Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Data Factory no Microsoft Fabric fornece serviços de movimentação e transformação de dados em escala de nuvem que permitem resolver os cenários mais complexos de data factory e ETL e capacitam você com uma experiência moderna de integração de dados para ingerir, preparar e transformar dados de um rico conjunto de fontes de dados. No Data Factory, você pode criar pipelines de dados para usar recursos avançados de orquestração de dados prontos para uso para compor fluxos de trabalho de dados flexíveis que atendam às necessidades da sua empresa.
Agora, com o modelo de IA no Azure, estamos ultrapassando os limites do que você pode fazer com o gpt-4o Data Factory e tornando possível criar soluções de dados a partir de apenas uma imagem.
O que precisa para começar? Apenas uma conta do Microsoft Fabric e uma ideia. Aqui, mostramos-lhe como transformar uma ideia de quadro branco num fluxo de dados do Fabric Data Factory usando apenas uma imagem e gpt-4o.
Pré-requisitos
Antes de criar a solução, verifique se os seguintes pré-requisitos estão configurados no Azure e no Fabric:
- Espaço de trabalho habilitado com Microsoft Fabric.
- Conta do Azure OpenAI com uma chave de API e um
gpt-4omodelo implantado. - Uma imagem de como você quer que seu pipeline se pareça.
Aviso
As chaves de API são informações confidenciais e as chaves de produção devem sempre ser armazenadas de forma segura no Cofre de Chaves do Azure ou em outros repositórios seguros. Este exemplo usa uma chave OpenAI apenas para fins de demonstração. Para código de produção, considere usar o Microsoft Entra ID em vez da autenticação de chave para um ambiente mais seguro que não dependa do compartilhamento de chaves ou corra o risco de uma violação de segurança se uma chave for comprometida.
Passo 1: Carregue a sua imagem para a Lakehouse
Antes de poder analisar a imagem, você precisa enviá-la para a sua Lakehouse. Entre na sua conta do Microsoft Fabric e navegue até o espaço de trabalho. Selecione + Novo item e crie uma nova Lakehouse.
Assim que o Lakehouse estiver configurado, crie uma nova pasta em arquivos, chamada imagens, e carregue a imagem lá.

Etapa 2: criar o bloco de anotações em seu espaço de trabalho
Agora só precisamos criar um bloco de anotações para executar algum código Python que resume e cria o pipeline no espaço de trabalho.
Crie um novo Bloco de Anotações no seu espaço de trabalho:
Na área de código, insira o seguinte código, que configura as bibliotecas e a configuração necessárias e codifica a imagem:
# Configuration
AZURE_OPENAI_KEY = "<Your Azure OpenAI key>"
AZURE_OPENAI_GPT4O_ENDPOINT = "<Your Azure OpenAI gpt-4o deployment endpoint>"
IMAGE_PATH = "<Path to your uploaded image file>" # For example, "/lakehouse/default/files/images/pipeline.png"
# Install the OpenAI library
!pip install semantic-link --q
!pip uninstall --yes openai
!pip install openai
%pip install openai --upgrade
# Imports
import os
import requests
import base64
import json
import time
import pprint
import openai
import sempy.fabric as fabric
import pandas as pd
# Load the image
image_bytes = open(IMAGE_PATH, 'rb').read()
encoded_image = base64.b64encode(image_bytes).decode('ascii')
## Request headers
headers = {
"Content-Type": "application/json",
"api-key": AZURE_OPENAI_KEY,
}
Execute este bloco de código para configurar o ambiente.
Etapa 3: Usar gpt-4o para descrever o pipeline (opcional)
Esta etapa é opcional, mas mostra como é simples extrair detalhes da imagem, que podem ser relevantes para seus propósitos. Se não executar esta etapa, ainda poderá gerar o JSON da pipeline no passo seguinte.
Primeiro, selecione Editar no menu principal do Bloco de Anotações e, em seguida, selecione o botão + Adicionar célula de código abaixo na barra de ferramentas, para adicionar um novo bloco de código após o anterior.
Em seguida, adicione o seguinte código à nova seção. Este código mostra como gpt-4o pode interpretar e resumir a imagem para entender seu conteúdo.
# Summarize the image
## Request payload
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps an Azure engineer understand an image that likely shows a Data Factory in Microsoft Fabric data pipeline. Show list of pipeline activities and how they are connected."
}
]
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
## Send request
try:
response = requests.post(AZURE_OPENAI_GPT4O_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
response_json = response.json()
## Show AI response
print(response_json["choices"][0]['message']['content'])
Execute este bloco de código para ver o resumo de IA da imagem e seus componentes.
Etapa 4: Gerar o JSON do fluxo de processos
Adicione outro bloco de código ao Bloco de Anotações e adicione o código a seguir. Este código analisa a imagem e gera o pipeline JSON.
# Analyze the image and generate the pipeline JSON
## Setup new payload
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps an Azure engineer understand an image that likely shows a Data Factory in Microsoft Fabric data pipeline. Succeeded is denoted by a green line, and Fail is denoted by a red line. Generate an ADF v2 pipeline JSON with what you see. Return ONLY the JSON text required, without any leading or trailing markdown denoting a code block."
}
]
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
## Send request
try:
response = requests.post(AZURE_OPENAI_GPT4O_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
## Get JSON from request and show
response_json = response.json()
pipeline_json = response_json["choices"][0]['message']['content']
print(pipeline_json)
Corra este bloco de código para gerar o pipeline JSON a partir da imagem.
Etapa 4: Criar o pipeline com APIs REST de Fabric
Agora que já possui o JSON do pipeline, pode criá-lo diretamente usando as Fabric REST APIs. Adicione outro bloco de código ao Bloco de Anotações e adicione o código a seguir. Esse código cria o pipeline em seu espaço de trabalho.
# Convert pipeline JSON to Fabric REST API request
json_data = json.loads(pipeline_json)
# Extract the activities from the JSON
activities = json_data["properties"]["activities"]
# Prepare the data pipeline JSON definition
data = {}
activities_list = []
idx = 0
# Name mapping used to track activity name found in image to dynamically generated name
name_mapping = {}
for activity in activities:
idx = idx + 1
activity_name = activity["type"].replace("Activity","")
objName = f"{activity_name}{idx}"
# store the name mapping so we can deal with dependency
name_mapping[activity["name"]] = objName
if 'dependsOn' in activity:
activity_dependent_list = activity["dependsOn"]
dependent_activity = ""
if ( len(activity_dependent_list) > 0 ):
dependent_activity = activity_dependent_list[0]["activity"]
match activity_name:
case "Copy":
activities_list.append({'name': objName, 'type': "Copy", 'dependsOn': [],
'typeProperties': { "source": { "datasetSettings": {} },
"sink": { "datasetSettings": {} } }})
case "Web":
activities_list.append({'name': objName, 'type': "Office365Outlook",
"dependsOn": [
{
"activity": name_mapping[dependent_activity] ,
"dependencyConditions": [
"Succeeded"
]
}
]
}
)
case "ExecutePipeline":
activities_list.append({'name': "execute pipeline 1", 'type': "ExecutePipeline",
"dependsOn": [
{
"activity": name_mapping[dependent_activity] ,
"dependencyConditions": [
"Succeeded"
]
}
]
}
)
case _:
continue
else:
# simple activities with no dependencies
match activity_name:
case "Copy":
activities_list.append({'name': objName, 'type': "Copy", 'dependsOn': [],
'typeProperties': { "source": { "datasetSettings": {} } , "sink": { "datasetSettings": {} } }})
case "SendEmail":
activities_list.append({'name': "Send mail on success", 'type': "Office365Outlook"})
case "Web":
activities_list.append({'name': "Send mail on success", 'type': "Office365Outlook"})
case "ExecutePipeline":
activities_list.append({'name': "execute pipeline 1", 'type': "ExecutePipeline"})
case _:
print("NoOp")
# Now that the activities_list is created, assign it to the activities tag in properties
data['properties'] = { "activities": activities_list}
# Convert data from dict to string, then Byte Literal, before doing a Base-64 encoding
data_str = str(data).replace("'",'"')
createPipeline_json = data_str.encode(encoding="utf-8")
createPipeline_Json64 = base64.b64encode(createPipeline_json)
# Create a new data pipeline in Fabric
timestr = time.strftime("%Y%m%d-%H%M%S")
pipelineName = f"Pipeline from image with AI-{timestr}"
payload = {
"displayName": pipelineName,
"type": "DataPipeline",
"definition": {
"parts": [
{
"path": "pipeline-content.json",
"payload": createPipeline_Json64,
"payloadType": "InlineBase64"
}
]
}
}
print(f"Creating pipeline: {pipelineName}")
# Call the Fabric REST API to generate the pipeline
client = fabric.FabricRestClient()
workspaceId = fabric.get_workspace_id()
try:
response = client.post(f"/v1/workspaces/{workspaceId}/items",json=payload)
if response.status_code != 201:
raise FabricHTTPException(response)
except WorkspaceNotFoundException as e:
print("Workspace is not available or cannot be found.")
except FabricHTTPException as e:
print(e)
print("Fabric HTTP Exception. Check that you have the correct Fabrric API endpoints.")
response = client.get(f"/v1/workspaces/{workspaceId}/Datapipelines")
df_items = pd.json_normalize(response.json()['value'])
print("List of pipelines in the workspace:")
df_items
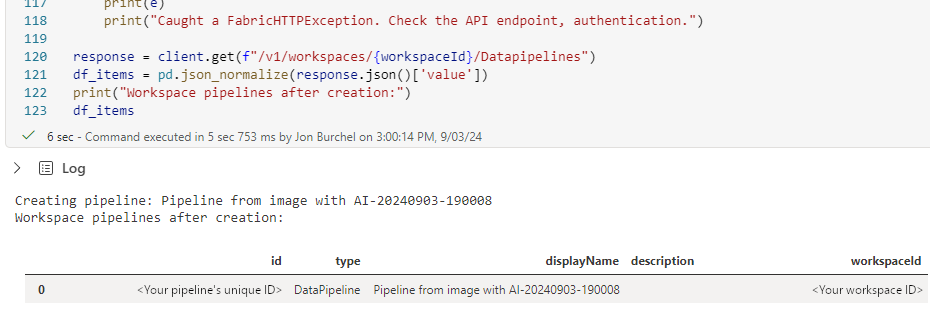
A saída confirma o nome do pipeline criado e mostra uma lista dos pipelines do seu espaço de trabalho, para que o utilizador possa confirmar a sua presença.
Etapa 6: Utilize o seu pipeline
Assim que o pipeline for criado, poderá editá-lo na sua área de trabalho do Fabric, de modo a ver a sua imagem implementada como um pipeline. Você pode selecionar cada atividade para configurá-la como desejar e, em seguida, executá-la e monitorá-la conforme necessário.
