Ajustar índices não clusterizados com sugestões de índice ausentes
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
O recurso de índices ausentes é uma ferramenta leve para encontrar índices ausentes que possam aprimorar significativamente o desempenho da consulta. Este artigo descreve como usar sugestões de índice ausente para ajustar índices de maneira eficaz e melhorar o desempenho da consulta.
Limitações do recurso de índice ausente
Quando o otimizador de consulta gera um plano de consulta, ele analisa quais são os melhores índices para uma condição de filtro específica. Mesmo que os melhores índices não existam, o otimizador de consulta gerará um plano de consulta usando os métodos de acesso de menor custo disponíveis, mas também armazenará informações sobre esses índices. O recurso de índices ausentes permite acessar essas informações sobre os melhores índices possíveis para que você possa decidir se deveriam ser implementados.
A otimização de consulta é um processo sensível ao fator tempo, portanto, há limitações para o recurso de índice ausente. As limitações incluem:
- As sugestões de índice ausente são baseadas em estimativas feitas durante a otimização de uma única consulta, antes da execução da consulta. As sugestões de índice ausente não são testadas nem atualizadas após a execução da consulta.
- O recurso de índice ausente sugere apenas índices rowstore não clusterizados baseados em disco. Índices exclusivos e filtrados não são sugeridos.
- As colunas de chave são sugeridas, mas a sugestão não especifica uma ordem para essas colunas. Para obter informações sobre como ordenar colunas, veja a seção Aplicar sugestões de índice ausente deste artigo.
- As colunas incluídas são sugeridas, mas o SQL Server não executa análise de custo-benefício em relação ao tamanho do índice resultante quando um grande número de colunas incluídas é sugerido.
- As solicitações de índice ausente podem oferecer variações semelhantes de índices na mesma tabela e na mesma coluna em outras consultas. É importante revisar sugestões de índice e combinar sempre que possível.
- Não são feitas sugestões para planos de consulta triviais.
- As informações de custos são menos precisas para consultas que envolvem somente predicados de desigualdade.
- As sugestões são reunidas para, no máximo, 600 grupos de índices ausentes. Depois que esse limite é alcançado, não são mais reunidos dados ausentes do grupo de índices.
Devido a essas limitações, as sugestões de índice ausente são melhor tratadas como uma das várias fontes de informações ao executar análise, design, ajuste e teste de índice. As sugestões de índice ausente não são determinações para criar índices exatamente como sugerido.
Observação
O Banco de Dados SQL do Azure oferece ajuste automático de índice. O ajuste automático de índice usa aprendizado de máquina para aprender horizontalmente com todos os bancos de Banco de Dados SQL do Azure por meio de IA e melhorar dinamicamente as ações de ajuste. O ajuste automático de índice inclui um processo de verificação para garantir que haja um aprimoramento positivo no desempenho da carga de trabalho com os índices criados.
Exibir recomendações de índice ausente
O recurso de índices ausentes consiste em dois componentes:
- O elemento
MissingIndexesno XML dos planos de execução. Ele possibilita correlacionar índices que o otimizador de consulta considera ausentes nas consultas para as quais eles estão ausentes. - Um conjunto de DMVs (exibições de gerenciamento dinâmico) que pode ser consultado para retornar informações sobre índices ausentes. Ele permite que você veja todas as recomendações de índices ausentes de um banco de dados.
Exibir sugestões de índice ausente em planos de execução
Os planos de execução de consulta podem ser gerados ou obtidos de várias maneiras:
- Ao escrever ou ajustar uma consulta, você pode usar o SSMS (SQL Server Management Studio) para exibir o plano de execução estimado sem executar a consulta ou executar a consulta e exibir um plano de execução real.
- O Repositório de Consultas, quando habilitado, coleta planos de execução.
- Você pode identificar planos de execução armazenados em cache consultando DMVs como sys.dm_exec_text_query_plan.
Por exemplo, você pode usar a consulta a seguir para gerar solicitações de índice ausentes no banco de dados de exemplo AdventureWorks.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
Para gerar e exibir as solicitações de índice ausente:
Abra o SSMS e conecte uma sessão à sua cópia do banco de dados de exemplo AdventureWorks.
Cole a consulta na sessão e gere um plano de execução estimado para a consulta no SSMS, selecionando o botão Exibir Plano de Execução Estimado da barra de ferramentas. O plano de execução será exibido em um painel na sessão atual. Uma indicação de Índice Ausente na cor verde aparecerá próximo à parte superior do plano gráfico.

Um único plano de execução pode conter várias solicitações de índice ausente, mas apenas uma solicitação de índice ausente pode ser exibida no plano de execução gráfico. Uma opção para ver uma lista completa de índices ausentes de um plano de execução é exibir o XML do plano de execução.
Clique com o botão direito do mouse no plano de execução e selecione Mostrar XML do Plano de Execução... no menu.
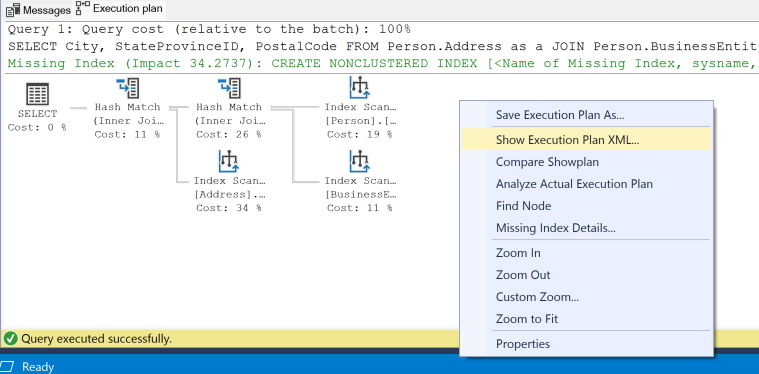
O XML do plano de execução será aberto como uma nova guia dentro do SSMS.
Observação
Apenas uma única sugestão de índice ausente será mostrada na opção de menu Detalhes do Índice Ausente..., mesmo se várias sugestões estiverem presentes no XML do plano de execução. A sugestão de índice ausente exibida pode não ser aquela com o aprimoramento estimado mais alto para a consulta.
Exiba a caixa de diálogo Encontrar usando o atalho CTRL+f.
Pesquise por
MissingIndex.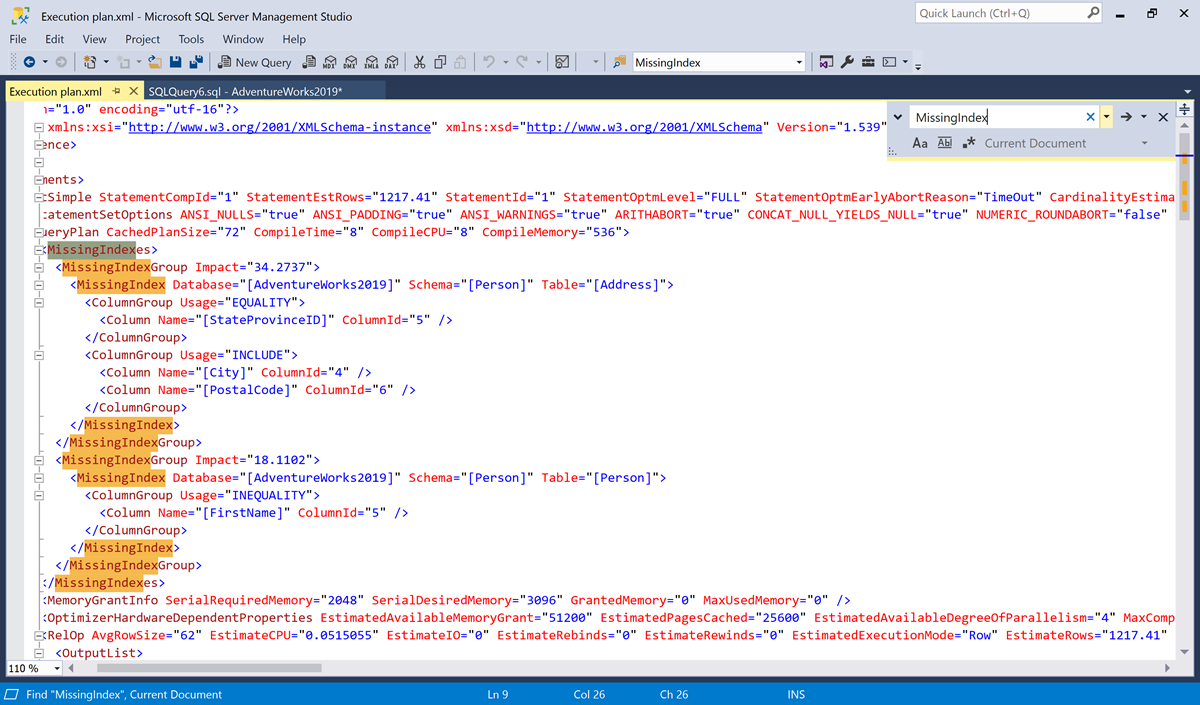
Neste exemplo, há dois elementos
MissingIndex.- O primeiro índice ausente sugere que a consulta poderia usar um índice na tabela
Person.Addressque desse suporte a uma pesquisa de igualdade na colunaStateProvinceID, que inclui mais duas colunas,CityePostalCode'. No momento da otimização, o otimizador de consulta acreditava que esse índice poderia reduzir o custo estimado da consulta em 34,2737%. - O segundo índice ausente sugere que a consulta poderia usar um índice na tabela
Person.Personque desse suporte a uma pesquisa de desigualdade na coluna FirstName. No momento da otimização, o otimizador de consulta acreditava que esse índice poderia reduzir o custo estimado da consulta em 18,1102%.
- O primeiro índice ausente sugere que a consulta poderia usar um índice na tabela


Cada índice não clusterizado baseado em disco de seu banco de dados ocupa espaço, adiciona sobrecarga para inserções, atualizações e exclusões e pode exigir manutenção. Por esses motivos, a melhor prática é revisar todas as solicitações de índices ausentes de uma tabela e os índices existentes de uma tabela antes de adicionar um índice com base em um plano de execução de consulta.
Exibir sugestões de índice ausente em DMVs
Você pode recuperar informações sobre índices ausentes consultando os objetos de gerenciamento dinâmico listados na tabela a seguir.
| Exibição de gerenciamento dinâmico | Informações retornadas |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | Retorna informações resumidas sobre grupos de índices ausentes, por exemplo, as melhorias de desempenho que poderiam ser obtidas com a implementação de um grupo específico de índices ausentes. |
| sys.dm_db_missing_index_groups (Transact-SQL) | Retorna informações sobre um grupo específico de índices ausentes, como o identificador de grupo e os identificadores de todos os índices ausentes contidos nesse grupo. |
| sys.dm_db_missing_index_details (Transact-SQL) | Retorna informações detalhadas sobre um índice ausente; Por exemplo, ele retorna o nome e o identificador da tabela em que o índice está ausente e os tipos de colunas e colunas que devem compor o índice ausente. |
| sys.dm_db_missing_index_columns (Transact-SQL) | Retorna informações sobre as colunas de tabela de banco de dados que estão ausentes em um índice. |
A consulta a seguir usa os DMVs de índices ausentes para gerar instruções CREATE INDEX. As instruções de criação de índice aqui destinam-se a ajudar você a criar sua própria DDL depois de examinar todas as solicitações da tabela junto com os índices existentes na tabela.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
Essa consulta ordena as sugestões por uma coluna chamada estimated_improvement. O aprimoramento estimado baseia-se em uma combinação de:
- O custo estimado das consultas associadas à solicitação de índice ausente.
- O impacto estimado da adição do índice. Essa é uma estimativa de quanto o índice não clusterizado reduziria o custo da consulta.
- A soma das execuções de operadores de consulta (buscas e verificações) que foram executados nas consultas associadas à solicitação de índice ausente. Como discutimos em persistir índices ausentes com o Repositório de Consultas, essas informações são limpas periodicamente.
Observação
O script Index-Creation da Caixa de Ferramentas da Tiger da Microsoft examina DMVs de índices ausentes e remove automaticamente os índices sugeridos redundantes, analisa índices de baixo impacto e gera scripts de criação de índice para sua revisão. Como na consulta acima, ele NÃO executa comandos de criação de índice. O script Index-Creation é adequado para o SQL Server e a Instância Gerenciada de SQL do Azure. Para o Banco de Dados SQL do Azure, considere implementar o ajuste automático de índice.
Revise as Limitações do recurso de índice ausente e como aplicar sugestões de índice ausente antes de criar índices e modifique o nome do índice para corresponder à convenção de nomenclatura do seu banco de dados.
Persistir índices ausentes com o Repositório de Consultas
As sugestões de índices ausentes em DMVs são limpas por eventos como reinicializações de instância, failovers e a definição de um banco de dados como offline. Além disso, quando os metadados de uma tabela forem alterados, todas as informações de índice ausente sobre aquela tabela serão excluídas desses objetos de gerenciamento dinâmicos. As alterações nos metadados da tabela podem ocorrer quando colunas são adicionadas ou descartadas de uma tabela, por exemplo, ou quando um índice é criado em uma coluna de uma tabela. Executar uma operação ALTER INDEX REBUILD em um índice de uma tabela também limpa as solicitações de índice ausente dessa tabela.
Da mesma forma, os planos de execução armazenados no cache do plano são limpos por eventos como reinicializações de instância, failovers e a definição de um banco de dados como offline. Os planos de execução podem ser removidos do cache devido à pressão de memória e recompilações.
As sugestões de índice ausente em planos de execução podem ser persistidas entre esses eventos habilitando o Repositório de Consultas.
A consulta a seguir recupera os primeiros 20 planos de consulta que contêm solicitações de índices ausentes no repositório de consultas com base em uma estimativa aproximada do total de leituras lógicas para a consulta. Os dados estão limitados às execuções de consulta das últimas 48 horas.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Aplicar sugestões de índice ausente
Para usar sugestões de índice ausente com de maneira efetiva, siga as diretrizes de design de índice não clusterizado. Ao ajustar índices não clusterizados com sugestões de índice ausente, revise a estrutura da tabela base, combine cuidadosamente os índices, considere a ordem da coluna de chave e revise as sugestões de coluna incluídas.
Revisar a estrutura da tabela base
Antes de criar índices não clusterizados em uma tabela com base em sugestões de índice ausente, revise o índice clusterizado da tabela.
Uma forma de verificar se há um índice clusterizado é usando o procedimento armazenado do sistema sp_helpindex. Por exemplo, podemos ver um resumo dos índices da tabela Person.Address executando a seguinte instrução:
exec sp_helpindex 'Person.Address';
GO
Analise a coluna index_description. Uma tabela pode ter apenas um índice clusterizado. Se um índice clusterizado tiver sido implementado para a tabela, o index_description conterá a palavra "clustered".

Se nenhum índice clusterizado estiver presente, a tabela será um heap. Nesse caso, verifique se a tabela foi criada intencionalmente como um heap para resolver um problema de desempenho específico. A maioria das tabelas se beneficia de índices clusterizados; geralmente, as tabelas são implementadas como heaps por acidente. Considere implementar um índice clusterizado com base nas diretrizes de design de índice clusterizado.
Revisar a sobreposição de índices ausentes e índices existentes
Os índices ausentes podem oferecer variações semelhantes de índices não clusterizados na mesma tabela e na mesma coluna em outras consultas. Índices ausentes também podem ser semelhantes aos índices existentes em uma tabela. Para obter um desempenho ideal, é melhor examinar se há sobreposição de índices ausentes e índices existentes e evitar a criação de índices duplicados.
Script de índices existentes em uma tabela
Uma forma de examinar a definição de índices existentes em uma tabela é fazer script dos índices com Detalhes do Pesquisador de Objetos:
- Conecte o Pesquisador de Objetos à sua instância ou ao seu banco de dados.
- Expanda o nó do banco de dados em questão no Pesquisador de Objetos.
- Expanda a pasta Tabelas .
- Expanda a tabela para a qual você gostaria de fazer script dos índices.
- Selecione a pasta Índices.
