Orientação do modelo DirectQuery no Power BI Desktop
Este artigo destina-se a modeladores de dados que desenvolvem modelos DirectQuery do Power BI, desenvolvidos utilizando o Power BI Desktop ou o serviço do Power BI. Ele descreve casos de uso, limitações e orientações do DirectQuery. Especificamente, a orientação foi projetada para ajudá-lo a determinar se o DirectQuery é o modo apropriado para seu modelo e para melhorar o desempenho de seus relatórios com base em modelos DirectQuery. Este artigo aplica-se a modelos DirectQuery alojados no serviço Power BI ou no Servidor de Relatórios do Power BI.
Este artigo não se destina a fornecer uma discussão completa sobre o design do modelo DirectQuery. Para obter uma introdução, consulte o artigo Modelos DirectQuery no Power BI Desktop . Para obter uma discussão mais profunda, consulte diretamente o whitepaper DirectQuery no SQL Server 2016 Analysis Services . Lembre-se de que o whitepaper descreve o uso do DirectQuery no SQL Server Analysis Services. No entanto, grande parte do conteúdo ainda é aplicável aos modelos DirectQuery do Power BI.
Nota
Para obter considerações ao usar o modo de armazenamento DirectQuery para Dataverse, consulte Diretrizes de modelagem do Power BI para Power Platform.
Este artigo não aborda diretamente os modelos compostos. Um modelo composto consiste em pelo menos uma fonte DirectQuery e possivelmente mais. A orientação descrita neste artigo ainda é relevante, pelo menos em parte, para o design do modelo composto. No entanto, as implicações da combinação de tabelas de importação com tabelas DirectQuery não estão no escopo deste artigo. Para obter mais informações, consulte Usar modelos compostos no Power BI Desktop.
É importante entender que os modelos DirectQuery impõem uma carga de trabalho diferente no ambiente do Power BI (serviço do Power BI ou Servidor de Relatório do Power BI) e também nas fontes de dados subjacentes. Se você determinar que o DirectQuery é a abordagem de design apropriada, recomendamos que você envolva as pessoas certas no projeto. Costumamos ver que uma implantação bem-sucedida do modelo DirectQuery é o resultado de uma equipe de profissionais de TI trabalhando em estreita colaboração. A equipe geralmente consiste em desenvolvedores de modelos e administradores de banco de dados de origem. Também pode envolver arquitetos de dados e desenvolvedores de data warehouse e ETL. Muitas vezes, as otimizações precisam ser aplicadas diretamente à fonte de dados para alcançar bons resultados de desempenho.
Otimize o desempenho da fonte de dados
A fonte do banco de dados relacional pode ser otimizada de várias maneiras, conforme descrito na lista com marcadores a seguir.
Nota
Entendemos que nem todos os modeladores têm as permissões ou habilidades para otimizar um banco de dados relacional. Embora seja a camada preferida para preparar os dados para um modelo DirectQuery, algumas otimizações também podem ser obtidas no design do modelo, sem modificar o banco de dados de origem. No entanto, os melhores resultados de otimização geralmente são alcançados aplicando otimizações ao banco de dados de origem.
Garantir que a integridade dos dados esteja completa: é especialmente importante que as tabelas de tipo de dimensão contenham uma coluna de valores exclusivos (chave de dimensão) que mapeie para a(s) tabela(s) de tipo de fato. Também é importante que as colunas de dimensão de tipo de fato contenham valores de chave de dimensão válidos. Eles permitirão configurar relações de modelo mais eficientes que esperam valores correspondentes em ambos os lados dos relacionamentos. Quando os dados de origem não têm integridade, é recomendável que um registro de dimensão "desconhecido" seja adicionado para reparar efetivamente os dados. Por exemplo, pode adicionar uma linha à tabela Produto para representar um produto desconhecido e, em seguida, atribuir-lhe uma chave fora do intervalo, como -1. Se as linhas na tabela Sales contiverem um valor de chave de produto ausente, substitua-as por -1. Ele garante que cada valor de chave de produto de vendas tenha uma linha correspondente na tabela Produto .
Adicionar índices: defina índices apropriados — em tabelas ou exibições — para dar suporte à recuperação eficiente de dados para a filtragem visual e o agrupamento de relatórios esperados. Para fontes do SQL Server, do Banco de Dados SQL do Azure ou do Azure Synapse Analytics (anteriormente SQL Data Warehouse), consulte Guia de Design e Arquitetura de Índice do SQL Server para obter informações úteis sobre diretrizes de design de índice. Para fontes voláteis do SQL Server ou do Banco de Dados SQL do Azure, consulte Introdução ao Columnstore para análises operacionais em tempo real.
Projetar tabelas distribuídas: para fontes do Azure Synapse Analytics (anteriormente SQL Data Warehouse), que usam a arquitetura MPP (Massively Parallel Processing), considere configurar grandes tabelas de tipo de fato como hash distribuído e tabelas de tipo de dimensão para replicar em todos os nós de computação. Para obter mais informações, consulte Orientação para projetar tabelas distribuídas no Azure Synapse Analytics (anteriormente SQL Data Warehouse).
Garantir que as transformações de dados necessárias sejam materializadas: para fontes de banco de dados relacional do SQL Server (e outras fontes de banco de dados relacional), colunas computadas podem ser adicionadas a tabelas. Essas colunas são baseadas em uma expressão, como Quantidade multiplicada por PreçoUnitário. As colunas computadas podem ser persistentes (materializadas) e, como colunas regulares, às vezes podem ser indexadas. Para obter mais informações, consulte Índices em colunas computadas.
Considere também visualizações indexadas que podem pré-agregar dados da tabela de fatos em um grão mais alto. Por exemplo, se a tabela Sales armazenar dados no nível da linha do pedido, você poderá criar um modo de exibição para resumir esses dados. A exibição pode ser baseada em uma instrução SELECT que agrupa os dados da tabela Sales por data (no nível do mês), cliente, produto e resume valores de medida como vendas, quantidade, etc. O modo de exibição pode então ser indexado. Para obter fontes do SQL Server ou do Banco de Dados SQL do Azure, consulte Criar exibições indexadas.
Materializar uma tabela de data: um requisito de modelagem comum envolve a adição de uma tabela de data para dar suporte à filtragem baseada em tempo. Para dar suporte aos filtros baseados em tempo conhecidos em sua organização, crie uma tabela no banco de dados de origem e verifique se ela está carregada com um intervalo de datas que engloba as datas da tabela de fatos. Certifique-se também de que inclui colunas para períodos de tempo úteis, como ano, trimestre, mês, semana, etc.
Otimize o projeto do modelo
Um modelo DirectQuery pode ser otimizado de várias maneiras, conforme descrito na lista com marcadores a seguir.
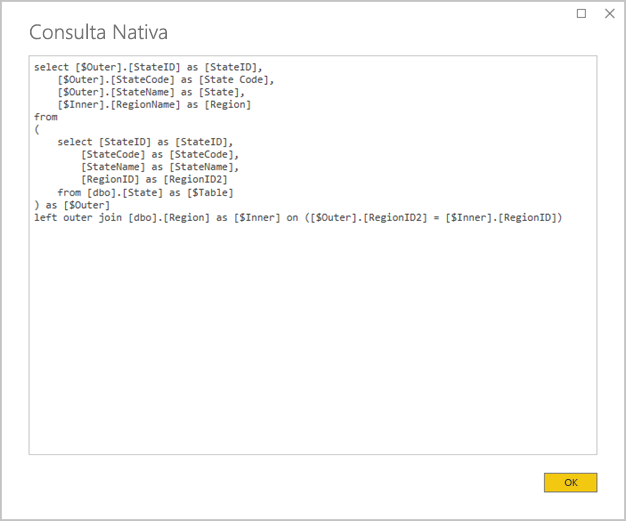
Evite consultas complexas do Power Query: é possível obter um design de modelo eficiente eliminando a necessidade de as consultas do Power Query aplicarem quaisquer transformações. Isso significa que cada consulta é mapeada para uma única tabela ou exibição de origem de banco de dados relacional. Você pode visualizar uma representação da instrução de consulta SQL real para uma etapa aplicada do Power Query, selecionando a opção Exibir Consulta Nativa .
