Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) no Linux
SQL Server 2019 (15.x) no Linux
A integração com Python está disponível no SQL Server 2017 e posteriores, quando inclui a opção Python numa instalação de Machine Learning Services (In-Database).
Observação
Atualmente, este artigo aplica-se apenas ao SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) e SQL Server 2019 (15.x) apenas para Linux.
Para desenvolver e implementar soluções Python para SQL Server, instale o revoscalepy da Microsoft e outras bibliotecas Python na sua estação de trabalho de desenvolvimento. A biblioteca revoscalepy, que também está na instância remota do SQL Server, coordena os pedidos de cálculo entre ambos os sistemas.
Neste artigo, aprenda como configurar uma estação de trabalho de desenvolvimento em Python para que possa interagir com um SQL Server remoto habilitado para aprendizagem automática e integração com Python. Depois de completar os passos deste artigo, terá as mesmas bibliotecas Python que as do SQL Server. Também saberás como transferir cálculos de uma sessão Python local para uma sessão Python remota no SQL Server.
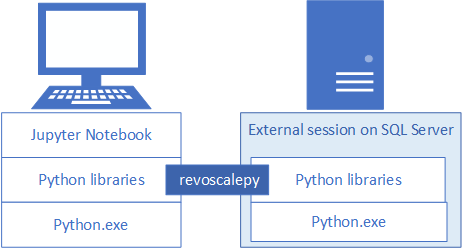
Para validar a instalação, pode usar os Jupyter Notebooks incorporados, conforme descrito neste artigo, ou ligar as bibliotecas ao PyCharm ou a qualquer outro IDE que utilize normalmente.
Sugestão
Para uma demonstração em vídeo destes exercícios, veja Executar R e Python remotamente no SQL Server a partir do Jupyter Notebooks.
Ferramentas comumente usadas
Quer seja um programador Python novo em SQL, ou um programador SQL novo em Python e análise dentro da base de dados, precisará tanto de uma ferramenta de desenvolvimento Python como de um editor de consultas T-SQL, como o SQL Server Management Studio (SSMS), para exercer todas as capacidades da análise dentro da base de dados.
Para desenvolvimento em Python, pode usar o Jupyter Notebooks, que vêm incluídos na distribuição Anaconda instalada pelo SQL Server. Este artigo explica como iniciar o Jupyter Notebooks para que possa executar código Python local e remotamente no SQL Server.
O SSMS é um download separado, útil para criar e executar stored procedures no SQL Server, incluindo aqueles que contêm código Python. Quase qualquer código Python que escrevas no Jupyter Notebooks pode ser incorporado num procedimento armazenado. Pode passar por outros quickstarts para aprender sobre SSMS e Python embutido.
1 - Instalar pacotes Python
As estações de trabalho locais devem ter as mesmas versões dos pacotes Python que as do SQL Server, incluindo a base Anaconda 4.2.0 com distribuição Python 3.5.2, e pacotes específicos da Microsoft.
Um script de instalação adiciona três bibliotecas específicas da Microsoft ao cliente Python. O script instala-se:
- A Revoscalepy é usada para definir objetos fonte de dados e o contexto de computação.
- MicrosoftML fornece algoritmos de aprendizagem automática.
- Azureml aplica-se a tarefas de operacionalização associadas a um contexto de servidor autónomo e pode ser de utilidade limitada para análises dentro da base de dados.
Descarrega um script de instalação. Na página seguinte do GitHub apropriada, selecione Descarregar ficheiro raw.
Install-PyForMLS.ps1 instala a versão 9.2.1 dos pacotes Microsoft Python. Esta versão corresponde a uma instância padrão do SQL Server.
Install-PyForMLS.ps1 instala a versão 9.3 dos pacotes Microsoft Python.
Abra uma janela PowerShell com permissões elevadas de administrador (clique com o botão direito em Executar como administrador).
Vai à pasta onde descarregaste o instalador e executa o script. Adicione o
-InstallFolderargumento da linha de comandos para especificar a localização da pasta para as bibliotecas. Por exemplo:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Se omitir a pasta de instalação, o padrão é %ProgramFiles%\Microsoft\PyForMLS.
A instalação demora algum tempo a concluir. Podes monitorizar o progresso na janela do PowerShell. Quando a configuração estiver concluída, tem um conjunto completo de pacotes.
Sugestão
Recomendamos o FAQ Python para Windows para informações gerais sobre como executar programas Python no Windows.
2 - Localizar executáveis
Ainda no PowerShell, liste o conteúdo da pasta de instalação para confirmar que Python.exe, scripts e outros pacotes estão instalados.
Enter
cd \para ir ao disco raiz e depois introduz o caminho que especificaste no-InstallFolderpasso anterior. Se omitiste este parâmetro durante a instalação, o padrão écd %ProgramFiles%\Microsoft\PyForMLS.Enter
dir *.exepara listar os executáveis. Deves ver python.exe, pythonw.exee uninstall-anaconda.exe.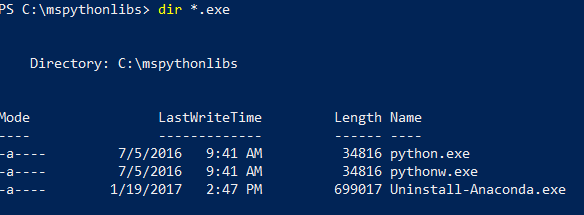
Em sistemas com múltiplas versões de Python, lembra-te de usar este Python.exe em particular se quiseres carregar o revoscalepy e outros pacotes da Microsoft.
Observação
O script de instalação não modifica a variável de ambiente PATH no teu computador, o que significa que o novo interpretador python e os módulos que acabaste de instalar não estão automaticamente disponíveis para outras ferramentas que possas ter. Para ajuda na ligação do interpretador Python e das bibliotecas a ferramentas, consulte Instalar um IDE.
3 - Cadernos de Júpiter Abertos
Anaconda inclui os Jupyter Notebooks. Como passo seguinte, cria um caderno e executa algum código Python com as bibliotecas que acabaste de instalar.
No prompt PowerShell, ainda no
%ProgramFiles%\Microsoft\PyForMLSdiretório, abra os Jupyter Notebooks a partir da pasta Scripts:.\Scripts\jupyter-notebookUm caderno deve abrir-se no seu navegador predefinido em
https://localhost:8889/tree.Outra forma de começar é clicar duas vezesjupyter-notebook.exe.
Selecione Novo e depois selecione Python 3.
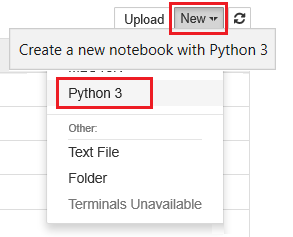
Introduza
import revoscalepye execute o comando para carregar uma das bibliotecas específicas da Microsoft.Introduza e execute
print(revoscalepy.__version__)para devolver a informação da versão. Deves ver a 9.2.1 ou a 9.3.0. Pode usar qualquer uma destas versões com revoscalepy no servidor.Entra em cena uma série mais complexa de afirmações. Este exemplo gera estatísticas resumidas usando rx_summary sobre um conjunto de dados local. Outras funções obtêm a localização dos dados de amostra e criam um objeto fonte de dados para um ficheiro .xdf local.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
A captura de ecrã seguinte mostra a entrada e uma parte da saída, cortadas para maior brevidade.

4 - Obter permissões SQL
Para se ligar a uma instância do SQL Server para executar scripts e carregar dados, deve ter um login válido no servidor da base de dados. Pode usar um login SQL ou autenticação integrada do Windows. Geralmente recomendamos que use autenticação integrada no Windows, mas usar o login SQL é mais simples em alguns cenários, especialmente quando o seu script contém cadeias de ligação a dados externos.
No mínimo, a conta usada para executar código deve ter permissão para ler as bases de dados com as quais está a trabalhar, além da permissão especial EXECUTAR QUALQUER SCRIPT EXTERNO. A maioria dos programadores também necessita de permissões para criar procedimentos armazenados e para escrever dados em tabelas que contenham dados de treino ou pontuação.
Peça ao administrador da base de dados para configurar as seguintes permissões para a sua conta, na base de dados onde usa Python:
- EXECUTE QUALQUER SCRIPT EXTERNO para executar Python no servidor.
- db_datareader privilégios para executar as consultas usadas para treinar o modelo.
- db_datawriter para escrever dados de treino ou dados pontuados.
- db_owner criar objetos como procedimentos armazenados, tabelas, funções. Também precisas db_owner para criar bases de dados de amostras e testes.
Se o seu código requer pacotes que não estejam instalados por defeito no SQL Server, combine com o administrador da base de dados que os pacotes sejam instalados com a instância. O SQL Server é um ambiente seguro e existem restrições sobre onde os pacotes podem ser instalados. A instalação ad hoc de pacotes como parte do seu código não é recomendada, mesmo que tenha direitos. Além disso, considere sempre cuidadosamente as implicações de segurança antes de instalar novos pacotes na biblioteca do servidor.
5 - Criar dados de teste
Se tiver permissões para criar uma base de dados no servidor remoto, pode executar o código seguinte para criar a base de dados demo Iris usada nos passos restantes deste artigo.
5-1 - Criar a base de dados irissql remotamente
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2 - Importar amostra de íris do SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Usar APIs do Revoscalepy para criar uma tabela e carregar os dados Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - Testar ligação remota
Antes de tentares este próximo passo, certifica-te de que tens permissões na instância do SQL Server e uma string de ligação para a base de dados de exemplo Iris. Se a base de dados não existir e tiver permissões suficientes, pode criar uma base de dados usando estas instruções inline.
Substitua a cadeia de ligação por valores válidos. O código de exemplo usa "Server=localhost;Database=irissql;Trusted_Connection=Yes;" , mas o seu código deve especificar um servidor remoto, possivelmente com um nome de instância, e uma opção de credencial que corresponda ao login de uma base de dados.
6-1 Defina uma função
O código seguinte define uma função que irá enviar para o SQL Server numa etapa posterior. Quando executado, utiliza dados e bibliotecas (revoscalepy, pandas, matplotlib) no servidor remoto para criar gráficos de dispersão do conjunto de dados da íris. Devolve o fluxo de bytes da .png de volta ao Jupyter Notebooks para renderizar no navegador.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 Enviar a função para SQL Server
Neste exemplo, crie o contexto de computação remota e depois envie a execução da função para o SQL Server com rx_exec. A função rx_exec é útil porque aceita um contexto computacional como argumento. Qualquer função que queiras executar remotamente deve ter um argumento de contexto de cálculo. Algumas funções, como rx_lin_mod , apoiam este argumento diretamente. Para operações que não o fazem, pode usar rx_exec para entregar o seu código num contexto de computação remota.
Neste exemplo, nenhum dado bruto teve de ser transferido do SQL Server para o Jupyter Notebook. Todos os cálculos ocorrem dentro da base de dados Iris e apenas o ficheiro de imagem é devolvido ao cliente.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
A seguinte captura de ecrã mostra a entrada e o resultado do gráfico de dispersão.

7 - Começar Python a partir de ferramentas
Como os programadores frequentemente trabalham com múltiplas versões de Python, a configuração não adiciona Python ao seu PATH. Para usar o executável Python e as bibliotecas instaladas pela configuração, liga o teu IDE ao Python.exe no caminho que também fornece o revoscalepy e o microsoftml.
Linha de comandos
Quando executasPython.exe a partir %ProgramFiles%\Microsoft\PyForMLS de (ou do local que especificaste para a instalação da biblioteca cliente Python), tens acesso à distribuição completa do Anaconda mais aos módulos Microsoft Python, revoscalepy e microsoftml.
- Vá para
%ProgramFiles%\Microsoft\PyForMLSe execute Python.exe. - Ajuda interativa aberta:
help(). - Digite o nome de um módulo no prompt de ajuda:
help> revoscalepy. A ajuda devolve o nome, conteúdo do pacote, versão e localização do ficheiro. - Versão de devolução e informações sobre a embalagem no prompt de ajuda> :
revoscalepy. Prima a tecla Enter algumas vezes para sair da ajuda. - Importar um módulo:
import revoscalepy.
Cadernos Jupyter
Este artigo utiliza Jupyter Notebooks incorporados para demonstrar chamadas de funções para revoscalepy. Se és novo nesta ferramenta, a captura de ecrã seguinte ilustra como as peças encaixam e porque é que tudo "simplesmente funciona".
A pasta %ProgramFiles%\Microsoft\PyForMLS principal contém o Anaconda mais os pacotes Microsoft. O Jupyter Notebooks está incluído no Anaconda, na pasta Scripts, e os executáveis em Python são automaticamente registados no Jupyter Notebooks. Os pacotes encontrados em site-packages podem ser importados para um caderno, incluindo os três pacotes da Microsoft usados para ciência de dados e aprendizagem automática.
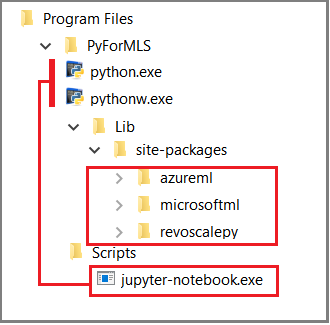
Se estiveres a usar outro IDE, terás de ligar os executáveis Python e as bibliotecas de funções à tua ferramenta. As secções seguintes fornecem instruções para as ferramentas mais usadas.
Visual Studio
Se tiver Python no Visual Studio, use as seguintes opções de configuração para criar um ambiente Python que inclua os pacotes Microsoft Python.
| Definição de configuração | valor |
|---|---|
| Caminho do prefixo | %ProgramFiles%\Microsoft\PyForMLS |
| Caminho do intérprete | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Intérprete em modo de janela | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Para ajuda na configuração de um ambiente Python, consulte Gestão de ambientes Python no Visual Studio.
PyCharm
No PyCharm, defina o interpretador para o executável Python instalado.
Num novo projeto, nas Definições, selecione Adicionar Local.
Introduza
%ProgramFiles%\Microsoft\PyForMLS\.
Agora pode importar revoscalepy, microsoftml ou azureml. Também pode escolher Tools>Python Console para abrir uma janela interativa.