Opções de continuidade de negócios e recuperação de desastres para FSLogix
Observação
Todos os diagramas são exemplos baseados na Área de Trabalho Virtual do Azure e são aplicáveis a outras plataformas de área de trabalho virtual.
Um plano eficaz de continuidade de negócios e recuperação de desastres (BCDR) se concentra nos processos e recursos necessários para uma organização operar em caso de catástrofe ou outra interrupção significativa. Os perfis de usuário móvel não são comumente descritos como um componente de negócios ou de missão crítica de uma estratégia BCDR . Em um ambiente de área de trabalho virtual, um usuário não sabe que tem um perfil móvel. O perfil é móvel para fornecer aos usuários uma experiência consistente, independentemente da máquina virtual. Os dados comerciais ou de missão crítica não devem ser armazenados no perfil de um usuário, se possível. Usar o OneDrive, o SharePoint ou outras soluções são um meio eficaz de proteger dados durante um evento BCDR sem depender do roaming de dados com o usuário como parte de seu perfil. Esse processo é melhor delineado em um exercício de objetivo de tempo de recuperação (RTO) e objetivo de ponto de recuperação (RPO), onde a análise de custo-benefício e risco pode ser ponderada com base em metas organizacionais e de negócios.
Opção 1: Sem recuperação de perfil
Embora essa opção não pareça um design BCDR , ela se concentra em garantir que os dados de negócios e de missão crítica não estejam no perfil do usuário. Durante um desastre, os usuários criariam novos perfis em um novo local ou em um novo provedor de armazenamento (ambos podem ser verdadeiros). Essa opção é a mais econômica em termos de custo de infraestrutura, embora tenha uma penalidade devido ao efeito que pode ter na experiência do usuário.
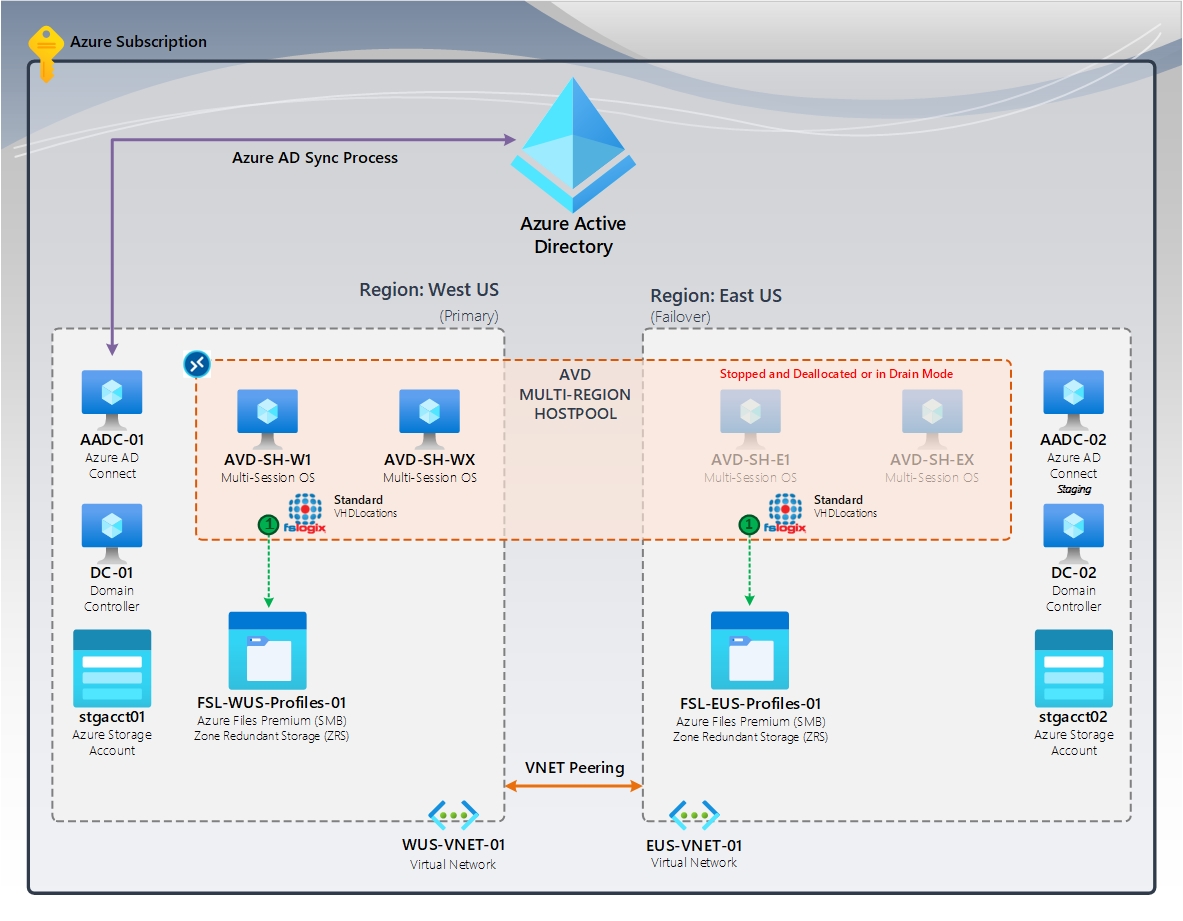
Figura 1: Sem recuperação de perfil | Contêineres padrão FSLogix (VHDLocations)
No diagrama, é um Pool de Hosts de várias regiões usando a Área de Trabalho Virtual do Azure. As regiões primária e de failover têm um compartilhamento de Arquivos do Azure dedicado usando ZRS (armazenamento com redundância de zona), que fornece alta disponibilidade na região. A região de failover tem Hosts de Sessão, que são interrompidos ou deslocalizados. Em um desastre, a região de failover se torna a região primária e os usuários entrarão nesses Hosts de Sessão e criarão novos perfis no compartilhamento de Arquivos do Azure nessa região.
Opção 2: Cloud Cache (primário / failover)
Um design de failover é uma estratégia comum para garantir a disponibilidade e a confiabilidade de sua infraestrutura em caso de desastre ou falha. O Cloud Cache permite que você use o FSLogix usando esse tipo de design de failover. Com o Cloud Cache, você pode configurar seus dispositivos para usar dois (2) provedores de armazenamento que armazenam seus dados de perfil em locais diferentes. O Cloud Cache sincroniza seus dados de perfil com cada um dos dois provedores de armazenamento de forma assíncrona, para que você sempre tenha a versão mais recente de seus dados. Alguns dos seus dispositivos estão no local principal e os outros dispositivos estão no local de failover. O Cloud Cache prioriza o primeiro provedor de armazenamento (mais próximo do seu dispositivo) e usa o outro provedor de armazenamento como backup. Por exemplo, se o dispositivo principal estiver no oeste dos EUA e o dispositivo de failover estiver no leste dos EUA, você poderá configurar o Cloud Cache da seguinte maneira:
- O dispositivo principal usa um provedor de armazenamento no oeste dos EUA como a primeira opção e um provedor de armazenamento no leste dos EUA como a segunda opção.
- O dispositivo de failover usa um provedor de armazenamento no leste dos EUA como a primeira opção e um provedor de armazenamento no oeste dos EUA como a segunda opção.
- Se o dispositivo principal ou o provedor de armazenamento mais próximo falhar, você poderá alternar para o dispositivo de failover ou para o provedor de armazenamento de backup e continuar seu trabalho sem perder os dados do perfil.
No entanto, há algumas desvantagens de usar um design de failover com o Cloud Cache. Primeiro, você tem que pagar mais para armazenar seus dados de perfil em dois (2) locais. Em segundo lugar, você precisa iniciar manualmente o processo de failover, que pode exigir a aprovação das partes interessadas do negócio. Em terceiro lugar, você pode enfrentar alguma latência ou inconsistência nos dados do perfil devido à sincronização assíncrona com os dois provedores de armazenamento.
Dica
- Antes de permitir que os usuários façam failback para perfis no local primário, certifique-se de que todos os usuários tenham saído com êxito do local de failover para garantir que o local primário tenha uma réplica atualizada dos dados de perfil do usuário.
- O Cloud Cache é um sistema intensivo de E/S e pode facilmente causar gargalos de rede e/ou armazenamento no local restaurado.
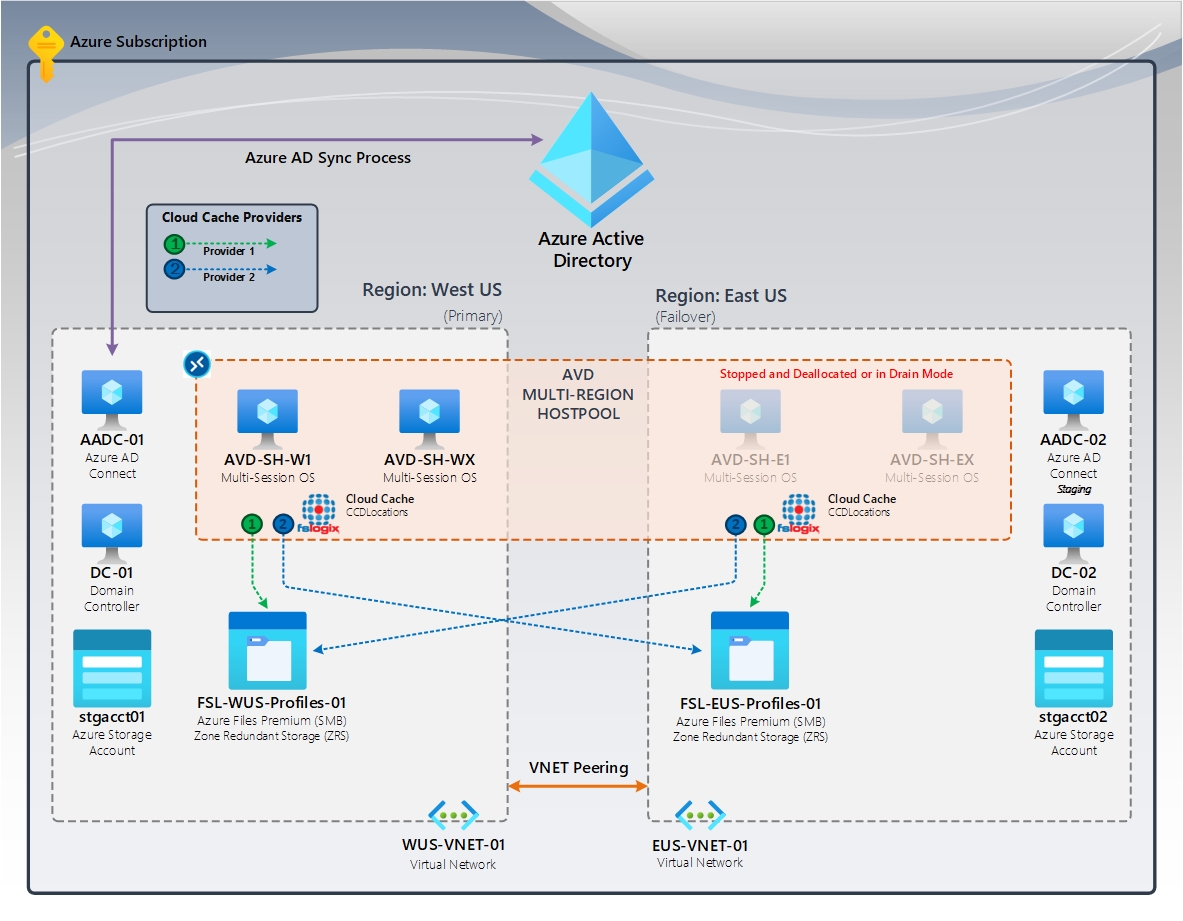
Figura 2: Cache na nuvem (principal/failover) | Cache de nuvem FSLogix (CCDLocations)
No diagrama, temos um Pool de Hosts de várias regiões utilizando a Área de Trabalho Virtual do Azure. As regiões primária e de failover fazem parte dessa configuração. Cada um deles tem um compartilhamento de Arquivos do Azure dedicado usando ZRS (armazenamento com redundância de zona), garantindo alta disponibilidade na região. A região de failover contém Hosts de Sessão, que são interrompidos ou deslocalizados. No caso de um desastre, a região de failover se torna a região principal. Os usuários entrarão nesses hosts de sessão e carregarão seu perfil replicado da região de failover.
No entanto, é essencial considerar o seguinte:
- Os eventos BCDR (Business Continuity and Disaster Recovery) raramente são normais. Dependendo das circunstâncias, os dados do perfil do usuário podem não ter garantia de estarem intactos.
- Os usuários que entrarem em hosts de sessão na região de failover podem enfrentar perda de dados ou, em casos piores, corrupção de contêiner.
Dada essa situação, é crucial usar plataformas de armazenamento como OneDrive ou SharePoint para dados críticos. Essas plataformas fornecem redundância adicional e proteção contra perda de dados. Lembre-se, planejar a recuperação de desastres é essencial, e ter a estratégia de armazenamento certa pode reduzir os riscos e garantir a continuidade dos negócios.
Opção 3: Cloud Cache (ativo / ativo)
Ao discutir infraestrutura, é comum usar designs ativos/ativos, que também podem ser aplicados a uma solução de perfil FSLogix. Com essa opção, o Cloud Cache é configurado com dois provedores de armazenamento que são atualizados de forma assíncrona para refletir todas as alterações feitas no cache local. O provedor de armazenamento mais próximo do local ativo é listado em primeiro lugar, enquanto o provedor mais distante é listado em segundo. No outro local, a ordem é invertida. Essa opção incorre em custos adicionais para armazenar dados do provedor em dois locais e requer uma decisão manual das partes interessadas do negócio antes de iniciar um failover.
Dica
- Quando a região com falha está operacional, pode levar um tempo significativo para que os dados de perfil sejam totalmente replicados.
- O Cloud Cache é um sistema intensivo de E/S e pode facilmente causar gargalos de rede e/ou armazenamento no local restaurado.
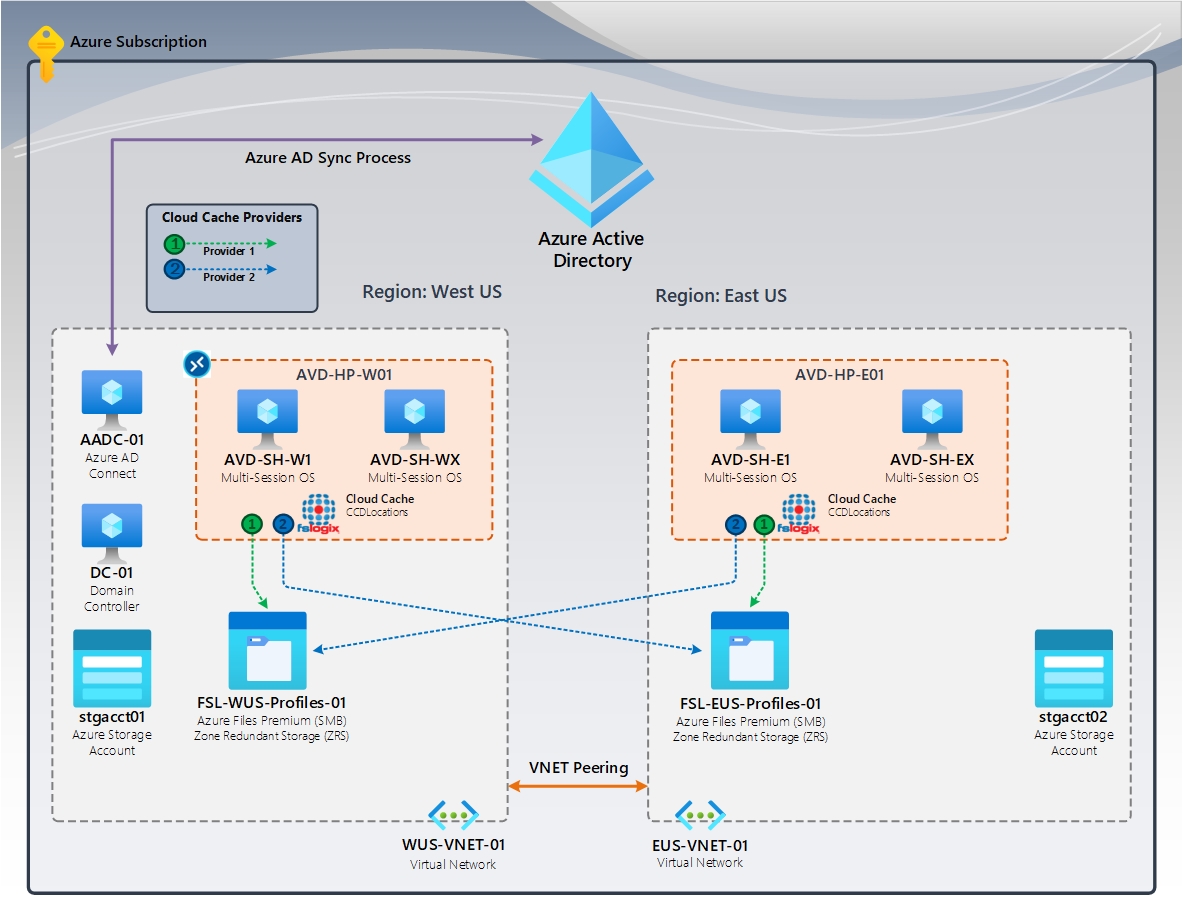
Figura 3: Cache na nuvem (ativo/ativo) | Cache de nuvem FSLogix (CCDLocations)
No diagrama, há dois (2) Pools de Host AVD e Hosts de Sessão residentes em regiões específicas do Azure. Os usuários atribuídos à região Oeste dos EUA acessam essas máquinas virtuais. Os usuários na região Leste dos EUA acessam e são atribuídos a essas máquinas virtuais. Durante um desastre, a região sobrevivente deve ter capacidade suficiente para suportar todos os usuários. Além disso, os usuários da região com falha precisam de acesso concedido às máquinas virtuais na região sobrevivente.
Os eventos BCDR nunca são normais e, dependendo das circunstâncias do evento, os dados do perfil do usuário não têm garantia de estarem intactos. Os usuários que entrarem em hosts de sessão na região sobrevivente podem sofrer perda de dados ou, na pior das hipóteses, corrupção de contêiner. Essa situação amplia a necessidade de usar plataformas de armazenamento como OneDrive ou SharePoint para dados críticos do usuário.