Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Um modelo de aprendizado de máquina é um arquivo treinado para reconhecer certos tipos de padrões. Você treina um modelo sobre um conjunto de dados e fornece a ele um algoritmo que usa para raciocinar e aprender com esse conjunto de dados. Depois de treinar o modelo, você pode usá-lo para raciocinar sobre dados que nunca viu antes e fazer previsões sobre esses dados.
No MLflow, um modelo de aprendizado de máquina pode incluir várias versões de modelo. Aqui, cada versão pode representar uma iteração de modelo. Neste artigo, aprende a interagir com modelos de ML para acompanhar e comparar iterações de modelos.
Neste artigo, aprende como:
- Criar modelos de aprendizagem automática no Microsoft Fabric
- Gestão e acompanhamento das versões dos modelos
- Compare o desempenho dos modelos entre versões
- Aplicar modelos para pontuação e inferência
Criar um modelo de aprendizagem automática
Pode criar um modelo de aprendizagem automática a partir da interface do Fabric ou programaticamente com a API MLflow. No MLflow, os modelos utilizam um formato de empacotamento padrão que funciona com várias outras ferramentas, incluindo a inferência em lote no Apache Spark. O formato guarda um modelo em diferentes "versões" que diferentes ferramentas subsequentes conseguem compreender.
Para criar um modelo de aprendizagem automática a partir da interface:
- Selecione um espaço de trabalho de ciência de dados existente, ou crie um novo espaço de trabalho.
- Crie um novo item através do espaço de trabalho ou usando o botão Criar:
- Espaço de trabalho:
- Selecione a área de trabalho.
- Selecione Novo item.
- Selecione Modelo de ML em Analisar e treinar dados.
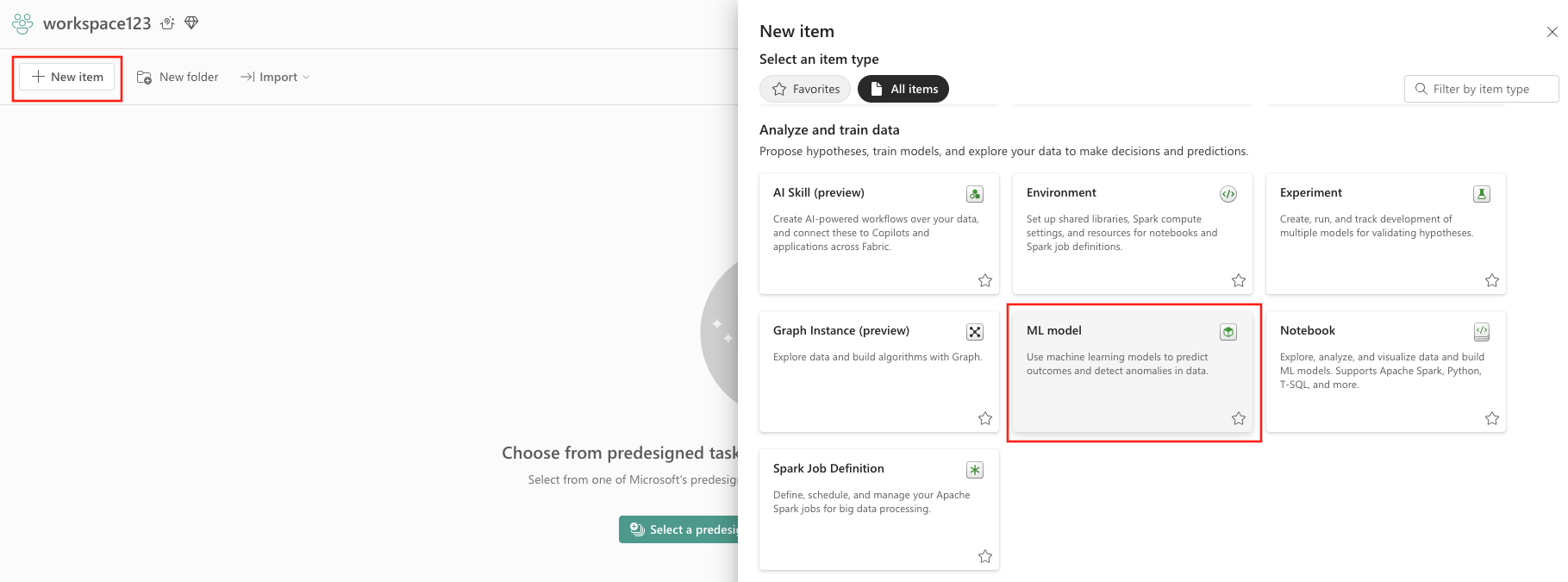
- Botão Criar:
- Selecione Criar, que pode ser encontrado em ... no menu vertical.
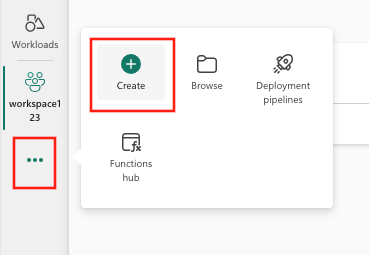
- Selecione Modelo de ML em Ciência de Dados.

- Selecione Criar, que pode ser encontrado em ... no menu vertical.
- Espaço de trabalho:
- Após a criação do modelo, você pode começar a adicionar versões do modelo para controlar métricas e parâmetros de execução. Registre ou salve execuções de experimento em um modelo existente.



Você também pode criar um modelo de aprendizado de máquina diretamente de sua experiência de criação com a mlflow.register_model() API. Se um modelo de aprendizado de máquina registrado com o nome fornecido não existir, a API o criará automaticamente.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Gerenciar versões dentro de um modelo de aprendizado de máquina
Um modelo de aprendizado de máquina contém uma coleção de versões de modelo para rastreamento e comparação simplificados. Dentro de um modelo, um cientista de dados pode navegar por várias versões do modelo para explorar os parâmetros e métricas subjacentes. Os cientistas de dados também podem fazer comparações entre versões de modelos para identificar se modelos mais recentes podem ou não produzir melhores resultados.
Note
Com suporte do MLflow 3 no Fabric, cada modelo que registar com mlflow.<flavor>.log_model(model, name="...") cria uma entidade LoggedModel que fica associada à respetiva execução de origem, aos parâmetros, às métricas, aos conjuntos de dados e ao ambiente. Pode abrir um LlogedModel a partir da página do experimento e registá-lo como um novo modelo de ML ou uma nova versão de um modelo existente. Para mais detalhes, veja MLflow 3 em Fabric Ciência de Dados.
Rastreie modelos de aprendizado de máquina
Uma versão de modelo de aprendizado de máquina representa um modelo individual que é registrado para rastreamento.
![]()
Cada versão do modelo inclui as seguintes informações:
| Propriedade | Description |
|---|---|
| Tempo de Criação | Data e hora da criação do modelo. |
| Nome de Execução | O identificador da execução do experimento usado para criar esta versão específica do modelo. |
| Hiperparâmetros | Guardados como pares chave-valor. Tanto as chaves quanto os valores são cadeias de caracteres. |
| Métricas | Executar métricas guardadas como pares de chave e valor. O valor é numérico. |
| Esquema/Assinatura do Modelo | Uma descrição das entradas e saídas do modelo. |
| Ficheiros registados | Ficheiros registados em qualquer formato. Por exemplo, você pode gravar imagens, ambiente, modelos e arquivos de dados. |
| Etiquetas | Metadados personalizados como pares chave-valor anexados às execuções. Aprenda a aplicar etiquetas. |
Aplicar tags a modelos de aprendizado de máquina
A marcação MLflow para versões de modelo permite que os usuários anexem metadados personalizados a versões específicas de um modelo registrado no Registro de Modelo MLflow. Essas tags, armazenadas como pares chave-valor, ajudam a organizar, rastrear e diferenciar entre as versões do modelo, facilitando o gerenciamento dos ciclos de vida do modelo. As tags podem ser usadas para indicar a finalidade do modelo, o ambiente de implantação ou qualquer outra informação relevante, facilitando o gerenciamento mais eficiente do modelo e a tomada de decisões dentro das equipes.
Este código demonstra como treinar um modelo RandomForestRegressor usando Scikit-learn, registrar o modelo e os parâmetros com MLflow e, em seguida, registrar o modelo no Registro de Modelo MLflow com tags personalizadas. Essas tags fornecem metadados úteis, como nome do projeto, departamento, equipe e trimestre do projeto, facilitando o gerenciamento e o acompanhamento da versão do modelo.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
Depois de aplicar as tags, você pode visualizá-las diretamente na página de detalhes da versão do modelo. Além disso, as tags podem ser adicionadas, atualizadas ou removidas desta página a qualquer momento.

Comparar e filtrar modelos de aprendizagem automática
Para comparar e avaliar a qualidade das versões do modelo de aprendizado de máquina, você pode comparar os parâmetros, métricas e metadados entre as versões selecionadas.
Compare visualmente modelos de aprendizado de máquina
Você pode comparar visualmente execuções dentro de um modelo existente. A comparação visual permite uma navegação fácil entre várias versões e ordenações entre elas.

Para comparar execuções, você pode:
- Selecione um modelo de aprendizado de máquina existente que contenha várias versões.
- Selecione o separador Ver e navegue para a vista de lista do modelo. Você também pode selecionar a opção Exibir lista de modelos diretamente na visualização de detalhes.
- Você pode personalizar as colunas dentro da tabela. Expanda o painel Personalizar colunas . A partir daí, você pode selecionar as propriedades, métricas, tags e hiperparâmetros que deseja ver.
- Por fim, você pode selecionar várias versões, para comparar seus resultados, no painel de comparação de métricas. Neste painel, você pode personalizar os gráficos com alterações no título do gráfico, tipo de visualização, eixo X, eixo Y e muito mais.
Compare modelos de aprendizado de máquina usando a API MLflow
Os cientistas de dados também podem usar o MLflow para pesquisar entre vários modelos salvos no espaço de trabalho. Visite a documentação do MLflow para explorar outras APIs do MLflow para interação do modelo.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Aplicar modelos de aprendizagem automática
Depois de treinar um modelo em um conjunto de dados, você pode aplicar esse modelo a dados que ele nunca viu para gerar previsões. Chamamos a utilização deste modelo de técnica de pontuação ou de inferência.
O Fabric suporta múltiplas abordagens para aplicar os seus modelos treinados:
- Pontuação por lote Aplique o seu modelo em escala em grandes conjuntos de dados usando o Apache Spark. Isto é ideal para gerar previsões com base em dados históricos ou agendados.
- Pontuação em tempo real Implemente o seu modelo num endpoint para previsões a pedido, úteis para aplicações que necessitam de resultados imediatos.
Para começar a aplicar os seus modelos, escolha a abordagem que se adequa ao seu cenário: