Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Sistema de Plataforma de Análise (PDW)
Sistema de Plataforma de Análise (PDW)![]() Base de dados SQL no Microsoft Fabric
Base de dados SQL no Microsoft Fabric
O SQL Server usa junções para recuperar dados de várias tabelas com base em relações lógicas entre elas. As junções são fundamentais para operações de banco de dados relacional e permitem combinar dados de duas ou mais tabelas em um único conjunto de resultados.
O SQL Server implementa operações de junção lógica (definidas pela sintaxe Transact-SQL) e operações de junção física (os algoritmos reais usados para executar as junções). Compreender ambos os aspetos ajuda a escrever consultas eficientes e otimizar o desempenho do banco de dados.
As operações de junção lógica incluem:
- Junções internas
- Junções externas à esquerda, à direita e completas
- Junções cruzadas
As operações de junção física incluem:
- Loops aninhados se unem
- Mesclar junções
- Junções por Hash
- Junções adaptáveis (Aplica-se a: SQL Server 2017 (14.x) e versões posteriores)
Este artigo explica como as junções funcionam, quando usar diferentes tipos de junção e como o Otimizador de Consulta seleciona o algoritmo de junção mais eficiente com base em fatores como tamanho da tabela, índices disponíveis e distribuição de dados.
Note
Para obter mais informações sobre a sintaxe de junções, consulte a cláusula FROM, bem como JOIN, APPLY e PIVOT.
Junte-se aos fundamentos
Usando junções, você pode recuperar dados de duas ou mais tabelas com base em relações lógicas entre as tabelas. As associações indicam como o SQL Server deve usar dados de uma tabela para selecionar as linhas em outra tabela.
Uma condição de junção define a maneira como duas tabelas são relacionadas em uma consulta por:
- Especificando a coluna de cada tabela a ser usada para a junção. Uma condição de junção típica especifica uma chave estrangeira de uma tabela e sua chave associada na outra tabela.
- Especificar um operador lógico (por exemplo, = ou <>,) a ser usado na comparação de valores das colunas.
As junções são expressas logicamente usando a seguinte sintaxe Transact-SQL:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
As junções internas podem ser especificadas nas cláusulas FROM ou WHERE.
As junções externas e cruzadas só podem ser especificadas na FROM cláusula. **
As condições de junção combinam-se com as condições de pesquisa WHERE e HAVING para controlar as linhas selecionadas nas tabelas base referenciadas na cláusula FROM.
Especificar as condições de junção na FROM cláusula ajuda a separá-las de quaisquer outras condições de pesquisa que possam ser especificadas em uma WHERE cláusula e é o método recomendado para especificar junções. Uma sintaxe simplificada de junção de cláusula ISO FROM é:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- O join_type especifica que tipo de junção é executada: uma junção interna, externa ou cruzada. Para explicações sobre os diferentes tipos de junções, consulte a cláusula FROM.
- O join_condition define o predicado a ser avaliado para cada par de linhas unidas.
O código a seguir é um exemplo de uma FROM especificação de junção de cláusula:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
O código a seguir é uma declaração simples SELECT utilizando esta operação de junção:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
A SELECT declaração retorna as informações do produto e do fornecedor para qualquer combinação de peças fornecidas por uma empresa para a qual o nome da empresa começa com a letra F e o preço do produto é superior a US $ 10.
Quando várias tabelas são referenciadas em uma única consulta, todas as referências de coluna devem ser inequívocas. No exemplo anterior, tanto a tabela ProductVendor quanto a Vendor têm uma coluna chamada BusinessEntityID. Qualquer nome de coluna duplicado entre duas ou mais tabelas referenciadas na consulta deve ser qualificado com o nome da tabela. Todas as referências às Vendor colunas no exemplo são qualificadas.
Quando um nome de coluna não é duplicado em duas ou mais tabelas usadas na consulta, as referências a ele não precisam ser qualificadas com o nome da tabela. Isso é mostrado no exemplo anterior.
SELECT Tal cláusula às vezes é difícil de entender porque não há nada para indicar a tabela que forneceu cada coluna. A legibilidade da consulta será melhorada se todas as colunas forem qualificadas com os respetivos nomes de tabela. A legibilidade é melhorada se forem utilizados aliases de tabela, especialmente quando os próprios nomes das tabelas têm de ser qualificados com o banco de dados e os nomes dos proprietários. O código a seguir é o mesmo exemplo, exceto que aliases de tabela foram atribuídos e as colunas qualificadas com aliases de tabela para melhorar a legibilidade:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Os exemplos anteriores especificaram as condições de junção na FROM cláusula, que é o método preferido. A consulta a seguir contém a mesma condição de junção especificada na WHERE cláusula:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
A SELECT lista de uma junção pode fazer referência a todas as colunas nas tabelas unidas ou a qualquer subconjunto das colunas. A SELECT lista não precisa conter colunas de todas as tabelas na associação. Por exemplo, em uma junção de três tabelas, apenas uma tabela pode ser usada para fazer a ponte de uma das outras tabelas para a terceira tabela, e nenhuma das colunas da tabela do meio precisa ser referenciada na lista de seleção. Isso também é chamado de anti semi junção.
Embora as condições de junção geralmente tenham comparações de igualdade (=), outras comparações ou operadores relacionais podem ser especificados, assim como outros predicados. Para obter mais informações, consulte Operadores de comparação e ONDE.
Quando o SQL Server processa junções, o Otimizador de Consultas escolhe o método mais eficiente (entre várias possibilidades) de processar a associação. Isso inclui escolher o tipo mais eficiente de junção física, a ordem na qual as tabelas serão unidas e até mesmo usar tipos de operações de junção lógica que não podem ser expressas diretamente com Transact-SQL sintaxe, como semijunções e anti-semi-junções. A execução física de várias junções pode usar muitas otimizações diferentes e, portanto, não pode ser prevista de forma confiável. Para obter mais informações sobre junções parciais e anti-junções parciais, consulte Referência de operador de showplan lógico e físico.
As colunas usadas em uma condição de junção não precisam ter o mesmo nome ou ser do mesmo tipo de dados. No entanto, se os tipos de dados não forem idênticos, eles deverão ser compatíveis ou ser tipos que o SQL Server possa converter implicitamente. Se os tipos de dados não puderem ser convertidos implicitamente, a condição de junção deverá converter explicitamente o tipo de dados usando a CAST função. Para obter mais informações sobre conversões implícitas e explícitas, consulte Conversão de tipo de dados (Mecanismo de Banco de Dados).
A maioria das consultas usando uma junção pode ser reescrita usando uma subconsulta (uma consulta aninhada em outra consulta) e a maioria das subconsultas pode ser reescrita como junções. Para obter mais informações sobre subconsultas, consulte Subconsultas (SQL Server).
Note
As tabelas não podem ser juntadas diretamente em colunas do tipo ntext, text ou image. No entanto, as tabelas podem ser unidas indiretamente em colunas ntext, text ou image usando SUBSTRING.
Por exemplo, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) executa uma junção interna de duas tabelas nos primeiros 20 caracteres de cada coluna de texto em tabelas t1 e t2.
Além disso, outra possibilidade de comparar ntext ou colunas de texto de duas tabelas é comparar os comprimentos das colunas com uma WHERE cláusula, por exemplo: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Compreender as uniões de loops aninhados
Se uma entrada de junção for pequena (menos de 10 linhas) e a outra entrada de junção for bastante grande e indexada nas suas colunas de junção, uma junção por loops aninhados usando índice será a operação de junção mais rápida, pois exige o mínimo de E/S e o menor número de comparações.
A junção de loops aninhados, também chamada iteração aninhada, utiliza uma entrada de junção como a tabela de entrada externa (mostrada como a entrada superior no plano de execução gráfica) e outra como a tabela de entrada interna (inferior). O loop externo consome a tabela de entrada externa linha por linha. O loop interno, executado para cada linha externa, procura linhas correspondentes na tabela de entrada interna.
No caso mais simples, a pesquisa verifica uma tabela ou índice inteiro; isso é chamado de junção de loops aninhados simples. Se a pesquisa explorar um índice, ela será chamada de associação de loops aninhados de índice. Se o índice for criado como parte do plano de consulta (e destruído após a conclusão da consulta), ele será chamado de associação de loops aninhados de índice temporários. Todas essas variantes são consideradas pelo Otimizador de Consultas.
Uma junção de ciclos aninhados é particularmente eficaz se a entrada externa for pequena e a entrada interna for grande e pré-indexada. Em muitas transações pequenas, como aquelas que afetam apenas um pequeno conjunto de linhas, as junções de loops aninhados com índice são superiores às junções de mesclagem e às junções de hash. Em consultas grandes, no entanto, as uniões de loops aninhadas geralmente não são a escolha ideal.
Quando o atributo OPTIMIZED de um operador de junção de Loops Aninhados é definido como True, isso significa que um Loops Aninhados Otimizados (ou Batch Sort) é usado para minimizar a E/S quando a tabela lateral interna é grande, independentemente de ser paralelizada ou não. A presença dessa otimização em um determinado plano pode não ser muito óbvia ao analisar um plano de execução, dado que a classificação em si é uma operação oculta. Mas, ao procurar o atributo OPTIMIZED no XML do plano, isso indica que a junção Nested Loops pode tentar reordenar as linhas de entrada para melhorar o desempenho de operações de entrada/saída.
Mesclar junções
Se as duas entradas de junção não forem pequenas, mas forem classificadas em sua coluna de junção (por exemplo, se tiverem sido obtidas pela verificação de índices classificados), uma junção de mesclagem será a operação de junção mais rápida. Se ambas as entradas de junção forem grandes e as duas entradas forem de tamanhos semelhantes, uma junção de mistura com ordenamento prévio e uma junção de hash oferecerão desempenho semelhante. No entanto, as operações de junção de hash geralmente são muito mais rápidas se os dois tamanhos de entrada diferirem significativamente um do outro.
A junção por mescla requer que ambas as entradas sejam ordenadas nas colunas de junção, que são definidas pelas cláusulas de igualdade (ON) do predicado de junção. O otimizador de consulta normalmente verifica um índice, se existir no conjunto adequado de colunas, ou coloca um operador de classificação abaixo da junção de mesclagem. Em casos raros, pode haver várias cláusulas de igualdade, mas as colunas de mesclagem são retiradas de apenas algumas das cláusulas de igualdade disponíveis.
Como cada entrada é classificada, o operador Merge Join obtém uma linha de cada entrada e as compara. Por exemplo, para operações de junção interna, as linhas são retornadas se forem iguais. Se eles não forem iguais, a linha de valor mais baixo será descartada e outra linha será obtida a partir dessa entrada. Este processo repete-se até que todas as linhas tenham sido processadas.
A operação de "merge join" pode ser uma operação regular ou de muitos para muitos. Uma junção de mesclagem muitos-para-muitos usa uma tabela temporária para armazenar linhas. Se houver valores duplicados de cada entrada, uma das entradas tem que retroceder para o início de cada valor duplicado à medida que cada duplicado da outra entrada é processado.
Se um predicado residual estiver presente, todas as linhas que satisfazem o predicado de mesclagem avaliam o predicado residual, e somente as linhas que o satisfazem são retornadas.
A junção de mesclagem em si é muito rápida, mas pode ser uma escolha cara se as operações de classificação forem necessárias. No entanto, se o volume de dados for grande e os dados desejados puderem ser obtidos a partir de índices B-tree existentes, a merge join geralmente é o algoritmo de junção mais rápido disponível.
Junções por Hash
As junções de hash podem processar com eficiência entradas grandes, não ordenadas e não indexadas. Eles são úteis para resultados intermediários em consultas complexas porque:
- Os resultados intermediários não são indexados (a menos que explicitamente salvos no disco e, em seguida, indexados) e, muitas vezes, não são classificados adequadamente para a próxima operação no plano de consulta.
- Os otimizadores de consulta estimam apenas tamanhos de resultados intermediários. Como as estimativas podem ser muito imprecisas para consultas complexas, os algoritmos para processar resultados intermediários não só devem ser eficientes, mas também devem degradar-se graciosamente se um resultado intermediário for muito maior do que o previsto.
A junção de hash permite reduções no uso da desnormalização. A desnormalização é normalmente usada para obter um melhor desempenho reduzindo as operações de junção, apesar dos perigos de redundância, como atualizações inconsistentes. As junções de hash reduzem a necessidade de desnormalização. As junções de hash permitem que o particionamento vertical (representando grupos de colunas de uma única tabela em arquivos ou índices separados) se torne uma opção viável para o design de banco de dados físico.
A junção de hash tem duas entradas: a entrada de compilação e a entrada de teste . O otimizador de consulta atribui essas funções para que a menor das duas entradas seja a entrada de compilação.
As junções de hash são usadas para muitos tipos de operações de correspondência de conjuntos: junção interna; junção externa esquerda, direita e completa; semi-junção esquerda e direita; intersecção; união; e diferença. Além disso, uma variante da junção de hash pode remover duplicados e realizar agrupamentos, como SUM(salary) GROUP BY department. Essas modificações usam apenas uma entrada para as funções de compilação e teste.
As seguintes seções descrevem diferentes tipos de junções de hash: junção de hash em memória, junção de hash grace e junção de hash recursiva.
Junção de hash na memória
A junção de hash primeiro verifica ou calcula toda a entrada de construção e, em seguida, cria uma tabela de hash na memória. Cada linha é inserida em um bucket de hash dependendo do valor de hash calculado para a chave de hash. Se toda a entrada de compilação for menor do que a memória disponível, todas as linhas podem ser inseridas na tabela de hash. Esta fase de construção é seguida pela fase de sonda. Toda a entrada da sonda é digitalizada ou computada uma linha de cada vez e, para cada linha da sonda, o valor da chave de hash é calculado, o bucket de hash correspondente é examinado e as correspondências são produzidas.
Junção de hash Grace
Se a entrada de compilação não couber na memória, uma junção de hash prossegue em várias etapas. Conhecido como "grace hash join". Cada etapa tem uma fase de construção e uma fase de sonda. Inicialmente, todas as entradas de compilação e teste são consumidas e particionadas (usando uma função de hash nas chaves de hash) em vários arquivos. Usar a função hash nas teclas de hash garante que quaisquer dois registros de junção devem estar no mesmo par de arquivos. Portanto, a tarefa de unir duas entradas grandes foi reduzida a várias instâncias, mas menores, das mesmas tarefas. A junção de hash é então aplicada a cada par de arquivos particionados.
Junção de hash recursiva
Se a entrada de compilação for tão grande que as entradas para uma mesclagem externa padrão exigiriam vários níveis de mesclagem, várias etapas de particionamento e vários níveis de particionamento serão necessários. Se apenas algumas das partições forem grandes, etapas adicionais de particionamento serão usadas apenas para essas partições específicas. Para tornar todas as etapas de particionamento o mais rápido possível, operações de E/S grandes e assíncronas são usadas para que um único thread possa manter várias unidades de disco ocupadas.
Note
Se a entrada de construção for apenas ligeiramente maior do que a memória disponível, os elementos de junção de hash na memória e junção de hash de Grace são combinados num único passo, produzindo uma junção de hash híbrida.
Nem sempre é possível durante a otimização determinar qual junção de hash é usada. Portanto, o SQL Server começa usando uma junção de hash na memória e gradualmente faz a transição para a junção de hash grace e a junção de hash recursiva, dependendo do tamanho da entrada de compilação.
Se o Otimizador de Consulta antecipar erroneamente qual das duas entradas é menor e, portanto, deveria ter sido a entrada de compilação, as funções de compilação e teste serão invertidas dinamicamente. A junção de hash garante que ela use o arquivo de estouro menor como entrada de compilação. Esta técnica é chamada de inversão de papéis. A inversão de função ocorre dentro da junção de hash após pelo menos um derramamento para o disco.
Note
A inversão de função ocorre independentemente de qualquer sugestão ou estrutura de consulta. A inversão de função não é exibida no seu plano de consulta; Quando ocorre, é transparente para o usuário.
Mecanismo de resgate de hash
O termo resgate de hash às vezes é usado para descrever junções de hash de graça ou junções de hash recursivas.
Note
Junções de hash recursivas ou hash bailouts causam performance reduzida no seu servidor. Se você vir muitos eventos de Aviso de Hash em um rastreamento, atualize as estatísticas nas colunas que estão sendo associadas.
Para obter mais informações sobre resgate de hash, consulte Classe de evento de aviso de hash.
Junções adaptáveis
Junções Adaptativas em Modo de Lote permitem que a escolha de um método de junção por hash ou junção por loops aninhados seja adiada até após a primeira entrada ter sido analisada. O operador Adaptive Join define um limite que é utilizado para decidir quando alternar para um plano de Nested Loops. Um plano de consulta pode, portanto, alternar dinamicamente para uma melhor estratégia de junção durante a execução sem ter que ser recompilado.
Tip
Cargas de trabalho com oscilações frequentes entre pequenas e grandes análises de entrada de junção serão as que mais se beneficiarão deste recurso.
A decisão de tempo de execução é baseada nas seguintes etapas:
- Se a contagem de linhas da entrada de junção de compilação for pequena o suficiente para que uma junção de Loops Aninhados seja mais ideal do que uma junção de Hash, o plano alternará para um algoritmo de Loops Aninhados.
- Se a entrada da junção de compilação exceder um limite específico de contagem de linhas, nenhuma mudança ocorrerá e o seu plano continuará com uma junção de Hash.
A consulta a seguir é usada para ilustrar um exemplo de Adaptive Join:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
A consulta retorna 336 linhas. A habilitação das Estatísticas de Consulta ao Vivo exibe o seguinte plano:

No plano, observe o seguinte:
- Uma varredura de índice columnstore usada para fornecer linhas para a fase de construção da junção de hash.
- O novo operador de junção adaptativa. Este operador define um limite que é usado para decidir quando mudar para um plano de loops aninhados. Neste exemplo, o limite é de 78 linhas. Qualquer coisa com >= 78 linhas usará uma associação Hash. Se for menor que o limite, uma associação de Loops Aninhados será usada.
- Como a consulta retorna 336 linhas, isso excedeu o limite e, portanto, a segunda ramificação representa a fase de teste de uma operação de junção de hash padrão. Live Query Statistics mostra linhas que fluem através dos operadores - neste caso, "672 de 672".
- E a última ramificação é uma operação de procura de índice clusterizado que é utilizada pela junção Nested Loops se o limite não tiver sido excedido. Vemos "0 de 336" linhas exibidas (a ramificação não é usada).
Agora compare o plano com a mesma consulta, mas quando o valor de Quantity tiver apenas uma linha na tabela.
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
A consulta retorna uma linha. A habilitação das Estatísticas de Consulta ao Vivo exibe o seguinte plano:
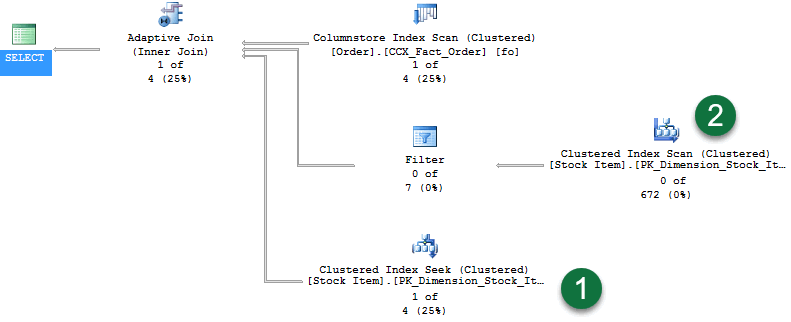
No plano, observe o seguinte:
- Com uma linha retornada, o Clustered Index Seek agora tem linhas fluindo através dela.
- E como a fase de compilação do Hash Join não continuou, não há linhas fluindo pela segunda ramificação.
Comentários do Adaptive Join
As junções adaptáveis exigem mais memória do que um plano equivalente de Nested Loops Join indexado. A memória adicional é solicitada como se o "Nested Loops" fosse uma "Hash join". Há também uma sobrecarga para a fase de construção, que funciona como uma operação de stop-and-go, em contraste com uma junção equivalente de streaming com Nested Loops. Com esse custo adicional, vem a flexibilidade para cenários em que as contagens de linhas flutuam na entrada da compilação.
As junções adaptativas em modo de lote funcionam na execução inicial de uma instrução e, uma vez compiladas, as execuções consecutivas permanecerão adaptativas com base no limite de Junção Adaptativa compilado e nas linhas de execução que fluem durante a fase de construção da entrada externa.
Se uma Junção Adaptável alternar para uma operação de Loops Aninhados, ela usará as linhas já lidas pela compilação Junção de Hash. O operador não relê as linhas de referência externas novamente.
Monitorizar a atividade de junção adaptativa
O operador Adaptive Join tem os seguintes atributos de operador de plano:
| Atributo de Plano | Description |
|---|---|
| AdaptiveThresholdRows | Mostra o uso do limite para alternar de uma junção de hash para uma associação de loop aninhada. |
| TipoDeJunçãoEstimado | Qual é o tipo de junção provável. |
| ActualJoinType | Em um plano real, mostra qual algoritmo de junção foi escolhido com base no limite. |
O plano estimado mostra a forma do plano de Junção Adaptável, juntamente com um limite de Junção Adaptável definido e um tipo de junção estimado.
Tip
O Repositório de Consultas captura e é capaz de forçar um plano de Adaptive Join em modo batch.
Declarações elegíveis de junção adaptável
Algumas condições tornam uma junção lógica elegível para um modo de lote Adaptive Join:
- O nível de compatibilidade do banco de dados é 140 ou superior.
- A consulta é uma
SELECTinstrução (as instruções de modificação de dados estão atualmente inelegíveis). - A junção é elegível para ser executada por uma junção de Loops Aninhados indexada ou por um algoritmo físico de junção de Hash.
- A junção de hash usa o modo de lote, habilitado através da presença de um índice columnstore na consulta geral, uma tabela indexada columnstore sendo referenciada diretamente pela junção ou através do uso do modo de lote em rowstore.
- As soluções alternativas geradas da junção Nested Loops e Hash join devem ter o mesmo primeiro filho (referência externa).
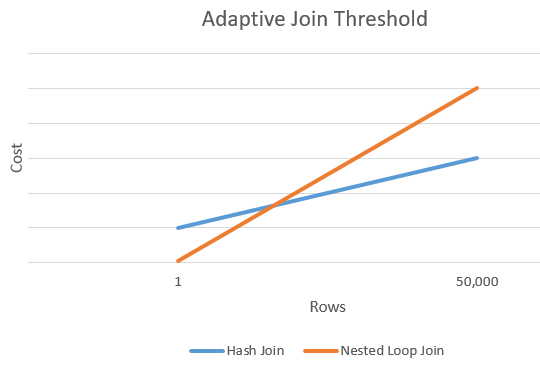
Linhas de limiar adaptáveis
O gráfico a seguir mostra uma comparação entre o custo de um Hash join e o custo de uma alternativa de Nested Loops join. Neste ponto de interseção, o limite é determinado que, por sua vez, determina o algoritmo real usado para a operação de junção.
Desativar associações adaptáveis sem alterar o nível de compatibilidade
As junções adaptativas podem ser desativadas no âmbito do banco de dados ou da instrução, mantendo ainda o nível de compatibilidade do banco de dados 140 e níveis superiores.
Para desabilitar as junções adaptáveis para todas as execuções de consulta originadas do banco de dados, execute o seguinte no contexto do banco de dados aplicável:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Quando habilitada, essa configuração aparece como habilitada no sys.database_scoped_configurations.
Para reativar junções adaptáveis para todas as execuções de consulta originadas do banco de dados, execute o seguinte no contexto do banco de dados aplicável:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
As junções adaptáveis também podem ser desativadas para uma consulta específica ao designar DISABLE_BATCH_MODE_ADAPTIVE_JOINS como uma dica de consulta USE HINT. Por exemplo:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
Uma USE HINT dica de consulta tem precedência sobre uma configuração de escopo de banco de dados ou uma configuração de sinalizador de rastreamento.
Valores nulos e junções
Quando há valores nulos nas colunas das tabelas que estão sendo unidas, os valores nulos não correspondem entre si. A presença de valores nulos em uma coluna de uma das tabelas que estão sendo unidas pode ser retornada somente usando uma junção externa (a menos que a cláusula exclua WHERE valores nulos).
Aqui estão duas tabelas que cada uma tem NULL na coluna que participará da junção:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Uma junção que compara os valores na coluna a com a coluna c não obtém uma correspondência nas colunas que têm valores de NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Apenas uma linha com o valor de 4 nas colunas a e c é retornada.
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Os valores nulos retornados de uma tabela base também são difíceis de distinguir dos valores nulos retornados de uma junção externa. Por exemplo, a instrução a seguir SELECT faz uma união externa esquerda entre estas duas tabelas:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Aqui está o conjunto de resultados.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Os resultados não facilitam a distinção entre um NULL nos dados e um NULL que representa uma falha na adesão. Quando NULL os valores estão presentes nos dados que estão sendo unidos, geralmente é preferível omiti-los dos resultados usando uma junção regular.