Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a: ✓ Todos os modelos personalizados | ✓ Todos os modelos pré-criados
No Microsoft Syntex, o processamento de documentos começa com modelos — ferramentas avançadas que o ajudam a identificar, classificar e extrair informações de documentos armazenados em bibliotecas de documentos do SharePoint. Estes modelos são a base para transformar conteúdos não estruturados em dados estruturados e utilizáveis.
Quando aplica um modelo a uma biblioteca do SharePoint, este é associado a um tipo de conteúdo que define a estrutura das informações que estão a ser extraídas. Este tipo de conteúdo, que inclui colunas para armazenar dados extraídos, é guardado na galeria de tipos de conteúdo do SharePoint. Pode criar um novo tipo de conteúdo adaptado às suas necessidades ou utilizar os existentes para reutilizar o respetivo esquema e manter a consistência na sua organização.
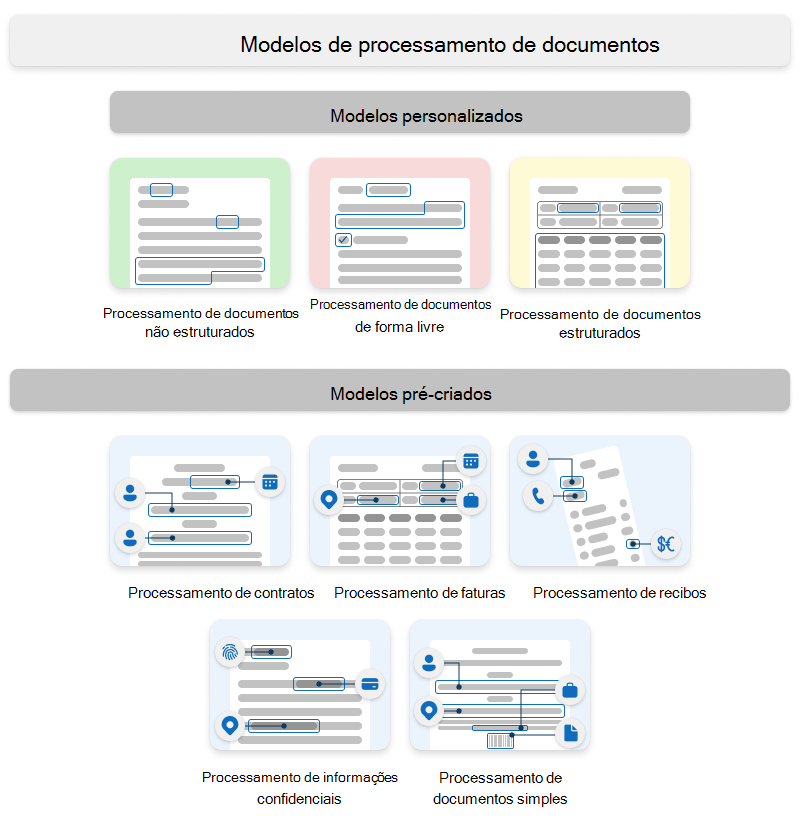
Microsoft Syntex utiliza modelos personalizados e modelos pré-criados.
Os modelos podem ser criados de duas formas, consoante as suas necessidades e onde pretende geri-los. Os modelos empresariais são criados e geridos num centro de conteúdos, tornando-os reutilizáveis em vários sites do SharePoint. Os modelos locais, por outro lado, são criados diretamente numa biblioteca de documentos do SharePoint no seu site e estão no âmbito dessa biblioteca específica. Isto dá-lhe flexibilidade para escolher o tipo de modelo certo com base no facto de precisar de controlo centralizado ou de personalização localizada.
Modelos personalizados
O tipo de modelo personalizado que escolher depende dos tipos de ficheiros com os quais trabalha, da estrutura e do formato desses ficheiros e das localizações do SharePoint onde planeia aplicar o modelo.
Os modelos personalizados incluem:
- Processamento de documentos não estruturados
- Processamento de documentos de forma livre
- Processamento de documentos estruturados
Para ver as diferenças lado a lado nos modelos personalizados, veja Comparar modelos personalizados.
Processamento de documentos não estruturados
Utilize o modelo de processamento de documentos não estruturado ao trabalhar com documentos como cartas ou contratos que não seguem um esquema consistente, mas contêm expressões ou padrões identificáveis. Este modelo classifica automaticamente documentos e extrai informações relevantes com base em padrões de texto.
Por exemplo, uma carta de renovação de contrato pode variar no formato, mas incluir consistentemente uma expressão como "Data de início do serviço de" seguida de uma data. O modelo utiliza esses padrões para determinar o tipo de documento (classificação) e os dados a extrair (extratores).
- Melhor para: Documentos não estruturados com padrões de texto reconhecíveis.
- Suporte para ficheiros: a maior variedade de tipos de ficheiros.
- Suporte de idiomas: mais de 40 idiomas.
- Configuração: utilize a opção Modelo de classe única .
Para obter mais informações, veja Descrição geral do processamento de documentos não estruturados.
Processamento de documentos de forma livre
O modelo de processamento de documentos de forma livre é ideal para extrair informações de documentos onde os dados podem aparecer em qualquer lugar, como cartas digitalizadas, faxes ou PDFs. Ao contrário dos modelos não estruturados, os modelos de forma livre não classificam o tipo de documento; concentram-se apenas na extração de dados.
Estes modelos são criados com Microsoft Power Apps AI Builder e são especialmente úteis ao processar grandes volumes de documentos recebidos de várias origens.
- Melhor para: PDFs ou ficheiros de imagem em que a classificação não é necessária.
- Suporte para ficheiros: formatos PDF e de imagem.
- Suporte de idiomas: mais de 40 idiomas.
- Configuração: utilize a opção Modelo de extração de forma livre.
- Disponibilidade: varia de acordo com a região.
Para obter mais informações, veja Descrição geral do processamento de documentos estruturados e de forma livre.
Processamento de documentos estruturados
Escolha o modelo de processamento de documentos estruturado para documentos com um esquema consistente, como formulários ou faturas. Este modelo identifica valores de campos e tabelas com base nas respetivas posições fixas no documento.
Criados com Microsoft Power Apps AI Builder, os modelos estruturados aprendem com documentos de exemplo e extraem dados de localizações semelhantes em ficheiros futuros. Por exemplo, um formulário fiscal pode sempre colocar o número da segurança social no mesmo local.
- Melhor para: documentos estruturados ou semiestruturados, como formulários.
- Suporte para ficheiros: Forms com esquemas consistentes.
- Suporte de idiomas: a maior variedade de idiomas suportados.
- Configuração: utilize a opção Modelo de extração estruturada .
Para obter mais informações, veja Descrição geral do processamento de documentos estruturados e de forma livre.
Modelos pré-construídos
Além dos modelos personalizados, o Microsoft Syntex oferece um conjunto de modelos pré-criados que fornecem capacidades prontos a utilizar para extrair informações estruturadas de documentos empresariais comuns. Estes modelos foram concebidos para poupar tempo e esforço ao eliminar a necessidade de preparação ou configuração manual.
Os modelos pré-criados incluem:
- Processamento de contratos
- Processamento de faturas
- Processamento de recibos
- Processamento de informações confidenciais
- Processamento de documentos simples
Processamento de contratos
O modelo de processamento de contratos foi concebido para analisar e extrair informações importantes de documentos contratuais. Funciona em vários formatos e identifica detalhes importantes do contrato, tais como:
- Nome do cliente ou do partido
- Endereço de faturação
- Jurisdição
- Data de expiração
Este modelo é ideal para equipas legais, de aprovisionamento ou de operações que gerem grandes volumes de contratos.
Para obter mais informações, veja Utilizar um modelo pré-criado para extrair informações de contratos.
Processamento de faturas
O modelo de processamento de faturas extrai dados essenciais das faturas de vendas, ajudando a simplificar os fluxos de trabalho a pagar das contas. Pode identificar informações como:
- Nome do cliente
- Endereço de faturação
- Data para conclusão
- Montante em dívida
Este modelo é especialmente útil para equipas financeiras que procuram automatizar a entrada de faturas e reduzir a introdução manual de dados.
Para obter mais informações, veja Utilizar um modelo pré-criado para extrair informações de faturas.
Processamento de recibos
O modelo de processamento de recibos processa recibos impressos e manuscritos, extraindo detalhes da transação de chaves, tais como:
- Nome do comerciante
- Número de telefone do comerciante
- Data da transação
- Imposto e montante total
Este modelo é adequado para relatórios de despesas e fluxos de trabalho de reembolso.
Para obter mais informações, veja Utilizar um modelo pré-criado para extrair informações de recibos.
Processamento de informações confidenciais
O modelo de processamento de informações confidenciais ajuda a identificar e extrair dados pessoais e confidenciais de documentos. Pode detetar informações como:
- Números da Segurança Social
- Números de contas financeiras
- IDs de carta de condução
- Outras informações pessoais identificáveis (PII)
Este modelo suporta os esforços de conformidade e proteção de dados em toda a sua organização.
Para obter mais informações, veja Utilizar um modelo pré-criado para detetar informações confidenciais de documentos.
Processamento de documentos simples
O modelo de processamento de documentos simples oferece uma solução flexível e pré-preparado para extrair informações como:
- Pares chave-valor
- Marcas de seleção (por exemplo, caixas de verificação)
- Entidades nomeadas
- Códigos de barras
- Deteção de idioma
Ao contrário de outros modelos pré-criados com esquemas fixos, este modelo adapta-se a uma maior variedade de documentos estruturados e é uma ótima alternativa quando a etiquetagem personalizada não é viável.
Para obter mais informações, veja Utilizar um modelo pré-criado para detetar informações confidenciais de documentos.