGZipReadSettings ou TarReadSettings):verdadeiro (true) (padrão) ou falso (false) |
| Valor nulo | A representação de cadeia de caracteres de valor nulo. |
<seu valor nulo> string vazia (por padrão) |
Não | valor nulo |
| Modo de validação | Se o esquema XML deve ser validado. |
Nenhuma XSD DTD |
Não | validationMode: xsd DTD |
| Namespaces (Espaços de nomes) | Se o namespace deve ser habilitado ao analisar os arquivos XML. | Selecionado (padrão) ou não selecionado | Não | namespaces: verdadeiro (true) (padrão) ou falso (false) |
| Pares de prefixo de namespace | URI de namespace para o mapeamento de prefixo, que é usado para nomear campos ao processar o arquivo XML. Se um arquivo XML tiver namespace e o namespace estiver habilitado, por padrão, o nome do campo será o mesmo que no documento XML. Se houver um item definido para o URI do namespace neste mapa, o nome do campo será prefix:fieldName. |
<url>:<prefixo> | Não | namespacePrefixes: <url>:<prefixo> |
| Detetar tipo de dados | Se os tipos de dados inteiros, duplos e booleanos devem ser detetados ou não. | Selecionado (padrão) ou não selecionado | Não | detectDataType: verdadeiro (true) (padrão) ou falso (false) |