TripPin parte 10 - Dobragem de consulta básica
Nota
Atualmente, esse conteúdo faz referência ao conteúdo de uma implementação herdada para logs no Visual Studio. O conteúdo será atualizado em um futuro próximo para cobrir o novo SDK do Power Query no Visual Studio Code.
Este tutorial com várias partes aborda a criação de uma nova extensão de fonte de dados para o Power Query. O tutorial deve ser feito sequencialmente — cada lição se baseia no conector criado nas lições anteriores, adicionando incrementalmente novos recursos ao seu conector.
Nesta lição, você irá:
- Aprenda as noções básicas de dobragem de consultas
- Saiba mais sobre a função Table.View
- Replicar manipuladores de dobragem de consulta OData para:
$top$skip$count$select$orderby
Um dos recursos poderosos da linguagem M é sua capacidade de enviar o trabalho de transformação para uma ou mais fontes de dados subjacentes. Esse recurso é conhecido como dobramento de consulta (outras ferramentas/tecnologias também se referem a uma função semelhante como Pushdown de predicado ou delegação de consulta).
Ao criar um conector personalizado que usa uma função M com recursos internos de dobragem de consulta, como OData.Feed ou Odbc.DataSource, seu conector herda automaticamente esse recurso gratuitamente.
Este tutorial replica o comportamento de dobramento de consulta interno para OData implementando manipuladores de função para a função Table.View . Esta parte do tutorial implementa alguns dos manipuladores mais fáceis de implementar (ou seja, aqueles que não exigem análise de expressão e rastreamento de estado).
Para entender mais sobre os recursos de consulta que um serviço OData pode oferecer, vá para Convenções de URL OData v4.
Nota
Como dito anteriormente, a função OData.Feed fornece automaticamente recursos de dobramento de consulta. Como a série TripPin está tratando o serviço OData como uma API REST regular, usando Web.Contents em vez de OData.Feed, você mesmo precisará implementar os manipuladores de dobragem de consulta. Para uso no mundo real, recomendamos que você use OData.Feed sempre que possível.
Aceda a Descrição geral da avaliação e dobragem de consultas no Power Query para obter mais informações sobre a dobragem de consultas.
Usando Table.View
A função Table.View permite que um conector personalizado substitua manipuladores de transformação padrão para sua fonte de dados. Uma implementação de Table.View fornecerá uma função para um ou mais dos manipuladores suportados. Se um manipulador não for implementado ou retornar um error durante a avaliação, o mecanismo M retornará ao seu manipulador padrão.
Quando um conector personalizado usa uma função que não suporta dobragem de consulta implícita, como Web.Contents, os manipuladores de transformação padrão são sempre executados localmente. Se a API REST à qual você está se conectando oferecer suporte a parâmetros de consulta como parte da consulta, Table.View permitirá adicionar otimizações que permitem que o trabalho de transformação seja enviado por push para o serviço.
A função Table.View tem a seguinte assinatura:
Table.View(table as nullable table, handlers as record) as table
Sua implementação encapsula sua função principal de fonte de dados. Há dois manipuladores necessários para Table.View:
GetType—retorna o esperadotable typedo resultado da consultaGetRows—retorna o resultado realtableda função de fonte de dados
A implementação mais simples seria semelhante ao seguinte exemplo:
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
Atualize a TripPinNavTable função para chamar TripPin.SuperSimpleView em vez de GetEntity:
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
Se você executar novamente os testes de unidade, verá que o comportamento da sua função não foi alterado. Nesse caso, sua implementação Table.View está simplesmente passando pela chamada para GetEntity. Como você ainda não implementou nenhum manipulador de transformação, o parâmetro original url permanece intocado.
Implementação inicial do Table.View
A implementação acima do Table.View é simples, mas não muito útil. A implementação a seguir é usada como sua linha de base — ela não implementa nenhuma funcionalidade de dobragem, mas tem o andaime necessário para fazê-lo.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Se você olhar para a chamada para Table.View, verá uma função de wrapper extra ao redor do handlers registro—Diagnostics.WrapHandlers. Essa função auxiliar é encontrada no módulo Diagnóstico (que foi introduzido na lição de adição de diagnóstico) e fornece uma maneira útil de rastrear automaticamente quaisquer erros gerados por manipuladores individuais.
As GetType funções e GetRows são atualizadas para fazer uso de duas novas funções auxiliares —CalculateSchema e CalculateUrl. No momento, as implementações dessas funções são bastante simples — observe que elas contêm partes do que foi feito anteriormente pela GetEntity função.
Finalmente, observe que você está definindo uma função interna (View) que aceita um state parâmetro.
À medida que você implementa mais manipuladores, eles chamarão recursivamente a função interna View , atualizando e transmitindo à medida state que avançam.
Atualize a TripPinNavTable função mais uma vez, substituindo a chamada para por TripPin.SuperSimpleView uma chamada para a nova TripPin.View função, e execute novamente os testes de unidade. Você ainda não verá nenhuma nova funcionalidade, mas agora tem uma linha de base sólida para testes.
Implementando dobramento de consulta
Como o mecanismo M retorna automaticamente ao processamento local quando uma consulta não pode ser dobrada, você deve executar algumas etapas adicionais para validar se seus manipuladores Table.View estão funcionando corretamente.
A maneira manual de validar o comportamento de dobragem é observar as solicitações de URL que seus testes de unidade fazem usando uma ferramenta como o Fiddler. Como alternativa, o log de diagnóstico que você adicionou emite TripPin.Feed a URL completa que está sendo executada, que deve incluir os parâmetros de cadeia de caracteres de consulta OData que seus manipuladores adicionam.
Uma maneira automatizada de validar a dobragem de consulta é forçar a execução do teste de unidade a falhar se uma consulta não for totalmente dobrada. Você pode fazer isso abrindo as propriedades do projeto e definindo Error on Folding Failure como True. Com essa configuração habilitada, qualquer consulta que exija processamento local resulta no seguinte erro:
Não podíamos dobrar a expressão para a fonte. Por favor, tente uma expressão mais simples.
Você pode testar isso adicionando um novo Fact ao seu arquivo de teste de unidade que contém uma ou mais transformações de tabela.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Nota
A configuração Erro ao dobrar falha é uma abordagem de "tudo ou nada". Se você quiser testar consultas que não foram projetadas para dobrar como parte de seus testes de unidade, será necessário adicionar alguma lógica condicional para habilitar/desabilitar testes de acordo.
As seções restantes deste tutorial adicionam um novo manipulador Table.View . Você está adotando uma abordagem TDD (Test Driven Development), na qual primeiro adiciona testes de unidade com falha e, em seguida, implementa o código M para resolvê-los.
As seções do manipulador a seguir descrevem a funcionalidade fornecida pelo manipulador, a sintaxe de consulta equivalente a OData, os testes de unidade e a implementação. Usando o código de scaffolding descrito anteriormente, cada implementação do manipulador requer duas alterações:
- Adicionar o manipulador a Table.View que atualiza o
stateregistro. - Modificando
CalculateUrlpara recuperar os valores dos parâmetros e adicionar à url e/ou cadeia de caracteres destateconsulta.
Manipulando Table.FirstN com OnTake
O OnTake manipulador recebe um count parâmetro, que é o número máximo de linhas a serem retiradas do GetRows.
Em termos OData, você pode traduzir isso para o parâmetro de consulta $top .
Use os seguintes testes de unidade:
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
Ambos os testes usam Table.FirstN para filtrar o conjunto de resultados para o primeiro número X de linhas. Se você executar esses testes com Error on Folding Failure definido como False (o padrão), os testes deverão ser bem-sucedidos, mas se você executar o Fiddler (ou verificar os logs de rastreamento), observe que a solicitação enviada não contém nenhum parâmetro de consulta OData.
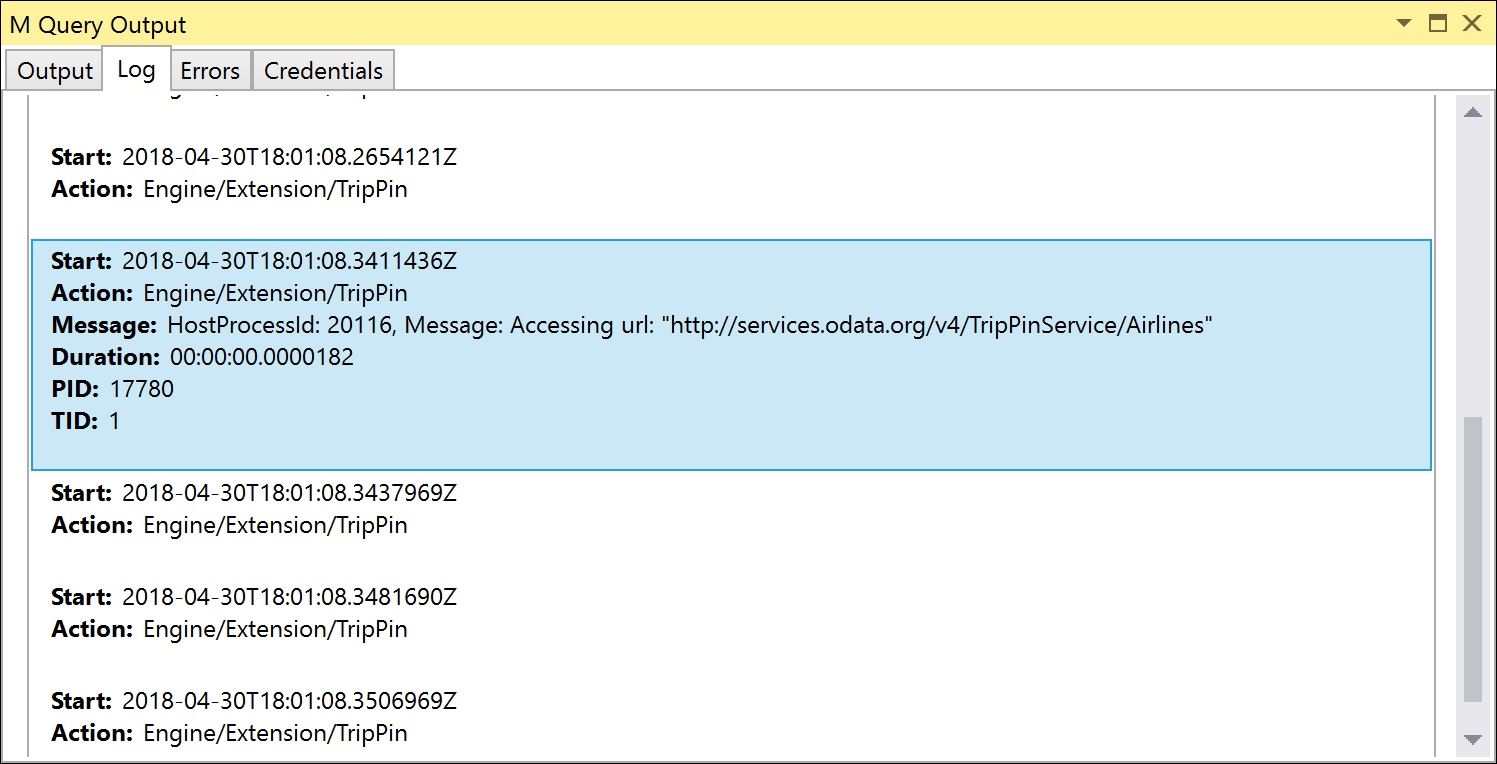
Se você definir Error on Folding Failure como True, os testes falharão com o Please try a simpler expression. erro. Para corrigir esse erro, você precisa definir seu primeiro manipulador Table.View para OnTake.
O OnTake manipulador se parece com o seguinte código:
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
A CalculateUrl função é atualizada para extrair o Topstate valor do registro e definir o parâmetro correto na cadeia de caracteres de consulta.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
Executando novamente os testes de unidade, observe que a URL que você está acessando agora contém o $top parâmetro. Devido à codificação de URL, $top aparece como %24top, mas o serviço OData é inteligente o suficiente para convertê-lo automaticamente.
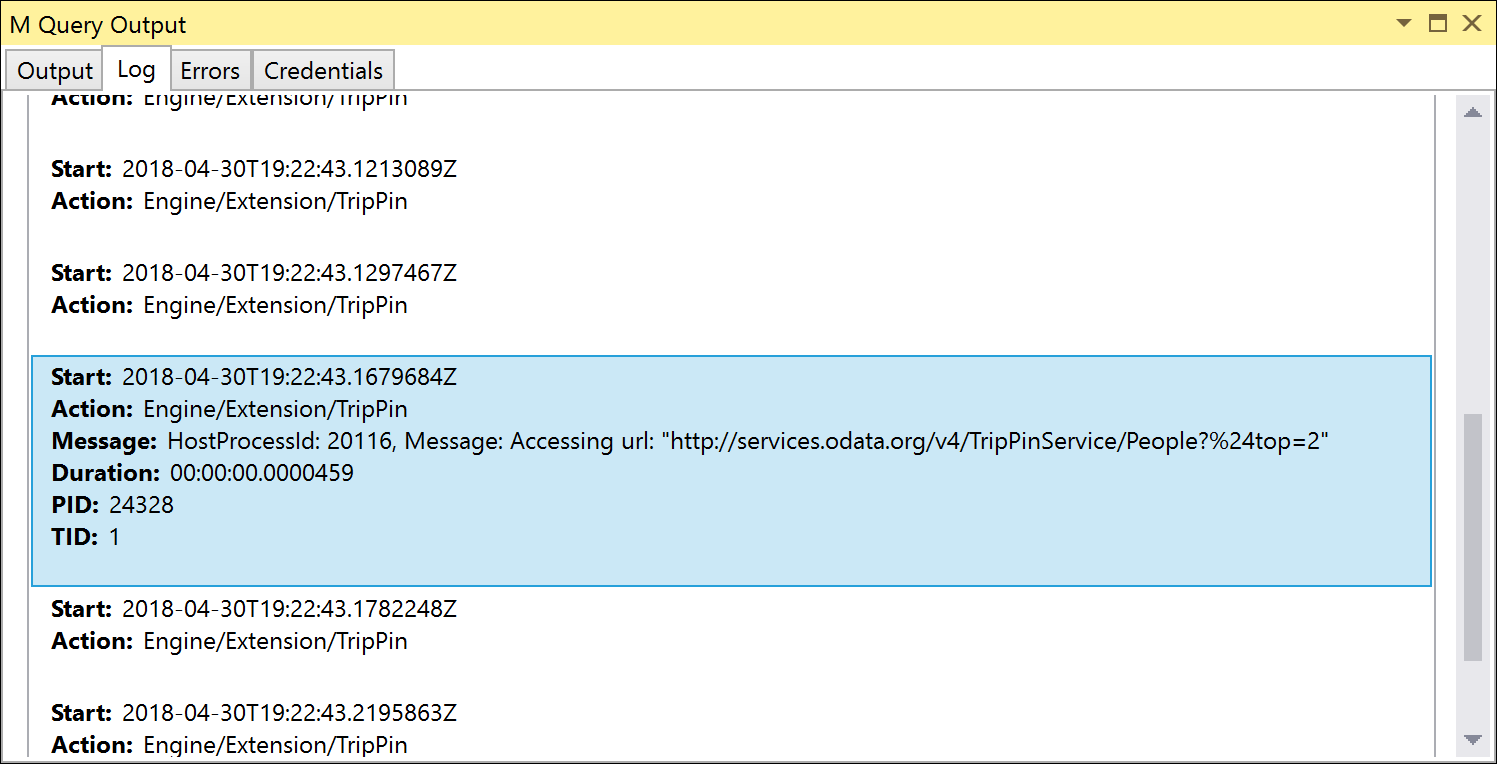
Manipulando Table.Skip com OnSkip
O OnSkip manipulador é muito parecido com OnTake. Ele recebe um count parâmetro, que é o número de linhas a serem ignoradas do conjunto de resultados. Esse manipulador se traduz bem para o parâmetro OData $skip query.
Testes unitários:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
Implementação:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
Atualizações correspondentes a CalculateUrl:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
Para obter mais informações: Table.Skip
Manipulando Table.SelectColumns com OnSelectColumns
O OnSelectColumns manipulador é chamado quando o usuário seleciona ou remove colunas do conjunto de resultados. O manipulador recebe um list dos text valores, representando uma ou mais colunas a serem selecionadas.
Em termos OData, essa operação é mapeada para a opção de consulta $select .
