Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O algoritmo de amostragem no Power BI melhora os visuais que amostram dados de alta densidade. Por exemplo, pode criar um gráfico de linhas a partir dos resultados de vendas das suas lojas físicas, cada loja com mais de 10.000 receitas de vendas por ano. Um gráfico de linhas com esta informação de vendas amostra dados dos dados de cada loja e cria um gráfico de linhas multi-série que representa os dados subjacentes. Selecione uma representação significativa desses dados para ilustrar como as vendas variam ao longo do tempo. Esta prática é comum na visualização de dados de alta densidade. Os detalhes da amostragem de dados de alta densidade são descritos neste artigo.
Observação
O algoritmo de amostragem de alta densidade descrito neste artigo está disponível tanto no Power BI Desktop como no serviço Power BI.
Como funciona a amostragem de linhas de alta densidade
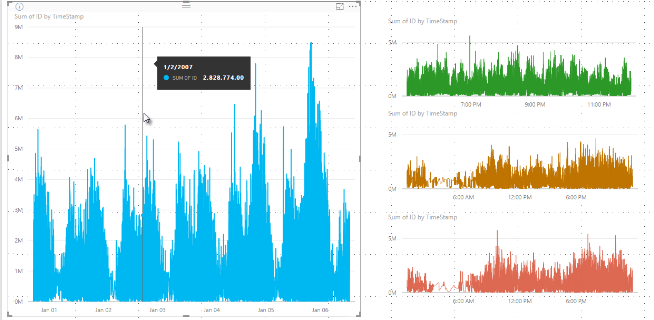
Anteriormente, o Power BI selecionava uma coleção de pontos de dados de amostra na gama completa de dados subjacentes de forma determinística. Por exemplo, com dados de alta densidade num visual que abrange um ano civil, o visual apresenta 350 pontos de dados de amostra. O algoritmo seleciona cada ponto de dados para garantir que toda a gama de dados é representada visualmente. Para ajudar a perceber como isto acontece, imagine representar o preço de uma ação ao longo de um ano e selecionar 365 pontos de dados para criar um gráfico de linhas visual. Trata-se de um ponto de dados para cada dia.
Nessa situação, existem muitos valores para o preço de uma ação em cada dia. Claro que há um máximo e um mínimo diários, mas esses valores podem ocorrer a qualquer momento do dia em que a bolsa de valores está aberta. Para amostragem de linhas de alta densidade, se a amostra de dados subjacente for recolhida às 10:30 e 12:00 de cada dia, obtém uma imagem representativa dos dados subjacentes, como o preço às 10:30 e 12:00. No entanto, o snapshot pode não captar o máximo e mínimo reais do preço da ação para esse ponto representativo nesse dia. Nessa e noutras, a amostragem é representativa dos dados subjacentes, mas nem sempre capta pontos importantes, que neste caso seriam os máximos e mínimos diários do preço das ações.
Por definição, os dados de alta densidade são amostrados para criar visualizações de forma razoavelmente rápida que respondam à interatividade. Demasiados pontos de dados num visual podem atrasá-lo e prejudicar a visibilidade das tendências. A forma como os dados são amostrados impulsiona a criação do algoritmo de amostragem para proporcionar a melhor experiência de visualização. No Power BI Desktop, o algoritmo proporciona a melhor combinação de responsividade, representação e preservação clara dos pontos importantes em cada fatia temporal.
Como funciona o algoritmo de amostragem de linhas
O algoritmo para amostragem linear de alta densidade está disponível para gráficos lineares e gráficos de área visuais com um eixo x contínuo.
Para um visual de alta densidade, o Power BI divide inteligentemente os seus dados em blocos de alta resolução e depois escolhe pontos importantes para representar cada bloco. Esse processo de fatiar dados de alta resolução é ajustado para garantir que o gráfico resultante seja visualmente indistinguível da renderização de todos os pontos de dados subjacentes, mas seja mais rápido e interativo.
Valores mínimos e máximos para visuais de linhas de alta densidade
Para qualquer visualização, aplicam-se as seguintes limitações:
- 3.500 é o número máximo de pontos de dados exibidos na maioria dos visuais, independentemente do número de pontos de dados ou séries subjacentes. Para exceções, consulte a lista seguinte. Por exemplo, se tiver 10 séries com 350 pontos de dados cada, o visual atinge o seu limite máximo total de pontos de dados. Se tiver uma série, pode ter até 3.500 pontos de dados se o algoritmo considerar que é a melhor amostragem para os dados subjacentes.
- Há um máximo de 60 séries para qualquer visual. Se tiver mais de 60 séries, divida os dados e crie múltiplos gráficos com 60 ou menos séries cada. É boa prática usar um slicer para mostrar apenas segmentos dos dados, mas apenas para certas séries. Por exemplo, se estiveres a mostrar todas as subcategorias na legenda, podes usar um slicer para filtrar pela categoria geral na mesma página de relatório.
O número máximo de limites de dados é maior para os seguintes tipos visuais, que são exceções ao limite de 3.500 pontos de dados:
- 150.000 pontos de dados no máximo para visuais de R.
- 30.000 pontos de dados para o Azure Map visuals.
- 10.000 dados para certas configurações de gráficos de dispersão (os gráficos de dispersão por padrão são 3.500).
- 3,500 para todos os outros elementos visuais que utilizem amostragem de alta densidade. Outros visuais podem mostrar uma maior quantidade de dados, mas não utilizam amostragem.
Estes parâmetros garantem que os visuais no Power BI Desktop sejam renderizados rapidamente, permaneçam responsivos à interação do utilizador e não causem sobrecarga computacional excessiva ao computador que renderiza o visual.
Avaliar pontos de dados representativos para gráficos de linha de alta densidade
Quando o número de pontos de dados subjacentes excede o máximo de pontos de dados que o visual pode representar, inicia-se um processo chamado binning . O binning divide os dados subjacentes em grupos chamados bins e depois refina iterativamente esses bins.
O algoritmo cria o maior número possível de bins para criar a maior granularidade visual. Dentro de cada bin, o algoritmo encontra o valor mínimo e máximo dos dados para garantir que valores importantes e significativos, como valores atípicos, sejam capturados e mostrados na visualização. Com base nos resultados do binning e da subsequente avaliação dos dados pelo Power BI, determina-se a resolução mínima para o eixo x do visual para garantir a máxima granularidade do visual.
Como mencionado anteriormente, a granularidade mínima para cada série é de 350 pontos, e o máximo é de 3.500 para a maioria dos visuais. As exceções estão listadas na secção anterior.
Cada contentor é representado por dois pontos de dados, que se tornam os pontos de dados representativos do contentor no visual. Os pontos de dados são o valor mais alto e baixo desse bin. Ao selecionar os valores altos e baixos, o processo de binning assegura que qualquer valor alto importante ou baixo significativo é capturado e renderizado visualmente.
Se esse processo parece uma análise intensa para garantir que o caso excecional é captado e devidamente exibido visualmente, tens razão. Essa é exatamente a razão do algoritmo e do processo de binning.
Dicas de ferramentas e amostragem de linhas de alta densidade
O processo de agrupamento captura e apresenta o valor mínimo e máximo num dado bin. Este processo pode afetar a forma como os tooltips exibem os dados ao passar o rato sobre os pontos de dados. Para explicar como e porquê este processo afeta os tooltips, vamos revisitar o nosso exemplo sobre os preços das ações.
Estás a criar um visual baseado no preço das ações e estás a comparar duas ações diferentes, ambas usando amostragem de alta densidade. Os dados subjacentes de cada série têm muitos pontos de dados. Por exemplo, regista o preço da ação a cada segundo do dia. O algoritmo de amostragem de linhas de alta densidade realiza binning para cada série independentemente das outras.
Agora, a primeira ação sobe de preço às 12:02, depois volta rapidamente a descer 10 segundos depois. Esse é um dado importante. Quando ocorre o agrupamento para esse ativo, o valor mais alto às 12:02 é um valor representativo para esse intervalo.
No entanto, para a segunda ação [financeira], 12:02 não é um máximo nem um mínimo no intervalo que inclui esse tempo. Talvez os máximos e mínimos do intervalo que inclui 12:02 ocorram três minutos depois. Nessa situação, quando o gráfico de linhas é criado e passa o rato sobre 12:02, vês um valor na tooltip para a primeira ação. Este valor existe porque o primeiro stock salta às 12:02 e o algoritmo seleciona esse valor como o ponto de dados mais alto do contentor. No entanto, não encontras qualquer valor na tooltip às 12:02 para a segunda ação. A segunda ação financeira não tinha um máximo nem um mínimo para o intervalo que inclui 12:02. Portanto, não há dados para mostrar para o segundo stock às 12:02 e, por isso, não são apresentados dados de tooltip.
Esta situação acontece frequentemente com dicas de ferramenta. Os valores altos e baixos de uma caixa específica provavelmente não coincidem perfeitamente com os valores do eixo x escalados uniformemente, por isso a dica não mostra o valor.
Ativar a amostragem linear de alta densidade
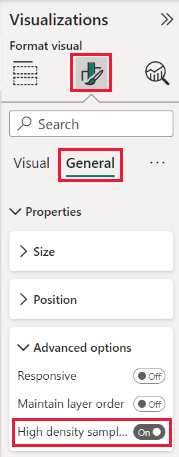
Por padrão, o algoritmo está Ligado. Para alterar esta definição, vá ao painel de Formatação, na seção Geral, e na parte inferior, vai encontrar o deslizador de amostragem de alta densidade. Selecione o controlo deslizante para ativar ou desligar.
Considerações e limitações
O algoritmo para amostragem de linhas de alta densidade é uma melhoria importante em relação ao Power BI, mas há algumas considerações que deve ter em conta ao trabalhar com valores e dados de alta densidade.
- Devido ao aumento da granularidade e ao processo de binning, as dicas de ferramenta podem mostrar apenas um valor se os dados representativos estiverem alinhados com o cursor. Para mais informações, consulte a secção Tooltips e amostragem de linhas de alta densidade neste artigo.
- Quando o tamanho total de uma fonte de dados é demasiado grande, o algoritmo elimina séries (elementos de legenda) para acomodar a restrição máxima de importação de dados.
- Nesta situação, o algoritmo ordena as séries de legendas por ordem alfabética. Começa a listar os elementos da legenda por ordem alfabética até que o máximo de importação de dados seja atingido, e deixa de importar mais séries.
- Quando um conjunto de dados subjacente tem mais de 60 séries, o número máximo de séries, o algoritmo ordena a série alfabeticamente e elimina as séries para além da 60.ª série ordenada alfabeticamente.
- Se os valores nos dados não forem numéricos ou do tipo data/hora, o Power BI não usa o algoritmo e volta ao algoritmo de amostragem anterior, que não é de alta densidade.
- Mostrar itens sem definição de dados não é suportado pelo algoritmo.
- O algoritmo não é suportado quando se utiliza uma ligação em tempo real a um modelo alojado no SQL Server Analysis Services versão 2016 ou anterior. É suportado em modelos alojados no Power BI ou Azure Analysis Services.