Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este documento fornece orientações específicas para a experiência na recuperação dos seus dados Fabric em caso de desastre regional.
Cenário de exemplo
Muitas seções de orientação neste documento usam o seguinte cenário de exemplo para fins de explicação e ilustração. Consulte novamente este cenário conforme necessário.
Digamos que você tenha uma capacidade C1 na região A que tenha um espaço de trabalho W1. Se ativou recuperação em desastres para capacidade C1, os dados do OneLake são replicados para um backup na região B. Se a região A enfrentar interrupções, o serviço Fabric em C1 passa para a região B.
Nota
Esta orientação de recuperação aplica-se apenas quando a região primária tem uma região secundária emparelhada com Azure e o Fabric é suportado nessa região emparelhada.
A imagem a seguir ilustra esse cenário. A caixa à esquerda mostra a região afetada. A caixa no meio representa a disponibilidade contínua dos dados após o failover, e a caixa à direita mostra a situação totalmente coberta depois que o cliente age para restaurar seus serviços para o pleno funcionamento.
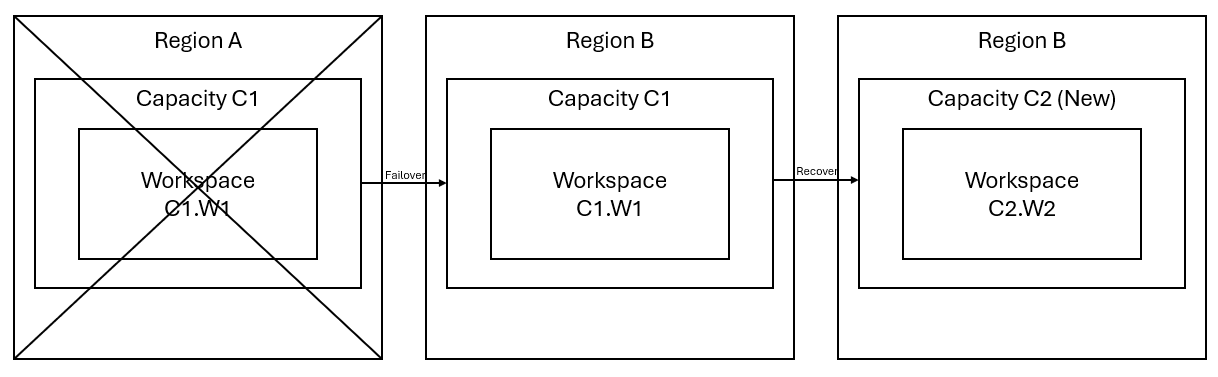
Eis o plano geral de recuperação:
Crie uma nova capacidade Fabric C2 numa nova região.
Crie um novo espaço de trabalho W2 em C2, incluindo seus itens correspondentes com os mesmos nomes que em C1. W1.
Copie os dados do C1.W1 interrompido para C2.W2.
Siga as instruções dedicadas para cada componente para restaurar os itens para a sua função completa.
Este plano de recuperação assume que a região de residência dos inquilinos permanece operacional. Se a região de origem do inquilino sofrer uma interrupção, os passos descritos neste documento dependem da sua recuperação, que deve ser iniciada e concluída primeiro pela Microsoft.
Planos de recuperação adaptados a experiências específicas
As secções seguintes fornecem guias passo a passo para cada experiência Fabric, ajudando os clientes durante o processo de recuperação.
Engenheria de Dados
Este guia orienta você pelos procedimentos de recuperação para a experiência de Engenharia de Dados. Abrange casas de lago, cadernos e definições de trabalho do Spark.
Casa do Lago
As residências à beira do lago da região original permanecem indisponíveis para os clientes. Para recuperar uma casa do lago, os clientes podem recriá-la no espaço de trabalho C2. W2. Recomendamos duas abordagens para recuperar casas de lago:
Abordagem 1: Usando script personalizado para copiar tabelas e arquivos Lakehouse Delta
Os clientes podem recriar lakehouses usando um script Scala personalizado.
Crie a casa do lago (por exemplo, LH1) no espaço de trabalho C2 recém-criado. W2.
Crie um novo bloco de anotações no espaço de trabalho C2. W2.
Para recuperar as tabelas e ficheiros do lakehouse original, consulte os dados com os caminhos OneLake, como abfss (ver Ligar ao Microsoft OneLake). Pode usar o seguinte exemplo de código (ver Introdução às Microsoft Spark Utilities) no notebook para obter os caminhos ABFS dos ficheiros e tabelas do lakehouse original. (Substituir C1. W1 com o nome real do espaço de trabalho)
notebookutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Use o exemplo de código a seguir para copiar tabelas e arquivos para o lakehouse recém-criado.
Para tabelas Delta, você precisa copiar a tabela uma de cada vez para recuperar na nova casa do lago. No caso de arquivos Lakehouse, você pode copiar a estrutura completa do arquivo com todas as pastas subjacentes com uma única execução.
Entre em contato com a equipa de suporte para obter a marca temporal necessária do failover no script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support notebookutils.fs.cp(source, destination, true) val filesToDelete = notebookutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelete <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelete.name}" println(s"Deleting file $destFileToDelete") notebookutils.fs.rm(destFileToDelete, false) } notebookutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Depois de executar o script, as tabelas aparecem na nova casa do lago.