Examine o uso de colunas calculadas e alterações de tipo de dados: os modelos DirectQuery suportam a adição de cálculos e etapas do Power Query para converter tipos de dados. No entanto, um melhor desempenho é frequentemente alcançado pela materialização dos resultados da transformação na fonte do banco de dados relacional, quando possível.
Não utilizar a filtragem de data relativa do Power Query: é possível definir a filtragem de data relativa numa consulta do Power Query. Por exemplo, para recuperar as ordens de venda que foram criadas no ano passado (em relação à data de hoje). Esse tipo de filtro se traduz em uma consulta nativa ineficiente, da seguinte maneira:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Uma melhor abordagem de design é incluir colunas de tempo relativo na tabela de datas. Essas colunas armazenam valores de deslocamento relativos à data atual. Por exemplo, em uma coluna RelativeYear , o valor zero representa o ano atual, -1 representa o ano anterior, etc. De preferência, a coluna RelativeYear é materializada na tabela de datas. Embora menos eficiente, também pode ser adicionada como uma coluna calculada por modelo, com base na expressão usando as funções TODAY e DATE DAX.
Mantenha as medidas simples: pelo menos inicialmente, recomenda-se limitar as medidas a agregados simples. As funções agregadas incluem SOMA, CONTAGEM, MIN, MAX e MÉDIA. Então, se as medidas forem suficientemente responsivas, você pode experimentar medidas mais complexas, mas prestando atenção ao desempenho de cada uma. Embora a função CALCULATE DAX possa ser usada para produzir expressões de medida sofisticadas que manipulam o contexto do filtro, elas podem gerar consultas nativas caras que não têm um bom desempenho.
Evite relações em colunas calculadas: as relações de modelo só podem relacionar uma única coluna em uma tabela a uma única coluna em uma tabela diferente. Às vezes, no entanto, é necessário relacionar tabelas usando várias colunas. Por exemplo, as tabelas Vendas e Geografia são relacionadas por duas colunas: CountryRegion e City. Para criar uma relação entre as tabelas, é necessária uma única coluna e, na tabela Geografia , a coluna deve conter valores exclusivos. A concatenação do país/região e da cidade com um separador de hífen poderia alcançar este resultado.
A coluna combinada pode ser criada com uma coluna personalizada do Power Query ou no modelo como uma coluna calculada. No entanto, isso deve ser evitado, pois a expressão de cálculo será incorporada nas consultas de origem. Não só é ineficiente, como normalmente impede a utilização de índices. Em vez disso, adicione colunas materializadas na fonte do banco de dados relacional e considere indexá-las. Você também pode considerar a adição de colunas de chave substitutas a tabelas de tipo de dimensão, que é uma prática comum em projetos de data warehouse relacional.
Há uma exceção a essa orientação e ela diz respeito ao uso da função COMBINEVALUES DAX. O objetivo desta função é suportar relações de modelo de várias colunas. Em vez de gerar uma expressão que o relacionamento usa, ele gera um predicado de junção SQL de várias colunas.
Evite relações nas colunas "Identificador Único": o Power BI não suporta nativamente o tipo de dados GUID (identificador exclusivo). Ao definir uma relação entre colunas desse tipo, o Power BI gera uma consulta de origem com uma junção envolvendo uma transmissão. Essa conversão de dados em tempo de consulta geralmente resulta em baixo desempenho. Até que esse caso seja otimizado, a única solução é materializar colunas de um tipo de dados alternativo no banco de dados subjacente.
Ocultar a coluna de um lado de relações: A coluna de um lado de um relacionamento deve estar oculta. (Geralmente é a coluna de chave primária de tabelas de tipo de dimensão.) Quando oculto, ele não está disponível no painel Campos e, portanto, não pode ser usado para configurar um visual. A coluna de muitos lados pode permanecer visível se for útil agrupar ou filtrar relatórios pelos valores da coluna. Por exemplo, considere um modelo em que existe uma relação entre as tabelas Vendas e Produtos . As colunas de relacionamento contêm valores de SKU (Unidade de Manutenção de Estoque) do produto. Se a SKU do produto precisar ser adicionada aos elementos visuais, ela deverá estar visível apenas na tabela Vendas . Quando essa coluna é usada para filtrar ou agrupar em um visual, o Power BI gera uma consulta que não precisa ingressar nas tabelas Vendas e Produto .
Definir relações para impor integridade: A propriedade Assumir Integridade Referencial das relações DirectQuery determina se o Power BI gera consultas de origem usando uma associação interna em vez de uma associação externa. Ele geralmente melhora o desempenho da consulta, embora dependa das especificidades da fonte do banco de dados relacional. Para obter mais informações, consulte Assumir configurações de integridade referencial no Power BI Desktop.
Evite o uso de filtragem de relacionamento bidirecional: o uso de filtragem de relacionamento bidirecional pode levar a instruções de consulta que não têm um bom desempenho. Use esse recurso de relacionamento apenas quando necessário, e geralmente é o caso ao implementar um relacionamento muitos-para-muitos em uma tabela de ponte. Para obter mais informações, consulte Relações com uma cardinalidade muitos-muitos no Power BI Desktop.
Limitar consultas paralelas: você pode definir o número máximo de conexões que o DirectQuery abre para cada fonte de dados subjacente. Ele controla o número de consultas enviadas simultaneamente para a fonte de dados.
- A configuração só é habilitada quando há pelo menos uma fonte do DirectQuery no modelo. O valor se aplica a todas as fontes do DirectQuery e a quaisquer novas fontes do DirectQuery adicionadas ao modelo.
- Aumentar o valor de Máximo de Conexões por Fonte de Dados garante que mais consultas (até o número máximo especificado) possam ser enviadas para a fonte de dados subjacente, o que é útil quando vários elementos visuais estão em uma única página ou muitos usuários acessam um relatório ao mesmo tempo. Quando o número máximo de conexões é atingido, outras consultas são enfileiradas até que uma conexão fique disponível. Aumentar esse limite resulta em mais carga na fonte de dados subjacente, portanto, não é garantido que a configuração melhore o desempenho geral.
- Quando o modelo é publicado no Power BI, o número máximo de consultas simultâneas enviadas para a fonte de dados subjacente também depende do ambiente. Ambientes diferentes (como Power BI, Power BI Premium ou Power BI Report Server) podem impor restrições de taxa de transferência diferentes. Para obter mais informações sobre limitações de recursos de capacidade, consulte Licenças de capacidade do Microsoft Fabric e Configurar e gerenciar capacidades no Power BI Premium.
Importante
Às vezes, este artigo se refere ao Power BI Premium ou suas assinaturas de capacidade (SKUs P). Lembre-se de que a Microsoft está atualmente consolidando opções de compra e desativando as SKUs do Power BI Premium por capacidade. Em vez disso, os clientes novos e existentes devem considerar a compra de assinaturas de capacidade de malha (SKUs F).
Para obter mais informações, consulte Atualização importante chegando ao licenciamento do Power BI Premium e Perguntas frequentes sobre o Power BI Premium.
Otimize os designs de relatórios
Os relatórios baseados em um modelo semântico do DirectQuery (anteriormente conhecido como conjunto de dados) podem ser otimizados de várias maneiras, conforme descrito na lista com marcadores a seguir.
- Habilitar técnicas de redução de consulta: Opções e Configurações do Power BI Desktop inclui uma página de Redução de Consulta. Esta página tem três opções úteis. É possível desativar o realce cruzado e a filtragem cruzada por padrão, embora possa ser substituído pela edição de interações. Também é possível mostrar um botão Aplicar em segmentações de dados e filtros. As opções de segmentação de dados ou filtro não serão aplicadas até que o usuário do relatório clique no botão. Se você habilitar essas opções, recomendamos que o faça ao criar o relatório pela primeira vez.
