Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Por Andrew Marshall, Jugal Parikh, Emre Kiciman e Ram Shankar Siva Kumar
Agradecimentos especiais a Raul Rojas e ao AETHER Security Engineering Workstream
Novembro de 2019
Este documento é um resultado do AETHER Engineering Practices for AI Working Group e complementa as práticas de modelagem de ameaças SDL existentes, fornecendo novas orientações sobre enumeração e mitigação de ameaças específicas para o espaço de IA e Machine Learning. Destina-se a ser usado como referência durante as revisões do projeto de segurança relativos ao seguinte:
Produtos/serviços que interagem ou dependem de serviços baseados em IA/ML
Produtos/serviços sendo construídos com IA/ML em seu núcleo
A mitigação tradicional de ameaças à segurança é mais importante do que nunca. Os requisitos estabelecidos pelo Security Development Lifecycle são essenciais para estabelecer uma base de segurança do produto na qual esta orientação se baseia. A falha em lidar com as ameaças de segurança tradicionais ajuda a habilitar os ataques específicos de IA/ML cobertos neste documento nos domínios de software e físico, além de tornar o comprometimento trivial na pilha de software. Para obter uma introdução às novas ameaças de segurança neste espaço, consulte Protegendo o futuro da IA e do ML na Microsoft.
As habilidades dos engenheiros de segurança e cientistas de dados normalmente não se sobrepõem. Esta orientação fornece uma maneira para ambas as disciplinas terem conversas estruturadas sobre essas novas ameaças/mitigações sem exigir que os engenheiros de segurança se tornem cientistas de dados ou vice-versa.
Este documento está dividido em duas secções:
- "Key New Considerations in Threat Modeling" foca-se em novas formas de pensar e novas perguntas a fazer ao modelar sistemas de IA/ML de ameaças. Tanto os cientistas de dados quanto os engenheiros de segurança devem revisar isso, pois será seu manual para discussões de modelagem de ameaças e priorização de mitigação.
- "Ameaças específicas de IA/ML e suas mitigações" fornece detalhes sobre ataques específicos, bem como etapas de mitigação específicas em uso atualmente para proteger os produtos e serviços da Microsoft contra essas ameaças. Esta seção destina-se principalmente a cientistas de dados que podem precisar implementar mitigações de ameaças específicas como resultado do processo de modelagem de ameaças/revisão de segurança.
Esta orientação é organizada em torno de uma Taxonomia Adversarial de Ameaças de Machine Learning criada por Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover intitulada "Failure Modes in Machine Learning". Para obter orientações de gerenciamento de incidentes sobre a triagem de ameaças à segurança detalhadas neste documento, consulte a Barra de bugs SDL para ameaças de IA/ML. Todos estes são documentos vivos que evoluirão ao longo do tempo com o cenário de ameaças.
Principais novas considerações na modelagem de ameaças: alterando a maneira como você vê os limites de confiança
Suponha o comprometimento/envenenamento dos dados com os quais se treina, bem como do fornecedor de dados. Aprenda a detetar entradas de dados anômalas e maliciosas, bem como ser capaz de distinguir e recuperar delas
Resumo
Os armazenamentos de dados de treinamento e os sistemas que os hospedam fazem parte do escopo da modelagem de ameaças. A maior ameaça à segurança no aprendizado de máquina hoje é o envenenamento de dados devido à falta de deteções e mitigações padrão nesse espaço, combinada com a dependência de conjuntos de dados públicos não confiáveis/não curados como fontes de dados de treinamento. Rastrear a procedência e linhagem de seus dados é essencial para garantir sua confiabilidade e evitar um ciclo de treinamento "lixo dentro, lixo fora".
Perguntas a fazer numa revisão de segurança
Se seus dados forem envenenados ou adulterados, como você saberia?
-Que telemetria tem para detetar uma distorção na qualidade dos seus dados de treino?
Você está treinando a partir de insumos fornecidos pelo usuário?
-Que tipo de validação/higienização de entrada você está fazendo nesse conteúdo?
-A estrutura destes dados está documentada semelhante às Folhas de Dados para Conjuntos de Dados?
Se você treina contra armazenamentos de dados online, quais medidas você toma para garantir a segurança da conexão entre seu modelo e os dados?
- Têm forma de comunicar as violações aos consumidores dos seus feeds?
- Eles são mesmo capazes disso?
Qual é a sensibilidade dos dados a partir dos quais treina?
-Você cataloga ou controla a adição/atualização/exclusão de entradas de dados?
O seu modelo pode produzir dados confidenciais?
-Estes dados foram obtidos com autorização da fonte?
O modelo produz apenas os resultados necessários para atingir o seu objetivo?
O seu modelo devolve pontuações de confiança brutas ou qualquer outra saída direta que possa ser registada e duplicada?
Qual é o impacto de seus dados de treinamento serem recuperados atacando/invertendo seu modelo?
Se os níveis de confiança da saída do seu modelo caírem repentinamente, você pode descobrir como/por quê, bem como os dados que causaram isso?
Já definiu uma entrada bem formada para o seu modelo? O que você está fazendo para garantir que as entradas atendam a esse formato e o que você faz se elas não o fizerem?
Se suas saídas estiverem erradas, mas não causarem erros a serem relatados, como você saberia?
Sabe se os seus algoritmos de treino são resilientes a inputs adversários a nível matemático?
Como você se recupera da contaminação adversária de seus dados de treinamento?
- É possível isolar/colocar em quarentena conteúdo adversário e treinar novamente os modelos afetados?
-É possível reverter/recuperar para um modelo de uma versão prévia para re-treinamento?
Você está usando o Reinforcement Learning em conteúdo público sem curadoria?
Comece a pensar sobre a linhagem de seus dados – se você encontrar um problema, você poderia rastreá-lo até sua introdução no conjunto de dados? Em caso negativo, isso constitui um problema?
Saiba de onde vêm seus dados de treinamento e identifique normas estatísticas para começar a entender como são as anomalias
-Que elementos dos seus dados de formação são vulneráveis a influências externas?
-Quem pode contribuir para os conjuntos de dados a partir dos quais está a treinar?
- Como você atacaria suas fontes de dados de treinamento para prejudicar um concorrente?
Ameaças e mitigações relacionadas neste documento
Perturbação adversarial (todas as variantes)
Envenenamento de dados (todas as variantes)
Exemplo de ataques
Forçar e-mails benignos a serem classificados como spam ou fazer com que um exemplo malicioso não seja detetado
Entradas criadas pelo atacante que reduzem o nível de confiança da classificação correta, especialmente em cenários de alta consequência
Um invasor injeta ruído aleatoriamente nos dados de origem a ser classificados para reduzir a probabilidade de a classificação correta ser usada no futuro, tornando o modelo menos eficaz.
Contaminação de dados de treinamento para forçar a classificação incorreta de pontos de dados selecionados, resultando em ações específicas sendo tomadas ou omitidas por um sistema
Identificar ações que o(s) seu(s) modelo(s) ou produto/serviço podem tomar e que podem causar danos ao cliente on-line ou no domínio físico
Resumo
Se não forem mitigados, os ataques a sistemas de IA/ML podem chegar ao mundo físico. Qualquer cenário que possa ser distorcido para prejudicar psicologicamente ou fisicamente os usuários é um risco catastrófico para o seu produto/serviço. Isso se estende a quaisquer dados confidenciais sobre os seus clientes usados para treinamento e opções de design que possam vazar essas informações privadas.
Perguntas a fazer numa revisão de segurança
Treina com exemplos adversários? Que impacto têm na saída do seu modelo no domínio físico?
Como se manifesta a trollagem no seu produto/serviço? Como você pode detetar e responder a isso?
O que seria necessário para que seu modelo retornasse um resultado que engana seu serviço para negar acesso a usuários legítimos?
Qual é o impacto de o seu modelo ser copiado/roubado?
Seu modelo pode ser usado para inferir a pertença de uma pessoa individual em um grupo específico, ou simplesmente nos dados de treinamento?
Um invasor pode causar danos reputacionais ou uma reação negativa de relações públicas ao seu produto, forçando-o a realizar ações específicas?
Como você lida com dados formatados corretamente, mas abertamente tendenciosos, como de trolls?
Para cada maneira de interagir com ou consultar o seu modelo que é exposta, esse método pode ser analisado para divulgar dados de treino ou funcionalidades do modelo?
Ameaças e mitigações relacionadas neste documento
Inferência de associação
Inversão do modelo
Roubo de modelos
Exemplo de ataques
Reconstrução e extração de dados de treinamento consultando repetidamente o modelo para obter resultados de confiança máxima
Duplicação do modelo próprio através de correspondência exaustiva de consulta/resposta
Consultar o modelo de uma forma que revele um elemento específico de dados privados foi incluído no conjunto de treinamento
Carro autônomo sendo enganado para ignorar sinais de parada / semáforos
Bots de conversação manipulados para trollar usuários benignos
Identifique todas as fontes de dependências de IA/ML, bem como camadas de apresentação frontend em sua cadeia de suprimentos de dados/modelo
Resumo
Muitos ataques em IA e Machine Learning começam com acesso legítimo a APIs que são exibidas para fornecer acesso de consulta a um modelo. Devido às abundantes fontes de dados e experiências de utilizador diversificadas envolvidas, o acesso de terceiros autenticado mas "inadequado" (há uma área cinzenta aqui) aos seus modelos representa um risco devido à capacidade de atuar como camada de interface sobre um serviço fornecido pela Microsoft.
Perguntas a fazer numa revisão de segurança
Quais clientes/parceiros são autenticados para acessar suas APIs de modelo ou serviço?
-Eles podem atuar como uma camada de apresentação em cima do seu serviço?
-Você pode revogar o acesso deles prontamente em caso de comprometimento?
-Qual é a sua estratégia de recuperação em caso de uso mal-intencionado do seu serviço ou dependências?
Um terceiro pode construir uma fachada em torno do seu modelo para reutilizá-lo e causar danos à Microsoft ou aos seus clientes?
Os clientes fornecem dados de treinamento diretamente para você?
-Como você protege esses dados?
- E se for malicioso e o seu serviço for o alvo?
Como é um falso-positivo aqui? Qual é o impacto de um falso-negativo?
Você pode rastrear e medir o desvio das taxas de True Positive vs False Positive em vários modelos?
Que tipo de telemetria você precisa para provar a confiabilidade da saída do seu modelo para seus clientes?
Identifique todas as dependências de terceiros na sua cadeia de abastecimento de dados de treino de ML – não só software de código aberto, mas também provedores de dados.
-Porque é que os está a utilizar e como verifica a sua fiabilidade?
Você está a utilizar modelos pré-construídos de terceiros ou a enviar dados de treino para provedores de MLaaS de terceiros?
Inventariar notícias sobre ataques a produtos/serviços semelhantes. Entendendo que muitas ameaças de IA/ML são transferidas entre tipos de modelo, que impacto esses ataques teriam em seus próprios produtos?
Ameaças e mitigações relacionadas neste documento
Reprogramação de Redes Neurais
Exemplos de adversários no domínio físico
Provedores de Aprendizagem de Máquina maliciosos recuperando dados de treinamento
Atacando a cadeia de suprimentos de ML
Modelo Backdoored
Dependências específicas de ML comprometidas
Exemplo de ataques
O provedor de MLaaS mal-intencionado trojaniza seu modelo com um bypass específico
O cliente adversário encontra uma vulnerabilidade numa dependência OSS comum que utiliza e carrega um payload de dados de treino fabricado para comprometer o seu serviço.
Um parceiro sem escrúpulos usa APIs de reconhecimento facial e cria uma camada de apresentação sobre o seu serviço para produzir Deep Fakes.
Ameaças específicas de IA/ML e suas mitigações
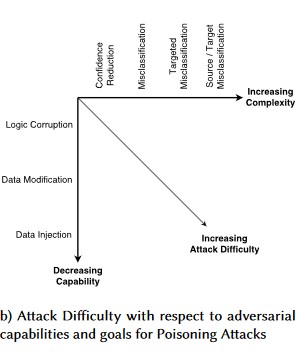
#1: Perturbação Adversária
Descrição
Em ataques do estilo de perturbação, o atacante modifica discretamente a consulta para obter uma resposta desejada de um modelo em produção[1]. Esta é uma violação da integridade de entrada do modelo que leva a ataques no estilo difuso, onde o resultado final não é necessariamente uma violação de acesso ou EOP, mas compromete o desempenho de classificação do modelo. Isso também pode ser manifestado por trolls usando certas palavras-alvo de uma forma que a IA irá bani-los, efetivamente negando serviço a usuários legítimos com um nome correspondente a uma palavra "banida".
 [24]
[24]
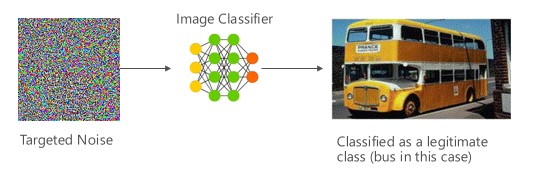
Variante #1a: Classificação incorreta direcionada
Nesse caso, os invasores geram uma amostra que não está na classe de entrada do classificador de destino, mas é classificada pelo modelo como essa classe de entrada específica. A amostra adversarial pode parecer um ruído aleatório para os olhos humanos, mas os atacantes têm algum conhecimento do sistema de aprendizado de máquina de destino para gerar um ruído branco que não é aleatório, mas está explorando alguns aspetos específicos do modelo de destino. O adversário fornece uma amostra de entrada que não é uma amostra legítima, mas o sistema de destino a classifica como uma classe legítima.
Exemplos
 [6]
[6]
Atenuações
Reforçando a Robustez Adversarial usando a Confiança do Modelo Induzida pelo Treinamento Adversarial [19]: Os autores propõem o Highly Confident Near Neighbor (HCNN), uma estrutura que combina informações de confiança e busca de vizinhos mais próximos, para reforçar a robustez adversarial de um modelo base. Isso pode ajudar a distinguir entre previsões de modelo certo e errado em uma vizinhança de um ponto amostrado da distribuição de treinamento subjacente.
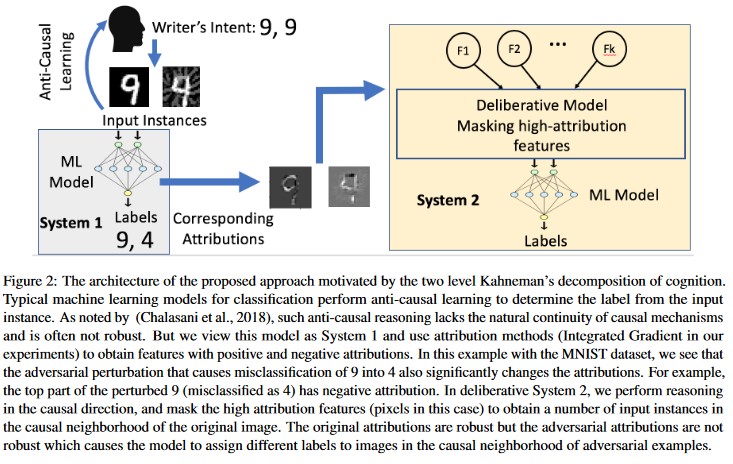
Análise Causal Orientada por Atribuição [20]: Os autores estudam a conexão entre a resiliência a perturbações adversárias e a explicação baseada em atribuição de decisões individuais geradas por modelos de aprendizado de máquina. Eles relatam que as entradas adversárias não são robustas no espaço de atribuição, ou seja, mascarar alguns recursos com alta atribuição leva à mudança de indecisão do modelo de aprendizado de máquina sobre os exemplos adversários. Em contraste, os insumos naturais são robustos no espaço de atribuição.
 [20]
[20]
Essas abordagens podem tornar os modelos de aprendizado de máquina mais resilientes a ataques adversários, porque enganar esse sistema de cognição de duas camadas requer não apenas atacar o modelo original, mas também garantir que a atribuição gerada para o exemplo adversário seja semelhante aos exemplos originais. Ambos os sistemas devem ser comprometidos simultaneamente para um ataque adversário bem-sucedido.
Paralelos Tradicionais
Elevação remota de privilégio, uma vez que o invasor agora está no controle do seu modelo
Severidade
Crítico
Variante #1b: Classificação incorreta de origem/destino
Isto é caracterizado como uma tentativa de um invasor de fazer com que um modelo retorne o rótulo que desejam para uma determinada entrada. Isso geralmente força um modelo a retornar um falso positivo ou falso negativo. O resultado final é uma apropriação sutil da precisão de classificação do modelo, onde um atacante pode provocar desvios específicos à vontade.
Embora este ataque tenha um impacto prejudicial significativo para a precisão da classificação, também pode ser mais demorado para ser realizado, dado que um adversário deve não apenas manipular os dados de origem para que eles não sejam mais rotulados corretamente, mas também rotulados especificamente com o rótulo fraudulento desejado. Estes ataques envolvem frequentemente várias etapas/tentativas para forçar uma classificação incorreta [3]. Se o modelo for suscetível a ataques de aprendizagem por transferência que forçam a classificação incorreta direcionada, pode não haver pegada de tráfego percetível do invasor, pois os ataques de sondagem podem ser realizados offline.
Exemplos
Forçar e-mails benignos a serem classificados como spam ou fazer com que um exemplo malicioso passe despercebido. Estes também são conhecidos como evasão de modelos ou ataques miméticos.
Atenuações
Ações de deteção reativa/defensiva
- Implemente um limite de tempo mínimo entre as chamadas para a API fornecendo resultados de classificação. Isso retarda o teste de ataque em várias etapas, aumentando a quantidade total de tempo necessária para encontrar uma perturbação de sucesso.
Ações Proativas/Protetoras
Feature Denoising for Improving Adversarial Robustness [22]: Os autores desenvolvem uma nova arquitetura de rede que aumenta a robustez adversarial através da realização de denoising. Especificamente, as redes contêm blocos que eliminam o ruído dos recursos usando meios não locais ou outros filtros; Todas as redes são treinadas de ponta a ponta. Quando combinado com o treino adversarial, as redes de remoção de ruído das características melhoram substancialmente a robustez adversarial de última geração em cenários de ataque de caixa branca e caixa preta.
Treino Adversarial e Regularização: Treine com amostras adversárias conhecidas para fortalecer a resiliência e robustez contra entradas maliciosas. Isso também pode ser visto como uma forma de regularização, que penaliza a norma de gradientes de entrada e torna a função de previsão do classificador mais suave (aumentando a margem de entrada). Isso inclui classificações corretas com taxas de confiança mais baixas.
Invista no desenvolvimento de classificação monotônica com seleção de características monotônicas. Isso garante que o adversário não será capaz de escapar do classificador simplesmente preenchendo características da classe negativa [13].
A compressão de recursos [18] pode ser usada para fortalecer modelos DNN detetando exemplos adversários. Ele reduz o espaço de pesquisa disponível para um adversário, aglutinando amostras que correspondem a muitos vetores de recursos diferentes no espaço original em uma única amostra. Ao comparar a previsão de um modelo DNN na entrada original com a da entrada espremida, a compressão de recursos pode ajudar a detetar exemplos adversários. Se os exemplos originais e espremidos produzirem saídas substancialmente diferentes do modelo, é provável que a entrada seja adversarial. Ao medir o desacordo entre previsões e selecionar um valor limite, o sistema pode produzir a previsão correta para exemplos legítimos e rejeita entradas adversárias.

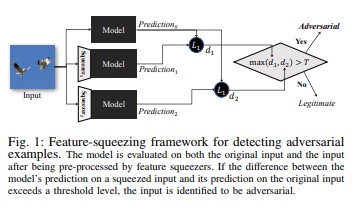 [18]
[18]Defesas certificadas contra exemplos adversários [22]: Os autores propõem um método baseado em um relaxamento semi-definido que produz um certificado de que, para uma determinada rede e entrada de teste, nenhum ataque pode forçar o erro a exceder um determinado valor. Em segundo lugar, como este certificado é diferenciável, os autores otimizam-no em conjunto com os parâmetros da rede, fornecendo um regularizador adaptativo que incentiva a robustez contra todos os ataques.
Ações de resposta
- Emitir alertas sobre resultados de classificação com alta variância entre classificadores, especialmente se de um único usuário ou pequeno grupo de usuários.
Paralelos Tradicionais
Elevação de Privilégio Remota
Severidade
Crítico
Variante #1c: Classificação incorreta aleatória
Esta é uma variação especial onde a classificação de alvo do atacante pode ser qualquer coisa diferente da classificação de origem legítima. O ataque geralmente envolve a injeção de ruído aleatoriamente nos dados de origem que estão sendo classificados para reduzir a probabilidade de a classificação correta ser usada no futuro [3].
Exemplos
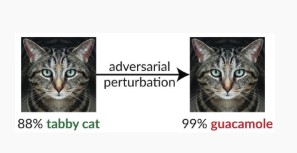
Atenuações
O mesmo que a Variante 1a.
Paralelos Tradicionais
Negação de serviço não persistente
Severidade
Importante
Variante #1d: Redução da Confiança
Um invasor pode criar dados de entrada para reduzir o nível de confiança da classificação correta, especialmente em cenários de alto impacto. Tal pode também assumir a forma de um grande número de falsos positivos destinados a sobrecarregar os administradores ou os sistemas de monitorização com alertas fraudulentos indistinguíveis dos alertas legítimos [3].
Exemplos

Atenuações
- Além das ações abordadas na Variante #1a, a limitação de eventos pode ser empregada para reduzir o volume de alertas de uma única fonte.
Paralelos Tradicionais
Negação de serviço não persistente
Severidade
Importante
#2a envenenamento direcionado de dados
Descrição
O objetivo do atacante é contaminar o modelo de máquina gerado na fase de treinamento, para que as previsões sobre novos dados sejam modificadas na fase de testes[1]. Em ataques de envenenamento direcionados, o invasor quer classificar erroneamente exemplos específicos para fazer com que ações específicas sejam tomadas ou omitidas.
Exemplos
Submeter software de antivírus como malware para forçar a sua classificação incorreta como malicioso e eliminar o uso de software de antivírus direcionado em sistemas de cliente.
Atenuações
Definir sensores de anomalia para analisar a distribuição de dados no dia a dia e alertar sobre variações
-Medir a variação de dados de treinamento diariamente, telemetria para inclinação / deriva
Validação de entrada, tanto higienização quanto verificação de integridade
O envenenamento injeta amostras de treinamento periféricas. Duas estratégias principais para combater esta ameaça:
-Sanitização/validação de dados: remover amostras maliciosas dos dados de treino -Bagging para prevenir ataques de envenenamento [14]
-Reject-on-Negative-Impact (RONI) defesa [15]
- Aprendizagem robusta: Escolha algoritmos de aprendizagem que sejam robustos na presença de amostras de envenenamento.
-Uma dessas abordagens é descrita em [21], onde os autores abordam o problema do envenenamento de dados em duas etapas: 1) introduzindo um novo método robusto de fatoração matricial para recuperar o subespaço verdadeiro, e 2) nova regressão robusta de componentes de princípio para podar instâncias adversárias com base na base recuperada na etapa (1). Eles caracterizam as condições necessárias e suficientes para recuperar com sucesso o subespaço verdadeiro e apresentam um limite na perda de previsão esperada em comparação com a verdade do solo.
Paralelos Tradicionais
Host trojanizado pelo qual o invasor persiste na rede. Os dados de treinamento ou configuração estão comprometidos e estão a ser processados para a criação do modelo.
Severidade
Crítico
#2b Envenenamento indiscriminado de dados
Descrição
O objetivo é arruinar a qualidade/integridade do conjunto de dados que está sendo atacado. Muitos conjuntos de dados são públicos/não confiáveis/sem curadoria, portanto, isso cria preocupações adicionais em torno da capacidade de detetar tais violações de integridade de dados em primeiro lugar. Treinar com dados comprometidos inadvertidamente é uma situação de lixo entra, lixo sai. Uma vez detetada, o processo de triagem precisa determinar a extensão dos dados que foram violados e colocá-los em quarentena e retreiná-los.
Exemplos
Uma empresa extrai dados sobre futuros de petróleo de um site bem conhecido e fiável para treinar os seus modelos. O site do provedor de dados é subsequentemente comprometido por meio de um ataque de injeção de SQL. O invasor pode envenenar o conjunto de dados à vontade e o modelo que está sendo treinado não tem noção de que os dados estão contaminados.
Atenuações
O mesmo que a variante 2a.
Paralelos Tradicionais
Negação de serviço autenticada em relação a um ativo de alto valor
Severidade
Importante
#3 Ataques de Inversão de Modelo
Descrição
Os recursos privados usados em modelos de aprendizado de máquina podem ser recuperados [1]. Isso inclui a reconstrução de dados de treinamento privados aos quais o invasor não tem acesso. Também conhecidos como ataques de escalada na comunidade biométrica [16, 17]. Isto é realizado encontrando a entrada que maximize a confiança retornada, sujeita à classificação correspondente ao alvo [4].
Exemplos
 [4]
[4]
Atenuações
Interfaces para modelos treinados a partir de dados confidenciais precisam de um forte controle de acesso.
Consultas de limite de taxa permitidas pelo modelo
Implemente portas entre usuários/chamadores e o modelo real executando a validação de entrada em todas as consultas propostas, rejeitando qualquer coisa que não atenda à definição do modelo de correção de entrada e retornando apenas a quantidade mínima de informações necessárias para ser útil.
Paralelos Tradicionais
Divulgação de informações direcionada e encoberta
Severidade
Define-se como importante de acordo com o padrão de barra de bugs SDL, mas a extração de dados confidenciais ou pessoalmente identificáveis elevaria isso para crítico.
#4 Ataque de inferência de afiliação
Descrição
O invasor pode determinar se um determinado registro de dados fazia parte do conjunto de dados de treinamento do modelo ou não[1]. Os pesquisadores foram capazes de prever o procedimento principal de um paciente (por exemplo: Cirurgia pela qual o paciente passou) com base nos atributos (por exemplo: idade, sexo, hospital) [1].
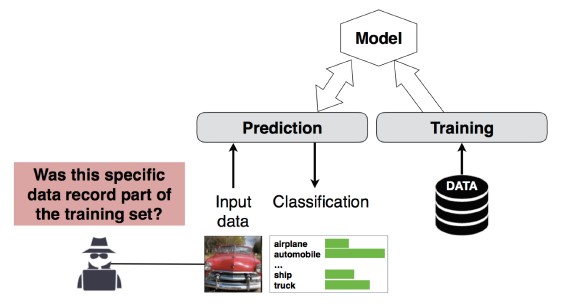 [12]
[12]
Atenuações
Trabalhos de investigação que demonstram a viabilidade deste ataque indicam que a Privacidade Diferencial [4, 9] seria uma mitigação eficaz. Este ainda é um campo incipiente na Microsoft e a AETHER Security Engineering recomenda a construção de experiência com investimentos em pesquisa neste espaço. Esta investigação precisaria enumerar as capacidades de Privacidade Diferencial e avaliar a sua eficácia prática como mitigação; depois, projetar formas para que estas defesas sejam herdadas de forma transparente nas nossas plataformas de serviços online, de modo semelhante à forma como a compilação de código no Visual Studio oferece as proteções de segurança padrão on-by, que são transparentes tanto para o desenvolvedor como para os utilizadores.
O uso de abandono de neurônios e empilhamento de modelos pode ser mitigações eficazes até certo ponto. Usar o abandono de neurônios não só aumenta a resiliência de uma rede neural a esse ataque, mas também aumenta o desempenho do modelo [4].
Paralelos Tradicionais
Privacidade de Dados. Inferências estão sendo feitas sobre a inclusão de um ponto de dados no conjunto de treinamento, mas os dados de treinamento em si não estão sendo divulgados
Severidade
Esta é uma questão de privacidade, não uma questão de segurança. Isso é abordado na orientação de modelagem de ameaças porque os domínios se sobrepõem, mas qualquer resposta aqui seria impulsionada pela Privacidade, não pela Segurança.
#5 Roubo de modelos
Descrição
Os atacantes recriam o modelo subjacente ao legitimamente consultar o modelo. A funcionalidade do novo modelo é idêntica à do modelo subjacente[1]. Depois que o modelo é recriado, ele pode ser invertido para recuperar informações de recursos ou fazer inferências em dados de treinamento.
Resolução de equações – Para um modelo que retorna probabilidades de classe via saída de API, um invasor pode criar consultas para determinar variáveis desconhecidas em um modelo.
Path Finding – um ataque que explora as particularidades da API para extrair as "decisões" tomadas por uma árvore ao classificar uma entrada [7].
Ataque de transferibilidade - Um adversário pode treinar um modelo local - possivelmente emitindo consultas de previsão para o modelo alvo - e usá-lo para criar exemplos adversários que se transferem para o modelo de destino [8]. Se o seu modelo for extraído e descoberto vulnerável a um tipo de entrada adversarial, novos ataques contra o modelo implantado na produção poderão ser desenvolvidos totalmente offline pelo invasor que extraiu uma cópia do modelo.
Exemplos
Em configurações onde um modelo de ML serve para detetar comportamentos adversários, como identificação de spam, classificação de malware e deteção de anomalias de rede, a extração de modelos pode facilitar ataques de evasão [7].
Atenuações
Ações Proativas/Protetoras
Minimize ou ofusque os detalhes retornados nas APIs de previsão, mantendo sua utilidade para aplicativos "honestos" [7].
Defina uma consulta bem formada para as entradas do modelo e só retorne resultados em resposta a entradas concluídas e bem formadas que correspondam a esse formato.
Devolver valores de confiança arredondados. A maioria dos chamadores legítimos não precisa de várias casas decimais de precisão.
Paralelos Tradicionais
Adulteração não autenticada, sem possibilidade de modificação, de dados do sistema, e divulgação direcionada de informações de alto valor?
Severidade
Importante em modelos sensíveis à segurança, moderado de outra forma
#6 Reprogramação de Redes Neurais
Descrição
Por meio de uma consulta especialmente criada de um adversário, os sistemas de aprendizado de máquina podem ser reprogramados para uma tarefa que se desvia da intenção original do criador [1].
Exemplos
Controles de acesso fracos em uma API de reconhecimento facial permitindo que terceiros incorporem-se em aplicações destinadas a prejudicar os clientes da Microsoft, como um gerador de deep fakes.
Atenuações
Forte autenticação mútua cliente-servidor<> e controle de acesso a interfaces de modelo
Retirada das contas infratoras.
Identifique e aplique um contrato de nível de serviço para suas APIs. Determine o tempo aceitável para corrigir um problema uma vez relatado e certifique-se de que o problema não seja mais repetido quando o SLA expirar.
Paralelos Tradicionais
Este é um cenário de abuso. É menos provável que você abra um incidente de segurança sobre isso do que simplesmente desative a conta do infrator.
Severidade
Importante a Crítico
#7 Exemplo Adversarial no domínio Físico (bits-átomos>)
Descrição
Um exemplo contraditório é uma entrada/consulta de uma entidade maliciosa enviada com o único objetivo de enganar o sistema de aprendizado de máquina [1]
Exemplos
Esses exemplos podem se manifestar no domínio físico, como um carro autônomo sendo enganado para executar um sinal de parada por causa de uma certa cor de luz (a entrada adversarial) sendo brilhada no sinal de parada, forçando o sistema de reconhecimento de imagem a não ver mais o sinal de parada como um sinal de parada.
Paralelos Tradicionais
Elevação de privilégio, execução remota de código
Atenuações
Esses ataques se manifestam porque os problemas na camada de aprendizado de máquina (a camada de dados e algoritmo abaixo da tomada de decisão orientada por IA) não foram mitigados. Tal como acontece com qualquer outro software *ou* sistema físico, a camada abaixo do alvo pode sempre ser atacada através de vetores tradicionais. Por isso, as práticas tradicionais de segurança são mais importantes do que nunca, especialmente com a camada de vulnerabilidades não mitigadas (a camada de dados/algo) sendo usada entre a IA e o software tradicional.
Severidade
Crítico
#8 Provedores de ML mal-intencionados que podem recuperar dados de treinamento
Descrição
Um provedor mal-intencionado apresenta um algoritmo com backdoor, através do qual os dados de treinamento privados são recuperados. Eles foram capazes de reconstruir rostos e textos, apenas com o modelo.
Paralelos Tradicionais
Divulgação de informações direcionada
Atenuações
Trabalhos de pesquisa demonstrando a viabilidade deste ataque indicam que a criptografia homomórfica seria uma mitigação eficaz. Esta é uma área com pouco investimento atual na Microsoft e a AETHER Security Engineering recomenda a construção de experiência com investimentos em pesquisa neste espaço. Esta pesquisa precisaria enumerar princípios de criptografia homomórfica e avaliar sua eficácia prática como mitigações em face de provedores maliciosos de ML-as-a-Service.
Severidade
Importante se os dados forem informação pessoal identificável, menos importante caso contrário
#9 Atacando a cadeia de suprimentos de ML
Descrição
Devido aos grandes recursos (dados + computação) necessários para treinar algoritmos, a prática atual é reutilizar modelos treinados por grandes corporações e modificá-los ligeiramente para a tarefa em questão (por exemplo: ResNet é um modelo de reconhecimento de imagem popular da Microsoft). Esses modelos são selecionados em um zoológico modelo (o Caffe hospeda modelos populares de reconhecimento de imagem). Neste ataque, o adversário ataca os modelos hospedados em Caffe, envenenando assim o poço para qualquer outra pessoa. [1]
Paralelos Tradicionais
Comprometimento de dependência de terceiros não relacionada à segurança
App Store está inadvertidamente a hospedar malware.
Atenuações
Minimize as dependências de terceiros para modelos e dados sempre que possível.
Incorpore essas dependências em seu processo de modelagem de ameaças.
Utilize autenticação forte, controle de acesso e criptografia entre sistemas de 1ª/3ª parte.
Severidade
Crítico
#10 Aprendizagem Automática Backdoor
Descrição
O processo de treino foi terceirizado para uma 3ª parte mal-intencionada que estava a adulterar os dados de treino e entregou um modelo infectado por trojan que força classificações incorretas direcionadas, como classificar um certo vírus como não malicioso[1]. Este é um risco em cenários de geração de modelo ML-as-a-Service.
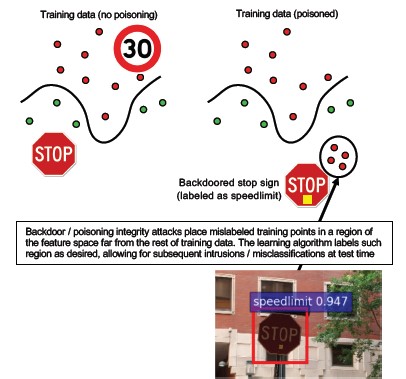 [12]
[12]
Paralelos Tradicionais
Comprometimento da dependência de segurança de terceiros
Mecanismo de atualização de software comprometido
Violação da Autoridade de Certificação
Atenuações
Ações de deteção reativa/defensiva
- O dano já está feito uma vez que essa ameaça foi descoberta, portanto, o modelo e quaisquer dados de treinamento fornecidos pelo provedor mal-intencionado não podem ser confiáveis.
Ações Proativas/Protetoras
Treine todos os modelos sensíveis internamente
Cataloge dados de treinamento ou certifique-se de que eles vêm de terceiros confiáveis com fortes práticas de segurança
Modelo de ameaça: a interação entre o provedor de MLaaS e seus próprios sistemas
Ações de resposta
- O mesmo que para o comprometimento da dependência externa
Severidade
Crítico
#11 Tirar partido das dependências de software do sistema de ML
Descrição
Neste ataque, o atacante NÃO manipula os algoritmos. Em vez disso, explora vulnerabilidades de software, como estouros de buffer ou scripts entre sites[1]. Ainda é mais fácil comprometer camadas de software sob IA/ML do que atacar diretamente a camada de aprendizagem, portanto, as práticas tradicionais de mitigação de ameaças à segurança detalhadas no Ciclo de Vida de Desenvolvimento de Segurança são essenciais.
Paralelos Tradicionais
Dependência de software de código aberto comprometida
Vulnerabilidade no servidor Web (falha de validação de entrada XSS, CSRF, API)
Atenuações
Trabalhe com sua equipe de segurança para seguir as práticas recomendadas aplicáveis do Ciclo de Vida de Desenvolvimento de Segurança/Garantia de Segurança Operacional.
Severidade
Variável; Até Crítico, dependendo do tipo de vulnerabilidade de software tradicional.
Bibliografia
[1] Modos de falha no aprendizado de máquina, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Fluxo de Trabalho de Engenharia de Segurança AETHER, equipa V de Proveniência/Linhagem de Dados
[3] Exemplos Adversariais em Deep Learning: Caracterização e Divergência, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Ataques e Defesas de Inferência de Filiação Independente de Modelo e Dados em Modelos de Aprendizagem Automática, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha e T. Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, nas Atas da Conferência ACM SIGSAC sobre Segurança de Computadores e Comunicações de 2015 (CCS).
[6] Nicolas Papernot e Patrick McDaniel - Exemplos Adversários em Aprendizagem Automática AIWTB 2017
[7] Roubo de Modelos de Aprendizagem Automática através de APIs de Predição, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Universidade de Cornell; Ari Juels, Cornell Tech; Michael K. Reiter, Universidade da Carolina do Norte em Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] O Espaço de Exemplos Adversariais Transferíveis, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh e Patrick McDaniel
[9] Compreender Inferências de Associação em Modelos de Aprendizagem Well-Generalized Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 e Kai Chen3,4
[10] Simon-Gabriel et al., A vulnerabilidade adversarial das redes neurais aumenta com a dimensão de entrada, ArXiv 2018;
[11] Lyu et al., A unified gradient regularization family for adversarial examples (Uma família unificada de regularização de gradientes para exemplos adversários), ICDM 2015
[12] Padrões Selvagens: Dez Anos Após a Ascensão da Aprendizagem de Máquina Adversarial - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Deteção de malware adversariamente robusta usando classificação monotônica, Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto e Fabio Roli. Classificadores de ensacamento para combater ataques de envenenamento em tarefas de classificação adversária
[15] Uma rejeição aprimorada na defesa contra impactos negativos Hongjiang Li e Patrick P.K. Chan
[16] Adler. Vulnerabilidades em sistemas de encriptação biométrica. 5ª Conf. Int. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Sobre a vulnerabilidade dos sistemas de verificação facial a ataques de escalada iterativa. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Compactação de Características: Detecção de exemplos adversários em redes neurais profundas. Simpósio de Segurança de Redes e Sistemas Distribuídos 2018. 18-21 fevereiro.
[19] Reforçar a Robustez Adversarial usando a Confiança do Modelo Induzida pelo Treino Adversarial - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Análise Causal Orientada por Atribuição para Deteção de Exemplos Adversários, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Regressão linear robusta contra envenenamento de dados de treinamento – Chang Liu et al.
[22] Característica de Redução de Ruído para Melhorar a Robustez a Ataques Adversariais, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Defesas certificadas contra exemplos adversários - Aditi Raghunathan, Jacob Steinhardt, Percy Liang