Abordagem 2: Usar o Azure Storage Explorer para copiar ficheiros e tabelas
Para recuperar apenas ficheiros ou tabelas específicas de um Lakehouse a partir do Lakehouse original, use o Azure Storage Explorer. Consulte Integrar OneLake com Azure Storage Explorer para passos detalhados. Para tamanhos de dados grandes, use a Abordagem 1.
Nota
As duas abordagens descritas acima recuperam os metadados e os dados para tabelas formatadas em Delta, porque os metadados são colocalizados e armazenados com os dados no OneLake. Para tabelas não formatadas em Delta (por exemplo, CSV, Parquet, etc.) que são criadas usando scripts/comandos DDL (Spark Data Definition Language), o usuário é responsável por manter e executar novamente os scripts/comandos DDL do Spark para recuperá-los.
A recuperação de Fabric materializou vistas para o lago
As visualizações materializadas do Lago da região original continuam indisponíveis para os clientes após o failover. Os horários de atualização e o histórico de execução não são replicados para a região secundária. Para os recuperar, complete os seguintes passos após recuperar os seus dados de Lakehouse.
- Recupere as tabelas de Lakehouse usando a Aproximação 1 ou Abordagem 2 descrita acima. Copie apenas as tabelas de origem.
- Recupera os cadernos que contêm as definições do teu MLV. Consulte a secção do Caderno para os passos de recuperação.
- Executar os cadernos recuperados para recriar os MLVs no novo Lakehouse. Para informações sobre a criação de MLVs, consulte Criar uma Vista de Lago Materializada. Se os MLVs foram também copiados na etapa anterior, execute CREATE OR REPLACE ao recriá-los.
- Recrie manualmente os agendamentos de atualização do MLV no novo espaço de trabalho. O histórico de agendamento e as métricas de execução não são recuperáveis.
- Se os seus MLVs fornecem modelos semânticos ou relatórios, verifique e atualize as referências do ID Lakehouse e do ID do conjunto de dados conforme necessário. Reconecte os relatórios ao modelo semântico atualizado e valide a novidade dos dados.
Sugestão
Para minimizar alterações de código ao executar notebooks após o failover, use os mesmos nomes workspace e Lakehouse na nova região (especialmente ao usar o nome Workspace ou Lakehouse nas convenções de nomenclatura). Os cronogramas de atualização, o histórico de execução e as métricas operacionais começam do zero na região recuperada. Planeie um período de referência ao estabelecer novos limiares de monitorização.
Bloco de Notas
Os notebooks da região primária permanecem indisponíveis para os clientes, e o código nos notebooks não é replicado para a região secundária. Para recuperar código de Notebook na nova região, existem duas abordagens para recuperar o seu conteúdo.
Abordagem 1: Redundância gerenciada pelo usuário com integração Git (em visualização pública)
A melhor forma de tornar isto fácil e rápido é usar integração com o Fabric Git e depois sincronizar o teu portátil com o repositório ADO. Depois que o serviço fizer failover para outra região, você poderá usar o repositório para reconstruir o bloco de anotações no novo espaço de trabalho criado.
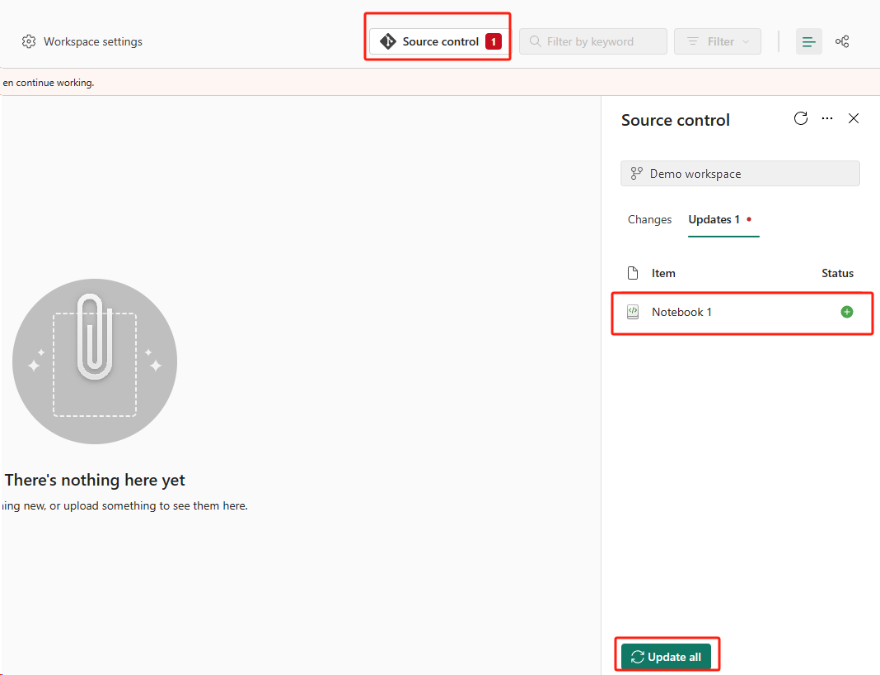
Configure a Integração Git para seu espaço de trabalho e selecione Conectar e sincronizar com o repositório ADO.
A imagem a seguir mostra o bloco de anotações sincronizado.
Recupere o bloco de anotações do repositório ADO.
No espaço de trabalho recém-criado, ligue-se novamente ao seu repositório Azure ADO.
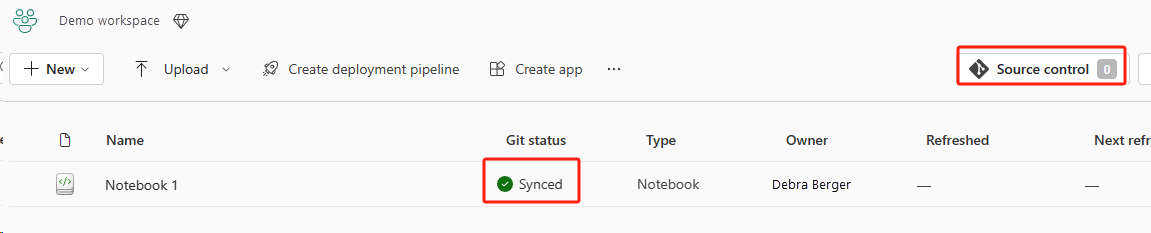
Selecione o botão Controle do código-fonte. Em seguida, selecione a ramificação relevante do repositório. Em seguida, selecione Atualizar tudo. O bloco de notas original é apresentado.
Se o notebook original tiver uma casa de lago padrão, os usuários podem consultar a seção Lakehouse para recuperar a casa do lago e, em seguida, conectar a casa do lago recém-recuperada ao notebook recém-recuperado.
A integração do Git não suporta sincronizar ficheiros, pastas ou instantâneos do notebook no explorador de recursos do notebook.
Se o bloco de notas original tiver ficheiros no explorador de recursos do bloco de notas:
Certifique-se de salvar arquivos ou pastas em um disco local ou em algum outro lugar.
Recarregue o ficheiro a partir do seu disco local ou unidades na nuvem para o bloco de notas recuperado.
Se o bloco de anotações original tiver um instantâneo do bloco de anotações, também salve o instantâneo no seu próprio sistema de controle de versão ou no disco local.
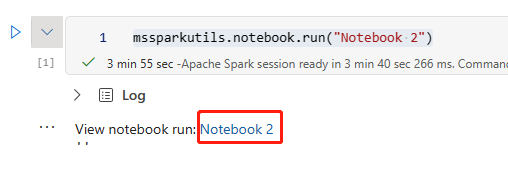
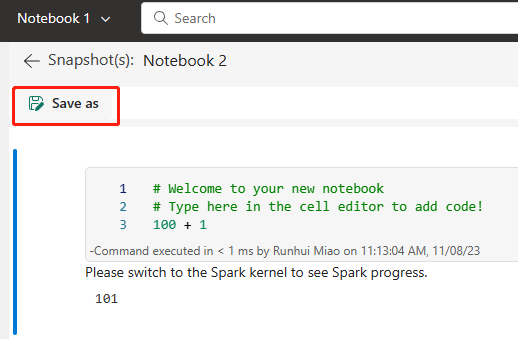
Para obter mais informações sobre a integração do Git, consulte Introdução à integração do Git.
Abordagem 2: Abordagem manual para fazer backup do conteúdo do código
Se você não adotar a abordagem de integração do Git, poderá salvar a versão mais recente do código, os arquivos no explorador de recursos e o instantâneo do bloco de anotações em um sistema de controle de versão, como o Git, e recuperar manualmente o conteúdo do bloco de anotações após um desastre:
Use o recurso "Importar bloco de anotações" para importar o código do bloco de anotações que você deseja recuperar.
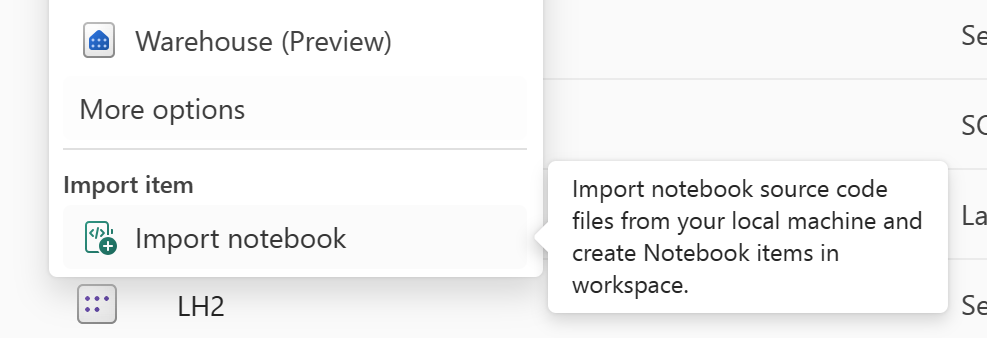
Após a importação, vá para o espaço de trabalho desejado (por exemplo, "C2. W2") para acessá-lo.
Se o notebook original tiver uma lakehouse padrão, consulte a seção Lakehouse. Em seguida, conecte o lakehouse recém-recuperado (que tem o mesmo conteúdo do lakehouse padrão original) ao notebook recém-recuperado.
Se o bloco de notas original tiver ficheiros ou pastas no explorador de recursos, volte a carregar os ficheiros ou pastas guardados no sistema de controlo de versão do utilizador.
Definição de trabalho do Spark
As definições de trabalho do Spark (SJD) da região primária permanecem indisponíveis para os clientes, e o arquivo de definição principal e o arquivo de referência no bloco de anotações serão replicados para a região secundária por meio do OneLake. Se você quiser recuperar o SJD na nova região, você pode seguir as etapas manuais descritas abaixo para recuperar o SJD. As execuções históricas do SJD não serão restauradas.
Podes recuperar os itens SJD copiando o código da região original usando o Azure Storage Explorer e reconectando manualmente as referências do Lakehouse após o desastre.
Crie um novo item SJD (por exemplo, SJD1) no novo espaço de trabalho C2. W2, com as mesmas definições e configurações do item SJD original (por exemplo, idioma, ambiente, etc.).
Utilize o Azure Storage Explorer para copiar Libs, Mains e Snapshots do item SJD original para o novo item SJD.
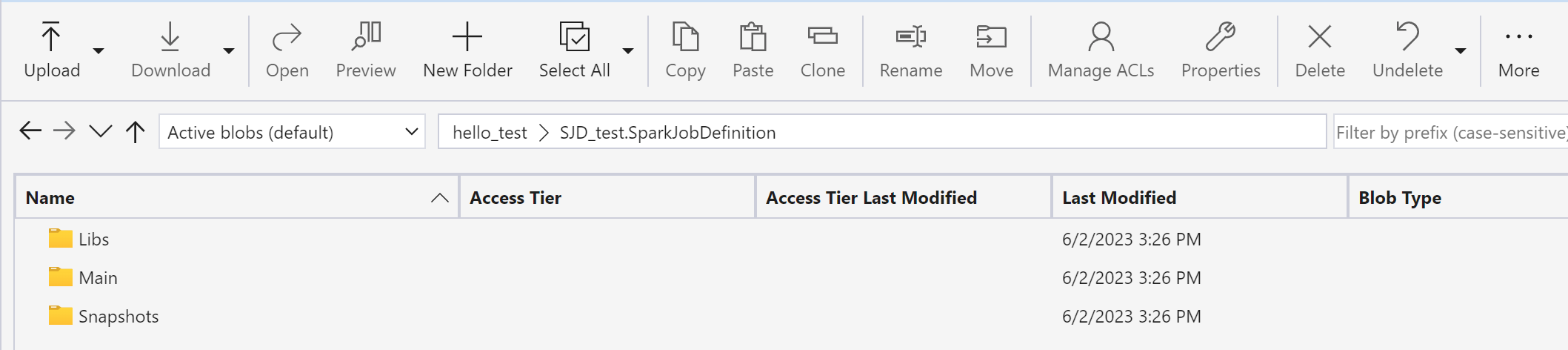
O conteúdo do código aparecerá no SJD recém-criado. Você precisará adicionar manualmente a referência recém-recuperada do Lakehouse ao trabalho (Para mais detalhes, consulte as etapas de recuperação do Lakehouse). Os usuários precisarão reinserir os argumentos de linha de comando originais manualmente.
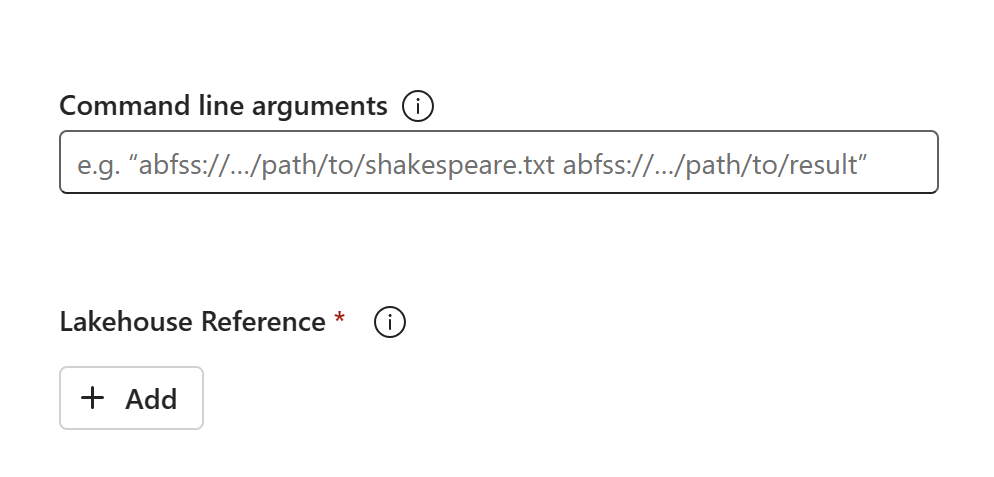
Agora você pode executar ou agendar seu SJD recém-recuperado.
