Diagnosticar e resolver uma contenção de spinlock no SQL Server
Este artigo fornecerá informações detalhadas sobre como identificar e resolver problemas relacionados a uma contenção de spinlock em aplicativos do SQL Server e sistemas de alta simultaneidade.
Observação
As recomendações e práticas recomendadas documentadas aqui são baseadas em uma experiência real durante o desenvolvimento e a implantação de sistemas OLTP reais. Este artigo foi publicado originalmente pela equipe do SQLCAT (Equipe de Consultoria para Clientes do Microsoft SQL Server).
Tela de fundo
No passado, os computadores básicos do Windows Server usavam somente um ou dois chips de microprocessadores/CPUs. Além disso, as CPUs eram projetadas somente com um processador ou "núcleo". O aumento da capacidade de processamento dos computadores foi obtido usando CPUs mais rápidas. Elas foram possibilitadas, em grande parte, pelo avanço da densidade do transistor. Após a "lei de Moore", a densidade do transistor ou o número de transistores que podem ser colocados em um circuito integrado tem sido dobrado de modo consistente a cada dois anos, desde o desenvolvimento da primeira CPU de um chip de uso geral em 1971. Nos últimos anos, a abordagem tradicional de aumentar a capacidade de processamento dos computadores com CPUs mais rápidas foi ampliada pela criação de computadores com várias CPUs. No momento em que este artigo foi escrito, a arquitetura de CPU do Intel Nehalem acomodava até oito núcleos por CPU. No entanto, quando usado em um sistema de oito soquetes, o processador poderá ser dobrado para acomodar 128 processadores lógicos usando uma tecnologia de SMT (multithreading simultâneo). Em CPUs Intel, o SMT é chamado Hyper-Threading. Conforme aumenta o número de processadores lógicos em computadores compatíveis com x86, os problemas relacionados à simultaneidade também aumentam à medida que os processadores lógicos competem por recursos. Este guia descreverá como identificar e resolver problemas específicos de contenção de recursos observados durante a execução de aplicativos do SQL Server em sistemas de alta simultaneidade com algumas cargas de trabalho.
Nesta seção, analisamos as lições aprendidas pela equipe do SQLCAT ao diagnosticar e resolver problemas de contenção de spinlock. A contenção de spinlock é um tipo de problema de simultaneidade observado em cargas de trabalho reais do cliente em sistemas de alta escala.
Os sintomas e as causas da contenção de spinlock
Esta seção descreverá como diagnosticar problemas com uma contenção de spinlock, que é prejudicial ao desempenho de aplicativos OLTP no SQL Server. O diagnóstico e a solução de problemas de spinlock devem ser considerados um assunto avançado, que requer conhecimento de ferramentas de depuração e funções internas do Windows.
Os spinlocks são primitivos de sincronização leve, usados para proteger o acesso a estruturas de dados. Os spinlocks não são exclusivos do SQL Server. Eles são usados pelo sistema operacional quando é necessário obter acesso a uma determinada estrutura de dados somente por um curto período. Quando um thread não consegue obter acesso ao tentar adquirir um spinlock, ele é executado em um loop verificando de maneira periódica se o recurso está disponível, em vez de fazer uma suspensão imediata. Após algum tempo, o thread que está aguardando o spinlock será suspenso antes de poder adquirir o recurso. A suspensão permite que outros threads em execução na mesma CPU sejam executados. Esse comportamento é conhecido como retirada e é discutido em mais detalhes posteriormente neste artigo.
O SQL Server usa spinlocks para proteger o acesso a algumas estruturas internas de dados. Os spinlocks são usados no mecanismo para serializar o acesso a determinadas estruturas de dados de maneira semelhante às travas. A principal diferença entre a trava e o spinlock é o fato de que os spinlocks giram (executar um loop) por um período verificando a disponibilidade de uma estrutura de dados. Por outro lado, um thread tentando obter acesso a uma estrutura protegida por trava cederá imediatamente se recurso não estiver disponível. A suspensão requer a alternância de contexto de um thread fora da CPU para que outro thread possa ser executado. Essa é uma operação relativamente cara. Para os recursos que são bloqueados por um curto período, em geral, é mais eficiente permitir que o thread seja executado em um loop verificando de maneira periódica a disponibilidade do recurso.
Os ajustes internos no Mecanismo de Banco de Dados introduzidos no SQL Server 2022 (16.x) tornam os spinlocks mais eficientes.