- Aplicar filtros primeiro: ao criar relatórios pela primeira vez, recomendamos que você aplique quaisquer filtros aplicáveis — no nível de relatório, página ou visual — antes de mapear campos para os campos visuais. Por exemplo, em vez de arrastar as medidas PaísRegião e Vendas e, em seguida, filtrar por um determinado ano, aplique primeiro o filtro no campo Ano . Isso ocorre porque cada etapa da criação de um visual enviará uma consulta e, embora seja possível fazer outra alteração antes que a primeira consulta seja concluída, ela ainda coloca uma carga desnecessária na fonte de dados subjacente. Ao aplicar filtros antecipadamente, geralmente torna essas consultas intermediárias menos dispendiosas e mais rápidas. Além disso, não aplicar filtros antecipadamente pode resultar em exceder o limite de 1 milhão de linhas, conforme descrito em sobre o DirectQuery.
- Limitar o número de elementos visuais em uma página: quando uma página de relatório é aberta (e quando os filtros de página são aplicados), todos os elementos visuais de uma página são atualizados. No entanto, há um limite no número de consultas que podem ser enviadas em paralelo, imposto pelo ambiente do Power BI e pela configuração do modelo Máximo de Conexões por Fonte de Dados , conforme descrito acima. Assim, à medida que o número de visuais de página aumenta, há maior chance de que eles sejam atualizados de forma serial. Isso aumenta o tempo necessário para atualizar a página inteira e também aumenta a chance de que os elementos visuais possam exibir resultados inconsistentes (para fontes de dados voláteis). Por esses motivos, recomenda-se limitar o número de elementos visuais em qualquer página e, em vez disso, ter páginas mais simples. A substituição de vários visuais de cartão por um único visual de cartão de várias linhas pode obter um layout de página semelhante.
- Desativar a interação entre elementos visuais: as interações de realce cruzado e filtragem cruzada exigem que as consultas sejam enviadas para a fonte subjacente. A menos que essas interações sejam necessárias, recomenda-se que sejam desativadas se o tempo necessário para responder às seleções dos usuários for excessivamente longo. Essas interações podem ser desativadas para todo o relatório (conforme descrito acima para as opções de Redução de Consulta) ou caso a caso. Para obter mais informações, consulte Como os elementos visuais filtram uns aos outros em um relatório do Power BI.
Além da lista de técnicas de otimização acima, cada um dos seguintes recursos de relatório pode contribuir para problemas de desempenho:
Filtros de medida: elementos visuais que contêm medidas (ou agregados de colunas) podem ter filtros aplicados a essas medidas. Por exemplo, o visual abaixo mostra Vendas por categoria, mas apenas para categorias com mais de US$ 15 milhões de vendas.
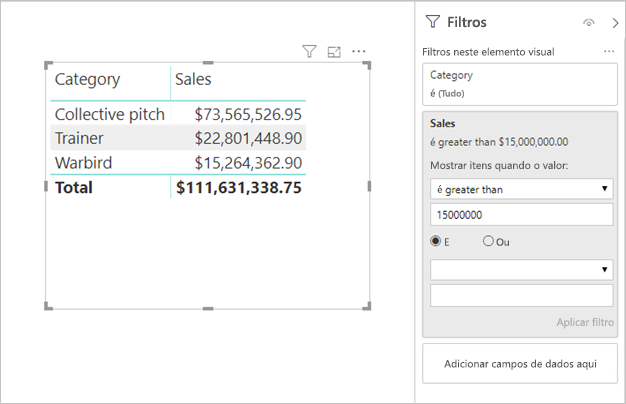
Isso pode resultar no envio de duas consultas para a fonte subjacente:
- A primeira consulta recuperará as categorias que atendem à condição (Vendas > de US$ 15 milhões)
- A segunda consulta recuperará os dados necessários para o visual, adicionando as categorias que atenderam à condição à cláusula WHERE
Geralmente funciona bem se houver centenas ou milhares de categorias, como neste exemplo. O desempenho pode diminuir, no entanto, se o número de categorias for muito maior (e, de fato, a consulta falhará se houver mais de 1 milhão de categorias atendendo à condição, devido ao limite de 1 milhão de linhas discutido acima).
Filtros TopN: Os filtros avançados podem ser definidos para filtrar apenas os valores N superiores (ou inferiores) classificados por uma medida. Por exemplo, para exibir apenas as cinco principais categorias no visual acima. Como os filtros de medida, ele também resultará no envio de duas consultas para a fonte de dados subjacente. No entanto, a primeira consulta retornará todas as categorias da fonte subjacente e, em seguida, os N superiores serão determinados com base nos resultados retornados. Dependendo da cardinalidade da coluna envolvida, isso pode levar a problemas de desempenho (ou falhas de consulta devido ao limite de 1 milhão de linhas).
Mediana: Geralmente, qualquer agregação (Soma, Contagem Distinta, etc.) é enviada para a fonte subjacente. No entanto, isso não é verdade para Median, pois esse agregado não é suportado pela fonte subjacente. Nesses casos, os dados detalhados são recuperados da fonte subjacente e o Power BI avalia a mediana dos resultados retornados. É bom quando a mediana deve ser calculada sobre um número relativamente pequeno de resultados, mas problemas de desempenho (ou falhas de consulta devido ao limite de 1 milhão de linhas) ocorrerão se a cardinalidade for grande. Por exemplo, a população mediana do país/região pode ser razoável, mas o preço médio de venda pode não ser.
Segmentações de dados de seleção múltipla: permitir a seleção múltipla em segmentações de dados e filtros pode causar problemas de desempenho. Isso ocorre porque, à medida que o usuário seleciona itens de segmentação de dados adicionais (por exemplo, criando até os 10 produtos em que está interessado), cada nova seleção resulta em uma nova consulta sendo enviada para a fonte subjacente. Embora o usuário possa selecionar o próximo item antes da conclusão da consulta, isso resulta em carga extra na fonte subjacente. Essa situação pode ser evitada mostrando o botão Aplicar, conforme descrito acima nas técnicas de redução de consulta.
Totais visuais: por padrão, tabelas e matrizes exibem totais e subtotais. Em muitos casos, consultas adicionais devem ser enviadas à fonte subjacente para obter os valores para os totais. Aplica-se sempre que usar agregados Count Distinct ou Median e, em todos os casos, ao usar DirectQuery sobre SAP HANA ou SAP Business Warehouse. Esses totais devem ser desligados (usando o painel Formato) se não forem necessários.
Converter em um modelo composto
Os benefícios dos modelos Import e DirectQuery podem ser combinados em um único modelo configurando o modo de armazenamento das tabelas de modelo. O modo de armazenamento de tabela pode ser Import ou DirectQuery, ou ambos, conhecidos como Dual. Quando um modelo contém tabelas com diferentes modos de armazenamento, é conhecido como modelo Composto. Para obter mais informações, consulte Usar modelos compostos no Power BI Desktop.
Há muitos aprimoramentos funcionais e de desempenho que podem ser alcançados convertendo um modelo DirectQuery em um modelo Composto. Um modelo composto pode integrar mais de uma fonte DirectQuery e também pode incluir agregações. As tabelas de agregação podem ser adicionadas às tabelas do DirectQuery para importar uma representação resumida da tabela. Eles podem obter melhorias de desempenho impressionantes quando os visuais consultam agregados de nível mais alto. Para obter mais informações, consulte Agregações no Power BI Desktop.
Educar os utilizadores
É importante educar seus usuários sobre como trabalhar eficientemente com relatórios baseados em modelos semânticos DirectQuery. Os autores de relatórios devem ser instruídos sobre o conteúdo descrito na seção Otimizar designs de relatórios.
Recomendamos que você eduque os consumidores de relatórios sobre os relatórios baseados em modelos semânticos do DirectQuery. Pode ser útil para eles entender a arquitetura geral de dados, incluindo quaisquer limitações relevantes descritas neste artigo. Informe-os de que as respostas de atualização e a filtragem interativa podem, por vezes, ser lentas. Quando os usuários de relatórios entendem por que a degradação do desempenho acontece, é menos provável que percam a confiança nos relatórios e dados.
Ao entregar relatórios sobre fontes de dados voláteis, certifique-se de educar os usuários de relatórios sobre o uso do botão Atualizar. Informe-os também de que pode ser possível ver resultados inconsistentes e que uma atualização do relatório pode resolver quaisquer inconsistências na página do relatório.
Conteúdos relacionados
Para obter mais informações sobre o DirectQuery, consulte os seguintes recursos:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários