Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se a:![]() SQL Server em Linux
SQL Server em Linux
Este documento descreve como executar as seguintes tarefas para o SQL Server em um cluster de failover de disco compartilhado com o Red Hat Enterprise Linux.
- Executar a transferência manual do cluster
- Monitorar um serviço de SQL Server num cluster de alta disponibilidade
- Adicionar um nó de cluster
- Remover um nó de cluster
- Alterar a frequência de monitoramento de recursos do SQL Server
Descrição da arquitetura
A camada de clustering é baseada no complemento Red Hat Enterprise Linux (RHEL) HA construído sobre Pacemaker. O Corosync e o Pacemaker coordenam as comunicações do cluster e o gerenciamento de recursos. A instância do SQL Server está ativa num dos nós ou no outro.
O diagrama a seguir ilustra os componentes em um cluster Linux com o SQL Server.
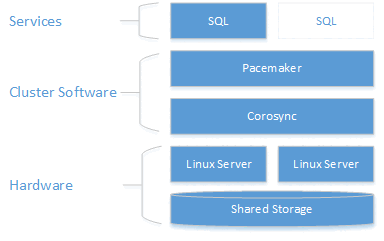
Para obter mais informações sobre configuração de cluster, opções de agentes de recursos e gerenciamento, visite documentação de referência do RHEL.
Executar o failover do cluster manualmente
O comando resource move cria uma restrição forçando o recurso a iniciar no nó de destino. Depois de executar o comando move, a execução do recurso clear removerá a restrição para que seja possível mover o recurso novamente ou fazer com que o recurso faça failover automaticamente.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
O exemplo a seguir move o recurso mssqlha para um nó chamado sqlfcivm2e, em seguida, remove a restrição para que o recurso possa ser movido para um nó diferente mais tarde.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Monitorar um serviço de SQL Server num cluster de alta disponibilidade
Exibir o status atual do cluster:
sudo pcs status
Visualize o status ao vivo do cluster e dos recursos:
sudo crm_mon
Exiba os logs do agente de recursos em /var/log/cluster/corosync.log
Adicionar um nó a um cluster
Verifique o endereço IP de cada nó. O script a seguir mostra o endereço IP do nó atual.
ip addr showO novo nó precisa de um nome exclusivo que tenha, no máximo, 15 caracteres. Por padrão, no Red Hat Linux o nome do computador é
localhost.localdomain. Esse nome padrão pode não ser exclusivo e é muito longo. Defina o nome do computador para o novo nó. Defina o nome do computador adicionando-o a/etc/hosts. O script a seguir permite editar/etc/hostscomvi.sudo vi /etc/hostsO exemplo a seguir mostra
/etc/hostscom adições para três nós chamadossqlfcivm1,sqlfcivm2esqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3O arquivo deve ser o mesmo em todos os nós.
Interrompa o serviço SQL Server no novo nó.
Siga as instruções para montar o diretório do arquivo de banco de dados no local compartilhado:
A partir do servidor NFS, instalar
nfs-utils:sudo yum -y install nfs-utilsAbra o firewall dos clientes e do servidor NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadEdite o arquivo
/etc/fstabpara incluir o comando mount:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrExecute
mount -apara que as alterações entrem em vigor.No novo nó, crie um arquivo para armazenar o nome de usuário e a senha do SQL Server para o logon do Pacemaker. O comando a seguir cria e preenche esse arquivo:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdAtenção
Sua senha deve seguir a política de senha de padrão do SQL Server. Por padrão, a senha deve ter pelo menos oito caracteres e conter caracteres de três dos quatro conjuntos a seguir: letras maiúsculas, letras minúsculas, dígitos de base 10 e símbolos. As palavras-passe podem ter até 128 caracteres. Use senhas tão longas e complexas quanto possível.
No novo nó, abra as portas de firewall do Pacemaker. Para abrir essas portas com
firewalld, execute o seguinte comando:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSe você estiver usando outro firewall que não tenha uma configuração interna de alta disponibilidade, as seguintes portas precisarão ser abertas para que o Pacemaker possa se comunicar com outros nós no cluster:
- TCP: portas 2224, 3121, 21064
- UDP: porta 5405
Instale os pacotes do Pacemaker no novo nó.
sudo yum install pacemaker pcs fence-agents-all resource-agentsDefina a senha para o usuário padrão que é criado ao instalar os pacotes Pacemaker e Corosync. Use a mesma senha que os nós existentes.
sudo passwd haclusterAtive e inicie o serviço
pcsde o Pacemaker. Isso permitirá que o novo nó se junte novamente ao cluster após a reinicialização. Execute o seguinte comando no novo nó.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstale o agente de recursos FCI para SQL Server. Execute os seguintes comandos no novo nó.
sudo yum install mssql-server-haNum nó já existente do cluster, autentique o novo nó e adicione-o ao cluster.
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>O exemplo a seguir adiciona um nó chamado vm3 ao cluster.
sudo pcs cluster auth sudo pcs cluster start
Remover nós de um cluster
Para remover um nó de um cluster, execute o seguinte comando:
sudo pcs cluster node remove <nodeName>
Alterar a frequência do intervalo de monitoramento de recursos sqlservr
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
O exemplo a seguir define o intervalo de monitoramento para 2 segundos para o recurso mssql:
sudo pcs resource op monitor interval=2s mssqlha
Solução de problemas do cluster de disco compartilhado Red Hat Enterprise Linux para SQL Server
Quando você soluciona problemas do cluster, isso ajuda a entender como os três daemons trabalham juntos para gerenciar recursos de cluster.
| Daemon | Descrição |
|---|---|
| Corosync | Fornece adesão ao quórum e troca de mensagens entre os nós do cluster. |
| Marcapasso | Reside sobre o Corosync e fornece máquinas de estado para recursos. |
| PCSD | Gerencia o Pacemaker e o Corosync através das ferramentas pcs. |
PCSD deve estar em execução para usar as ferramentas pcs.
Status atual do cluster
sudo pcs status retorna informações básicas sobre o cluster, quorum, nós, recursos e status do daemon para cada nó.
Um exemplo de uma saída de quórum de marcapasso saudável seria:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
No exemplo, partition with quorum significa que um quórum majoritário de nós está online. Se o cluster perder a maioria do quórum de nós, pcs status retornará partition WITHOUT quorum e todos os recursos serão interrompidos.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] retorna o nome de todos os nós que participam atualmente do cluster. Se algum nó não estiver participando, pcs status retornará OFFLINE: [<nodename>].
PCSD Status mostra o status do cluster para cada nó.
Razões pelas quais um nó pode estar offline
Verifique os seguintes itens quando um nó estiver offline.
Firewall
As seguintes portas precisam estar abertas em todos os nós para permitir a comunicação do Pacemaker.
- **TCP: 2224, 3121, 21064
Pacemaker ou serviços Corosync em execução
Comunicação do nó
Mapeamentos de nome de nó