Sintomas
É normal ver uma contenção ativa em estruturas acessadas com frequência que são protegidas por spinlocks em um sistema ocupado e de alta simultaneidade. Esse uso é considerado problemático somente quando a contenção apresentar uma sobrecarga significativa da CPU. As estatísticas de spinlock são expostas pelo DMV (exibição de gerenciamento dinâmico) sys.dm_os_spinlock_stats no SQL Server. Por exemplo, esta consulta produzirá a seguinte saída:
Observação
Mais detalhes sobre como interpretar as informações retornadas por essa DMV serão discutidos posteriormente neste artigo.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
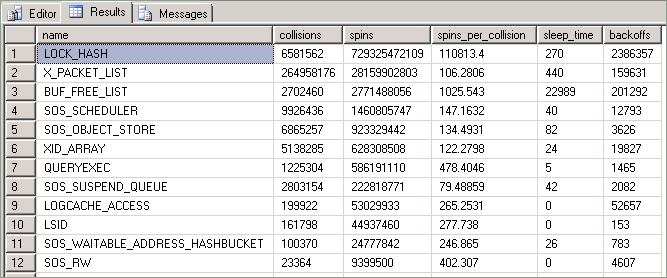
As estatísticas expostas por essa consulta serão descritas da seguinte maneira:
| Coluna | Descrição |
|---|---|
| Colisões | Esse valor será incrementado cada vez que um thread for impedido de acessar um recurso protegido por um spinlock. |
| Rotações | Esse valor será incrementado cada vez que o thread executar um loop enquanto aguarda a disponibilização de um spinlock. Essa é a medida da quantidade de trabalho realizado por um thread enquanto ele tenta adquirir um recurso. |
| Spins_per_collision | Taxa de rotações por colisão. |
| Tempo de suspensão | Relacionado a eventos de retirada. No entanto, ele não é relevante para as técnicas descritas neste artigo. |
| Retiradas | Ocorre quando um thread em "rotação" que está tentando acessar um recurso bloqueado, determina que é necessário permitir a execução de outros threads na mesma CPU. |
Para os objetivos desta discussão, estatísticas de interesse específico são o número de colisões, rotações e eventos de retirada que ocorrem em um determinado período quando o sistema está com um carregamento intenso. A colisão ocorre quando um thread tenta acessar um recurso protegido por um spinlock. Quando uma colisão ocorre, a contagem de colisões é incrementada e o thread começa uma rotação em loop, além de verificar de maneira periódica se o recurso está disponível. Cada vez que ocorrer uma rotação (executar um loop) do thread, a contagem de rotações será incrementada.
Rotações por colisão é uma medida da quantidade de rotações que ocorrem enquanto um spinlock está sendo mantido por um thread e informa quantas rotações ocorrem enquanto os threads estão mantendo o spinlock. Por exemplo, pequenas rotações por colisão e uma contagem alta de colisões significam que há uma pequena quantidade de rotações ocorrendo no spinlock, além de haver uma disputa de vários threads por elas. Uma grande quantidade de rotações significa que o tempo gasto com a rotação no código de spinlock teve um período relativamente longo (ou seja, o código está passando por um grande número de entradas em um bucket de hash). Conforme a contenção aumenta (aumentando, portanto, a contagem de colisões), o número de rotações também aumenta.
As retiradas podem ser consideradas semelhantes às rotações. Por design, para evitar um desperdício excessivo da CPU, os spinlocks não continuam a executar uma rotação indefinidamente até que possam acessar um recurso bloqueado. Para garantir que um spinlock não use os recursos da CPU de modo excessivo, ocorre um retirada de spinlocks ou eles interrompem a rotação e ficam "suspensos". A retirada de spinlocks ocorre independentemente se eles já obtiveram a propriedade do recurso de destino. Isso ocorre para permitir que outros threads sejam agendados na CPU, com a expectativa de possibilitar que o trabalho seja mais produtivo. O comportamento padrão do mecanismo é primeiro fazer uma rotação durante um intervalo de tempo constante antes de executar uma retirada. Tentar obter um spinlock requer a manutenção de um estado de simultaneidade de cache, que é uma operação intensiva da CPU em relação ao custo de rotação da CPU. Portanto, as tentativas de obter um spinlock são executadas com moderação e não cada vez que um thread fizer uma rotação. No SQL Server, certos tipos de spinlock (por exemplo: LOCK_HASH) foram aprimorados usando um intervalo de aumento exponencial entre as tentativas de adquirir um spinlock (até um determinado limite), o que geralmente reduz o impacto no desempenho da CPU.
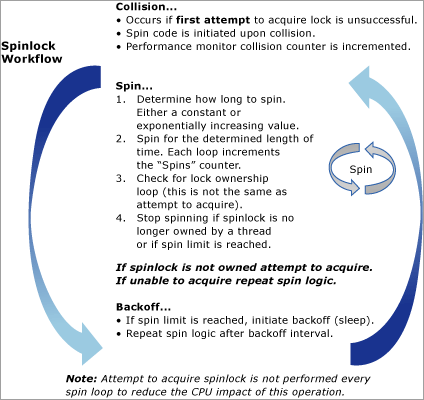
O seguinte diagrama fornecerá uma exibição conceitual do algoritmo de spinlock:
Cenários comuns
A contenção de spinlock pode ocorrer por vários motivos e eles podem não estar relacionados a decisões de design do banco de dados. Como os spinlocks controlam o acesso a estruturas internas de dados, a contenção de spinlock não é manifestada da mesma maneira que a contenção de trava de buffer, que é diretamente afetada por escolhas de design de esquema e padrões de acesso a dados.
Um sintoma associado principalmente a uma contenção de spinlock é o alto consumo de CPU como resultado do alto número de rotações e de vários threads que tentam adquirir o mesmo spinlock. Em geral, isso foi observado em sistemas >= 24 bits e frequentemente em sistemas com núcleo de CPU >= 32 bits. Como dito anteriormente, é normal haver algum nível de contenção em spinlocks para sistemas OLTP de alta simultaneidade com uma carga significativa. Além disso, muitas vezes, há um alto número de rotações (bilhões/trilhões) relatadas da DMV sys.dm_os_spinlock_stats em sistemas em execução por muito tempo. Novamente, observar um alto número de rotações em um determinado tipo de spinlock não é suficiente para determinar que há um impacto negativo no desempenho da carga de trabalho.
Uma combinação de vários sintomas abaixo poderá indicar a contenção de spinlock:
Um alto número de rotações e retiradas é observado para um tipo específico de spinlock.
O sistema está enfrentando uma intensa utilização da CPU ou há picos no consumo de CPU. Em cenários de uso intenso de CPU intenso, você vê sinais de alto volume de esperas em SOS_SCHEDULER_YEILD (relatado pela DMV
sys.dm_os_wait_stats).O sistema está enfrentando uma alta simultaneidade.
O uso da CPU e as rotações aumentam de maneira desproporcional à taxa de transferência.
Importante
Mesmo que cada uma das condições anteriores seja verdadeira, ainda é possível que a causa raiz do alto consumo de CPU esteja em outro lugar. Na verdade, na grande maioria dos casos, o aumento do consumo de CPU será devido a razões diferentes da contenção de spinlock. Algumas das causas mais comuns para o aumento do consumo de CPU incluem:
Consultas que se tornam mais caras ao longo do tempo devido ao crescimento de dados subjacentes, resultando na necessidade de executar leituras lógicas adicionais de dados residentes na memória.
Alterações nos planos de consulta resultando em uma execução de qualidade inferior.
Caso todas essas condições sejam verdadeiras, realize uma investigação adicional sobre possíveis problemas de contenção de spinlock.
Um fenômeno comum e facilmente diagnosticado é uma divergência significativa na taxa de transferência e no uso da CPU. Várias cargas de trabalho OLTP têm uma relação entre a taxa de transferência/o número de usuários no sistema e o consumo de CPU. As altas rotações observadas em conjunto com uma divergência significativa do consumo de CPU e a taxa de transferência podem indicar uma contenção de spinlock que introduz uma sobrecarga de CPU. É importante observar aqui que também é comum ver esse tipo de divergência nos sistemas quando determinadas consultas se tornam mais caras com o tempo. Por exemplo, as consultas emitidas em conjuntos de dados que executam um número maior de leituras lógicas ao longo do tempo poderão resultar em sintomas semelhantes.
É fundamental eliminar as causas mais comuns do alto consumo de CPU ao solucionar esses tipos de problemas.
