Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se a:![]() SQL Server
SQL Server![]() SSIS Integration Runtime em Azure Data Factory
SSIS Integration Runtime em Azure Data Factory
A tarefa Fluxo de Dados encapsula o motor de fluxo de dados que move dados entre fontes e destinos, permitindo ao utilizador transformar, limpar e modificar dados à medida que são movidos. A adição de uma tarefa de Fluxo de Dados a um fluxo de controlo de pacote permite ao pacote extrair, transformar e carregar dados.
Um fluxo de dados consiste em pelo menos um componente de fluxo de dados, mas é tipicamente um conjunto de componentes de fluxo de dados conectados: fontes que extraem dados; transformações que modificam, encaminham ou resumem dados; e destinos que carregam dados.
Em tempo de execução, a tarefa Data Flow constrói um plano de execução a partir do fluxo de dados, e o motor de fluxo de dados executa o plano. Pode criar uma tarefa de Fluxo de Dados que não tenha fluxo de dados, mas a tarefa só é executada se incluir pelo menos um fluxo de dados.
Para inserir dados em massa de ficheiros de texto numa base de dados SQL Server, pode usar a tarefa Inserir em massa em vez de uma tarefa de Fluxo de Dados e de um fluxo de dados. No entanto, a tarefa Bulk Insert não pode transformar dados. Para mais informações, consulte Tarefa de Inserção em Massa.
Fluxos Múltiplos
Uma tarefa de Fluxo de Dados pode incluir múltiplos fluxos de dados. Se uma tarefa copiar vários conjuntos de dados, e se a ordem em que os dados são copiados não for significativa, pode ser mais conveniente incluir múltiplos fluxos de dados na tarefa de Fluxo de Dados. Por exemplo, pode criar cinco fluxos de dados, cada um copiando dados de um ficheiro plano para uma tabela de dimensões diferente num esquema estrela de data warehouse.
No entanto, o motor de fluxo de dados determina a ordem de execução quando existem múltiplos fluxos de dados numa única tarefa de fluxo de dados. Portanto, quando a ordem é importante, o pacote deve usar múltiplas tarefas de Fluxo de Dados, cada tarefa contendo um fluxo de dados. Pode então aplicar restrições de precedência para controlar a ordem de execução das tarefas.
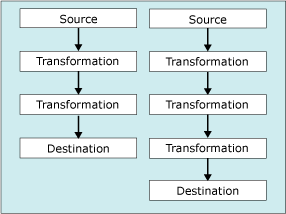
O diagrama seguinte mostra uma tarefa de Fluxo de Dados que possui múltiplos fluxos de dados.
Entradas de log
Os Serviços de Integração fornecem um conjunto de eventos de registo disponíveis para todas as tarefas. O Integration Services também fornece entradas de registo personalizadas para muitas tarefas. Para obter mais informações, consulte o Log de Serviços de Integração (SSIS) . A tarefa Fluxo de Dados inclui as seguintes entradas de registo personalizadas:
| Entrada de log | Description |
|---|---|
| BufferSizeTuning | Indica que a tarefa Data Flow alterou o tamanho do buffer. A entrada do registo descreve as razões para a alteração de tamanho e lista o novo tamanho temporário do buffer. |
| OnPipelinePostEndOfRowset | Denota que um componente recebeu o seu sinal de fim de linha, que é definido pela última chamada do método ProcessInput . É escrita uma entrada para cada componente no fluxo de dados que processa a entrada. A entrada inclui o nome do componente. |
| OnPipelinePostPrimeOutput | Indica que o componente completou a sua última chamada ao método PrimeOutput . Dependendo do fluxo de dados, podem ser escritas múltiplas entradas de registo. Se o componente for uma fonte, esta entrada de registo significa que o componente terminou de processar as linhas. |
| OnPipelinePreEndOfRowset | Indica que um componente está prestes a receber o seu sinal de fim de linhas, que é definido pela última chamada do método ProcessInput . É escrita uma entrada para cada componente no fluxo de dados que processa a entrada. A entrada inclui o nome do componente. |
| OnPipelinePrePrimeOutput | Indica que o componente está prestes a receber a sua chamada do método PrimeOutput . Dependendo do fluxo de dados, podem ser escritas múltiplas entradas de registo. |
| OnPipelineRowsSent | Reporta o número de linhas fornecidas a uma entrada de componente por uma chamada ao método ProcessInput . A entrada do registo inclui o nome do componente. |
| PipelineBufferLeak | Fornece informações sobre qualquer componente que manteve os buffers ativos depois de o gestor de buffers desaparecer. Se um buffer ainda estiver ativo, os recursos do buffer não foram libertados e podem causar fugas de memória. A entrada do registo fornece o nome do componente e o ID do buffer. |
| PipelineComponentTime | Reporta o tempo (em milissegundos) que o componente passou em cada um dos seus cinco principais passos de processamento — Validar, Pré-Executar, Pós-Executar, ProcessInput e ProcessOutput. |
| PipelineExecutionPlan | Reporta o plano de execução do fluxo de dados. O plano de execução fornece informações sobre como os buffers serão enviados aos componentes. Esta informação, em combinação com a entrada de registo PipelineExecutionTrees, descreve o que está a acontecer dentro da tarefa Data Flow. |
| PipelineExecutionTrees | Reporta as árvores de execução do layout no fluxo de dados. O escalonador do motor de fluxo de dados utiliza as árvores para construir o plano de execução do fluxo de dados. |
| Inicialização do Pipeline | Fornece informação de inicialização sobre a tarefa. Esta informação inclui os diretórios a usar para armazenamento temporário de dados BLOB, o tamanho padrão do buffer e o número de linhas num buffer. Dependendo da configuração da tarefa Data Flow, podem ser escritas várias entradas de log. |
Estas entradas de registo fornecem uma grande quantidade de informação sobre a execução da tarefa de Fluxo de Dados cada vez que executa um pacote. À medida que executa os pacotes repetidamente, pode captar informação que, ao longo do tempo, fornece informações históricas importantes sobre o processamento que a tarefa realiza, questões que podem afetar o desempenho e o volume de dados que essa tarefa gere.
Para mais informações sobre como usar estas entradas de registo para monitorizar e melhorar o desempenho do fluxo de dados, consulte um dos seguintes tópicos:
Mensagens de exemplo de uma tarefa de fluxo de dados
A tabela seguinte lista mensagens de exemplo para entradas de registo para um pacote muito simples. O pacote utiliza uma fonte OLE DB para extrair dados de uma tabela, uma transformação Sort para ordenar os dados e um destino OLE DB para escrever os dados numa tabela diferente.
| Entrada de log | Messages |
|---|---|
| BufferSizeTuning | Rows in buffer type 0 would cause a buffer size greater than the configured maximum. There will be only 9637 rows in buffers of this type.Rows in buffer type 2 would cause a buffer size greater than the configured maximum. There will be only 9497 rows in buffers of this type.Rows in buffer type 3 would cause a buffer size greater than the configured maximum. There will be only 9497 rows in buffers of this type. |
| OnPipelinePostEndOfRowset | A component will be given the end of rowset signal. : 1180 : Sort : 1181 : Sort InputA component will be given the end of rowset signal. : 1291 : OLE DB Destination : 1304 : OLE DB Destination Input |
| OnPipelinePostPrimeOutput | A component has returned from its PrimeOutput call. : 1180 : SortA component has returned from its PrimeOutput call. : 1 : OLE DB Source |
| OnPipelinePreEndOfRowset | A component has finished processing all of its rows. : 1180 : Sort : 1181 : Sort InputA component has finished processing all of its rows. : 1291 : OLE DB Destination : 1304 : OLE DB Destination Input |
| OnPipelinePrePrimeOutput | PrimeOutput will be called on a component. : 1180 : SortPrimeOutput will be called on a component. : 1 : OLE DB Source |
| OnPipelineRowsSent | Rows were provided to a data flow component as input. : : 1185 : OLE DB Source Output : 1180 : Sort : 1181 : Sort Input : 76Rows were provided to a data flow component as input. : : 1308 : Sort Output : 1291 : OLE DB Destination : 1304 : OLE DB Destination Input : 76 |
| PipelineComponentTime | The component "Calculate LineItemTotalCost" (3522) spent 356 milliseconds in ProcessInput.The component "Sum Quantity and LineItemTotalCost" (3619) spent 79 milliseconds in ProcessInput.The component "Calculate Average Cost" (3662) spent 16 milliseconds in ProcessInput.The component "Sort by ProductID" (3717) spent 125 milliseconds in ProcessInput.The component "Load Data" (3773) spent 0 milliseconds in ProcessInput.The component "Extract Data" (3869) spent 688 milliseconds in PrimeOutput filling buffers on output "OLE DB Source Output" (3879).The component "Sum Quantity and LineItemTotalCost" (3619) spent 141 milliseconds in PrimeOutput filling buffers on output "Aggregate Output 1" (3621).The component "Sort by ProductID" (3717) spent 16 milliseconds in PrimeOutput filling buffers on output "Sort Output" (3719). |
| PipelineExecutionPlan | SourceThread0Drives: 1Influences: 1180 1291Output Work ListCreatePrimeBuffer of type 1 for output ID 11.SetBufferListener: "WorkThread0" for input ID 1181CreatePrimeBuffer of type 3 for output ID 12.CallPrimeOutput on component "OLE DB Source" (1)End Output Work ListEnd SourceThread0WorkThread0Drives: 1180Influences: 1180 1291Input Work list, input ID 1181 (1 EORs Expected)CallProcessInput on input ID 1181 on component "Sort" (1180) for view type 2End Input Work list for input 1181Output Work ListCreatePrimeBuffer of type 4 for output ID 1182.SetBufferListener: "WorkThread1" for input ID 1304CallPrimeOutput on component "Sort" (1180)End Output Work ListEnd WorkThread0WorkThread1Drives: 1291Influences: 1291Input Work list, input ID 1304 (1 EORs Expected)CallProcessInput on input ID 1304 on component "OLE DB Destination" (1291) for view type 5End Input Work list for input 1304Output Work ListEnd Output Work ListEnd WorkThread1 |
| PipelineExecutionTrees | begin execution tree 0output "OLE DB Source Output" (11)input "Sort Input" (1181)end execution tree 0begin execution tree 1output "OLE DB Source Error Output" (12)end execution tree 1begin execution tree 2output "Sort Output" (1182)input "OLE DB Destination Input" (1304)output "OLE DB Destination Error Output" (1305)end execution tree 2 |
| Inicialização do Pipeline | No temporary BLOB data storage locations were provided. The buffer manager will consider the directories in the TEMP and TMP environment variables.The default buffer size is 10485760 bytes.Buffers will have 10000 rows by defaultThe data flow will not remove unused components because its RunInOptimizedMode property is set to false. |
Muitos eventos de registo escrevem múltiplas entradas, e as mensagens de várias entradas de registo contêm dados complexos. Para facilitar a compreensão e a comunicação do conteúdo de mensagens complexas, pode analisar o texto da mensagem. Dependendo da localização dos registos, podes usar instruções Transact-SQL ou um componente Script para separar o texto complexo em colunas ou outros formatos que consideres mais úteis.
Por exemplo, a tabela seguinte contém a mensagem "As linhas foram fornecidas a um componente de fluxo de dados como entrada. : : 1185 : OLE DB Fonte Saída : 1180 : Ordenar : 1181 : Ordenar Entrada : 76", analisada em colunas. A mensagem foi escrita pelo evento OnPipelineRowsSent quando as linhas foram enviadas da fonte do OLE DB para a transformação Sort.
| Coluna | Description | Valor |
|---|---|---|
| PathID | O valor da propriedade ID no caminho entre a origem OLE DB e a transformação de ordenação. | 1185 |
| Nome do Caminho | O valor da propriedade Nome do caminho. | Saída Fonte OLE DB |
| ComponentID | O valor da propriedade ID da transformação Ordenar. | 1180 |
| ComponentName | O valor da propriedade Name da transformação Sort. | Ordenar |
| InputID | O valor da propriedade ID da entrada para a transformação Ordenar. | 1181 |
| InputName | O valor da propriedade Nome da entrada para a transformação Ordenar. | Ordenar Entrada |
| RowsSent | O número de linhas enviadas para a entrada da transformação Ordenar. | 76 |
Configuração da Tarefa de Fluxo de Dados
Podes definir propriedades na janela de Propriedades ou programaticamente.
Para mais informações sobre como definir estas propriedades na janela de Propriedades , clique no seguinte tópico:
Configuração Programática da Tarefa de Fluxo de Dados
Para mais informações sobre como adicionar programaticamente uma tarefa de fluxo de dados a um pacote e definir propriedades de fluxo de dados, clique no seguinte tópico:
Tarefas relacionadas
Definir as propriedades de uma tarefa ou contêiner
Conteúdo relacionado
Vídeo, Distribuidor de Dados Balanceados, em technet.microsoft.com.