Monitorar o desempenho de Grupos de Disponibilidade AlwaysOn
Aplica-se a: ![]() SQL Server
SQL Server
O aspecto do desempenho de Grupos de Disponibilidade Always On é crucial para manter o SLA (Contrato de Nível de Serviço) dos seus bancos de dados de mais críticos. A compreensão de como os grupos de disponibilidade enviam logs para réplicas secundárias pode ajudá-lo a estimar o RTO (objetivo de tempo de recuperação) e o RPO (objetivo de ponto de recuperação) de sua implementação de disponibilidade e identificar gargalos no mau desempenho de grupos de disponibilidade ou réplicas. Este artigo descreve o processo de sincronização, mostra como calcular algumas das principais métricas e fornece os links para alguns dos cenários comuns de solução de problemas de desempenho.
Processo de sincronização de dados
Para estimar o tempo para a sincronização completa e identificar o gargalo, você precisa entender o processo de sincronização. O gargalo de desempenho pode estar em qualquer lugar do processo e localizar esse gargalo poderá ajudá-lo a se obter detalhes sobre os problemas subjacentes. A figura e a tabela a seguir ilustram o processo de sincronização de dados:

| Sequência | Descrição da etapa | Comentários | Métricas úteis |
|---|---|---|---|
| 1 | Geração de log | Os dados de log são liberados para o disco. Esse log deve ser replicado para as réplicas secundárias. Os registros de log entram na fila de envio. | SQL Server:Database > bytes de log liberados\s |
| 2 | Capturar | Os logs de cada banco de dados são capturados e enviados para a fila de parceiro correspondente (um por par de réplica de banco de dados). Esse processo de captura é executado continuamente enquanto a réplica de disponibilidade está conectada e a movimentação de dados não é suspensa por qualquer razão e o par de réplica de banco de dados está aparecendo como Sincronizando ou Sincronizado. Se o processo de captura não puder verificar e enfileirar as mensagens com a rapidez necessária, a fila de envio de log se acumulará. | SQL Server:Availability Replica > Bytes enviados à replica\s, que é uma agregação de soma de todas as mensagens de banco de dados enfileiradas para essa réplica de disponibilidade. log_send_queue_size (KB) e log_bytes_send_rate (KB/s) na réplica primária. |
| 3 | Enviar | As mensagens na fila de cada réplica de banco de dados são removidas da fila e enviadas pela rede para a respectiva réplica secundária. | SQL Server: Réplica de Disponibilidade > Bytes enviados para transporte\s |
| 4 | Receber e armazenar em cache | Cada réplica secundária recebe e armazena em cache a mensagem. | Contador de desempenho SQL Server:Availability Replica > Bytes de log recebidos/s |
| 5 | Proteção | O log é liberado na réplica secundária para proteção. Após a liberação do log, uma confirmação é enviada de volta para a réplica primária. Depois que o log é protegido, a perda de dados é evitada. |
Contador de desempenho SQL Server:Database > Bytes de log liberados/s Tipo de espera HADR_LOGCAPTURE_SYNC |
| 6 | Refaz | Refaz as páginas liberadas na réplica secundária. As páginas são mantidas na fila para refazer enquanto aguardam para serem refeitas. | SQL Server:Réplica de Banco de Dados > Bytes refeitos/s redo_queue_size (KB) e redo_rate. Tipo de espera REDO_SYNC |
Portões de controle de fluxo
Os grupos de disponibilidade são projetados com portões de controle de fluxo na réplica primária para evitar o consumo excessivo de recursos, como recursos de rede e de memória, em todas as réplicas de disponibilidade. Esses portões de controle de fluxo não afetam o estado de integridade da sincronização das réplicas de disponibilidade, mas eles podem afetar o desempenho geral de seus bancos de dados de disponibilidade, incluindo o RPO.
Depois que os logs forem capturados na réplica primária, eles ficarão sujeitos a dois níveis de controles de fluxo. Quando é alcançado o limite de mensagem de qualquer portão, as mensagens de log não são mais enviadas para uma réplica específica ou para um banco de dados específico. As mensagens poderão ser enviadas depois que as mensagens de confirmação das mensagens enviadas forem recebidas, a fim de reduzir o número de mensagens enviadas abaixo do limite.
Além dos portões de controle de fluxo, há outro fator que pode impedir que as mensagens de log sejam enviadas. A sincronização das réplicas garante que as mensagens sejam enviadas e aplicadas na ordem do LSN (número de sequência de log). Antes do envio de uma mensagem de log, o LSN também é verificado em relação ao menor número LSN confirmado para verificar se ele é menor que um dos limites (dependendo do tipo de mensagem). Se a diferença entre os dois números LSN for maior do que o limite, as mensagens não serão enviadas. Depois que o intervalo estiver abaixo do limite novamente, as mensagens serão enviadas.
O SQL Server 2022 aumenta os limites para o número de mensagens que cada portão permite. Usando o sinalizador de rastreamento 12310, o limite aumentado também está disponível para as seguintes versões do SQL Server, começando com: SQL Server 2019 CU9, SQL Server 2017 CU18 e SQL Server 2016 SP1 CU16.
A seguinte tabela compara os limites de mensagem:
SQL Server 2022 e versões com suporte do SQL Server (começando com SQL Server 2019 CU9, SQL Server 2017 CU18 e SQL Server 2016 SP1 CU16) que habilitam o sinalizador de rastreamento 12310, confira os seguintes limites:
| Nível | Número de portões | Número de mensagens | Métricas úteis |
|---|---|---|---|
| Transporte | 1 por réplica de disponibilidade | 16384 | Eventos estendidos database_transport_flow_control_action |
| Banco de dados | 1 por banco de dados de disponibilidade | 7168 | DBMIRROR_SEND Eventos estendidos hadron_database_flow_control_action |
Dois contadores de desempenho úteis, SQL Server:Réplica de Disponibilidade > Controle de fluxo/s e SQL Server:Réplica de Disponibilidade> Tempo de Controle do Fluxo (ms/s), mostram, no último segundo, o número de vezes que o controle de fluxo foi ativado e quanto tempo foi gasto aguardando pelo controle de fluxo. Um tempo maior de espera pelo controle de fluxo significa um RPO maior. Para obter mais informações sobre os tipos de problemas que podem causar um tempo de espera alto no controle de fluxo, confira Solução de problemas: O grupo de disponibilidade excedeu o RPO.
Estimando o tempo de failover (RTO)
O RTO no seu SLA depende do tempo de failover da sua implementação Always On em um determinado momento, podendo ser expresso na seguinte fórmula:

Importante
Se um grupo de disponibilidade contém mais de um banco de dados de disponibilidade, o banco de dados de disponibilidade com o Tfailover mais alto torna-se o valor de limitação de conformidade do RTO.
O tempo de detecção de falha, Tdetection, é o tempo necessário para o sistema detectar a falha. Esse tempo depende de configurações no nível do cluster e não de cada uma das réplicas de disponibilidade. Dependendo da condição de failover automático configurada, um failover poderá ser disparado como uma resposta imediata para um erro interno crítico do SQL Server, como spinlocks órfãos. Nesse caso, a detecção pode ser tão rápida quanto o envio do relatório de erro sp_server_diagnostics (Transact-SQL) para o cluster WSFC ( o padrão é 1/3 do tempo limite de verificação de integridade). Um failover também pode ser disparado devido a um tempo limite, como a expiração do tempo limite de verificação de integridade do cluster (30 segundos por padrão) ou a expiração do tempo de concessão entre a DLL de recurso e a instância do SQL Server (20 segundos por padrão). Nesse caso, o tempo de detecção será igual ao intervalo de tempo limite. Para obter mais informações, confira Política de failover flexível para failover automático de um grupo de disponibilidade (SQL Server).
A única coisa que a réplica secundária precisa para estar pronta para um failover é que a fase refazer alcance o final do log. O tempo para refazer, Tredo, é calculado com a seguinte fórmula:

em que redo_queue é o valor de redo_queue_size e redo_rate é o valor de redo_rate.
O tempo de sobrecarga de failover, Toverhead, inclui o tempo necessário para realizar o failover do cluster do WSFC e colocar os bancos de dados online. Esse tempo é geralmente curto e constante.
Estimando o potencial de perda de dados (RPO)
O RPO do seu SLA depende da possível perda de dados da implementação Always On em um determinado momento. Essa possível perda de dados pode ser expressa na seguinte fórmula:

em que log_send_queue é o valor de log_send_queue_size e taxa de geração de log é o valor de SQL Server:Database > Bytes de log liberados/s.
Aviso
Se um grupo de disponibilidade contém mais de um banco de dados de disponibilidade, o banco de dados de disponibilidade com o Tdata_loss mais alto torna-se o valor de limitação de conformidade do RPO.
A fila de envio de log representa todos os dados que podem ser perdidos em uma falha catastrófica. À primeira vista, é curioso que a taxa de geração de log seja usada em vez da taxa de envio de log (veja log_send_rate). No entanto, lembre-se de que o uso da taxa de envio de log só lhe oferece o tempo para sincronizar, enquanto que o RPO mede a perda de dados com base na velocidade que ele é gerado, não a velocidade com que ele é sincronizado.
Uma maneira mais simples de estimar o Tdata_loss é usar last_commit_time. O DMV na réplica primária relata esse valor para todas as réplicas. Você pode calcular a diferença entre o valor da réplica primária e o valor da réplica secundária para estimar a velocidade com que o log da réplica secundária é atualizado com a réplica primária. Como mencionado anteriormente, esse cálculo não informa a potencial perda de dados com base na velocidade em que o log é gerado, mas é uma boa aproximação.
Estimar o RTO e RPO com o painel do SSMS
Em grupos de disponibilidade Always On, o RTO e o RPO são calculados e exibidos para os bancos de dados hospedados nas réplicas secundárias. No painel da réplica primária, o RTO e o RPO são agrupados pela réplica secundária.
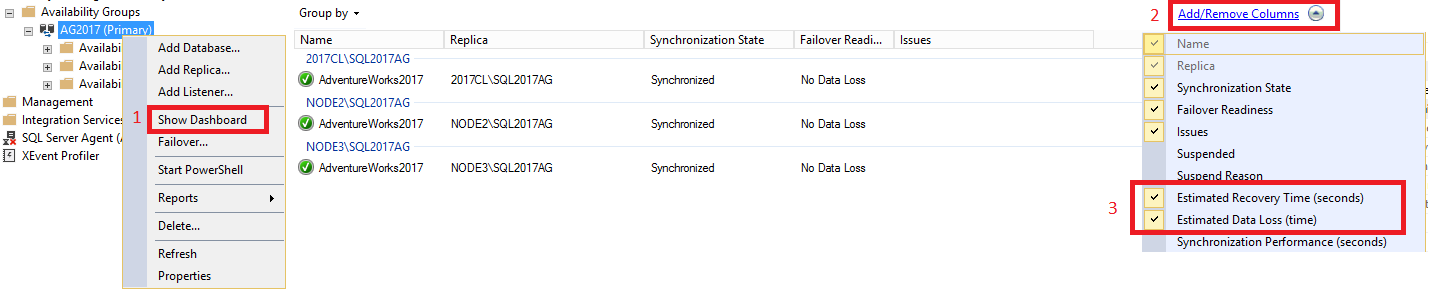
Para exibir o RTO e o RPO dentro do painel, faça o seguinte:
No SQL Server Management Studio, expanda o nó alta disponibilidade Always On, clique com o botão direito do mouse no nome do seu grupo de disponibilidade e selecione Mostrar painel.
Selecione Adicionar/remover colunas na guia Agrupar por. Verifique o Tempo estimado para recuperação (segundos) [RTO] e também a Perda de dados estimada (tempo) [RPO].
Cálculo do RTO do banco de dados secundário
O cálculo do tempo de recuperação determina quanto tempo é necessário para recuperar o banco de dados secundário após um failover. O tempo de failover geralmente é curto e constante. O tempo de detecção depende de configurações no nível do cluster e não de cada uma das réplicas de disponibilidade.
Para um banco de dados secundário (DB_sec), o cálculo e a exibição do respectivo RTO é baseado em seus valores de redo_queue_size e redo_rate:
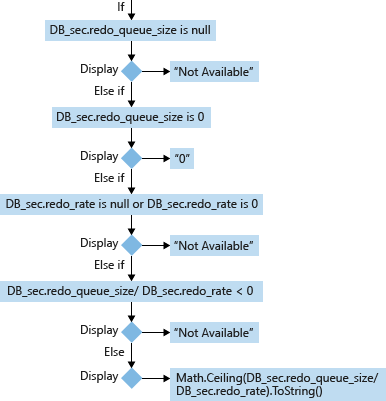
Exceto em casos muito atípicos, a fórmula para calcular o RTO do banco de dados secundário é:
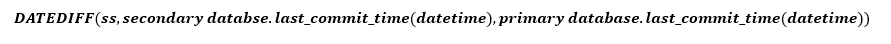
Cálculo do RPO do banco de dados secundário
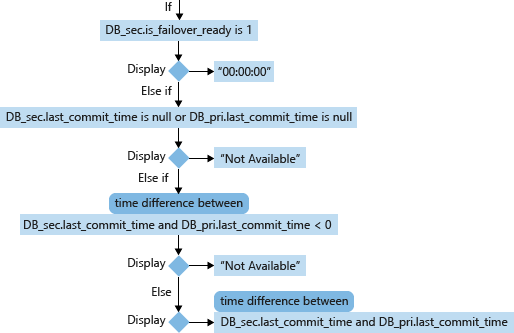
Para um banco de dados secundário (DB_sec), o cálculo e a exibição de seu RPO se baseiam nos seus valores de is_failover_ready e last_commit_time, bem como no valor de last_commit_time do seu banco de dados primário correlacionado (DB_pri). Quando is_failover_ready = 1 no banco de dados secundário, os dados estão sincronizados e não há perda de dados após o failover. No entanto, se esse valor é 0, há uma lacuna entre o last_commit_time no banco de dados primário e o last_commit_time no banco de dados secundário.
Para o banco de dados primário, o last_commit_time é a hora em que última transação foi confirmada. Para o banco de dados secundário, o last_commit_time é a hora de confirmação mais recente da transação no banco de dados primário, que também foi protegido com êxito no banco de dados secundário. Esse número deve ser o mesmo para o banco de dados primário e o secundário. Uma diferença entre esses dois valores é a duração pela qual as transações pendentes não foram protegidas no banco de dados secundário e serão perdidas em caso de um failover.
Contadores de desempenho usados em fórmulas de RTO/RPO
- redo_queue_size (KB) [usado no RTO]: O tamanho da fila de restauração é o tamanho dos logs de transação entre o last_received_lsn e o last_redone_lsn. last_received_lsn é a ID de bloco de log que identifica o ponto até o qual todos os blocos de log foram recebidos pela réplica secundária que hospeda este banco de dados secundário. Last_redone_lsn é o número de sequência de log real do último registro de log que foi desfeito no banco de dados secundário. Com base nesses dois valores, podemos encontrar IDs do bloco de log inicial (last_received_lsn) e do bloco de log final (last_redone_lsn). O espaço entre esses dois blocos de log pode então representar como os blocos de log de transação talvez ainda não tenham sido refeitos. Isso é medido em quilobytes (KB).
- redo_rate (KB/s) [usado no RTO]: Um valor cumulativo que representa, em um período de tempo decorrido, quanto do log de transações (KB) foi refeito no banco de dados secundário em quilobytes/segundo (KB/s).
- last_commit_time (Datetime) [usado no RPO]: Para o banco de dados primário, o last_commit_time é a hora em que última transação foi confirmada. Para o banco de dados secundário, o last_commit_time é a hora de confirmação mais recente da transação no banco de dados primário, que também foi protegido com êxito no banco de dados secundário. Uma vez que esse valor na réplica secundária deve ser sincronizado com o mesmo valor na réplica primária, qualquer lacuna existente entre esses dois valores é a estimativa de perda de dados (RPO).
Estimar o RTO e o RPO usando DMVs
É possível consultar os DMVs sys.dm_hadr_database_replica_states e sys.dm_hadr_database_replica_cluster_states para estimar o RPO e o RTO de um banco de dados. As consultas abaixo criam procedimentos armazenados que fazem duas coisas.
Observação
Verifique se você criou e executou o procedimento armazenado para estimar o RTO pela primeira vez, pois os valores que ele produz são necessários para executar o procedimento armazenado a fim de estimar o RPO.
Criar um procedimento armazenado para estimar o RTO
- Na réplica secundária de destino, crie o procedimento armazenado proc_calculate_RTO. Se esse procedimento armazenado já existir, remova-o primeiro e, em seguida, recrie-o.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Execute proc_calculate_RTO com o nome do banco de dados secundário de destino:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
A saída exibe o valor de RTO do banco de dados de réplica secundária de destino. Salve a group_id, a replica_id e a group_database_id para usar com o procedimento armazenado de estimativa de RPO.
Saída de exemplo:
O RTO de banco de dados DB_sec' é 0
A group_id do banco de dados DB4 é F176DD65-C3EE-4240-BA23-EA615F965C9B
A replica_id do banco de dados DB4 é 405554F6-3FDC-4593-A650-2067F5FABFFD
A group_database_id do banco de dados DB4 é 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Criar um procedimento armazenado para estimar o RPO
- Na réplica primária, crie o procedimento armazenado proc_calculate_RPO. Se ele já existir, remova-o primeiro e, em seguida, recrie-o.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Execute proc_calculate_RPO com a group_id, a replica_id e a group_database_id do banco de dados secundário de destino.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- A saída exibe o valor de RPO do banco de dados de réplica secundária de destino.
Monitoramento de RTO e RPO
Esta seção demonstra como monitorar as métricas de RTO e RPO de seus grupos de disponibilidade. Esta demonstração é semelhante ao tutorial de GUI fornecido em The Always On health model, part 2: Extending the health model (O modelo de integridade do Always On, parte 2: estendendo o modelo de integridade).
Os elementos do tempo de failover e os cálculos da possível perda de dados em Estimando o tempo de failover (RTO) e Estimando o potencial de perda de dados (RPO) são fornecidos convenientemente como métricas de desempenho na faceta de gerenciamento de política, Estado da réplica de banco de dados (veja Exibir as facetas do gerenciamento baseado em políticas em um objeto do SQL Server). Você pode monitorar essas duas métricas de acordo com um agendamento e ser alertado quando as métricas excederem o RTO e RPO, respectivamente.
Os scripts demonstrados criam duas políticas de sistema que são executadas de acordo com os respectivos agendamentos, com as seguintes características:
Uma política de RTO falha quando o tempo de failover estimado ultrapassa 10 minutos, avaliado a cada 5 minutos
Uma política de RPO falha quando a perda de dados estimada ultrapassa 1 hora, avaliada a cada 30 minutos
As duas políticas têm configurações idênticas em todas as réplicas de disponibilidade
As políticas são avaliadas em todos os servidores, mas somente nos grupos de disponibilidade para os quais a réplica de disponibilidade local é a réplica primária. Se a réplica de disponibilidade local não for a primária, as políticas não serão avaliadas.
As falhas de política são convenientemente exibidas no Painel Always On quando você as exibe na réplica primária.
Para criar as políticas, siga as instruções abaixo em todas as instâncias de servidor que participam do grupo de disponibilidade:
Inicie o serviço SQL Server Agent se ainda não tiver iniciado.
No SQL Server Management Studio, no menu Ferramentas, clique em Opções.
Na guia SQL Server Always On, selecione Habilitar política Always On definida pelo usuário e clique em OK.
Essa configuração permite que você exiba as políticas personalizadas configuradas corretamente no Painel Always On.
Crie uma condição de gerenciamento baseado em políticas usando as seguintes especificações:
Nome:
RTOFaceta: Estado da Réplica de Banco de Dados
Campo:
Add(@EstimatedRecoveryTime, 60)Operador: <=
Valor:
600
Essa condição falha quando o tempo de failover potencial ultrapassa 10 minutos, incluindo uma sobrecarga de 60 segundos para detecção de falha e failover.
Crie uma segunda condição de gerenciamento baseado em políticas usando as seguintes especificações:
Nome:
RPOFaceta: Estado da Réplica de Banco de Dados
Campo:
@EstimatedDataLossOperador: <=
Valor:
3600
Essa condição de falha quando a possível perda de dados excede 1 hora.
Crie uma terceira condição de gerenciamento baseado em políticas usando as seguintes especificações:
Nome:
IsPrimaryReplicaFaceta: Grupo de disponibilidade
Campo:
@LocalReplicaRoleOperador: =
Valor:
Primary
Essa condição verifica se a réplica de disponibilidade local de um determinado grupo de disponibilidade é a réplica primária.
Crie uma política de gerenciamento baseado em políticas usando as seguintes especificações:
Página geral:
Nome:
CustomSecondaryDatabaseRTOVerificar condição:
RTOEm relação aos destinos: Cada DatabaseReplicaState em IsPrimaryReplica AvailabilityGroup
Essa configuração garante que a política seja avaliada apenas em grupos de disponibilidade para os quais a réplica de disponibilidade local seja a réplica primária.
Modo de avaliação: Ao agendar
Agendamento: CollectorSchedule_Every_5min
Habilitado: selecionado
Página descrição:
Categoria: Avisos do banco de dados de disponibilidade
Essa configuração permite que os resultados da avaliação de política sejam exibidos no Painel Always On.
Descrição: A réplica atual tem um RTO que excede 10 minutos, considerando uma sobrecarga de 1 minuto para descoberta e failover. Você deve investigar problemas de desempenho na respectiva instância de servidor imediatamente.
Texto a ser exibido: RTO excedido!
Crie uma segunda política de gerenciamento baseado em políticas usando as seguintes especificações:
Página geral:
Nome:
CustomAvailabilityDatabaseRPOVerificar condição:
RPOEm relação aos destinos: Cada DatabaseReplicaState em IsPrimaryReplica AvailabilityGroup
Modo de avaliação: Ao agendar
Agendamento: CollectorSchedule_Every_30min
Habilitado: selecionado
Página descrição:
Categoria: Avisos do banco de dados de disponibilidade
Descrição: O banco de dados de disponibilidade excedeu o RPO de 1 hora. Você deve investigar problemas de desempenho nas réplicas de disponibilidade imediatamente.
Texto a ser exibido: RPO excedido!
Ao terminar, dois novos trabalhos do SQL Server Agent serão criados, um para cada agendamento de avaliação de política. Esses trabalhos devem ter nomes que começam com syspolicy_check_schedule.
Você pode exibir o histórico de trabalhos para inspecionar os resultados da avaliação. As falhas de avaliação também são registradas no log de aplicativos do Windows (no Visualizador de Eventos) com a ID de evento 34052. Você também pode configurar o SQL Server Agent para enviar alertas sobre falhas de política. Para obter mais informações, veja Configurar alertas para notificar os administradores de políticas sobre falhas.
Cenários de solução de problemas de desempenho
A tabela a seguir lista os cenários comuns de solução de problemas relacionados ao desempenho.
| Cenário | Descrição |
|---|---|
| Solucionar problemas: o grupo de disponibilidade excedeu o RTO | Após um failover automático ou um failover manual planejado sem perda de dados, o tempo de failover excede o RTO. Ou, quando você calcula o tempo de failover de uma réplica secundária de confirmação síncrona (como um parceiro de failover automático), você descobre que ele excede o RTO. |
| Solucionar problemas: o grupo de disponibilidade excedeu o RPO | Depois de executar um failover manual forçado, a perda de dados é maior que o RPO. Ou, ao calcular a possível perda de dados de uma réplica secundária de confirmação assíncrona, você descobre que ela excede o RPO. |
| Solucionar problemas: as alterações na réplica primária não são refletidas na réplica secundária | O aplicativo cliente conclui uma atualização na réplica primária com êxito, mas uma consulta à réplica secundária mostra que a alteração não foi refletida. |
Eventos estendidos úteis
Os seguintes eventos estendidos são úteis ao solucionar problemas de réplicas no estado Sincronizando.
| Nome do evento | Categoria | Canal | Réplica de disponibilidade |
|---|---|---|---|
| redo_caught_up | transações | Depurar | Secundário |
| redo_worker_entry | transações | Depurar | Secundário |
| hadr_transport_dump_message | alwayson |
Depurar | Primária |
| hadr_worker_pool_task | alwayson |
Depurar | Primária |
| hadr_dump_primary_progress | alwayson |
Depurar | Primária |
| hadr_dump_log_progress | alwayson |
Depurar | Primária |
| hadr_undo_of_redo_log_scan | alwayson |
Analítico | Secundário |