A vantagem de dobrar a seleção de colunas torna-se aparente quando você lida com tabelas com muitas colunas. O $select operador remove colunas não selecionadas do conjunto de resultados, resultando em consultas mais eficientes.
Testes unitários:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
Os dois primeiros testes selecionam números diferentes de colunas com Table.SelectColumns e incluem uma chamada Table.FirstN para simplificar o caso de teste.
Nota
Se o teste fosse simplesmente retornar os nomes das colunas (usando Table.ColumnNames e não quaisquer dados, a solicitação para o serviço OData nunca será realmente enviada. Isso ocorre porque a chamada para GetType retornará o esquema, que contém todas as informações que o mecanismo M precisa para calcular o resultado.
O terceiro teste usa a opção MissingField.Ignore , que diz ao mecanismo M para ignorar todas as colunas selecionadas que não existem no conjunto de resultados. O OnSelectColumns manipulador não precisa se preocupar com essa opção — o mecanismo M a manipula automaticamente (ou seja, as colunas ausentes não são incluídas na columns lista).
Nota
A outra opção para Table.SelectColumns, MissingField.UseNull, requer um conector para implementar o OnAddColumn manipulador. Isso será feito em uma aula subsequente.
A implementação para OnSelectColumns faz duas coisas:
- Adiciona a lista de colunas selecionadas ao
state. - Recalcula o
Schemavalor para que você possa definir o tipo de tabela correto.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl é atualizado para recuperar a lista de colunas do estado e combiná-las (com um separador) para o $select parâmetro.
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
Manipulando Table.Sort com OnSort
O OnSort manipulador recebe uma lista de registros do tipo:
type [ Name = text, Order = Int16.Type ]
Cada registro contém um Name campo, indicando o nome da coluna, e um Order campo igual a Order.Ascending ou Order.Descending.
Em termos OData, essa operação é mapeada para a opção de consulta $orderby .
A $orderby sintaxe tem o nome da coluna seguido de asc ou desc para indicar ordem crescente ou decrescente. Quando você classifica em várias colunas, os valores são separados por vírgula. Se o columns parâmetro contiver mais de um item, é importante manter a ordem em que eles aparecem.
Testes unitários:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
Implementação:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
Atualizações para CalculateUrl:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
Manipulando Table.RowCount com GetRowCount
Ao contrário dos outros manipuladores de consulta que você está implementando, o GetRowCount manipulador retorna um único valor — o número de linhas esperado no conjunto de resultados. Em uma consulta M, esse valor normalmente seria o resultado da transformação Table.RowCount .
Você tem algumas opções diferentes sobre como lidar com esse valor como parte de uma consulta OData:
- O parâmetro de consulta $count, que retorna a contagem como um campo separado no conjunto de resultados.
- O segmento de caminho /$count, que retorna apenas a contagem total, como um valor escalar.
A desvantagem da abordagem de parâmetro de consulta é que você ainda precisa enviar a consulta inteira para o serviço OData. Como a contagem volta em linha como parte do conjunto de resultados, você precisa processar a primeira página de dados do conjunto de resultados. Embora esse processo ainda seja mais eficiente do que ler todo o conjunto de resultados e contar as linhas, provavelmente ainda é mais trabalho do que você deseja fazer.
A vantagem da abordagem de segmento de caminho é que você recebe apenas um único valor escalar no resultado. Esta abordagem torna toda a operação muito mais eficiente. No entanto, conforme descrito na especificação OData, o segmento de caminho /$count retornará um erro se você incluir outros parâmetros de consulta, como $top ou $skip, o que limita sua utilidade.
Neste tutorial, você implementou o GetRowCount manipulador usando a abordagem de segmento de caminho. Para evitar os erros que você obteria se outros parâmetros de consulta fossem incluídos, você verificou outros valores de estado e retornou um "erro não implementado" (...) se encontrou algum. O retorno de qualquer erro de um manipulador Table.View informa ao mecanismo M que a operação não pode ser dobrada e deve voltar para o manipulador padrão (que, neste caso, estaria contando o número total de linhas).
Primeiro, adicione um teste de unidade:
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
Como o segmento de /$count caminho retorna um único valor (em formato simples/texto) em vez de um conjunto de resultados JSON, você também precisa adicionar uma nova função interna (TripPin.Scalar) para fazer a solicitação e manipular o resultado.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
A implementação, em seguida, usa esta função (se nenhum outro parâmetro de consulta for encontrado no state):
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
A CalculateUrl função é atualizada para anexar /$count ao URL se o RowCountOnly campo estiver definido no state.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
O novo Table.RowCount teste de unidade deve agora ser aprovado.
Para testar o caso de fallback, adicione outro teste que força o erro.
Primeiro, adicione um método auxiliar que verifique o resultado de uma try operação em busca de um erro de dobragem.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
Em seguida, adicione um teste que usa Table.RowCount e Table.FirstN para forçar o erro.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
Uma observação importante aqui é que esse teste agora retorna um erro se Error on Folding Error estiver definido como false, porque a Table.RowCount operação retorna ao manipulador local (padrão). Executar os testes com Error on Folding Error definido como true causa Table.RowCount falha e permite que o teste seja bem-sucedido.
Conclusão
A implementação do Table.View para seu conector adiciona uma quantidade significativa de complexidade ao seu código. Como o mecanismo M pode processar todas as transformações localmente, adicionar manipuladores Table.View não permite novos cenários para seus usuários, mas resulta em um processamento mais eficiente (e, potencialmente, usuários mais felizes). Uma das principais vantagens dos manipuladores Table.View serem opcionais é que ele permite que você adicione novas funcionalidades de forma incremental sem afetar a compatibilidade com versões anteriores do seu conector.
Para a maioria dos conectores, um manipulador importante (e básico) a ser implementado é OnTake (que se traduz em $top OData), pois limita o número de linhas retornadas. A experiência do Power Query sempre executa uma OnTake das linhas ao exibir visualizações no navegador e no editor de 1000 consultas, para que seus usuários possam ver melhorias significativas de desempenho ao trabalhar com conjuntos de dados maiores.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários