Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Este tutorial leva 15 minutos e descreve como acumular dados incrementalmente em uma casa de lago usando o Dataflow Gen2.
O acúmulo incremental de dados em um destino de dados requer uma técnica para carregar apenas dados novos ou atualizados em seu destino de dados. Essa técnica pode ser feita usando uma consulta para filtrar os dados com base no destino dos dados. Este tutorial mostra como criar um fluxo de dados para carregar dados de uma fonte OData numa lakehouse e como adicionar uma consulta ao fluxo de dados para filtrar os dados com base no destino pretendido.
As etapas de alto nível neste tutorial são as seguintes:
- Crie um fluxo de dados para carregar dados de uma fonte OData em uma casa de lago.
- Adicione uma consulta ao fluxo de dados para filtrar os dados com base no destino dos dados.
- (Opcional) recarregar dados usando notebooks e pipelines.
Pré-requisitos
Você deve ter um espaço de trabalho habilitado para Microsoft Fabric. Se você ainda não tiver um, consulte Criar um espaço de trabalho. Além disso, o tutorial pressupõe que você esteja usando a exibição de diagrama no Dataflow Gen2. Para verificar se está a utilizar a Vista de Diagrama, no friso superior aceda a Vista e certifique-se de que a Vista de Diagrama está selecionada.
Criar um fluxo de dados para carregar dados de uma fonte OData em uma casa de lago
Nesta secção, o utilizador criará um fluxo de dados para carregar dados de uma fonte OData num lakehouse.
Crie uma nova casa do lago no seu espaço de trabalho.
Crie um novo Dataflow Gen2 em seu espaço de trabalho.
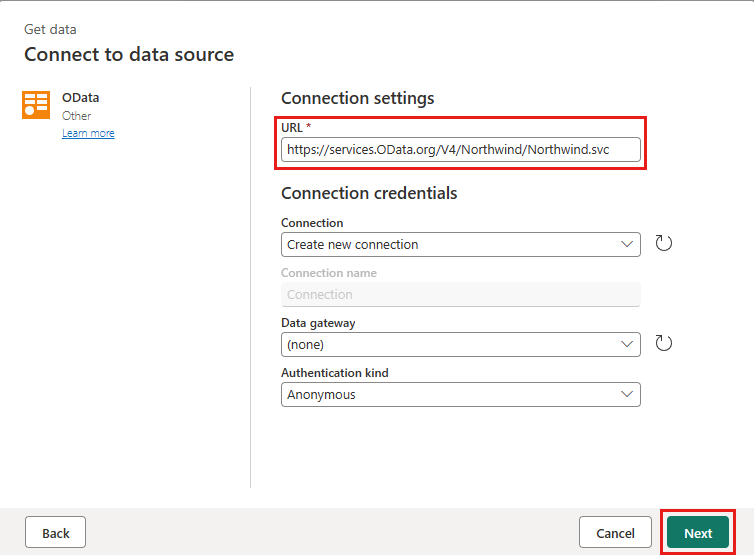
Adicione uma nova fonte ao fluxo de dados. Selecione a fonte OData e insira o seguinte URL:
https://services.OData.org/V4/Northwind/Northwind.svc

Selecione a tabela Pedidos e selecione Avançar.
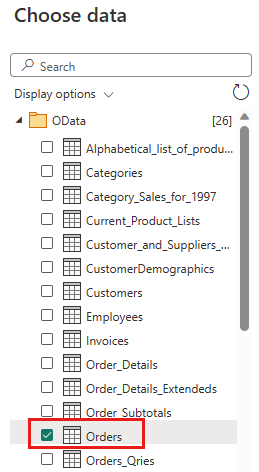
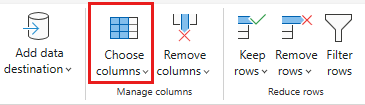
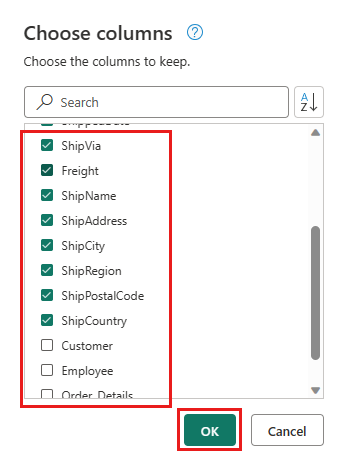
Selecione as seguintes colunas para manter:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Altere o tipo de dados de
OrderDate,RequiredDateeShippedDateparadatetime.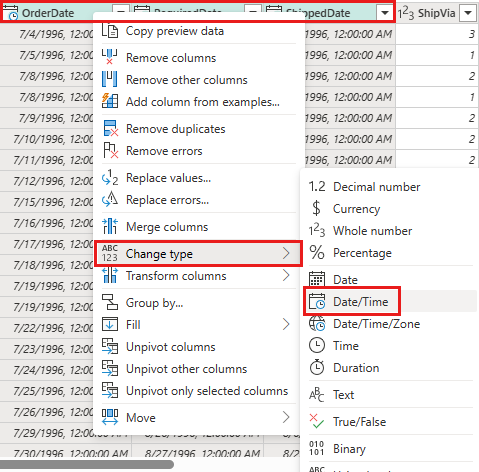
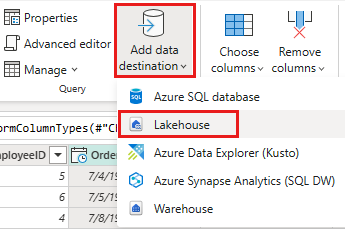
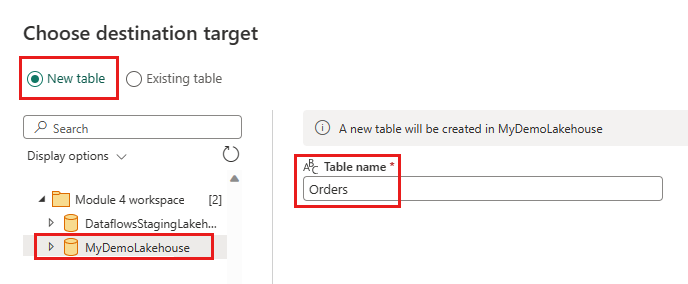
Configure o destino dos dados para sua casa do lago usando as seguintes configurações:
- Destino dos dados:
Lakehouse - Lakehouse: Selecione a lakehouse que você criou na etapa 1.
- Novo nome da tabela:
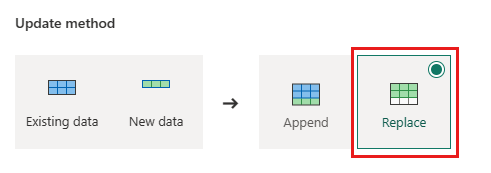
Orders - Método de atualização:
Replace
- Destino dos dados:
selecione Avançar e publique o fluxo de dados.



Agora você criou um fluxo de dados para carregar dados de uma fonte OData em uma casa de lago. Esse fluxo de dados é usado na próxima seção para adicionar uma consulta ao fluxo de dados para filtrar os dados com base no destino dos dados. Depois disso, pode-se usar o fluxo de dados para recarregar os dados utilizando notebooks e pipelines.
Adicionar uma consulta ao fluxo de dados para filtrar os dados com base no destino dos dados
Esta seção adiciona uma consulta ao fluxo de dados para filtrar os dados com base nos dados no lakehouse de destino. A consulta obtém o máximo OrderID na lakehouse no início da atualização do fluxo de dados e usa o OrderId máximo para obter apenas os pedidos com um OrderId mais alto da origem para anexar ao seu destino de dados. Isso pressupõe que as ordens sejam adicionadas à fonte em ordem crescente de OrderID. Se esse não for o caso, você pode usar uma coluna diferente para filtrar os dados. Por exemplo, você pode usar a OrderDate coluna para filtrar os dados.
Nota
Os filtros OData são aplicados no Fabric depois que os dados são recebidos da fonte de dados, no entanto, para fontes de banco de dados como o SQL Server, o filtro é aplicado na consulta enviada à fonte de dados de back-end e apenas as linhas filtradas são retornadas ao serviço.
Depois que o fluxo de dados for atualizado, reabra o fluxo de dados criado na seção anterior.
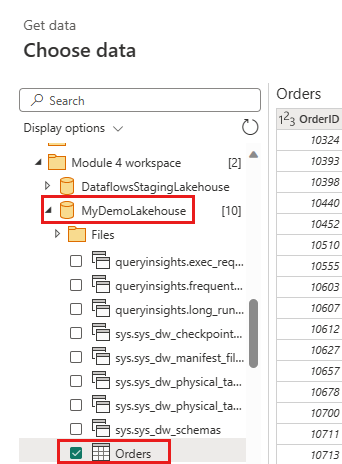
Crie uma nova consulta com o nome
IncrementalOrderIDe obtenha dados da tabela Pedidos na casa do lago que você criou na seção anterior.
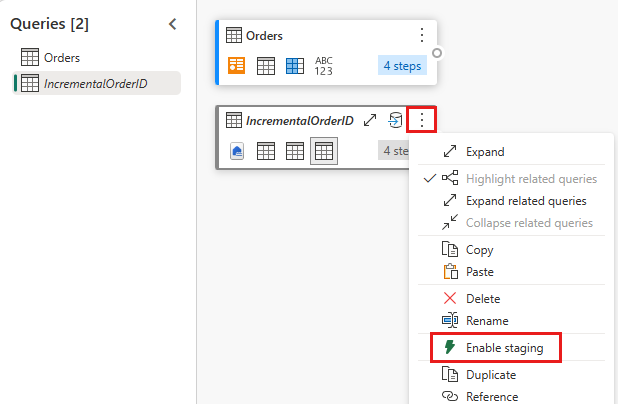
Desative o preparo desta consulta.
Na visualização de dados, clique com o botão direito do mouse na coluna
OrderIDe selecione Detalhar.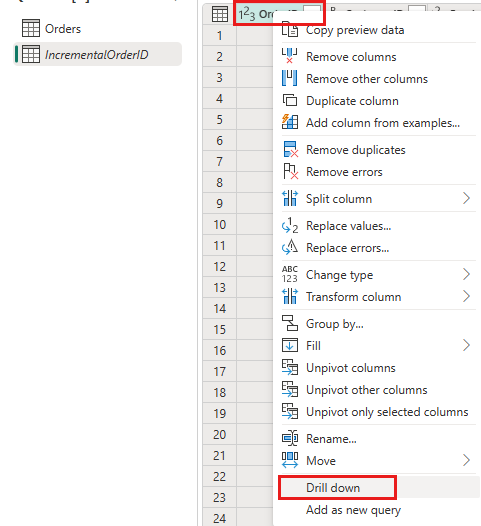
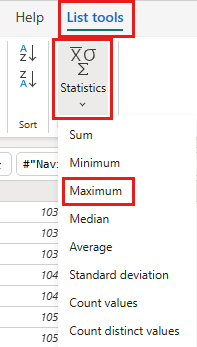
Na faixa de opções, selecione Ferramentas da Lista ->Estatísticas ->Máximo.
Agora tens uma consulta que retorna o OrderID máximo no lakehouse. Essa consulta é usada para filtrar os dados da fonte OData. A próxima seção adiciona uma consulta ao fluxo de dados para filtrar os dados da fonte OData com base no OrderID máximo na data lakehouse.
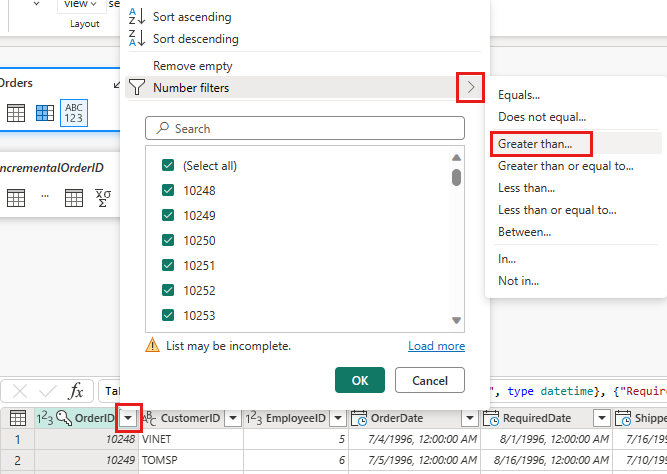
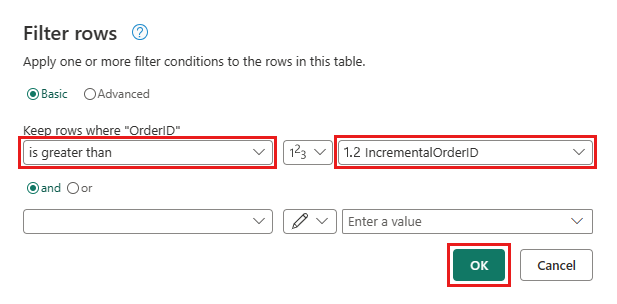
Volte para a consulta Pedidos e adicione uma nova etapa para filtrar os dados. Utilize as seguintes definições:
- Coluna:
OrderID - Funcionamento:
Greater than - Valor: parâmetro
IncrementalOrderID
- Coluna:
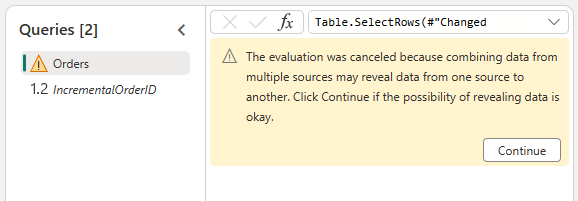
Permita combinar os dados da fonte OData e do lakehouse ao confirmar a seguinte caixa de diálogo:
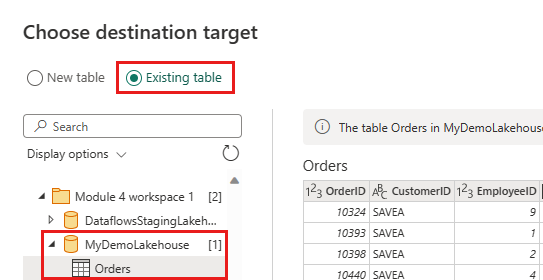
Atualize o destino dos dados para usar as seguintes configurações:
- Método de atualização:
Append

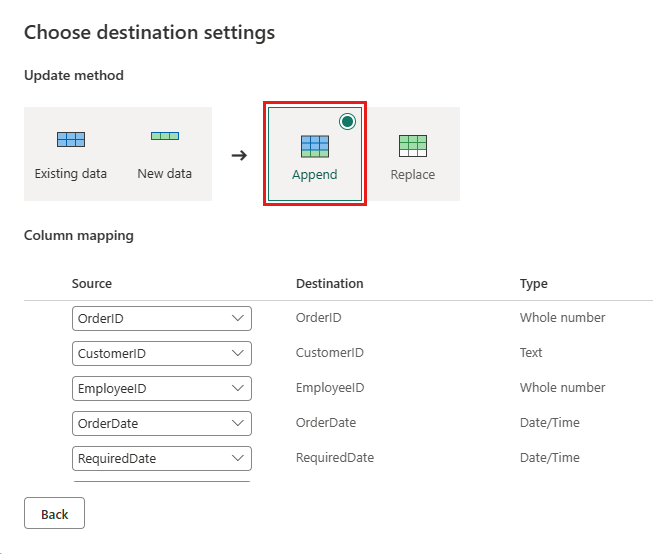
- Método de atualização:
Publique o fluxo de dados.
O seu fluxo de dados agora contém uma consulta que filtra os dados da fonte OData com base no OrderID máximo no lakehouse. Isso significa que apenas dados novos ou atualizados são carregados na casa do lago. A próxima seção utiliza o fluxo de dados para recarregar informações utilizando notebooks e pipelines.
(Opcional) recarregar dados usando notebooks e pipelines
Opcionalmente, você pode recarregar dados específicos usando blocos de anotações e pipelines. Com código Python personalizado no notebook, removem-se os dados antigos do lakehouse. Em seguida, ao criar um pipeline no qual o bloco de anotações é executado primeiro e em seguida o fluxo de dados é executado sequencialmente, recarregam-se os dados da fonte OData no lakehouse. Os notebooks suportam vários idiomas, mas este tutorial usa o PySpark. O Pyspark é uma API Python para o Spark e é usado neste tutorial para executar consultas SQL do Spark.
Crie um novo bloco de notas na sua área de trabalho.
Adicione o seguinte código PySpark ao seu bloco de notas:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Execute o notebook para verificar se os dados foram removidos do lakehouse.
Crie um novo pipeline em seu espaço de trabalho.
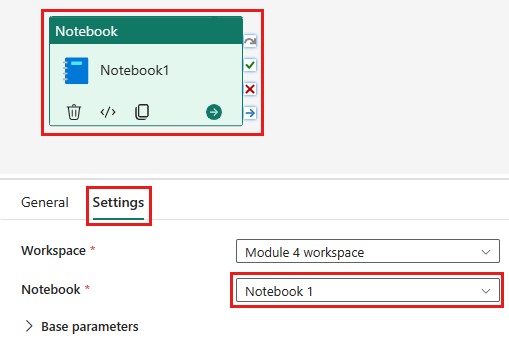
Adicione uma nova atividade de notebook ao pipeline e selecione o notebook criado na etapa anterior.
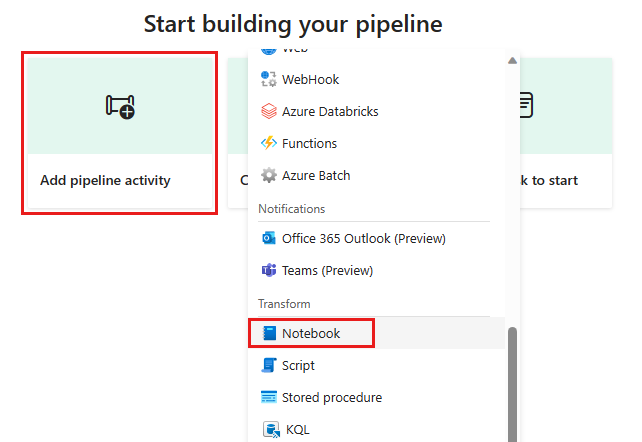
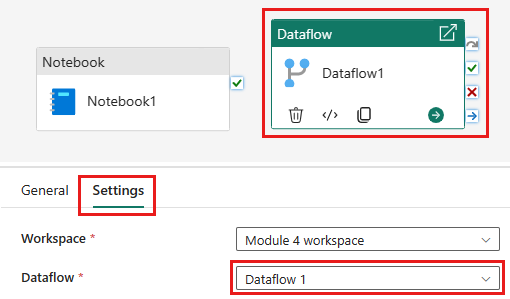
Adicione uma nova atividade de fluxo de dados ao pipeline e selecione o fluxo de dados criado na seção anterior.
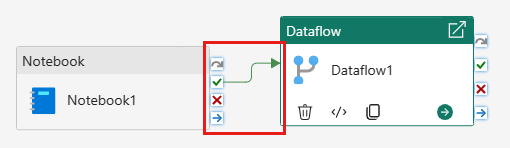
Vincule a atividade do bloco de anotações à atividade de fluxo de dados com um gatilho de sucesso.
Salve e execute o pipeline.


Agora, tem um pipeline que elimina dados antigos do lakehouse e carrega novamente os dados da fonte OData no lakehouse. Com esta configuração, é possível recarregar os dados da fonte OData no lakehouse regularmente.