Exemplos
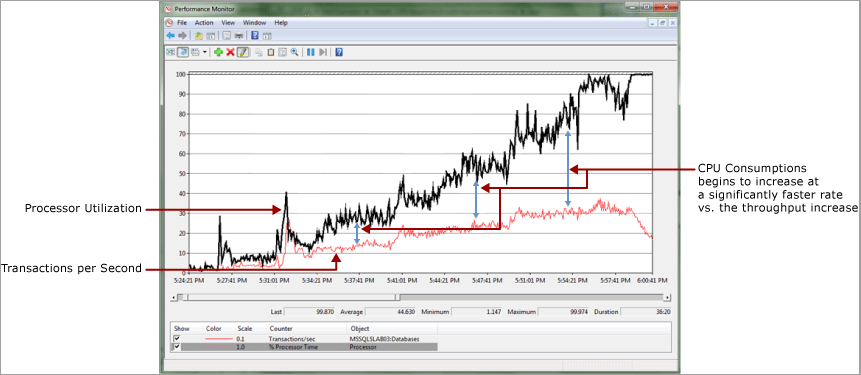
No exemplo a seguir, há uma relação quase linear entre o consumo de CPU e throughput medido por transações por segundo. É normal ver algumas divergências aqui porque a sobrecarga incorrerá conforme uma carga de trabalho aumentar. Conforme ilustrado aqui, essa divergência se tornará significativa. Também haverá uma queda abrupta de throughput quando o consumo de CPU atingir 100%.
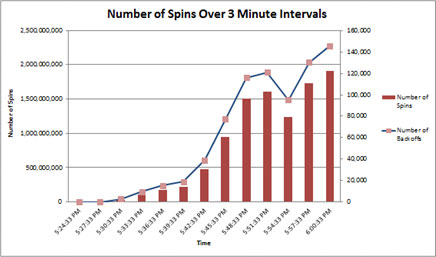
Ao medirmos o número de rotações em intervalos de três minutos, poderemos ver um aumento mais exponencial do que linear nas rotações, o que indica que a contenção de spinlock poderá ser problemática.
Conforme mencionado anteriormente, os spinlocks são mais comuns em sistemas de alta simultaneidade e com um carregamento intenso.
Alguns dos cenários propensos a esse problema incluem:
Problemas com a resolução de nomes causados por uma falha ao qualificar completamente os nomes de objetos. Para obter mais informações, confira Descrição de um bloqueio do SQL Server causado por bloqueios de compilação. Esse problema específico será descrito com mais detalhes neste artigo.
A contenção de buckets de hash de bloqueio no gerenciador de bloqueios de cargas de trabalho que acessam com frequência o mesmo bloqueio (como um bloqueio compartilhado em uma linha com leituras frequentes). Esse tipo de contenção aparece como um spinlock do tipo LOCK_HASH. Em um caso específico, descobrimos que esse problema apareceu como resultado de padrões de acesso modelados de maneira incorreta em um ambiente de teste. Nesse ambiente, um número maior do que o esperado de threads acessavam constantemente a mesma linha devido a parâmetros de teste configurados de maneira incorreta.
Uma alta taxa de transações DTC quando há um alto grau de latência entre os coordenadores de transações MSDTC. Esse problema específico será documentado em detalhes na entrada de blog do SQLCAT Como resolver esperas relacionadas ao DTC e ajustar a escalabilidade do DTC.
Diagnosticar e resolver uma contenção de spinlock
Esta seção fornecerá informações sobre como diagnosticar uma contenção de spinlock do SQL Server. As principais ferramentas usadas para diagnosticar uma contenção de spinlock são:
| Ferramenta | Uso |
|---|---|
| Monitor de desempenho | Procure por condições de alto consumo de CPU ou divergências entre a taxa de transferência e o consumo de CPU. |
DMV** de estatísticas sys.dm_os_spinlock |
Procure por um alto número de rotações e eventos de retirada em determinados períodos. |
| Eventos estendidos do SQL Server | Usado com o objetivo de rastrear pilhas de chamadas de spinlocks que apresentam um alto número de rotações. |
| Despejos de memória | Em alguns casos, a memória despeja o processo do SQL Server e as ferramentas de Depuração do Windows. Em geral, esse nível de análise será feito quando as equipes de suporte do Microsoft SQL Server estiverem envolvidas. |
O processo técnico geral para diagnosticar uma contenção de spinlock do SQL Server será:
Etapa 1: determinar se há uma contenção que pode estar relacionada ao spinlock.
Etapa 2: capturar estatísticas de
sys.dmsys.dm os_spinlock_stats para localizar o tipo de spinlock que está enfrentando a maior contenção.Etapa 3: obter símbolos de depuração para o sqlservr.exe (sqlservr.pdb) e colocar os símbolos no mesmo diretório do arquivo .exe serviço SQL Server (sqlservr.exe) para a instância do SQL Server.\ Para conferir as pilhas de chamadas dos eventos de retirada, você deverá ter os símbolos da versão específica do SQL Server que está executando. Os símbolos do SQL Server estão disponíveis no Servidor de Símbolos da Microsoft. Para obter mais informações sobre como baixar os símbolos do Servidor de Símbolos da Microsoft, confira Depuração com símbolos.
Etapa 4: usar os Eventos Estendidos do SQL Server para rastrear os eventos de retirada dos tipos de spinlock de interesse.
Os Eventos Estendidos fornecem a capacidade de rastrear o evento de “retirada” e capturar a pilha de chamadas para as operações que tentam veementemente obter o spinlock. Analisando a pilha de chamadas, é possível determinar que tipo de operação está contribuindo para a contenção de um spinlock específico.
Passo a passo do diagnóstico
O passo a passo a seguir mostrará como usar ferramentas e técnicas para diagnosticar um problema de contenção de spinlock em um cenário real. Esse passo a passo é baseado em uma participação do cliente executando um teste de parâmetro de comparação para simular aproximadamente 6.500 usuários simultâneos em um servidor de núcleo físico de 64 bits e 8 soquetes com 1 TB de memória.
Sintomas
Foram observados picos periódicos na CPU, o que pressionou a utilização da CPU para quase 100%. Foi observado que o problema ocorreu devido a uma divergência entre a taxa de transferência e o consumo de CPU. No momento em que ocorreu o grande pico de uso da CPU, foi estabelecido o padrão de um número grande de rotações ocorrendo durante períodos de uso intenso da CPU em intervalos específicos.
Esse foi um caso extremo em que a contenção foi tão grande que criou uma condição de comboio de spinlock. Um comboio ocorre quando os threads não podem mais progredir atendendo à carga de trabalho. Em vez disso, eles gastam todos os recursos de processamento tentando obter acesso ao bloqueio. O log do monitor de desempenho ilustra essa divergência entre a taxa de transferência do log de transações e o consumo de CPU, além de mostrar, por fim, um grande pico na utilização da CPU.
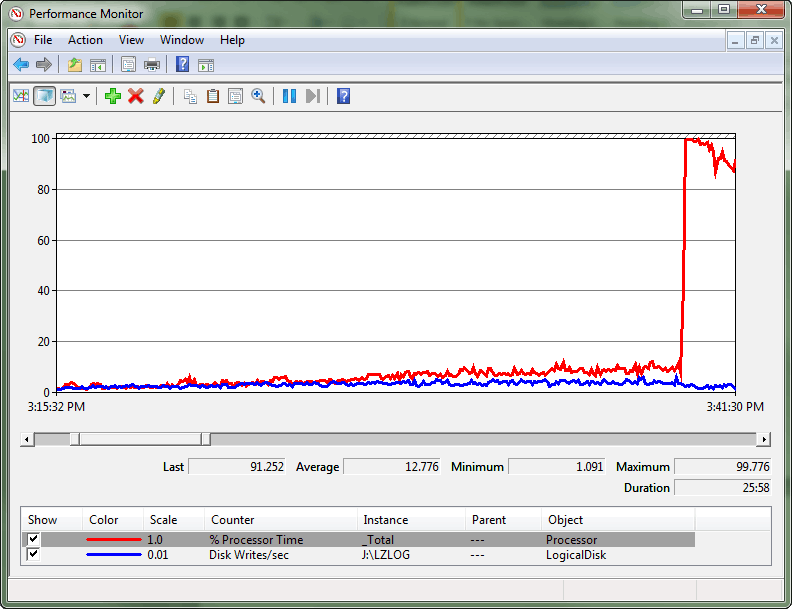
Depois de consultar sys.dm_os_spinlock_stats para determinar a existência de uma contenção significativa no SOS_CACHESTORE, um script de eventos estendidos foi usado para medir o número de eventos de retirada dos tipos de spinlock de interesse.
| Nome | Colisões | Rotações | Rotações por colisão | Retiradas |
|---|---|---|---|---|
SOS_CACHESTORE |
14.752.117 | 942.869.471.526 | 63.914 | 67.900.620 |
SOS_SUSPEND_QUEUE |
69.267.367 | 473.760.338.765 | 6\.840 | 2.167.281 |
LOCK_HASH |
5.765.761 | 260.885.816.584 | 45.247 | 3.739.208 |
MUTEX |
2.802.773 | 9.767.503.682 | 3.485 | 350.997 |
SOS_SCHEDULER |
1.207.007 | 3.692.845.572 | 3.060 | 109.746 |
O modo mais direto de quantificar o impacto das rotações é examinar o número de eventos de retirada expostos por sys.dm_os_spinlock_stats durante o mesmo intervalo de um minuto dos tipos de spinlock com o número mais alto de rotações. Esse método é o mais adequado para detectar uma contenção significativa porque ele indica quando os threads estão esgotando o limite de rotações enquanto aguardam para adquirir o spinlock. O script a seguir ilustrará uma técnica avançada que usa eventos estendidos para medir eventos de retirada relacionados, além de identificar os caminhos do código específicos em que a contenção está.
Para obter mais informações sobre os Eventos Estendidos no SQL Server, confira Introdução aos Eventos Estendidos do SQL Server.
Script
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Ao analisar a saída, podemos conferir as pilhas de chamadas dos caminhos do código mais comuns para rotações SOS_CACHESTORE. O script foi executado de modo diferente algumas vezes quando a utilização da CPU estava alta para verificar a consistência nas pilhas de chamadas retornadas. As pilhas de chamadas com o maior número de buckets de slot são comuns entre duas saídas (35.668 e 8.506). Essas pilhas de chamadas têm uma "contagem de slots" duas ordens de magnitude maior do que a segunda maior entrada. Essa condição indica um caminho do código de interesse.
Observação
Não é incomum ver pilhas de chamadas retornadas pelo script anterior. Quando o script foi executado por 1 minuto, observamos que as pilhas de chamadas com uma contagem de slots de > 1000 eram problemáticas, mas a contagem de slots de > 10.000 tinha mais probabilidade de ser problemática, pois tem uma contagem de slots maior.
Observação
Houve uma limpeza na formatação da saída a seguir para fins de legibilidade.
Saída 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Saída 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
No exemplo anterior, as pilhas mais interessantes tinham as Contagens de Slots mais altas (35.668 e 8.506). Isso, na verdade, significa ter uma contagem de slots > 1.000.
Nesse momento, você pode estar se perguntando: "o que devo fazer com essas informações"? Em geral, ter um conhecimento profundo sobre o mecanismo do SQL Server é necessário para usar as informações da pilha de chamadas. Portanto, nesse momento, o processo de solução de problemas será levado para uma área de indefinição. Nesse caso específico, ao examinar as pilhas de chamadas, podemos ver que o caminho do código em que o problema ocorre está relacionado a pesquisas de segurança e metadados (como fica evidente pelos registros de ativação CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID) a seguir.
É difícil usar essas informações de modo isolado para resolver o problema, porém elas fornecem algumas ideias nas quais se concentrar para obter uma solução adicional que isole ainda mais o problema.
Como esse problema parece estar relacionado a caminhos do código que executam verificações relacionadas à segurança, decidimos executar um teste em que um usuário do aplicativo que se conecta ao banco de dados recebeu privilégios sysadmin. Embora essa técnica nunca seja recomendada em um ambiente de produção, ela provou ser uma etapa útil de solução de problemas em nosso ambiente de teste. Quando as sessões foram executadas usando privilégios elevados (sysadmin), os picos de uso da CPU relacionados à contenção desapareceram.
Opções e soluções alternativas
É evidente que solucionar problemas de contenção de spinlock pode ser uma tarefa não trivial. Não há uma "abordagem comum mais adequada". A primeira etapa da solução de problemas de desempenho é identificar a causa raiz. Usar as técnicas e ferramentas descritas neste artigo é a primeira etapa para executar uma análise necessária com o objetivo de entender os pontos de contenção relacionados ao spinlock.
Conforme as novas versões do SQL Server são desenvolvidas, o mecanismo continua aprimorando a escalabilidade ao implementar um código mais otimizado para sistemas de alta simultaneidade. O SQL Server introduziu várias otimizações para sistemas de alta simultaneidade, uma delas é a retirada exponencial dos pontos de contenção mais comuns. Do SQL Server 2012 em diante foram feitos aprimoramentos específicos nessa área ao aproveitar algoritmos de retirada exponencial para todos os spinlocks dentro do mecanismo.
Ao criar aplicativos de alto nível que precisam de escala e desempenho extremos, considere como manter o caminho do código, necessário no SQL Server, o mais curto possível. Um caminho do código mais curto significa que menos trabalho será executado pelo mecanismo de banco de dados. Isso naturalmente evitará os pontos de contenção. Muitas práticas recomendadas têm o efeito colateral de reduzir a quantidade de trabalho necessária do mecanismo resultando, portanto, na otimização do desempenho da carga de trabalho.
Veja, por exemplo, algumas práticas recomendadas anteriormente neste artigo:
Nomes totalmente qualificados: os nomes totalmente qualificados de todos os objetos resultarão na remoção da necessidade do SQL Server de executar caminhos do código obrigatórios para resolver os nomes. Também observamos pontos de contenção no tipo de spinlock SOS_CACHESTORE encontrado quando os nomes totalmente qualificados não são usados em chamadas para procedimentos armazenados. Uma falha em qualificar totalmente esses nomes resultará na necessidade do SQL Server de procurar o esquema padrão para o usuário, o que resultará na necessidade de obter um caminho do código mais longo para executar o SQL.
Consultas parametrizadas: outro exemplo é usar consultas parametrizadas e chamadas de procedimento armazenado a fim de reduzir o trabalho necessário para gerar planos de execução. Isso resultará novamente em um caminho do código mais curto para a execução.
Contenção LOCK_HASH: a contenção em determinada estrutura de bloqueio ou colisões de bucket de hash é inevitável em alguns casos. Embora o mecanismo do SQL Server particione a maioria das estruturas de bloqueio, ainda há momentos em que a aquisição de um bloqueio resultará no acesso ao mesmo bucket de hash. Por exemplo, um aplicativo acessa a mesma linha que vários threads de modo simultâneo (ou seja, dados de referência). É possível lidar com esses tipos de problemas usando técnicas que escalam horizontalmente os dados de referência dentro do esquema de banco de dados ou usem as dicas NOLOCK quando possível.
A primeira linha de defesa ao ajustar cargas de trabalho do SQL Server é sempre executar as práticas de ajuste padrão (por exemplo, indexação, otimização de consulta, otimização de E/S etc.). No entanto, além de executar o ajuste padrão, as práticas a seguir são uma abordagem importante, pois elas reduzem a quantidade necessária de código para executar as operações. Mesmo quando as práticas recomendadas são seguidas, ainda há uma chance de que uma contenção de spinlock possa ocorrer em sistemas ocupados e de alta simultaneidade. Usar as ferramentas e técnicas deste artigo poderá ajudar a isolar ou eliminar esses tipos de problemas, além de determinar quando será necessário acionar os recursos mais adequados da Microsoft para obter ajuda.
Esperamos que essas técnicas forneçam uma metodologia útil para esse tipo de solução de problemas, além de insights sobre algumas das técnicas mais avançadas de criação de perfil de desempenho disponíveis no SQL Server.
Apêndice: automatizar a captura de despejo de memória
O script de eventos estendidos a seguir provou ser útil para automatizar a cobrança de despejos de memória quando uma contenção de spinlock se torna significativa. Em alguns casos, os despejos de memória serão necessários para executar um diagnóstico completo do problema ou serão solicitados pelas equipes de Suporte da Microsoft para que seja executada uma análise detalhada. No SQL Server 2008, há um limite de 16 quadros em pilhas de chamadas capturadas pelo bucketizer, o que pode não ser grande o suficiente para determinar exatamente onde a pilha de chamadas está sendo inserida no mecanismo. O SQL Server 2012 introduziu aperfeiçoamentos aumentando para 32 o número de quadros capturados pelo bucketizer em pilhas de chamadas.
O seguinte script do SQL poderá ser usado para automatizar o processo de captura de despejos de memória a fim de ajudar a analisar a contenção de spinlock:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Apêndice: capturar estatísticas de spinlock ao longo do tempo
O script a seguir poderá ser usado para examinar as estatísticas de spinlock em um determinado período. Cada vez que o script for executado, ele retornará um delta entre os valores atuais e os valores coletados anteriormente.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;
Próxima etapa
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários