Diagnosticar e resolver contenções de trava no SQL Server
Este guia descreve como identificar e resolver problemas de contenção de trava observados durante a execução de aplicativos do SQL Server em sistemas de alta simultaneidade com algumas cargas de trabalho.
À medida que o número de núcleos de CPU nos servidores continua aumentando, o aumento associado na simultaneidade pode introduzir pontos de contenção em estruturas de dados que precisam ser acessadas de maneira serial no mecanismo de banco de dados. Isso vale especialmente para cargas de trabalho de processamento de transações (OLTP) com alta taxa de transferência/alta simultaneidade. Há diversas ferramentas, técnicas e maneiras de abordar esses desafios, bem como práticas que podem ser seguidas na criação de aplicativos que podem ajudar a evitá-los completamente. Este artigo abordará um tipo específico de contenção em estruturas de dados que usam spinlocks para serializar o acesso a essas estruturas de dados.
Observação
Esse conteúdo foi escrito pela equipe de SQLCAT (Equipe de Consultoria ao Cliente do Microsoft SQL Server) com base em seu processo de identificação e resolução de problemas relacionados à contenção da trava de página em aplicativos SQL Server em sistemas de alta simultaneidade. As recomendações e práticas recomendadas documentadas aqui são baseadas em experiências reais durante o desenvolvimento e a implantação de sistemas OLTP reais.
O que é a contenção de trava do SQL Server?
Travas são primitivos de sincronização leves usados pelo mecanismo do SQL Server para garantir a consistência das estruturas na memória, incluindo índices, páginas de dados e estruturas internas (como páginas não folha em uma Árvore B). O SQL Server usa travas de buffer para proteger páginas no pool de buffers e travas de E/S para proteger páginas ainda não carregadas no pool de buffers. Sempre que dados são gravados ou lidos de uma página no pool de buffers do SQL Server, um thread de trabalho precisa adquirir uma trava de buffer para a página primeiro. Vários tipos de trava de buffer estão disponíveis para acessar páginas no pool de buffers, incluindo a trava exclusiva (PAGELATCH_EX) e a trava compartilhada (PAGELATCH_SH). Quando o SQL Server tenta acessar uma página que ainda não está presente no pool de buffers, uma E/S assíncrona é postada para carregar a página no pool de buffers. Se o SQL Server precisar esperar que o subsistema de E/S responda, ele aguardará uma trava de E/S exclusiva (PAGEIOLATCH_EX) ou compartilhada (PAGEIOLATCH_SH), dependendo do tipo de solicitação. Isso é feito para impedir que outro thread de trabalho carregue a mesma página no pool de buffers com uma trava incompatível. As travas também são usadas para proteger o acesso a estruturas de memória internas que não sejam as páginas do pool de buffers; elas são conhecidas como "travas de não buffer".
A contenção em travas de página é o cenário mais comum encontrado em sistemas com várias CPUs e, portanto, a maior parte deste artigo se concentrará nelas.
A contenção de trava ocorre quando vários threads tentam adquirir simultaneamente travas incompatíveis na mesma estrutura na memória. Como uma trava é um mecanismo de controle interno, o mecanismo do banco de dados SQL determina automaticamente quando usá-las. Uma vez que o comportamento das travas é determinístico, as decisões do aplicativo, incluindo o design de esquema, podem afetar esse comportamento. Este artigo tem a finalidade de fornecer as seguintes informações:
- Informações de contexto sobre como as travas são usadas pelo SQL Server.
- Ferramentas usadas para investigar a contenção de trava.
- Como determinar se a quantidade de contenção observada é problemática.
Discutiremos alguns cenários comuns e a melhor maneira de lidar com eles para aliviar a contenção.
Como o SQL Server usa travas?
Uma página no SQL Server tem 8 KB e pode armazenar várias linhas. Para aumentar a simultaneidade e o desempenho, as travas de buffer são mantidas apenas pela duração da operação física na página, diferentemente dos bloqueios, que são mantidos pela duração da transação lógica.
As travas são internas ao mecanismo do SQL e são usadas para fornecer consistência de memória, enquanto os bloqueios são usados pelo SQL Server para fornecer consistência transacional lógica. A seguinte tabela compara travas e bloqueios:
| Estrutura | Finalidade | Controlada por | Custo de desempenho | Exposta por |
|---|---|---|---|---|
| Trava | Garantir a consistência das estruturas na memória. | Somente mecanismo do SQL Server. | O custo de desempenho é baixo. Para permitir que haja simultaneidade máxima e fornecer desempenho máximo, as travas são mantidas apenas pela duração da operação física na estrutura na memória, diferentemente dos bloqueios, que são mantidos pela duração da transação lógica. | sys.dm_os_wait_stats (Transact-SQL) – fornece informações sobre os tipos de espera de PPAGELATCH, PAGEIOLATCH e LATCH (LATCH_EX LATCH_SH é usado para agrupar todos os tempos de espera de trava não buffer). sys.dm_os_latch_stats (Transact-SQL) – fornece informações detalhadas sobre os tempos de espera de trava não buffer. sys.dm_db_index_operational_stats (Transact-SQL) – essa DMV fornece esperas agregadas para cada índice, o que é útil para solucionar problemas de desempenho relacionados a travas. |
| Lock | Garantir a consistência das transações. | Pode ser controlado pelo usuário. | O custo de desempenho é alto em relação às travas, pois os bloqueios precisam ser mantidos durante a transação. | sys.dm_tran_locks (Transact-SQL). sys.dm_exec_sessions (Transact-SQL). |
Compatibilidade e modos de trava do SQL Server
É esperado que haja alguma contenção de trava como parte normal da operação do mecanismo do SQL Server. É inevitável que várias solicitações de trava simultâneas, com compatibilidades variadas, ocorram em um sistema de alta simultaneidade. O SQL Server impõe a compatibilidade de travas exigindo que as solicitações de trava incompatíveis aguardem em uma fila até que as solicitações de trava pendentes sejam concluídas.
Há cinco modos diferentes de aquisição de travas, que estão relacionados ao nível de acesso. Os modos de trava do SQL Server podem ser resumidos da seguinte maneira:
KP – trava de manutenção, garante que a estrutura referenciada não possa ser destruída. Usado quando um thread deseja examinar uma estrutura de buffer. Como a trava KP é compatível com todas as travas, exceto pela trava de destruição (DT), ela é considerada "leve", o que significa que o impacto sobre o desempenho ao usá-la é mínimo. Como a trava KP é incompatível com a trava DT, ela impede que qualquer outro thread destrua a estrutura referenciada. Por exemplo, uma trava KP impede que a estrutura que referencia seja destruída pelo processo lazywriter. Para obter mais informações sobre como o processo lazywriter é usado com o gerenciamento de páginas de buffer do SQL Server, confira Gravando páginas.
SH – trava compartilhada, necessária para ler a estrutura referenciada (por exemplo, ler uma página de dados). Vários threads podem acessar simultaneamente um recurso para leitura em uma trava compartilhada.
UP – trava de atualização, é compatível com SH (trava compartilhada) e KP, mas com nenhuma outra e, portanto, não permite que uma trava EX grave na estrutura referenciada.
EX – trava exclusiva, impede que outros threads gravem e leiam na estrutura referenciada. Um exemplo de uso seria modificar o conteúdo de uma página para proteção de página interrompida.
DT – trava de destruição, deve ser adquirida antes de destruir o conteúdo da estrutura referenciada. Por exemplo, uma trava DT precisa ser adquirida pelo processo lazywriter para liberar uma página limpa antes de adicioná-la à lista de buffers livres disponíveis para uso por outros threads.
Os modos de trava têm níveis diferentes de compatibilidade, por exemplo, uma trava compartilhada (SH) é compatível com uma trava de atualização (UP) ou de manutenção (KP), mas é incompatível com uma trava de destruição (DT). Várias travas podem ser adquiridas simultaneamente na mesma estrutura, desde que sejam compatíveis. Quando um thread tenta adquirir uma trava em um modo que não é compatível, ela é colocada em uma fila para aguardar um sinal indicando que o recurso está disponível. Um spinlock do tipo SOS_Task é usado para proteger a fila de espera impondo o acesso serializado à fila. Esse spinlock deve ser adquirido para adicionar itens à fila. O spinlock SOS_Task também sinaliza aos threads na fila quando travas incompatíveis são liberadas, permitindo que os threads em espera adquiram uma trava compatível e continuem funcionando. A fila de espera é processada de maneira PEPS (primeiro a entrar, primeiro a sair) conforme as solicitações de trava são liberadas. As travas seguem esse sistema PEPS para garantir a imparcialidade e para evitar a privação dos threads.
A compatibilidade dos modos de trava é listada na seguinte tabela (S indica compatibilidade e N, incompatibilidade):
| Modo de trava | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | N | N | N | Y | N |
| SH | N | N | Y | N | N |
| UP | N | Y | N | N | N |
| EX | N | N | N | N | N |
| DT | N | N | N | N | N |
SuperLatches e subtravas do SQL Server
Com a crescente presença de sistemas com vários soquetes e vários núcleos baseados em NUMA, o SQL Server 2005 introduziu as SuperLatches, também conhecidas como subtravas, que são eficazes somente em sistemas com 32 ou mais processadores lógicos. As SuperLatches aumentam a eficiência do mecanismo SQL para determinados padrões de uso em cargas de trabalho OLTP altamente simultâneas; por exemplo, quando determinadas páginas têm um padrão de acesso SH (compartilhado) somente leitura, mas raramente são gravadas. Um exemplo de página com esse padrão de acesso é uma página raiz de árvore B (ou seja, um índice). O mecanismo SQL requer que uma trava compartilhada seja mantida na página raiz quando uma divisão de página ocorrer em qualquer nível da árvore B. Em uma carga de trabalho OLTP de alta simultaneidade e com uso intenso de inserções, o número de divisões de página aumentará amplamente em paralelo com a taxa de transferência, o que pode prejudicar o desempenho. As SuperLatches podem permitir um aumento no desempenho para o acesso a páginas compartilhadas, em que vários threads de trabalho de execução simultânea exigem travas de SH. Para fazer isso, o mecanismo do SQL Server promove dinamicamente uma trava em uma página a uma SuperLatch. Uma SuperLatch particiona uma trava em uma matriz de estruturas de subtrava, com uma subtrava por partição por núcleo de CPU, em que a trava principal se torna um redirecionador de proxy e a sincronização de estado global não é necessária para travas somente leitura. Ao fazer isso, a função de trabalho, que sempre é atribuída a uma CPU específica, só precisa adquirir a subtrava compartilhada (SH) atribuída ao agendador local.
Observação
A documentação usa o termo árvore B geralmente em referência a índices. Em índices de rowstore, o Database Engine implementa uma árvore B+. Isso não se aplica a índices columnstore ou índice em tabelas com otimização de memória. Para obter mais informações, confira o Guia de arquitetura e design do índice do SQL Server e SQL do Azure.
A aquisição de travas compatíveis, como uma SuperLatch compartilhada, usa menos recursos e dimensiona o acesso a páginas quentes melhor do que uma trava compartilhada não particionada, pois a remoção do requisito de sincronização do estado global aprimora significativamente o desempenho ao acessar somente a memória NUMA local. Por outro lado, a aquisição de uma SuperLatch exclusiva (EX) é mais cara do que a aquisição de uma trava EX comum, uma vez que o SQL precisa sinalizar todas as subtravas. Quando é observado que uma SuperLatch usa um padrão de acesso EX pesado, o mecanismo do SQL pode rebaixá-la após a página ser descartada do pool de buffers. O seguinte diagrama ilustra uma trava normal e uma SuperLatch particionada:

Use o objeto SQL Server:Latches e os contadores associados no Monitor de Desempenho para reunir informações sobre as SuperLatches, incluindo o número de SuperLatches, as promoções de SuperLatches por segundo e os rebaixamentos de SuperLatch por segundo. Para saber mais sobre o objeto SQL Server:Latches e os contadores associados, confira Objeto SQL Server, Latches.
Tipos de tempo de espera de trava
Informações de espera cumulativas são monitoradas pelo SQL Server e podem ser acessadas usando a Exibição de gerenciamento dinâmico (DMW) sys.dm_os_wait_stats. O SQL Server emprega três tipos de tempo de espera de trava, conforme definido pelo elemento wait_type correspondente na DMV sys.dm_os_wait_stats:
Trava de buffer (BUF): usada para garantir a consistência das páginas de dados e índice para objetos de usuário. Também são usadas para proteger o acesso a páginas de dados que o SQL Server usa para objetos do sistema. Por exemplo, páginas que gerenciam alocações são protegidas por travas de buffer. Elas incluem as páginas PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) e IAM (Index Allocation Map). As travas de buffer são relatadas em
sys.dm_os_wait_statscom umwait_typede PAGELATCH_*.Trava de não buffer (Non-BUF): usada para garantir a consistência de qualquer estrutura na memória, exceto pelas páginas de pool de buffers. Todas as esperas por travas de não buffer serão relatadas como um
wait_typede LATCH_*.Trava de E/S: um subconjunto de travas de buffer que garantem a consistência das mesmas estruturas protegidas pelas travas de buffer quando essas estruturas exigem o carregamento no pool de buffers com uma operação de E/S. As travas de E/S impedem que outro thread carregue a mesma página no pool de buffers com uma trava incompatível. Associado a um
wait_typede PAGEIOLATCH_*.Observação
Quando você vê esperas de PAGEIOLATCH significativas, isso significa que o SQL Server está aguardando o subsistema de E/S. Embora seja esperado um número de esperas de PAGEIOLATCH e seja um comportamento normal, se o tempo médio de espera de PAGEIOLATCH estiver consistentemente acima de 10 milissegundos (MS), investigue por que o subsistema de E/S está sob pressão.
Se ao examinar a DMV sys.dm_os_wait_stats você encontrar travas de não buffer, sys.dm_os_latch_stats precisará ser examinado para obter um detalhamento de informações de espera cumulativas para travas de não buffer. Todos os tempos de espera de trava de buffer são classificados na classe de trava BUFFER, sendo os restantes usados para classificar travas de não buffer.
Sintomas e causas da contenção de trava no SQL Server
Em um sistema ocupado e com alta simultaneidade, é normal ver contenção ativa em estruturas que são acessadas com frequência e são protegidas por travas e por outros mecanismos de controle no SQL Server. É considerado problemático quando a contenção e o tempo de espera associado à aquisição da trava para uma página são suficientes para reduzir a utilização de recursos (CPU), o que prejudica a taxa de transferência.
Exemplo de contenção de trava
No diagrama a seguir, a linha azul representa a taxa de transferência no SQL Server, conforme medida pelas Transações por segundo; a linha preta representa o tempo médio de espera da trava da página. Nesse caso, cada transação executa um INSERT em um índice clusterizado com um valor inicial que aumenta sequencialmente, por exemplo, ao popular uma coluna IDENTITY com o tipo de dados bigint. Conforme o número de CPUs aumenta para 32, fica evidente que a taxa de transferência geral diminuiu e que o tempo de espera de trava da página aumentou para aproximadamente 48 milissegundos, conforme evidenciado pela linha preta. Essa relação inversa entre a taxa de transferência e o tempo de espera de trava da página é um cenário comum que é facilmente diagnosticado.

Desempenho quando a contenção de trava é resolvida
Como ilustra o diagrama a seguir, o SQL Server deixa de sofrer gargalos com os tempos de espera de trava de página e a taxa de transferência aumenta em 300%, conforme medido pelas transações por segundo. Isso foi feito usando a técnica Usar o particionamento de hash com uma coluna computada, descrita posteriormente neste artigo. Esse aprimoramento de desempenho é voltado para sistemas com um alto número de núcleos e um alto nível de simultaneidade.

Fatores que afetam a contenção de trava
Normalmente, a contenção de trava que prejudica o desempenho em ambientes OLTP é causada por uma alta simultaneidade relacionada a um ou mais dos seguintes fatores:
| Fator | Detalhes |
|---|---|
| Alto número de CPUs lógicas usadas pelo SQL Server | A contenção de trava pode ocorrer em qualquer sistema de vários núcleos. Segundo a experiência do SQLCAT, a contenção de trava excessiva, que afeta o desempenho do aplicativo além dos níveis aceitáveis, normalmente é observada em sistemas com mais de 16 núcleos de CPU e pode aumentar à medida que núcleos adicionais são disponibilizados. |
| Design de esquema e padrões de acesso | A profundidade da árvore B, o design de índice clusterizado e não clusterizado, o tamanho e a densidade das linhas por página e os padrões de acesso (atividade de leitura/gravação/exclusão) são fatores que podem contribuir para o excesso de contenção de trava na página. |
| Alto grau de simultaneidade no nível do aplicativo | Normalmente, o excesso de contenção de trava da página ocorre em conjunto com um alto nível de solicitações simultâneas da camada de aplicativo. Há algumas práticas de programação que também podem introduzir um grande número de solicitações para uma página específica. |
| Layout dos arquivos lógicos usados pelos bancos de dados do SQL Server | O layout do arquivo lógico pode afetar o nível de contenção de trava da página causado pelas estruturas de alocação, como as páginas FPS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) e IAM (Index Allocation Map). Para obter mais informações, confira Monitoramento e solução de problemas do TempDB: gargalo de alocação. |
| Desempenho do subsistema de E/S | Esperas de PAGEIOLATCH significativas indicam que o SQL Server está aguardando o subsistema de E/S. |
Diagnosticando a contenção de trava no SQL Server
Esta seção fornece informações para diagnosticar a contenção de trava no SQL Server a fim de determinar se ela é problemática para seu ambiente.
Ferramentas e métodos para diagnosticar a contenção de trava
As principais ferramentas usadas para diagnosticar a contenção de trava são:
O Monitor de Desempenho, para monitorar a utilização da CPU e os tempos de espera dentro do SQL Server e estabelecer se há uma relação entre a utilização da CPU e os tempos de espera de trava.
As DMVs do SQL Server, que podem ser usadas para determinar o tipo específico de trava que está causando o problema e o recurso afetado.
Em alguns casos, despejos de memória do processo do SQL Server precisam ser obtidos e analisados com as ferramentas de depuração do Windows.
Observação
Geralmente, esse nível avançado de solução de problemas é necessário apenas ao solucionar problemas de contenção de trava de não buffer. Talvez você queira envolver o Serviço de Suporte de Produto da Microsoft para esse tipo de solução de problemas avançada.
O processo técnico para diagnosticar a contenção de trava pode ser resumido nas seguintes etapas:
Determinar se há uma contenção que pode estar relacionada a uma trava.
Use as exibições DMV fornecidas no Apêndice: scripts de contenção de trava do SQL Server para determinar o tipo de trava e os recursos afetados.
Aliviar a contenção usando uma das técnicas descritas em Lidando com a contenção de trava em diferentes padrões de tabela.
Indicadores de contenção de trava
Conforme mencionado anteriormente, a contenção de trava é problemática apenas quando a contenção e o tempo de espera associado à aquisição de travas de página impedem o aumento da taxa de transferência quando recursos de CPU estão disponíveis. Determinar uma quantidade aceitável de contenção requer uma abordagem holística, que considere os requisitos de desempenho e taxa de transferência em conjunto com os recursos de CPU e E/S disponíveis. Esta seção descreve como determinar o impacto da contenção de trava sobre a carga de trabalho da seguinte maneira:
Meça os tempos de espera gerais durante um teste representativo.
Classifique sua ordem.
Determine a proporção daqueles que estão relacionados a travas.
Informações de espera cumulativas estão disponíveis a partir do DMV sys.dm_os_wait_stats. O tipo mais comum de contenção de trava é a contenção de trava de buffer, observada como um aumento nos tempos de espera para travas com um wait_type de PAGELATCH_*. Travas de não buffer são agrupadas sob o tipo de espera LATCH*. Como ilustra o diagrama a seguir, você deve, primeiramente, fazer uma análise cumulativa das esperas do sistema usando a DMV sys.dm_os_wait_stats para determinar o percentual do tempo de espera geral causado por travas de buffer e de não buffer. Se você encontrar travas de não buffer, a DMV sys.dm_os_latch_stats também deverá ser examinada.
O diagrama a seguir descreve a relação entre as informações retornadas pelas DMVs sys.dm_os_wait_stats e sys.dm_os_latch_stats.

Para obter mais informações sobre a DMV sys.dm_os_wait_stats, veja sys.dm_os_wait_stats (Transact-SQL) na ajuda do SQL Server.
Para obter mais informações sobre a DMV sys.dm_os_latch_stats, veja sys.dm_os_latch_stats (Transact-SQL) na ajuda do SQL Server.
As seguintes medidas de tempo de espera de trava são indicadores de que o excesso de contenção de trava está afetando o desempenho do aplicativo:
O tempo de espera de trava médio da página aumentam consistentemente com a produtividade: se os tempos de espera de trava médios aumentarem consistentemente com a produtividade e se os tempos de espera de trava médio de buffer também aumentarem para além dos tempos de resposta de disco esperados, examine as tarefas de espera atuais usando a DMV
sys.dm_os_waiting_tasks. As médias podem ser enganosas quando analisadas isoladamente, portanto, é importante observar o sistema em atividade quando possível para entender as características da carga de trabalho. Em particular, verifique se os tempos de espera são altos em solicitações de PAGELATCH_EX e/ou PAGELATCH_SH em qualquer página. Siga estas etapas para diagnosticar um aumento nos tempos médios de espera de trava com a taxa de transferência:- Use os scripts de exemplo Consultar sys.dm_os_waiting_tasks ordenadas pela ID da Sessão ou Calcular esperas ao longo de um período para examinar as tarefas atuais com espera e medir o tempo de espera médio de trava.
- Use o script de exemplo Consultar descritores de buffer para determinar objetos que causam contenção de trava para determinar o índice e a tabela subjacente em que a contenção está ocorrendo.
- Meça o tempo de espera de trava médio usando o contador do Monitor de Desempenho MSSQL%InstanceName%\Estatísticas de espera\Página de tempo de espera\Tempo de espera médio ou executando a DMV
sys.dm_os_wait_stats.
Observação
Para calcular o tempo de espera médio de um tipo de espera específico (retornado por
sys.dm_os_wait_statscomo wt_:type), divida o tempo de espera total (retornado comowait_time_ms) pelo número de tarefas em espera (retornado comowaiting_tasks_count).Percentual do tempo de espera total gasto em tipos de espera de trava durante o pico de carga: se o tempo de espera de trava médio como um percentual do tempo de espera geral aumentar em paralelo com a carga de aplicação, a contenção de trava poderá estar afetando o desempenho e deverá ser investigada.
Meça os tempos de espera de trava de página e os tempos de espera de trava que não são de página com os contadores de desempenho Objeto SQLServer:Wait Statistics. Em seguida, compare os valores desses contadores de desempenho com os contadores de desempenho associados à CPU, à E/S, à memória e à taxa de transferência de rede. Por exemplo, transações/s e solicitações em lote/s são duas boas medidas de utilização de recursos.
Observação
O tempo de espera relativo para cada tipo de espera não está incluído na DMV
sys.dm_os_wait_statsporque essa DMV mede os tempos de espera desde a última vez que a instância do SQL Server foi iniciada ou que as estatísticas de espera cumulativas foram redefinidas usando o DBCC SQLPERF. Para calcular o tempo de espera relativo para cada tipo de espera, faça um instantâneo desys.dm_os_wait_statsantes e depois da carga de pico e calcule a diferença. O script de exemplo Calcular esperas ao longo de um período pode ser usado para essa finalidade.Para um ambiente que não é de produção apenas, limpe a
sys.dm_os_wait_statsDMV com o seguinte comando:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')Um comando semelhante pode ser executado para limpar a DMV
sys.dm_os_latch_stats:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')A produtividade não aumenta e, em alguns casos, diminui conforme a carga de aplicação aumenta e o número de CPUs disponíveis para o SQL Server aumenta: isso foi ilustrado no Exemplo de contenção da trava.
A utilização da CPU não aumenta de acordo com o aumento da carga de trabalho aplicada: se a utilização da CPU no sistema não aumentar conforme a simultaneidade gerada pela produtividade aplicada aumentar, esse será um indicador de que o SQL Server está aguardando algo e um sintoma de contenção de trava.
Analise a causa raiz. Mesmo que cada uma das condições anteriores seja verdadeira, ainda é possível que a causa raiz dos problemas de desempenho esteja em outro lugar. Na verdade, na maioria dos casos, a utilização de CPU abaixo do ideal é causada por outros tipos de espera, como bloqueios de travas, esperas relacionadas à E/S ou problemas relacionados à rede. Como regra prática, é sempre melhor resolver a espera do recurso que representa a maior proporção do tempo de espera geral antes de prosseguir com uma análise mais detalhada.
Analisando travas de buffer de espera atuais
A contenção de trava do buffer é manifestada como um aumento nos tempos de espera para travas com um wait_type de PAGELATCH_* ou PAGEIOLATCH_*, conforme exibido na DMV sys.dm_os_wait_stats. Para ver o sistema em tempo real, execute a seguinte consulta em um sistema para ingressar nas DMVs sys.dm_os_wait_stats, sys.dm_exec_sessions e sys.dm_exec_requests. Os resultados podem ser usados para determinar o tipo de espera atual para as sessões em execução no servidor.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc

As estatísticas expostas por essa consulta serão descritas da seguinte maneira:
| Estatística | Descrição |
|---|---|
| Session_id | ID da sessão associada à tarefa. |
| Wait_type | O tipo de espera que o SQL Server registrou no mecanismo, que está impedindo que uma solicitação atual seja executada. |
| Last_wait_type | Se esta solicitação tiver sido previamente bloqueada, esta coluna retornará o tipo da última espera. Não permite valor nulo. |
| Wait_duration_ms | O tempo de espera total em milissegundos gasto com esse tipo de espera desde que a instância do SQL Server foi iniciada ou desde que as estatísticas de espera cumulativas foram redefinidas. |
| Blocking_session_id | ID da sessão que está bloqueando a solicitação. |
| Blocking_exec_context_id | ID do contexto de execução associado à tarefa. |
| Resource_description | A coluna resource_description lista a página exata que está sendo aguardada no formato: <database_id>:<file_id>:<page_id> |
A seguinte consulta retornará informações sobre todas as travas de não buffer:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;

As estatísticas expostas por essa consulta serão descritas da seguinte maneira:
| Estatística | Descrição |
|---|---|
| latch_class | O tipo de trava que o SQL Server registrou no mecanismo, que está impedindo que uma solicitação atual seja executada. |
| waiting_requests_count | Número de esperas por travas nessa classe desde o SQL Server foi reiniciado. O contador é incrementado no início de uma espera de trava. |
| wait_time_ms | O tempo de espera total em milissegundos gasto aguardando esse tipo de trava. |
| max_wait_time_ms | Tempo máximo em milissegundos que qualquer solicitação gastou aguardando esse tipo de trava. |
Observação
Os valores retornados por essa DMV são cumulativos desde a última vez que o mecanismo de banco de dados foi reiniciado ou que a DMV foi redefinida. Use a coluna sqlserver_start_time em sys.dm_os_sys_info para localizar a última hora de inicialização do mecanismo de banco de dados. Em um sistema que está sendo executado há muito tempo, isso significa que algumas estatísticas, como max_wait_time_ms, raramente são úteis. O seguinte comando pode ser usado para redefinir as estatísticas de espera para essa DMV:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Cenários de contenção de trava do SQL Server
Observou-se que os cenários a seguir causam excesso de contenção de trava.
Contenção de inserção de última página/página à direita
Uma prática de OLTP comum é criar um índice clusterizado em uma coluna de identidade ou data. Isso ajuda a manter uma boa organização física do índice, que pode beneficiar muito o desempenho de leituras e gravações nele. No entanto, esse design de esquema pode levar à contenção de trava de maneira não intencional. Esse problema é visto com mais frequência em tabelas grandes com linhas pequenas, bem como em inserções em um índice que contém uma coluna de chave à esquerda que aumenta sequencialmente, como um inteiro crescente ou uma chave de data e hora. Nesse cenário, o aplicativo raramente (ou nunca) executa atualizações ou exclusões, sendo a exceção as operações de arquivamento.
No exemplo a seguir, os threads um e dois desejam executar uma inserção de um registro que será armazenado na página 299. De uma perspectiva de bloqueio lógica, não há nenhum problema, pois serão usados bloqueios no nível da linha e bloqueios exclusivos em nos dois registros na mesma página podem ser mantidos ao mesmo tempo. No entanto, para garantir a integridade da memória física, apenas um thread por vez pode adquirir uma trava exclusiva, para que o acesso à página seja serializado a fim de evitar a perda de atualizações na memória. Nesse caso, o thread 1 adquire a trava exclusiva e o thread 2 espera, registrando uma espera de PAGELATCH_EX para esse recurso nas estatísticas de espera. Isso é exibido por meio do valor wait_type na DMV sys.dm_os_waiting_tasks.

Essa contenção é conhecida como contenção de "Inserção de última página", porque ocorre na borda na extrema direita da árvore B, conforme exibido no seguinte diagrama:

Esse tipo de contenção de trava pode ser explicado da maneira a seguir. Quando uma nova linha é inserida em um índice, o SQL Server usa o seguinte algoritmo para executar a modificação:
Percorrer a árvore B para localizar a página correta para manter o novo registro.
Travar a página com PAGELATCH_EX, impedindo que outras pessoas a modifiquem, e adquirir travas compartilhadas (PAGELATCH_SH) em todas as páginas não folha.
Observação
Em alguns casos, o Mecanismo do SQL requer que travas EX sejam adquiridas também nas páginas de árvore B não folha. Por exemplo, quando uma divisão de página ocorre, todas as páginas que forem afetadas diretamente precisarão ser travadas exclusivamente (PAGELATCH_EX).
Registrar uma entrada de log indicando que a linha foi modificada.
Adicionar a linha à página e marcar a página como suja.
Destravar todas as páginas.
Se o índice da tabela for baseado em uma chave com aumento sequencial, cada nova inserção irá para a mesma página no final da árvore B, até que essa página fique cheia. Em cenários de alta simultaneidade, isso pode causar contenção na borda na extrema direita da árvore B e pode ocorrer em índices clusterizados e não clusterizados. As tabelas afetadas por esse tipo de contenção primariamente aceitam INSERÇÕEs, e as páginas para os índices problemáticos costumam ser relativamente densas (por exemplo, um tamanho de linha de cerca de 165 bytes (incluindo a sobrecarga de linha) é igual a cerca de 49 linhas por página). Nesse exemplo com uso intenso de inserções, é esperado que ocorram esperas de PAGELATCH_EX/PAGELATCH_SH, e essa é a observação típica. Para examinar os tempos de espera de trava de Página versus tempos de espera de trava de Página de Árvore, use a sys.dm_db_index_operational_stats DMV.
A seguinte tabela seguir resume os principais fatores observados com esse tipo de contenção de trava:
| Fator | Observações típicas |
|---|---|
| CPUs lógicas em uso pelo SQL Server | Esse tipo de contenção de trava ocorre principalmente em sistemas com 16 ou mais núcleos de CPU e, mais comumente, em sistemas com 32 ou mais núcleos de CPU. |
| Design de esquema e padrões de acesso | Usa um valor de identidade com aumento sequencial como coluna inicial em um índice em uma tabela para dados transacionais. O índice tem uma chave primária crescente com uma alta taxa de inserções. O índice tem pelo menos um valor de coluna com crescimento sequencial. Normalmente, tamanho de linha pequeno com muitas linhas por página. |
| Tipo de espera observado | Muitos threads competindo pelo mesmo recurso com tempos de espera de trava EX (exclusiva) ou SH (compartilhada) associados à mesma resource_description na DMV sys.dm_os_waiting_tasks, conforme retornado por Consultar sys.dm_os_waiting_tasks ordenado pela duração da espera. |
| Fatores de design a considerar | Considere alterar a ordem das colunas do índice, conforme descrito na Estratégia de mitigação de índice não sequencial, se você puder garantir que as inserções serão distribuídas pela árvore B de maneira uniforme o tempo todo. Se a Estratégia de mitigação da partição de hash for usada, ela removerá a capacidade de usar o particionamento para qualquer outra finalidade, como o arquivamento de janelas deslizantes. O uso da estratégia de Mitigação de partição hash pode levar a problemas de eliminação de partição para consultas SELECT usadas pelo aplicativo. |
Contenção de trava em tabelas pequenas com um índice não clusterizado e inserções aleatórias (tabela de fila)
Esse cenário geralmente é visto quando uma tabela SQL é usada como uma fila temporária (por exemplo, em um sistema de mensagens assíncrono).
Nesse cenário, contenções de trava exclusiva (EX) e compartilhada (SH) podem ocorrer nas seguintes condições:
- As operações de inserção, seleção, atualização ou exclusão ocorrem com alta simultaneidade.
- O tamanho da linha é relativamente pequeno (levando a páginas densas).
- O número de linhas na tabela é relativamente pequeno, levando a uma árvore B superficial, definida por uma profundidade de índice de dois ou três.
Observação
Até mesmo árvores B com uma profundidade maior que essa podem sofrer contenção com esse tipo de padrão de acesso, quando a frequência da DML (linguagem de manipulação de dados) e a simultaneidade do sistema são altas o suficiente. O nível de contenção de trava poderá se tornar pronunciado conforme a simultaneidade aumentar, quando 16 ou mais núcleos de CPU estiverem disponíveis para o sistema.
A contenção de trava pode ocorrer mesmo quando o acesso é aleatório na árvore B, por exemplo, quando uma coluna não sequencial é a chave inicial em um índice clusterizado. A captura de tela a seguir é de um sistema que está apresentando esse tipo de contenção de trava. Nesse exemplo, a contenção é decorrente da densidade de páginas causada por um tamanho de linha pequeno e por uma árvore B relativamente superficial. Conforme a simultaneidade aumenta, a contenção de trava nas páginas ocorre mesmo quando as inserções são aleatórias na árvore B, já que um GUID era a coluna inicial do índice.
Na captura de tela a seguir, as esperas ocorrem nas páginas de dados do buffer e nas páginas PFS (Pages Free Space). Para obter mais informações sobre contenção de trava em página PFS, confira a seguinte postagem no blog de terceiros no SQLskills: Benchmarking: vários arquivos de dados nos SSDs. Mesmo quando o número de arquivos de dados aumentou, a contenção de trava permaneceu predominante nas páginas de dados de buffer.

A seguinte tabela seguir resume os principais fatores observados com esse tipo de contenção de trava:
| Fator | Observações típicas |
|---|---|
| CPUs lógicas em uso pelo SQL Server | A contenção de trava ocorre principalmente em computadores com 16 ou mais núcleos de CPU. |
| Design de esquema e padrões de acesso | Alta taxa de padrões de acesso de inserção/seleção/atualização/exclusão em tabelas pequenas. Árvore B superficial (profundidade de índice de dois ou três). Tamanho de linha pequeno (muitos registros por página). |
| Nível de simultaneidade | A contenção de trava ocorre somente com altos níveis de solicitações simultâneas da camada de aplicativo. |
| Tipo de espera observado | Observe as esperas no buffer (PAGELATCH_EX e PAGELATCH_SH) e no ACCESS_METHODS_HOBT_VIRTUAL_ROOT de trava de não buffer devido às divisões de raiz. Além disso, há esperas de PAGELATCH_UP em páginas PFS. Para obter mais informações sobre os tempos de espera de trava não buffer, confira sys.dm_os_latch_stats (Transact-SQL) na ajuda do SQL Server. |
A combinação de uma árvore B superficial e inserções aleatórias em todo o índice tende a causar divisões de página na árvore B. Para executar uma divisão de página, o SQL Server precisa adquirir travas compartilhadas (SH) em todos os níveis e, então, adquirir travas exclusivas (EX) nas páginas na árvore B envolvidas na divisão de página. Além disso, quando a simultaneidade é alta e os dados são inseridos e excluídos continuamente, podem ocorrer divisões de raiz na árvore B. Nesse caso, outras inserções podem precisar esperar por qualquer trava de não buffer adquirida na árvore B. Isso será manifestado como um grande número de esperas no tipo de trava ACCESS_METHODS_HOBT_VIRTUAL_ROOT, observadas na DMV sys.dm_os_latch_stats.
O script a seguir pode ser modificado para determinar a profundidade da árvore B para os índices na tabela afetada.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Contenção de trava em páginas PFS (Page Free Space)
PFS significa Page Free Space (espaço livre de página), e o SQL Server aloca uma página PFS para cada 8088 páginas (começando com PageID = 1) em cada arquivo de banco de dados. Cada byte na página PFS registra informações, incluindo a quantidade de espaço livre na página, se ela está alocada ou não e se a página armazena registros fantasmas. A página PFS contém informações sobre as páginas disponíveis para alocação quando uma nova página é necessária para uma operação de inserção ou de atualização. A página PFS deve ser atualizada em vários cenários, incluindo quando ocorrem alocações ou desalocações. Como o uso de uma trava de atualização (UP) é necessário para proteger a página PFS, a contenção de trava em páginas PFS pode ocorrer quando você tem relativamente poucos arquivos de dados em um grupo de arquivos e um grande número de núcleos de CPU. Uma forma simples de resolver isso é aumentar o número de arquivos por grupo de arquivos.
Aviso
Aumentar o número de arquivos por grupo de arquivos pode afetar negativamente o desempenho de determinadas cargas, como cargas com muitas operações grandes de classificação que despejam memória no disco.
Se muitas esperas de PAGELATCH_UP forem observadas para páginas PFS ou SGAM no tempdb, conclua estas etapas para eliminar esse gargalo:
Adicione arquivos de dados ao tempdb para que o número de arquivos de dados em tempdb seja igual ao número de núcleos de processador em seu servidor.
Habilite o Sinalizador de Rastreamento do SQL Server 1118.
Para saber mais sobre os gargalos de alocação causados pela contenção em páginas do sistema, confira a postagem no blog O que é o gargalo de alocação?.
Funções com valor de tabela e contenção de trava em tempdb
Outros fatores além da contenção de alocação podem causar contenção de trava em tempdb, como o uso intenso de TVF as consultas.
Lidando com a contenção de trava para diferentes padrões de tabela
As seções a seguir descrevem técnicas que podem ser usadas para resolver ou encontrar soluções alternativas para problemas de desempenho relacionados ao excesso de contenção de trava.
Usar uma chave de índice inicial não sequencial
Um método de lidar com contenção de trava é substituir uma chave de índice sequencial por uma não sequencial, para distribuir uniformemente as inserções em um intervalo de índice.
Geralmente, isso é feito colocando uma coluna inicial no índice que distribui a carga de trabalho proporcionalmente. Há duas opções aqui:
Opção: usar uma coluna dentro da tabela para distribuir os valores entre o intervalo de chaves de índice
Avalie sua carga de trabalho para encontrar um valor natural que possa ser usado para distribuir as inserções pelo intervalo de chaves. Por exemplo, considere um cenário com caixas eletrônicos em um banco, em que ATM_ID pode ser um bom candidato para distribuir inserções em uma tabela de transações com os saques, uma vez que apenas um cliente pode usar um caixa eletrônico por vez. De maneira semelhante, em um sistema de ponto de vendas, talvez Checkout_ID ou uma ID de Loja fosse um valor natural que poderia ser usado para distribuir inserções entre um intervalo de chaves. Essa técnica requer a criação de uma chave de índice composto com a coluna de chave inicial sendo o valor da coluna identificada ou algum hash desse valor combinado com uma ou mais colunas adicionais para fornecer exclusividade. Na maioria dos casos, um hash do valor funcionará melhor, pois muitos valores distintos levarão a uma organização física insatisfatória. Por exemplo, em um sistema de pontos de vendas, é possível criar, com base na ID da Loja, um hash que é um módulo e que se alinha com o número de núcleos de CPU. Essa técnica resultaria em um número relativamente pequeno de intervalos dentro da tabela, mas seria suficiente para distribuir inserções de maneira a evitar a contenção de trava. A imagem a seguir ilustra essa técnica.

Importante
Esse padrão contradiz as melhores práticas de indexação tradicionais. Embora essa técnica ajude a garantir a distribuição uniforme de inserções na árvore B, ela também pode exigir uma alteração de esquema no nível do aplicativo. Além disso, esse padrão pode afetar negativamente o desempenho de consultas que exigem verificações de intervalo e que utilizam o índice clusterizado. Algumas análises dos padrões de carga de trabalho serão necessárias para determinar se essa abordagem de design funcionará bem. Esse padrão deve ser implementado quando você pode sacrificar um pouco do desempenho de verificação sequencial para obter escala e taxa de transferência de inserção.
Esse padrão foi implementado durante uma participação em um laboratório de desempenho e resolveu a contenção de trava em um sistema com 32 núcleos físicos de CPU. A tabela foi usada para armazenar o saldo de fechamento ao final de uma transação; cada transação de negócios realizou uma inserção na tabela.
Definição da tabela original
Ao usar a definição da tabela original, era observada contenção de trava excessiva no índice clusterizado pk_table1:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Observação
Os nomes de objeto na definição da tabela foram alterados de seus valores originais.
Definição do índice reordenado
A reordenação das colunas de chave do índice com UserID como a coluna inicial na chave primária proporcionou uma distribuição quase aleatória de inserções nas páginas. A distribuição resultante não era 100% aleatória, pois nem todos os usuários ficam online ao mesmo tempo, mas a distribuição era aleatória o suficiente para aliviar o excesso de contenção de trava. Uma limitação da reordenação da definição de índice é que qualquer consulta SELECT nessa tabela precisa ser modificada para usar UserID e TransactionID como predicados de igualdade.
Importante
Certifique-se de testar exaustivamente todas as alterações em um ambiente de teste antes de executar em um ambiente de produção.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Usando um valor de hash como a coluna inicial na chave primária
A seguinte definição de tabela pode ser usada para gerar um módulo que se alinhe ao número de CPUs. HashValue é gerado usando o valor de TransactionID com aumento sequencial para garantir uma distribuição uniforme na árvore B:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Opção: usar um GUID como a coluna de chave inicial do índice
Se não houver um separador natural, uma coluna de GUID poderá ser usada como a coluna de chave inicial do índice para garantir a distribuição uniforme das inserções. Embora a abordagem de usar o GUID como a coluna inicial na chave do índice permita o uso do particionamento para outros recursos, essa técnica também pode introduzir possíveis desvantagens decorrentes de ter mais divisões de página, de uma organização física deficiente e das baixas densidades de página.
Observação
O uso de GUIDs como as colunas de chave iniciais dos índices é um assunto muito debatido. Uma discussão detalhada dos prós e contras desse método está fora do escopo deste artigo.
Usar o particionamento de hash com uma coluna computada
O particionamento de tabela dentro do SQL Server pode ser usado para atenuar o excesso de contenção de trava. A criação de um esquema de partição de hash com uma coluna computada em uma tabela particionada é uma abordagem comum que pode ser executada com estas etapas:
Crie um grupo de arquivos ou use um existente para armazenar as partições.
Se for usar um novo grupo de arquivos, equilibre igualmente os arquivos individuais no LUN, tomando cuidado para usar um layout ideal. Se o padrão de acesso envolver uma alta taxa de inserções, crie a mesma quantidade de arquivos que existe em núcleos de CPU físicos no computador do SQL Server.
Use o comando CREATE PARTITION FUNCTION para particionar as tabelas em X partições, em que X é o número de núcleos de CPU físicos no computador do SQL Server. (pelo menos 32 partições)
Observação
Um alinhamento de um para um entre o número de partições e o número de núcleos de CPU nem sempre é necessário. Em muitos casos, esse pode ser um valor menor que o número de núcleos de CPU. Ter mais partições pode causar mais sobrecarga para consultas que precisam pesquisar todas as partições e, nesses casos, ter menos partições ajudará. Nos testes do SQLCAT com sistemas com 64 e 128 CPUs lógicas com cargas de trabalho de clientes reais, 32 partições foram suficientes para resolver a contenção de trava excessivas e atingir as metas de escala. Em última instância, o número ideal de partições deve ser determinado por meio de testes.
Use o comando CREATE PARTITION SCHEME:
- Associe a partição aos grupos de arquivos.
- Adicione uma coluna de hash do tipo tinyint ou smallint à tabela.
- Calcule uma boa distribuição de hash. Por exemplo, use hashbytes com módulo ou binary_checksum.
O seguinte script de exemplo pode ser personalizado para sua implementação:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Esse script pode ser usado para fazer a partição de hash de uma tabela com problemas causados pela Contenção de inserção de última página/página à direita. Essa técnica move a contenção da última página particionando a tabela e distribuindo as inserções entre partições de tabela com uma operação de módulo do valor de hash.
O que o particionamento de hash com uma coluna computada faz
Como ilustra o diagrama a seguir, essa técnica move a contenção da última página recriando o índice na função de hash e criando um número de partições igual ao número de núcleos de CPU físicos no computador do SQL Server. As inserções ainda vão para o final do intervalo lógico (um valor com aumento sequencial), mas a operação de módulo do valor de hash garante que as inserções sejam divididas entre as diferentes árvores B, o que alivia o gargalo. Isso é ilustrado nos seguintes diagramas:


Compensações ao usar o particionamento hash
Embora o particionamento hash possa eliminar a contenção em inserções, há várias compensações a serem consideradas ao decidir entre usar ou não usar essa técnica:
Na maioria das vezes, as consultas SELECT precisam ser modificadas para incluir a partição hash no predicado e levar a um plano de consulta que não fornece nenhuma eliminação de partição quando essas consultas são emitidas. A captura de tela a seguir mostra um plano inadequado, sem eliminação de partição após a implementação do particionamento hash.
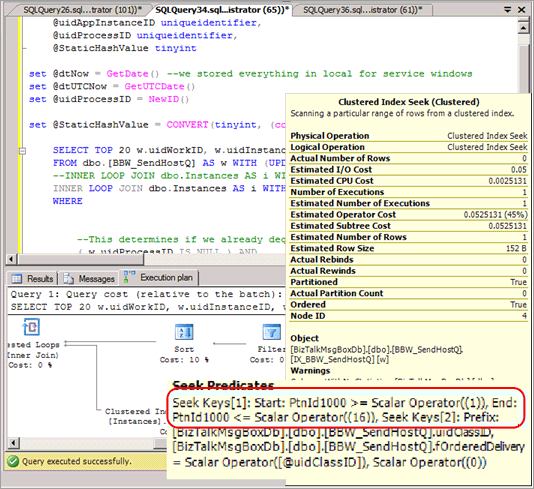
Ele elimina a possibilidade de eliminação de partição em algumas outras consultas, como em relatórios baseados em intervalos.
Ao unir uma tabela particionada por hash a outra tabela, para obter a eliminação de partição, a segunda tabela precisará ser particionada por hash na mesma chave e a chave de hash deverá fazer parte dos critérios de junção.
O particionamento hash impede o uso do particionamento por outros recursos de gerenciamento, como as funcionalidades arquivamento de janela deslizante e troca de partição.
O particionamento hash é uma estratégia eficaz para mitigar o excesso de contenção de trava, pois aumenta a taxa de transferência geral do sistema, aliviando a contenção em inserções. Como há algumas compensações envolvidas, talvez essa não seja a solução ideal para alguns padrões de acesso.
Resumo das técnicas usadas para solucionar a contenção de trava
As duas seções seguintes fornecem um resumo das técnicas que podem ser usadas para resolver a contenção de trava excessiva:
Chave/índice não sequencial
Vantagens:
- Permite o uso de outros recursos de particionamento, como o arquivamento de dados usando um esquema de janela deslizante e a funcionalidade de troca de partição.
Desvantagens:
- Possíveis desafios ao escolher uma chave/índice para garantir uma distribuição "próxima o suficiente" de uniforme das inserções o tempo todo.
- O GUID como coluna inicial pode ser usado para garantir a distribuição uniforme, com a limitação de que pode resultar em operações excessivas de divisão de página.
- Inserções aleatórias na árvore B podem resultar em muitas operações de divisão de página e levar à contenção de trava em páginas não folha.
Particionamento hash com coluna computada
Vantagens:
- Transparente para inserções.
Desvantagens:
- O particionamento não pode ser usado para os recursos de gerenciamento pretendidos, como arquivar dados usando opções de troca de partição.
- Pode causar problemas de eliminação de partição para consultas, incluindo seleção/atualização individual e baseada em intervalo e consultas que executam uma junção.
- A adição de uma coluna computada persistente é uma operação offline.
Dica
Para conhecer técnicas adicionais, confira a postagem no blog Espera e inserções pesadas com PAGELATCH_EX.
Passo a passo: diagnosticar uma contenção de trava
O passo a passo a seguir demonstra as ferramentas e técnicas descritas em Diagnosticando a contenção de trava no SQL Server e Lidando com a contenção de trava para diferentes padrões de tabela para resolver um problema em um cenário do mundo real. Este cenário descreve uma participação do cliente para realizar teste de carga de um sistema de ponto de vendas que simulava aproximadamente 8.000 lojas executando transações em um aplicativo SQL Server em execução em um sistema com 8 soquetes, 32 núcleos físicos e 256 GB de memória.
O seguinte diagrama detalha o hardware usado para testar o sistema de ponto de vendas:

Sintoma: travas quentes
Nesse caso, observamos tempos de espera elevados por PAGELATCH_EX, em que normalmente definimos elevado como uma média de mais de 1 ms. Nesse caso, observamos consistentemente esperas que ultrapassavam 20 ms.

Após determinarmos que a contenção de trava era problemática, partimos para a determinação do que estava causando a contenção de trava.
Isolando o objeto que está causando a contenção de trava
O seguinte script usa a coluna resource_description para isolar qual índice estava causando a contenção de PAGELATCH_EX:
Observação
A coluna resource_description retornada por esse script fornece a descrição do recurso no formato < DatabaseID,FileID,PageID>, em que o nome do banco de dados associado a DatabaseID pode ser determinado passando o valor de DatabaseID para a função DB_NAME ().
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Como mostrado aqui, a contenção está na tabela LATCHTEST e no nome de índice CIX_LATCHTEST. Observe que os nomes foram alterados para manter o anonimato da carga de trabalho.

Para ver um script mais avançado que sonda repetidamente e usa uma tabela temporária para determinar o tempo de espera total durante um período configurável, confira Descritores de buffer de consulta para determinar objetos que causam contenção de trava no apêndice.
Técnica alternativa para isolar o objeto que está causando contenção de trava
Às vezes pode ser impraticável consultar sys.dm_os_buffer_descriptors. Conforme a memória no sistema e a memória disponível para o pool de buffers aumenta, também aumenta o tempo necessário para executar essa DMV. Em um sistema de 256 GB, pode levar até 10 minutos ou mais para que essa DMV seja executada. Uma técnica alternativa está disponível. Ela é descrita de modo geral da seguinte maneira e é ilustrada com uma carga de trabalho diferente, que executamos no laboratório:
Consulte as tarefas com espera atuais usando o script da Apêndice Consultar sys.dm_os_waiting_tasks ordenado pela duração da espera.
Identifique a página principal em que um comboio é observado, o que acontece quando vários threads estão competindo pela mesma página. Neste exemplo, os threads que executam a inserção estão competindo pela página inicial na árvore B e aguardarão até que possam adquirir uma trava EX. Isso é indicado pela resource_description na primeira consulta, em nosso caso, 8:1:111305.
Habilite o sinalizador de rastreamento 3604, que expõe mais informações sobre a página por meio de DBCC PAGE com a seguinte sintaxe, substituindo o valor obtido por meio de resource_description pelo valor entre parênteses:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Examinar a saída do DBCC. Deve haver um ObjectID de metadados associado, em nosso caso, '78623323'.

Agora, podemos executar o comando a seguir para determinar o nome do objeto que está causando a contenção, que, como esperado, é LATCHTEST.
Observação
Verifique se você está no contexto de banco de dados correto, caso contrário, a consulta retornará NULL.
--get object name select OBJECT_NAME (78623323);
Resumo e resultados
Usando a técnica acima, pudemos confirmar que a contenção estava ocorrendo em um índice clusterizado com um valor de chave com aumento sequencial na tabela, que de longe recebia o número mais alto de inserções. Esse tipo de contenção não é incomum para índices com valor de chave com aumento sequencial, como datetime, identidade ou uma transactionID gerada por aplicativo.
Para resolver o problema, usamos o particionamento hash com uma coluna computada e observamos um aprimoramento de desempenho de 690%. A tabela a seguir resume o desempenho do aplicativo antes e depois de implementar o particionamento hash com uma coluna computada. A utilização da CPU aumenta bastante, em paralelo com a taxa de transferência, conforme esperado após a remoção do gargalo de contenção de trava:
| Medição | Antes do particionamento hash | Depois do particionamento hash |
|---|---|---|
| Transações de negócios/s | 36 | 249 |
| Tempo de espera médio de trava de página | 36 milissegundos | 0,6 milissegundo |
| Esperas de Trava/s | 9.562 | 2\.873 |
| Tempo do processador SQL | 24% | 78% |
| Solicitações em lote de SQL/s | 12.368 | 47.045 |
Como pode ser visto na tabela acima, identificar e resolver corretamente os problemas de desempenho causados pelo excesso de contenção de trava de página pode ter um impacto positivo sobre o desempenho geral do aplicativo.
Apêndice: técnica alternativa
Uma estratégia possível para evitar o excesso de contenção de trava de página é acrescentar linhas a uma coluna CHAR para garantir que cada linha use uma página inteira. Essa estratégia é uma opção quando o tamanho geral dos dados é pequeno e você precisa lidar com a contenção de trava de página EX causada pela seguinte combinação de fatores:
- Tamanho de linha pequeno
- Árvore B superficial
- Padrão de acesso com alta taxa de operações de inserção, seleção, atualização e exclusão aleatórias
- Tabelas pequenas, por exemplo, tabelas de fila temporárias
Preenchendo as linhas para ocupar uma página inteira, você exige que o SQL aloque páginas adicionais, disponibilizando mais páginas para inserções e reduzindo a contenção de trava de página EX.
Preenchimento de linhas para garantir que cada linha ocupe uma página inteira
Um script semelhante ao seguinte pode ser usado para preencher linhas para ocupar uma página inteira:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Observação
Use o menor caractere possível que force uma linha por página, para reduzir os requisitos adicionais de CPU para o valor de preenchimento e o espaço extra necessário para registrar a linha. Cada byte conta em um sistema de alto desempenho.
Essa técnica é explicada para fins de integridade; na prática, o SQLCAT só usou isso em uma pequena tabela com 10.000 linhas em uma só participação de desempenho. Essa técnica tem aplicação limitada porque aumenta a pressão de memória no SQL Server para tabelas grandes e pode resultar em contenção de trava de não buffer em páginas que não são folhas. A pressão de memória adicional pode ser um fator de limitação significativo para a aplicação dessa técnica. Com a quantidade de memória disponível em um servidor moderno, uma grande proporção do conjunto de trabalho para cargas de trabalhos OLTP normalmente é mantida na memória. Quando o conjunto de dados aumenta para um tamanho que não cabe mais na memória, ocorre uma queda significativa no desempenho. Portanto, essa técnica só se aplica a tabelas pequenas. Essa técnica não é usada pelo SQLCAT para cenários como a contenção de inserção de última página/página à direita para tabelas grandes.
Importante
Empregar essa estratégia pode causar um grande número de esperas no tipo de trava ACCESS_METHODS_HOBT_VIRTUAL_ROOT porque essa estratégia pode levar a um grande número de divisões de página que ocorrem nos níveis não folha da árvore B. Se isso ocorrer, o SQL Server precisará adquirir travas compartilhadas (SH) em todos os níveis, seguidas por travas exclusivas (EX) nas páginas na árvore B em que uma divisão de página é possível. Verifique na DMV sys.dm_os_latch_stats se há um grande número de esperas no tipo de trava ACCESS_METHODS_HOBT_VIRTUAL_ROOT após o preenchimento das linhas.
Apêndice: scripts de contenção de trava do SQL Server
Esta seção contém scripts que podem ser usados para ajudar a diagnosticar e solucionar problemas de contenção de trava.
Consulta sys.dm_os_waiting_tasks ordenada pela ID da sessão
O seguinte script de exemplo consulta sys.dm_os_waiting_tasks e retorna os tempos de espera de trava ordenados segundo a ID da sessão:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Consulta sys.dm_os_waiting_tasks ordenada pela duração da espera
O seguinte script de exemplo consulta sys.dm_os_waiting_tasks e retorna os tempos de espera de trava ordenados segundo a duração da espera:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Calcular esperas ao longo de um período
O script a seguir calcula e retorna os tempos de espera de trava ao longo de um período.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Consultar descritores de buffer para determinar os objetos que causam contenção de trava
O script a seguir consulta os descritores de buffer para determinar quais objetos estão associados aos tempos de espera de trava mais longos.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Script de particionamento hash
O uso desse script é descrito em Usar o particionamento de hash com uma coluna computada e deve ser personalizado para sua implementação.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Próximas etapas
Para obter mais informações sobre as ferramentas de monitoramento de desempenho, confira Ferramentas para monitoramento e ajuste de desempenho.