Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Uma expressão regular, normalmente conhecida como regex, é uma sequência de carateres que define um padrão de pesquisa. As expressões regulares são utilizadas principalmente para a correspondência de padrões com cadeias e na correspondência de cadeias; por exemplo, nas operações "localizar e substituir". Pode utilizar um regex no Prevenção Contra Perda de Dados do Microsoft Purview (DLP) para definir padrões que o ajudam a identificar e classificar dados confidenciais ou para ajudar a detetar padrões no conteúdo. As utilizações regex mais comuns no DLP do Microsoft Purview são:
- Definir tipos de informações confidenciais personalizados.
- Tirar partido da
SubjectOrBodyMatchesPatternscondição numa regra DLP (Leia mais aqui.)
Este artigo descreve problemas comuns que ocorrem ao trabalhar com expressões regulares e como pode resolve-las.
Potencial problema de validação ao utilizar um regex com DLP
- As unidades básicas do padrão, como carateres literais, dígitos, espaço em branco e sinais de pontuação podem ser representadas por si próprios ou por símbolos especiais chamados metacaractadores, como
\dpara qualquer dígito,\spara qualquer espaço em branco ou\.para um ponto literal. - As unidades básicas, quando combinadas com quantificadores, especificam o número de vezes que podem ou têm de ocorrer numa correspondência. Por exemplo,
*significa zero ou mais,+significa um ou mais,?significa zero ou um, e{n,m}significa entrenemhoras. Por exemplo,\d+significa um ou mais dígitos,\s?significa espaço em branco opcional ea{3,5}significa entre três a cinco instâncias do caráter literal a. - Um regex utiliza um aspeto positivo ou um aspeto negativo. Um lookbehind é utilizado para marcar se existe uma correspondência antes de uma determinada posição na cadeia de entrada, sem incluir os carateres reais na correspondência. Um aspeto positivo é utilizado para corresponder quando o padrão lookbehind está presente, enquanto um lookbehind negativo é usado para corresponder quando o padrão lookbehind não está presente.
- Considere este exemplo:
(?<=^|\s|_). Este exemplo mostra um lookbehind que inclui três possibilidades:-
^afirma a posição. Neste caso, requer que a correspondência de padrões comece no início da linha. -
\sdeteta quaisquer carateres de espaço em branco como uma correspondência. -
_corresponde ao caráter de sublinhado literal ( _ ).
-
- No exemplo anterior, as possibilidades n.º 2 e 3 corresponderão a um único caráter. No entanto, a possibilidade n.º 1 indica apenas onde deve começar a correspondência. Não produzirá resultados relativamente a quaisquer correspondências de carateres.
- Veja um segundo exemplo,
^\d+$. Este regex só detetará uma cadeia composta inteiramente por dígitos, do início ao fim. - As validações do padrão Regex em condições não são sensíveis a maiúsculas e minúsculas por predefinição. Para respeitar a sensibilidade às maiúsculas e minúsculas, adicione (?-i) ao padrão
Como obter texto extraído
Um regex é correspondido no texto extraído do conteúdo, em vez de no próprio conteúdo. Assim, mesmo quando o padrão parece estar no conteúdo, pode não corresponder ao avaliar uma política DLP.
Para garantir que captura as correspondências adequadas, siga os seguintes passos:
- Utilize o cmdlet Test-TextExtraction para obter o texto extraído, que será composto por um fluxo de cadeias.
- Em seguida, utilize o texto extraído para corresponder à expressão regular.
Por exemplo:
$data = ([System.IO.File]::ReadAllBytes('<FilePath>'))
$tr = Test-TextExtraction -FileData $data
$tr.ExtractedResults.ExtractedStreamText | Format-List
Como verificar a deteção de tipos de informações confidenciais
Para verificar a deteção do tipo de informação confidencial (SIT), precisamos de pegar no texto que acabámos de extrair e, em seguida, executar o cmdlet Test-DataClassification no mesmo para verificar a deteção. Os resultados da execução do cmdlet indicarão se existem correspondências SIT para o regex.
Por exemplo:
$textStream = $tr.ExtractedResults.ExtractedStreamText | Out-String
$result = Test-DataClassification -TextToClassify $textStream
$result.ClassificationResults | Format-List
Exemplo de utilização de um regex numa regra de política DLP
Neste exemplo, vamos bloquear o e-mail que contém cadeias de carateres a partir do ABC seguido de um número.
Regex utilizado:^ABC\d
Exemplo de regra DLP:New-DlpComplianceRule -Name "Rule_00" -Policy "Policy_00" -SubjectOrBodyMatchesPatterns "^ABC\d" - BlockAccess $True
E-mail de exemplo
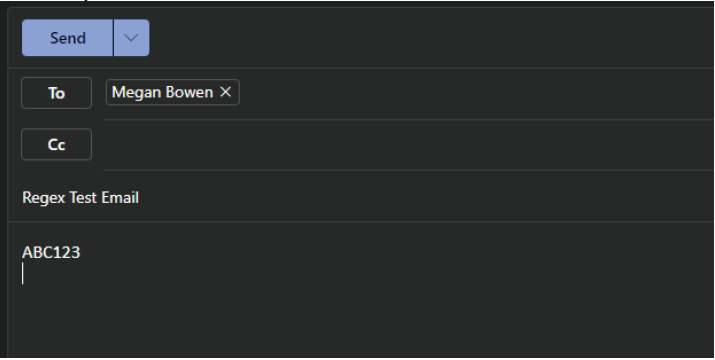
Embora pareça que o regex irá detetar uma correspondência com este item de correio, o texto extraído tem o seguinte aspeto:
Regex Test Email ABC123
Como pode ver, o texto extraído começa com o conteúdo na linha de assunto do e-mail, em vez de com o conteúdo no corpo do e-mail. No entanto, a inclusão do caráter de asserção, ^, no início do regex requer que a cadeia ABC... tenha de estar no início do texto extraído para que seja detetada uma correspondência.
Para resolve este problema, pode alterar o regex para ABC\d.