Para detalhes sobre Azure Storage Explorer, consulte Integrar OneLake com Azure Storage Explorer.
Ciência de Dados
Este guia orienta você pelos procedimentos de recuperação para a experiência de Ciência de Dados. Abrange modelos e experiências de ML.
Modelo e Experimento de ML
Os itens de Ciência de Dados da região primária permanecem indisponíveis para os clientes, e o conteúdo e os metadados em modelos e experimentos de ML não serão replicados para a região secundária. Para recuperá-los totalmente na nova região, salve o conteúdo do código em um sistema de controle de versão (como o Git) e execute manualmente o conteúdo do código novamente após o desastre.
Recupere o bloco de notas. Consulte as etapas de recuperação do Notebook.
A configuração, as métricas de execução histórica e os metadados não serão replicados para a região emparelhada. Você terá que executar novamente cada versão do seu código de ciência de dados para recuperar totalmente os modelos e experimentos de ML após o desastre.
Armazém de Dados
Este guia guia-o pelos procedimentos de recuperação para a experiência no Data Warehouse. Abrange armazéns.
Armazém
Os armazéns da região original permanecem indisponíveis para os clientes. Para recuperar armazéns, use as duas etapas a seguir.
Crie uma nova casa de lago provisória no espaço de trabalho C2. W2 para os dados que irá copiar do armazém original.
Preenche as tabelas Delta do armazém aproveitando o Explorador do armazém e as capacidades T-SQL (ver Tabelas em data warehousing em Microsoft Fabric).
Nota
É recomendável que você mantenha o código do Warehouse (esquema, tabela, exibição, procedimento armazenado, definições de função e códigos de segurança) versionado e salvo em um local seguro (como o Git) de acordo com suas práticas de desenvolvimento.
Ingestão de dados via Lakehouse e código T-SQL
No espaço de trabalho recém-criado C2.W2:
Crie uma casa de lago provisória "LH2" em C2. W2.
Recupere as tabelas Delta no lakehouse interino do armazém original seguindo as etapas de recuperação Lakehouse.
Crie um novo armazém "WH2" em C2. W2.
Conecte a casa do lago provisória em seu explorador de armazém.
Dependendo de como você vai implantar definições de tabela antes da importação de dados, o T-SQL real usado para importações pode variar. Você pode usar a abordagem INSERT INTO, SELECT INTO ou CREATE TABLE AS SELECT para recuperar tabelas de armazém de lakehouses. Mais adiante no exemplo, vamos utilizar o comando INSERT INTO. (Se você usar o código abaixo, substitua exemplos por nomes reais de tabelas e colunas)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOPor fim, altera a cadeia de conexão nas aplicações que usam o seu armazém Fabric.
Nota
Para clientes que necessitem de recuperação de desastres inter-regionais e de continuidade de negócio totalmente automatizada, recomendamos manter duas configurações Fabric Warehouse em regiões Fabric separadas e manter a paridade de código e dados através de implementações regulares e ingestão de dados em ambos os locais.
Base de dados espelhada
Os bancos de dados espelhados da região primária permanecem indisponíveis para os clientes e as configurações não são replicadas para a região secundária. Para recuperá-lo no caso de uma falha regional, você precisa recriar seu banco de dados espelhado em outro espaço de trabalho de uma região diferente.
Data Factory
Os itens do Data Factory da região primária permanecem indisponíveis para os clientes e as definições e configurações em pipelines ou itens gen2 do fluxo de dados não serão replicadas para a região secundária. Para recuperar esses itens no caso de uma falha regional, você precisará recriar seus itens de Integração de Dados em outro espaço de trabalho de uma região diferente. As seções a seguir descrevem os detalhes.
Fluxos de dados Gen2
Se você quiser recuperar um item Dataflow Gen2 na nova região, precisará exportar um arquivo PQT para um sistema de controle de versão, como o Git, e, em seguida, recuperar manualmente o conteúdo do Dataflow Gen2 após o desastre.
A partir do seu item Dataflow Gen2, no separador Início do editor de Power Query, selecione Exportar modelo.
Na caixa de diálogo Exportar modelo, insira um nome (obrigatório) e uma descrição (opcional) para esse modelo. Quando terminar, selecione OK.
Após o desastre, crie um novo item Dataflow Gen2 no novo espaço de trabalho "C2. W2".
No painel de visualização atual do editor de Power Query, selecione Importar de um modelo de Power Query.
Na caixa de diálogo Abrir, navegue até a pasta de downloads padrão e selecione o arquivo .pqt salvo nas etapas anteriores. Em seguida, selecione Abrir.
O modelo é então importado para o novo item Dataflow Gen2.
A funcionalidade Salvar como de fluxos de dados não é suportada em situações de recuperação de desastres.
Tubulações
Os clientes não podem aceder a pipelines em caso de um desastre regional, e as configurações não são replicadas para a região emparelhada. Recomendamos a criação dos seus pipelines críticos em vários espaços de trabalho em diferentes regiões.
Tarefa de Cópia
Os usuários do CopyJob devem tomar medidas proativas para se proteger contra um desastre regional. A abordagem a seguir garante que, após um desastre regional, os CopyJobs de um usuário permaneçam disponíveis.
Redundância gerenciada pelo usuário com integração Git (em visualização pública)
A melhor forma de tornar este processo fácil e rápido é usar integração com o Fabric Git e depois sincronizar o seu CopyJob com o seu repositório ADO. Depois que o serviço fizer failover para outra região, você poderá usar o repositório para reconstruir o CopyJob no novo espaço de trabalho criado.
Configure a integração Git do seu espaço de trabalho e selecione conectar e sincronizar com o repositório ADO.
A imagem a seguir mostra o CopyJob sincronizado.
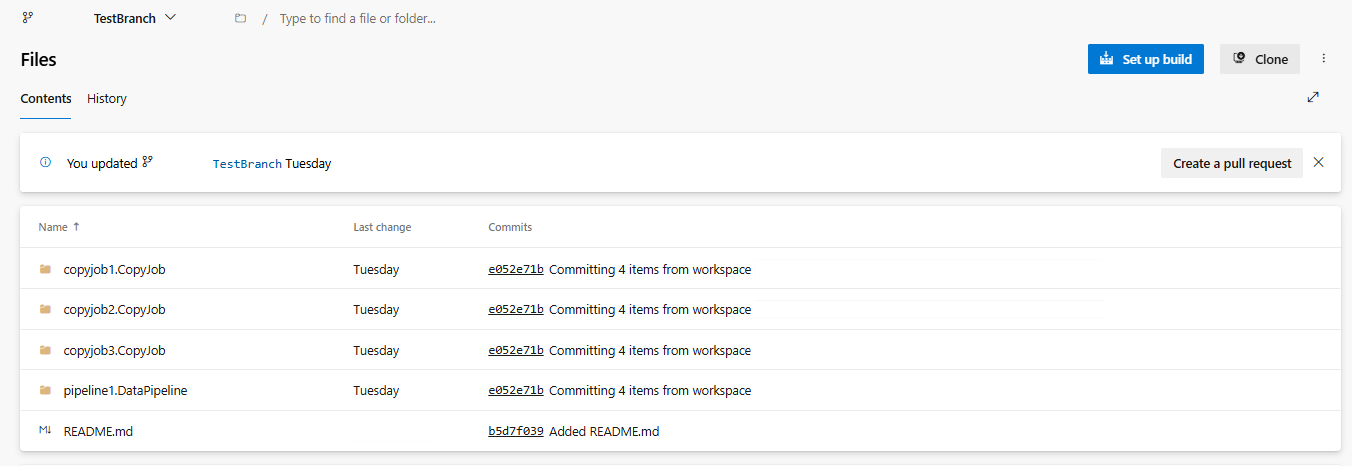
Recupere o CopyJob do repositório ADO.
No espaço de trabalho recém-criado, ligue-se e sincronize novamente com o seu repositório Azure ADO. Todos os itens Fabric neste repositório são automaticamente descarregados para o seu novo Workspace.
Se o CopyJob original usar um Lakehouse, os utilizadores podem consultar a seção do Lakehouse para recuperar o Lakehouse e, em seguida, conectar o CopyJob recém-recuperado ao Lakehouse recém-recuperado.
Para obter mais informações sobre a integração do Git, consulte Introdução à integração do Git.
Tarefa do Apache Airflow
Os utilizadores do Apache Airflow Job in Fabric devem tomar medidas proativas para se proteger contra um desastre regional.
Recomendamos gerir a redundância com integração do Fabric Git. Primeiro, sincronize a sua tarefa do Airflow com o seu repositório ADO. Se o serviço fizer failover para outra região, você poderá usar o repositório para reconstruir o Trabalho de Fluxo de Ar no novo espaço de trabalho criado.
Aqui estão os passos para conseguir isso:
Configure a integração do Git do seu espaço de trabalho e selecione "conectar e sincronizar" com o repositório ADO.
Depois disso, irá ver que a sua tarefa de Airflow foi sincronizada com o repositório ADO.
Se precisares de recuperar o trabalho Airflow do repositório ADO, cria um novo espaço de trabalho, liga-te e sincroniza novamente com o repositório Azure ADO. Todos os itens Fabric, incluindo o Airflow, neste repositório serão automaticamente descarregados para o seu novo espaço de trabalho.
Informação em Tempo Real
Este guia orienta você pelos procedimentos de recuperação para a experiência de Inteligência em Tempo Real. Abrange bases de dados/conjuntos de consultas KQL e fluxos de eventos.
Modelo de grafo/conjunto de consultas
Os itens do Graph Model e do Graph Queryset da região principal continuam indisponíveis para os clientes, e estes itens não são replicados para a região secundária. Para recuperar, crie ou use uma capacidade numa região diferente e recrie os itens do Modelo de Grafo e do Conjunto de Consultas de Grafo aí.
Crie ou use uma capacidade Fabric existente numa região diferente que não seja afetada pelo desastre.
Crie um novo espaço de trabalho ou use um espaço de trabalho existente nessa função.
Recrie o item do Modelo de Grafo no espaço de trabalho secundário (referenciado no passo 2). Reconfigure a definição do modelo, incluindo nós, arestas, etc., para corresponder ao Modelo de Grafo original.
Se a casa original do lago estiver na região em decadência, recupere-a primeiro seguindo a secção da Casa do Lago.
Ligue uma casa de lago como fonte de dados OneLake para o item recém-criado do Modelo de Grafo. Use um data lakehouse recuperado se este estivesse na região com falhas, ou reconecte-se ao data lakehouse existente se este continuar disponível.
Reconfigure quaisquer horários de carregamento de dados ou ligações para o Modelo de Grafo no novo espaço de trabalho.
Recrie o item Graph Queryset no espaço de trabalho secundário. Reintroduza manualmente as consultas e quaisquer configurações de consulta guardadas do Graph Queryset original.
Banco de dados KQL/Queryset
Os usuários do banco de dados/conjunto de consultas KQL devem tomar medidas proativas para se proteger contra um desastre regional. A abordagem a seguir garante que, no caso de um desastre regional, os dados em seus conjuntos de consultas de bancos de dados KQL permaneçam seguros e acessíveis.
Use as etapas a seguir para garantir uma solução eficaz de recuperação de desastres para bancos de dados e conjuntos de consultas KQL.
Estabelecer bases de dados KQL independentes: Configurar duas ou mais bases de dados/conjuntos de consultas KQL independentes em capacidades Fabric dedicadas. Estas devem ser configuradas em duas regiões diferentes do Azure (preferencialmente regiões emparelhadas com o Azure) para maximizar a resiliência.
Replicar atividades de gerenciamento: qualquer ação de gerenciamento executada em um banco de dados KQL deve ser espelhada no outro. Isso garante que ambos os bancos de dados permaneçam sincronizados. As principais atividades a serem replicadas incluem:
Tabelas: Certifique-se de que as estruturas de tabela e as definições de esquema sejam consistentes entre os bancos de dados.
Mapeamento: duplique todos os mapeamentos necessários. Certifique-se de que as fontes de dados e os destinos estão alinhados corretamente.
Políticas: certifique-se de que ambos os bancos de dados tenham políticas semelhantes de retenção, acesso e outras políticas relevantes.
Gerenciar autenticação e autorização: para cada réplica, configure as permissões necessárias. Certifique-se de que os níveis de autorização adequados sejam estabelecidos, concedendo acesso ao pessoal necessário, mantendo os padrões de segurança.
Ingestão paralela de dados: para manter os dados consistentes e prontos em várias regiões, carregue o mesmo conjunto de dados em cada banco de dados KQL ao mesmo tempo em que o ingere.
Eventstream
Um fluxo de eventos é um local centralizado na plataforma Fabric para capturar, transformar e encaminhar eventos em tempo real para vários destinos (por exemplo, lakehouses, bases de dados/conjuntos de consultas KQL) com uma experiência sem código. Desde que os destinos sejam suportados pela recuperação de desastres, os fluxos de eventos não perderão dados. Portanto, os clientes devem usar os recursos de recuperação de desastres desses sistemas de destino para garantir a disponibilidade dos dados.
Os clientes também podem alcançar geo-redundância ao implementar cargas de trabalho Eventstream idênticas em múltiplas regiões do Azure como parte de uma estratégia multi-site ativo/ativo. Com uma abordagem ativa/ativa em vários locais, os clientes podem aceder ao seu workload em qualquer uma das regiões implementadas. Essa abordagem é a mais complexa e dispendiosa para a recuperação de desastres, mas pode reduzir o tempo de recuperação para quase zero na maioria das situações. Para serem totalmente redundantes geograficamente, os clientes podem
Crie réplicas de suas fontes de dados em diferentes regiões.
Crie itens Eventstream nas regiões correspondentes.
Conecte esses novos itens às fontes de dados idênticas.
Adicione destinos idênticos para cada fluxo de eventos em regiões diferentes.
Map
Os itens do mapa da região principal continuam indisponíveis para os clientes e os itens do mapa não são replicados para a região secundária.
Se quiser recuperar um item do Mapa quando acontecer um desastre, configure a integração do Git da Fabric e sincronize o seu item do Mapa com o seu repositório Git.
Durante a recuperação, depois de a nova região/capacidade no Fabric estar configurada, podes usar o repositório para reconstruir o item Map no novo espaço de trabalho que criaste. Como o novo espaço de trabalho está vazio, o Git sync coloca o conteúdo do repositório no espaço de trabalho vazio. Este passo traz o item do Mapa de volta à vida.
Nota
Se o item original do Mapa tiver um lakehouse ou um conjunto de consultas KQL configurado, consulte a secção Lakehouse e a secção do conjunto de consultas KQL para os recuperar primeiro. Depois dessas dependências estarem resolvidas, conecte o lakehouse recém-recuperado e o queryset ao item do mapa recém-recuperado.
Ontologia
Os utilizadores de ontologias devem tomar medidas proativas para se prepararem para a recuperação regional de desastres. A abordagem descrita abaixo garante que, após um desastre regional, a sua Ontologia permaneça recuperável e possa ser restaurada rapidamente.
A forma mais simples e rápida de permitir a recuperação é usar a integração com o Fabric Git e sincronizar a sua Ontologia com um repositório Azure DevOps (ADO). Caso o serviço faça failover para outra região, pode usar este repositório para reconstruir a Ontologia num espaço de trabalho recém-criado.
Os itens de ontologia na região primária não estão disponíveis para os clientes após um desastre regional, e os itens de Ontologia não são replicados para a região secundária.
Para recuperar um item de Ontologia durante um desastre, configure a integração Git do Fabric e sincronize o item de Ontologia com o seu repositório ADO antecipadamente.
Durante a recuperação, uma vez que a nova região e capacidade no Fabric estejam configuradas, pode usar o repositório para reconstruir o item Ontology num novo espaço de trabalho. Como o novo espaço de trabalho está vazio, o Git sync puxa o conteúdo do repositório para o espaço de trabalho, restaurando efetivamente o item Ontologia.
Nota
Se o item original da Ontologia tiver uma casa do lago configurada, consulte a secção da casa do lago para recuperar primeiro a casa do lago. Depois de essas dependências serem resolvidas, ligue a casa do lago recém-recuperada ao item de Ontologia recém-recuperado.
Banco de dados transacional
Este guia descreve os procedimentos de recuperação para a experiência do banco de dados transacional.
base de dados SQL
Para se proteger contra uma falha regional, os usuários de bancos de dados SQL podem tomar medidas proativas para exportar periodicamente seus dados e usar os dados exportados para recriar o banco de dados em um novo espaço de trabalho quando necessário.
Isso pode ser conseguido usando a ferramenta SqlPackage CLI que fornece portabilidade de banco de dados e facilita implantações de banco de dados.
- Use a ferramenta SqlPackage para exportar o banco de dados para um
.bacpacarquivo. Consulte Exportar um banco de dados com SqlPackage para obter mais detalhes. - Armazene o
.bacpacarquivo em um local seguro que esteja em uma região diferente do banco de dados. Exemplos incluem armazenar o ficheiro.bacpacnuma Lakehouse que esteja numa região diferente, usar uma Conta Azure Storage geo-redundante, ou usar outro meio de armazenamento seguro que esteja numa região diferente. - Se o banco de dados SQL e a região não estiverem disponíveis, você poderá usar o
.bacpacarquivo com SqlPackage para recriar o banco de dados em um espaço de trabalho em uma nova região – Workspace C2. W2 na região B, conforme descrito no cenário acima. Siga as etapas detalhadas em Importar um banco de dados com SqlPackage para recriar o banco de dados com seu.bacpacarquivo.
O banco de dados recriado é um banco de dados independente do banco de dados original e reflete o estado dos dados no momento da operação de exportação.
Considerações sobre a reversão para estado original
O banco de dados recriado é um banco de dados independente. Os dados adicionados ao banco de dados recriado não seriam refletidos no banco de dados original. Se planear fazer um failback para a base de dados original quando a região inicial estiver disponível, será necessário considerar a reconciliação manual dos dados da base de dados recriada para a base de dados original.
Platform
Plataforma refere-se aos serviços compartilhados subjacentes e arquitetura que se aplicam a todas as cargas de trabalho. Esta seção orienta você pelos procedimentos de recuperação de experiências compartilhadas. Abrange bibliotecas variáveis.
Biblioteca de variáveis
As bibliotecas Microsoft Fabric Variable permitem aos programadores personalizar e partilhar configurações de itens dentro de um espaço de trabalho, simplificando a gestão do ciclo de vida do conteúdo. Do ponto de vista da recuperação de desastres, os usuários de bibliotecas variáveis devem se proteger proativamente contra um desastre regional. Isto pode ser feito através da integração Fabric Git, que garante que, após um desastre regional, a biblioteca de variáveis do utilizador permaneça disponível. Para recuperar uma biblioteca de variáveis, recomendamos o seguinte:
Use a integração do Fabric Git para sincronizar a sua biblioteca de variáveis com o seu repositório ADO. Em caso de desastre, você pode usar o repositório para reconstruir a biblioteca de variáveis no novo espaço de trabalho criado. Use as seguintes etapas:
No espaço de trabalho recém-criado, ligue-se e sincronize novamente com o seu repositório Azure ADO.
Todos os itens Fabric neste repositório são automaticamente descarregados para o seu novo Workspace.
Depois de sincronizar seus itens do Git, abra suas Bibliotecas de Variáveis no novo espaço de trabalho e selecione manualmente o conjunto de valores ativos desejado.
Chaves geridas pelo cliente para os workspaces do Fabric
Pode usar chaves geridas pelo cliente (CMK) armazenadas no Azure Key Vault para adicionar uma camada adicional de encriptação por cima das chaves geridas pela Microsoft para os dados em repouso. No caso de o Fabric se tornar inacessível ou inoperacional numa região, os seus componentes passarão para uma instância de backup. Durante o failover, o recurso CMK suporta operações em modo de leitura. Enquanto o serviço Azure Key Vault se mantiver saudável e as permissões para o cofre estiverem intactas, o Fabric continuará a conectar-se à sua chave e permitirá a leitura normal dos dados. Isso significa que as seguintes operações não são suportadas durante o failover: habilitar e desabilitar a configuração CMK do espaço de trabalho e atualizar a chave.