Visão geral: índices columnstore
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Os índices columnstore são o padrão para armazenar e consultar tabelas de fatos com armazenamento de dados grandes. Esse índice usa armazenamento de dados baseado em coluna e processamento de consultas para obter até 10 vezes mais desempenho de consulta em seu data warehouse em relação ao armazenamento tradicional orientado por linha. Também é possível obter ganhos de até 10 vezes na compactação de dados sobre o tamanho dos dados descompactados. A partir do SQL Server 2016 (13.x) SP1, os índices columnstore permitem a análise operacional: a capacidade de executar análises de desempenho em tempo real em uma carga de trabalho transacional.
Confira um cenário relacionado:
- Índices columnstore para data warehouse
- Introdução ao columnstore para análise operacional em tempo real
O que é um índice columnstore?
Um índice columnstore é uma tecnologia para armazenamento, recuperação e gerenciamento de dados usando um formato de dados colunar, chamado columnstore.
Termos e conceitos principais
Os termos e conceitos principais a seguir estão associados aos índices columnstore.
columnstore
Um columnstore são dados logicamente organizados como uma tabela com linhas e colunas e fisicamente armazenados em um formato de dados com reconhecimento de coluna.
Rowstore
Um rowstore são dados logicamente organizados como uma tabela com linhas e colunas e fisicamente armazenados em um formato de dados com reconhecimento de linha. Esse formato é o modo tradicional de armazenar dados da tabela relacional. No SQL Server, rowstore refere-se à uma tabela em que o formato de armazenamento de dados subjacente é um heap, um índice clusterizado ou uma tabela com otimização de memória.
Observação
Em discussões sobre índices columnstore, os termos rowstore e columnstore são usados para enfatizar o formato do armazenamento de dados.
Rowgroup
Um rowgroup é um grupo de linhas que são compactadas no formato columnstore ao mesmo tempo. Um rowgroup normalmente contém o número máximo de linhas por rowgroup que é 1.048.576 linhas.
Para taxas de alto desempenho e compactação, o índice columnstore fatia a tabela em rowgroups e depois compacta cada um desses rowgroups com um método com reconhecimento de coluna. O número de linhas no rowgroup deve ser grande o suficiente para melhorar as taxas de compactação e pequeno o suficiente para se beneficiar com as operações na memória.
Um rowgroup do qual todos os dados foram excluídos das transições do estado COMPACTADO para TOMBSTONE e, posteriormente, removidos por um processo em segundo plano denominado motor de tupla. Para mais informações sobre os status de rowgroup, veja sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Dica
Ter muitos rowgroups pequenos diminui a qualidade do índice columnstore. Até o SQL Server 2017 (14.x), uma operação de reorganização precisa mesclar rowgroups COMPACTADOS menores, seguindo uma política de limite interno que determina como remover linhas excluídas e combinar os rowgroups compactados.
A partir do SQL Server 2019 (15.X), uma tarefa de mesclagem em segundo plano também funciona para mesclar rowgroups COMPACTADOS dos quais um número grande de linhas foi excluído.
Depois de mesclar rowgroups menores, a qualidade do índice deve melhorar.
Observação
Começando com o SQL Server 2019 (15.x), Banco de Dados SQL do Azure, Instância Gerenciada de SQL do Azure e pools de SQL dedicados no Azure Synapse Analytics, o motor de tupla recebe ajuda de uma tarefa de mesclagem em segundo plano que compacta automaticamente rowgroups ABERTOS delta menores que existem há algum tempo, conforme determinado por um limite interno, ou mescla rowgroups COMPACTADOS dos quais foi excluído um número grande de linhas. Isso melhora a qualidade do índice columnstore ao longo do tempo.
Segmento de coluna
Um segmento de coluna é uma coluna de dados do rowgroup.
- Cada rowgroup contém um segmento de coluna para cada coluna na tabela.
- Cada segmento de coluna é compactado junto e armazenado em meio físico.
- Há metadados com cada segmento para permitir a eliminação rápida de segmentos sem lê-los.
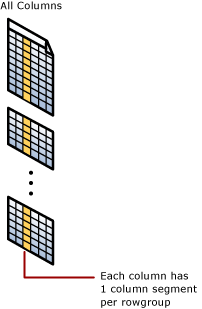
Índice columnstore clusterizado
Um índice columnstore clusterizado é o armazenamento físico da tabela inteira.
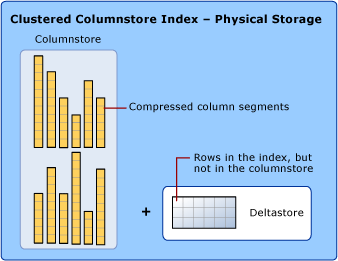
Para reduzir a fragmentação dos segmentos de coluna e melhorar o desempenho, o índice columnstore pode armazenar alguns dados temporariamente em um índice clusterizado, chamado deltastore, e em uma lista árvore B de IDs para linhas excluídas. As operações de deltastore são tratadas em segundo plano. Para retornar os resultados corretos da consulta, o índice columnstore clusterizado combina os resultados da consulta de columnstore e deltastore.
Observação
A documentação usa o termo árvore B geralmente em referência a índices. Em índices de rowstore, o Database Engine implementa uma árvore B+. Isso não se aplica a índices columnstore ou índice em tabelas com otimização de memória. Para obter mais informações, confira o Guia de arquitetura e design do índice do SQL Server e SQL do Azure.
Rowgroup delta
Um rowgroup delta é um índice de árvore B clusterizado usado somente com índices columnstore. Ele melhora o desempenho e a compactação do columnstore armazenando linhas até que o número de linhas alcance um limite (de 1.048.576 linhas) e depois é movido para o columnstore.
Quando um rowgroup delta alcança o número máximo de linhas, ele faz a transição do estado ABERTO para FECHADO. Um processo em segundo plano chamado de motor de tupla verifica os rowgroups fechados. Se o processo encontrar um rowgroup fechado, ele compactará o rowgroup delta e o armazenará no columnstore como um rowgroup COMPACTADO.
Quando um rowgroup delta é compactado, o grupo de rowgroup delta existente faz a transição para o estado TOMBSTONE a fim de ser removido posteriormente pelo motor de tupla quando não há nenhuma referência a ele.
Para mais informações sobre os status de rowgroup, veja sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Observação
A partir do SQL Server 2019 (15.x), o motor de tupla recebe a ajuda de uma tarefa de mesclagem em segundo plano que compacta automaticamente os rowgroups ABERTOS delta menores que existem há algum tempo, conforme determinado por um limite interno, ou mescla os rowgroups COMPACTADOS dos quais foi excluído um número grande de linhas. Isso melhora a qualidade do índice columnstore ao longo do tempo.
Deltastore
Um índice columnstore pode ter mais de um rowgroup delta. Todos os rowgroups delta são coletivamente chamados de deltastore.
Durante o carregamento em massa grande, a maioria das linhas vai diretamente para o columnstore sem passar pelo deltastore. No fim do carregamento em massa, o número de linhas pode ser muito pouco para atender ao tamanho mínimo de um rowgroup, que é de 102.400 linhas. Como resultado, as linhas finais vão para o deltastore, e não para o columnstore. Para carregamento em massa pequeno com menos de 102.400 linhas, todas as linhas vão diretamente para o deltastore.
índice columnstore não clusterizado
Um índice columnstore não clusterizado e um índice columnstore clusterizado funcionam da mesma maneira. A diferença é que um índice não clusterizado é um índice secundário criado em uma tabela rowstore, mas um índice columnstore clusterizado é o armazenamento primário da tabela inteira.
O índice não clusterizado contém uma cópia de parte ou de todas as linhas e colunas na tabela subjacente. O índice é definido como uma ou mais colunas da tabela e tem uma condição opcional que filtra as linhas.
Um índice columnstore não clusterizado permite análises operacionais em tempo real nas quais a carga de trabalho OLTP usa o índice clusterizado subjacente, enquanto as análises são executadas simultaneamente no índice columnstore. Para obter mais informações, veja Introdução ao columnstore para análise operacional em tempo real.
Execução em modo de lote
A execução em modo de lote é um método de processamento de consulta usado para processar várias linhas simultaneamente. A execução em modo de lote é estreitamente integrada ao formato de armazenamento columnstore e otimizada com base nele. A execução do modo em lote às vezes é conhecida como execução baseada em vetor ou vetorizada. Consultas em índices columnstore usam a execução em modo de lote, o que melhora o desempenho de consulta normalmente em duas a quatro vezes. Para saber mais, confira o Guia da arquitetura de processamento de consultas.
Por que devo usar um índice columnstore?
Um índice columnstore pode fornecer um nível muito alto de compactação de dados, geralmente de 10 vezes, para reduzir consideravelmente os custos de armazenamento em data warehouse. Para análises, um índice columnstore oferece um desempenho melhor de ordem de magnitude do que um índice de árvore B. Os índices columnstore são o formato de armazenamento de dados preferencial para data warehouse e cargas de trabalho de análise. A partir do SQL Server 2016 (13.x), você pode usar índices columnstore para análises em tempo real da sua carga de trabalho operacional.
Motivos pelos quais índices columnstore são tão rápidos:
colunas armazenam valores do mesmo domínio e normalmente têm valores semelhantes, o que resulta em altas taxas de compactação. Os gargalos de E/S em seu sistema são minimizados ou eliminados, e o volume de memória é reduzido consideravelmente.
As altas taxas de compactação melhoram o desempenho da consulta usando um volume de memória menor. Por sua vez, o desempenho da consulta pode ser melhorado porque o SQL Server pode realizar mais operações de consulta e dados na memória.
A execução em lote melhora o desempenho de consulta, normalmente em duas a quatro vezes, processando várias linhas simultaneamente.
Muitas vezes, as consultas selecionam apenas algumas colunas de uma tabela, o que reduz a E/S total da mídia física.
Quando devo usar um índice columnstore?
Casos de uso recomendados:
Use um índice columnstore clusterizado para armazenar tabelas de fatos e tabelas de dimensões grandes para cargas de trabalho de data warehouse. Esse método melhora o desempenho de consulta e a compactação de dados em até 10 vezes. Para mais informações, veja Índices columnstore para data warehouse.
Use um índice columnstore não clusterizado para análises de desempenho em tempo real em uma carga de trabalho OLTP. Para obter mais informações, veja Introdução ao columnstore para análise operacional em tempo real.
Para obter mais cenários de uso para índices columnstore, veja Escolher o melhor índice columnstore para suas necessidades.
Como escolher entre um índice rowstore e um índice columnstore?
Índices rowstore têm melhor desempenho em consultas nos dados, ao procurar um valor específico ou para consultas em um pequeno intervalo de valores. Use índices rowstore com cargas de trabalho transacionais, pois eles tendem a exigir principalmente buscas de tabela em vez de verificações de tabela.
Os índices columnstore oferecem altos ganhos de desempenho para consultas analíticas que examinam grandes quantidades de dados, especialmente em tabelas grandes. Use índices columnstore em cargas de trabalho de data warehouse e análise, especialmente em tabelas de fatos, pois eles tendem a exigir verificações de tabela completas em vez de buscas de tabela.
A partir do SQL Server 2022 (16.x), os índices columnstore clusterizados ordenados melhoram o desempenho de consultas com base em predicados de coluna ordenados. Os índices columnstore ordenados podem melhorar a eliminação de grupos de linhas, o que pode proporcionar melhorias de desempenho ignorando completamente os grupos de linhas. Para obter mais informações, consulte Ajuste de desempenho com índice columnstore clusterizado ordenado.
Posso combinar rowstore e columnstore na mesma tabela?
Sim. Começando com o SQL Server 2016 (13.x), você pode criar um índice columnstore não clusterizado atualizável em uma tabela rowstore. O índice columnstore armazena uma cópia das colunas selecionadas, então você precisa de espaço adicional para esses dados, mas os dados selecionados serão 10 vezes compactados, em média. Você pode executar análises no índice columnstore e transações no índice rowstore ao mesmo tempo. O columnstore é atualizado quando os dados são alterados na tabela rowstore, assim, ambos os índices trabalham com os mesmos dados.
A partir do SQL Server 2016 (13.x), você pode ter um ou mais índices rowstore não clusterizados em um índice columnstore, e executar pesquisas de tabela eficientes no columnstore subjacente. Outras opções também são disponibilizadas. Por exemplo, você pode impor uma restrição de chave primária usando uma restrição UNIQUE na tabela rowstore. Como um valor não exclusivo não pode ser inserido na tabela rowstore, o SQL Server não poderá inserir o valor no columnstore.
Metadados
Todas as colunas em um índice columnstore são armazenadas nos metadados como colunas incluídas. O índice columnstore não tem colunas de chave.
Tarefas relacionadas
Todas as tabelas relacionais usam rowstore como formato de dados subjacente, a menos que você as especifique como um índice columnstore clusterizado. CREATE TABLE cria uma tabela rowstore, a menos que a opção WITH CLUSTERED COLUMNSTORE INDEX seja especificada.
Ao criar uma tabela com a instrução CREATE TABLE, você pode criar a tabela como um columnstore especificando a opção WITH CLUSTERED COLUMNSTORE INDEX. Caso já tenha uma tabela rowstore e deseje convertê-la em um columnstore, use a instrução CREATE COLUMNSTORE INDEX.
| Tarefa | Artigos de referência | Observações |
|---|---|---|
| Crie uma tabela como columnstore. | CREATE TABLE (Transact-SQL) | Começando com o SQL Server 2016 (13.x), você pode criar a tabela como um índice columnstore clusterizado. Não é preciso criar primeiro uma tabela rowstore e convertê-la em columnstore. |
| Crie uma tabela com otimização de memória com um índice columnstore. | CREATE TABLE (Transact-SQL) | A partir do SQL Server 2016 (13.x), você pode criar uma tabela com otimização de memória com um índice columnstore. O índice columnstore também pode ser adicionado após a criação da tabela, usando a sintaxe ALTER TABLE ADD INDEX. |
| Converta uma tabela rowstore em columnstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Converta um heap ou árvore B existente em columnstore. Exemplos mostram como lidar com os índices existentes e o nome do índice ao realizar essa conversão. |
| Converta uma tabela columnstore em rowstore. | CREATE CLUSTERED INDEX (Transact-SQL) ou Converter uma tabela columnstore novamente em um heap rowstore | Geralmente, essa conversão não é necessária, mas pode haver ocasiões em que você precisa realizá-la. Exemplos mostram como converter um columnstore em uma pilha ou um índice clusterizado. |
| Crie um índice columnstore em uma tabela rowstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Uma tabela rowstore pode ter um índice columnstore. Começando com o SQL Server 2016 (13.x), o índice columnstore pode ter uma condição filtrada. Exemplos mostram a sintaxe básica. |
| Crie índices de alto desempenho para análises operacionais. | Introdução ao columnstore para análise operacional em tempo real | Descreve como criar índices de árvore B e columnstore complementares, para que as consultas OLTP usem índices de árvore B e as consultas de análise usem índices columnstore. |
| Crie índices columnstore de alto desempenho para data warehouse. | Índices columnstore para data warehouse | Descreve como usar índices de árvore B em tabelas columnstore para criar consultas de data warehouse de alto desempenho. |
| Use um índice de árvore B para impor uma restrição de chave primária em um índice columnstore. | Índices columnstore para data warehouse | Mostra como combinar índices columnstore e de árvore B para impor restrições de chave primária no índice columnstore. |
| Remover um índice columnstore. | DROP INDEX (Transact-SQL) | A remoção de um índice columnstore usa a sintaxe DROP INDEX padrão usada pelos índices de árvore B. A remoção de um índice columnstore clusterizado converte a tabela columnstore em uma pilha. |
| Excluir uma linha de um índice columnstore. | DELETE (Transact-SQL) | Use DELETE (Transact-SQL) para excluir uma linha. linha columnstore: o SQL Server marca a linha como excluída logicamente, mas não recupera o armazenamento físico da linha até que o índice seja recriado. linha deltastore: o SQL Server exclui a linha lógica e fisicamente. |
| Atualizar uma linha no índice columnstore. | UPDATE (Transact-SQL) | Use UPDATE (Transact-SQL) para atualizar uma linha. linha columnstore: o SQL Server marca a linha como excluída logicamente e insere a linha atualizada no deltastore. linha deltastore: o SQL Server atualiza a linha no deltastore. |
| Carregar dados em um índice columnstore. | Carregamento de dados dos índices columnstore | |
| Força todas as linhas no deltastore a ir para o columnstore. | ALTER INDEX (Transact-SQL) ... REBUILDReorganizar e recompilar índices |
ALTER INDEX com a opção REBUILD força todas as linhas a ir para o columnstore. |
| Desfragmentar um índice columnstore. | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE desfragmenta os índices columnstore online. |
| Mescle tabelas com índices columnstore. | MERGE (Transact-SQL) |
Conteúdo relacionado
- Novidades nos índices columnstore
- Índices columnstore – diretrizes de carregamento de dados
- Índices columnstore – desempenho de consultas
- Introdução ao Columnstore para análise operacional em tempo real
- Índices columnstore - Data Warehouse
- Desfragmentação de índices columnstore
- Guia de arquitetura e design de índices do SQL Server e do SQL do Azure
- Arquitetura de índices columnstore
- CREATE COLUMNSTORE INDEX (Transact-SQL)