- Se o painel Detalhes do Pesquisador de Objetos ainda não estiver aberto, no menu Exibir, selecione Detalhes do Pesquisador de Objetos ou pressione F7.
- Selecione todos os índices listados no painel Detalhes do Pesquisador de Objetos com o atalho CTRL+a.
- Clique com o botão direito do mouse em qualquer lugar na região selecionada e selecione a opção de menu Script de índice como e, em seguida, CREATE em e Nova Janela do Editor de Consultas.

Revisar índices e combinar sempre que possível
Revise as recomendações de índices ausentes de uma tabela como um grupo, juntamente com as definições de índices existentes na tabela. Lembre-se de que, ao definir índices, as colunas de igualdade geralmente devem ser colocadas antes das colunas de desigualdade e juntas devem formar a chave do índice. Para determinar uma ordem efetiva para as colunas desiguais, ordene-as com base em sua seletividade: liste as colunas mais seletivas primeiro (a mais à esquerda na lista de colunas). As colunas exclusivas são mais seletivas, enquanto as colunas com muitos valores repetidos são menos seletivas.
As colunas incluídas devem ser adicionadas à instrução CREATE INDEX com a cláusula INCLUDE. A ordem das colunas incluídas não afeta o desempenho da consulta. Portanto, ao combinar índices, as colunas incluídas podem ser combinadas sem se preocupar com a ordem. Saiba mais nas diretrizes de colunas incluídas.
Por exemplo, você pode ter uma tabela, Person.Address, com um índice existente na coluna de chave StateProvinceID. Você pode ver recomendações de índice ausente da tabela Person.Address para as seguintes colunas:
- Filtros EQUALITY para
StateProvinceIDeCity - Filtros EQUALITY para
StateProvinceIDeCity, INCLUDEPostalCode
A modificação do índice existente para corresponder à segunda recomendação, um índice com chaves em StateProvinceID e City, incluindo PostalCode, provavelmente atenderia às consultas que geraram as duas sugestões de índice.
As considerações de vantagens e desvantagens são comuns no ajuste de índice. É provável que, para muitos conjuntos de dados, a coluna City seja mais seletiva do que a coluna StateProvinceID. No entanto, se nosso índice existente em StateProvinceID for muito usado e outras solicitações pesquisarem em grande parte em StateProvinceID e City, será uma sobrecarga geral menor para o banco de dados ter um único índice com ambas as colunas na chave, a principal sendo StateProvinceID, embora essa não seja a coluna mais seletiva.
Os índices podem ser modificados de várias maneiras:
- Você pode usar a instrução CREATE INDEX com a cláusula DROP_EXISTING. Você pode renomear os índices após a modificação para que o nome continue descrevendo com precisão a definição do índice, dependendo de sua convenção de nomenclatura.
- Você pode usar a instrução DROP INDEX (Transact-SQL) seguida por uma instrução CREATE INDEX.
A ordem das chaves de índice é importante ao combinar as sugestões de índice: City como coluna principal é diferente de StateProvinceID como coluna principal. Saiba mais em diretrizes de design de índice não clusterizado.
Ao criar índices, considere usar operações de indexação online quando elas estão disponíveis.
Embora os índices possam aprimorar muito o desempenho da consulta em alguns casos, eles também têm custos de sobrecarga e gerenciamento. Examine as diretrizes gerais de design de índice para ajudar a avaliar o benefício dos índices antes de criá-los.
Verificar se a alteração de índice foi bem-sucedida
É importante confirmar se as alterações de índice foram bem-sucedidas: o otimizador de consulta está usando os índices?
Uma forma de validar as alterações de índice é usar o Repositório de Consultas para identificar consultas com solicitações de índices ausentes. Observe a query_id das consultas. Use a exibição Consultas Rastreadas no Repositório de Consultas para verificar se os planos de execução foram alterados em uma consulta e se o otimizador está usando o índice novo ou modificado. Saiba mais sobre Consultas Rastreadas em começar com a solução de problemas de desempenho de consulta.
Conteúdo relacionado
Saiba mais sobre índice e ajuste de desempenho nos seguintes artigos:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários