Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2016 (13.x) e versões posteriores
SQL Server 2016 (13.x) e versões posteriores![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Base de dados SQL no Microsoft Fabric
Base de dados SQL no Microsoft Fabric
A virtualização de dados permite-lhe executar consultas Transact-SQL (T-SQL) sobre dados externos sem os carregar na sua base de dados. PolyBase é a funcionalidade do Motor de Base de Dados que implementa virtualização de dados entre SQL Server e Azure SQL. Defines uma fonte de dados externa, um formato de ficheiro opcional e uma tabela externa, e depois consultas a tabela externa como SELECT qualquer outra tabela.
Este guia ajuda-o a:
- Compreenda quais recursos PolyBase são suportados pela sua plataforma e versão de SQL.
- Escolha entre
OPENROWSET, tabelas externas, eBULK INSERTpara consultar ou ingerir dados. - Siga os links passo a passo para cenários comuns.
- Revise desempenho, resolução de problemas e boas práticas para cargas de trabalho em produção.
Casos comuns de utilização
A tabela seguinte descreve possíveis cenários de utilização.
| Scenario | Utilização |
|---|---|
| Exploração ad-hoc de ficheiros | OPENROWSET(BULK ...) |
| Consulta a ficheiros reutilizáveis para BI/relatórios | Tabelas externas sobre ficheiros |
| Consulta entre bases de dados (SQL Server, Oracle, Teradata, MongoDB, ODBC) | Conectores PolyBase com tabelas externas |
| Exportação dos resultados das consultas para ficheiros |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Ingestão em massa nas mesas |
BULK INSERT ou OPENROWSET(BULK ...) com INSERT ... SELECT |
Que funcionalidades estão disponíveis onde?
A tabela seguinte mostra quais as funcionalidades principais do PolyBase e virtualização de dados disponíveis em cada plataforma SQL. Use esta tabela para determinar o que pode fazer na sua plataforma antes de usar os guias detalhados.
| Feature | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Base de Dados SQL do Azure | Azure SQL Managed Instance | Banco de dados SQL no Microsoft Fabric |
|---|---|---|---|---|---|---|
| Tabelas externas | Sim | Sim | Sim | Sim | Sim | Sim |
| OPENROWSET (BULK) | Sim 1 | Sim | Sim | Sim | Sim | Sim |
| CETAS (exportação) | No | Sim | Sim | No | Sim | No |
| CSV / ficheiros delimitados | Sim2 | Sim | Sim | Sim | Sim | Sim |
| Ficheiros Parquet | No | Sim | Sim | Sim | Sim | Sim |
| Tabelas do Delta Lake | No | Sim | Sim | No | No | No |
| Liga-te a outro SQL Server | Sim | Sim | Sim | No | No | No |
| Liga-te ao Azure SQL Database ou Azure SQL Managed Instance | Sim 3 | Sim 3 | Sim 3 | No | No | No |
| Liga-te à Oracle / Teradata / MongoDB | Sim | Sim | Sim | No | No | No |
| Conectar-se ao Azure Blob Storage | Sim | Sim | Sim | Sim | Sim | No |
| Liga-te à ADLS Gen2 | No | Sim | Sim | Sim | Sim | No |
| Liga-te a armazenamento compatível com S3 | No | Sim | Sim | No | No | No |
| Ligar-se ao OneLake (Fabric) | No | No | No | No | No | Sim |
| Cálculo por empurramento | Sim | Sim | Sim | No | No | No |
| Autenticação de Identidade Gerida | No | No | Sim 4 | Sim | Sim | No |
1 O SQL Server 2019 (15.x) suporta OPENROWSET(BULK...) caminhos de ficheiros locais e de rede. No SQL Server 2022 (16.x) e versões posteriores, OPENROWSET(BULK...) também suporta a leitura a partir de armazenamento na nuvem com FORMAT = 'PARQUET', FORMAT = DELTA, e FORMAT = 'CSV'.
Suporte a CSV 2 no SQL Server 2019 (15.x) requeria Hadoop. No SQL Server 2022 (16.x) e versões posteriores, o CSV é suportado nativamente sem Hadoop.
3 Utiliza o conector SQL Server (sqlserver://). A credencial com escopo da base de dados tem como alvo o endpoint Azure SQL, os mesmos passos que ligar a outro SQL Server.
4 A autenticação por Identidade Gerida é suportada para ligação ao Azure Blob Storage (ABS) e ADLS Gen2. Requer SQL Server habilitado com Azure Arc ou SQL Server numa VM Azure para SQL Server local. Está disponível nativamente no Azure SQL Database e no Azure SQL Managed Instance.
Observação
A partir do SQL Server 2025 (17.x), consultar ficheiros de dados (CSV, Parquet e Delta) no Azure Blob Storage, ADLS Gen2 ou armazenamento compatível com S3 é uma funcionalidade nativa do motor e já não requer instalar ou executar serviços PolyBase. Os conectores RDBMS (SQL Server, Oracle, Teradata, MongoDB, ODBC) ainda requerem que os serviços PolyBase estejam instalados e a funcionar. O SQL Server 2025 (17.x) também adiciona suporte Linux para estes conectores, que anteriormente estavam disponíveis apenas no Windows.
Interrogar dados externos
Antes de escolher um cenário específico, compreenda as três formas de consultar dados externos:
| Abordagem | Sintaxe | Utilizar quando | Authentication | PolyBase necessário |
|---|---|---|---|---|
| Consultas ad hoc OLE DB | OPENROWSET(provider, connection, query) |
Quer uma consulta rápida e única sem objetos persistentes, ou precisa de autenticação com ID Microsoft Entra | Autenticação SQL, Autenticação Windows, Microsoft Entra ID (MSOLEDBSQL) | No |
| Arquivar consultas ad hoc | OPENROWSET(BULK ...) |
Quer explorar rapidamente os dados dos ficheiros ou testar esquemas antes de criar uma tabela | Token SAS, chave de acesso, Identidade Gerida, Microsoft Entra ID | Sim, para Azure SQL Database e Azure SQL Managed Instance Não para instâncias do SQL Server |
| Conectores de dados persistentes |
CREATE EXTERNAL TABLE com sqlserver://, oracle://, teradata://, etc. |
Precisa de acesso recorrente, governança, estatísticas e computação de otimização para produção | Somente autenticação SQL | Sim |
Os serviços PolyBase são necessários para o acesso a ficheiros na cloud no SQL Server 2019 (15.x) e SQL Server 2022 (16.x). O SQL Server 2025 (17.x) e versões posteriores têm suporte nativo para CSV, Parquet e Delta sem PolyBase.
Guia de decisão
| Scenario | Recommendation |
|---|---|
| Preciso de autenticação Microsoft Entra ID para SQL remoto, ou pretendo evitar utilizar os serviços PolyBase. | Uso OPENROWSET(MSOLEDBSQL, ...) (ad hoc, sem objetos persistentes) |
| Preciso de tabelas persistentes, estatísticas ou cálculo pushdown para bases de dados remotas | Use CREATE EXTERNAL TABLE com conectores PolyBase (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET
não suporta conectores |
| Estou a explorar um novo ficheiro ou a testar um esquema | Uso OPENROWSET(BULK ...) (iteração rápida, sem objetos persistentes) |
| Estou a ingerir dados de ficheiros numa tabela com transformações | Use INSERT ... SELECT de OPENROWSET(BULK ...) |
| Preciso de governação ou acesso partilhado para muitos utilizadores ou aplicações | Use CREATE EXTERNAL TABLE para que as permissões e metadados sejam centralizados |
| Estou a trabalhar em base de dados SQL no Fabric | Use OPENROWSET(BULK ...) para consultas ad hoc do OneLake ou tabelas externas para acesso reutilizável; para armazenamento externo, utilize atalhos do OneLake |
Escolha o seu cenário
Agora que compreende as três abordagens, utilize um dos seguintes guias para implementar o seu caso de uso específico.
Ficheiros de consulta (Parquet, CSV ou Delta)
Se os seus dados estiverem em ficheiros Parquet, CSV ou Delta no Azure Blob Storage, ADLS Gen2, armazenamento compatível com S3 ou OneLake, siga um destes guias:
| Scenario | Guia recomendado | Plataformas |
|---|---|---|
| Consulta rápida e ad hoc num ficheiro Parquet ou CSV | Utilize OPENROWSET. Não é necessária mesa externa |
SQL Server 2022 (16.x) e versões posteriores, Azure SQL Database, Azure SQL Managed Instance, SQL database in Fabric |
| Consultas repetidas em ficheiros Parquet com um esquema persistente | Crie uma mesa externa sobre Parquet | SQL Server 2022 (16.x) e versões posteriores, Azure SQL Database, Azure SQL Managed Instance, SQL database in Fabric |
| Consultar ficheiros CSV com uma tabela externa | Crie uma tabela externa com um formato de ficheiro para texto delimitado | SQL Server 2019 (15.x) e versões posteriores, Azure SQL Database, Azure SQL Managed Instance, SQL database in Fabric |
| Consultar tabelas Delta Lake | Crie uma tabela externa com FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) e versões posteriores |
| Exportar resultados de consulta para ficheiros Parquet ou CSV (CETAS) | Utilize CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) e versões posteriores, Azure SQL Managed Instance |
Pode também seguir um destes tutoriais passo a passo:
| Tutorial | Descrição |
|---|---|
| Introdução ao PolyBase no SQL Server 2022 | Abrange OPENROWSET com Parquet e CSV, tabelas externas e navegação de pastas. |
| Virtualizar o ficheiro parquet num armazenamento de objetos compatível com S3 com o PolyBase | Tutorial para SQL Server 2022 (16.x) e versões posteriores. |
| Virtualizar ficheiro CSV com PolyBase | Tutorial para SQL Server 2022 (16.x) e versões posteriores. |
| Virtualize tabela delta com PolyBase | Tutorial para SQL Server 2022 (16.x) e versões posteriores. |
| Virtualização de dados com a Base de Dados SQL do Azure (Pré-visualização) | Azure SQL Database guide para Parquet e CSV. |
| Virtualização de dados com a Instância Gerenciada SQL do Azure | Guia Azure SQL Managed Instance para Parquet, CSV e CETAS. |
| Virtualização de dados em base de dados SQL no Fabric | Guia da base de dados SQL em Fabric para ficheiros OneLake. |
Liga-te a outra instância SQL Server, Azure SQL Database ou SQL Managed Instance
No SQL Server 2019 (15.x) e versões posteriores, o PolyBase pode consultar tabelas noutra instância do SQL Server, Azure SQL Database ou Azure SQL Managed Instance, sem recorrer a servidores ligados.
Importante
O sqlserver:// conector não é suportado na base de dados SQL no Fabric. Os conectores RDBMS PolyBase usam autenticação SQL através CREATE DATABASE SCOPED CREDENTIAL e não suportam Microsoft Entra ID, Managed Identity ou autenticação de principal de serviço. Como a base de dados SQL no Fabric requer autenticação Microsoft Entra, não podes ligar-te a ela usando PolyBase.
| Step | O que fazer |
|---|---|
| 1. Instalar o PolyBase | Instale o PolyBase no Windows ou instale o PolyBase no Linux |
| 2. Criar uma credencial |
CREATE DATABASE SCOPED CREDENTIAL com o login alvo |
| 3. Criar uma fonte de dados externa | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Criar uma tabela externa | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Consulta | SELECT * FROM <external_table> |
Sugestão
O conector SQL Server (sqlserver://) também funciona para Azure SQL Database e Azure SQL Managed Instance. Use os mesmos passos e defina LOCATION para o endpoint Azure SQL (por exemplo, sqlserver://myserver.database.windows.net).
Para um guia detalhado, consulte Configurar PolyBase para aceder a dados externos no SQL Server.
Liga-te ao Oracle, Teradata ou MongoDB
SQL Server 2019 (15.x) e versões posteriores podem consultar Oracle, Teradata, MongoDB e Cosmos DB através de conectores PolyBase ODBC.
| Origem de dados | Guide | Requisitos |
|---|---|---|
| Oracle | Configure o PolyBase para aceder a dados externos no Oracle | SQL Server 2019 (15.x) e versões posteriores, drivers do cliente Oracle |
| Teradata | Configure o PolyBase para aceder a dados externos no Teradata | SQL Server 2019 (15.x) e versões posteriores, driver Teradata ODBC |
| MongoDB / Cosmos DB | Configure o PolyBase para aceder a dados externos no MongoDB | SQL Server 2019 (15.x) e versões posteriores, driver MongoDB ODBC |
| Qualquer fonte ODBC | Configure o PolyBase para aceder a dados externos com tipos genéricos ODBC | SQL Server 2019 (15.x) e versões posteriores (Windows) (Linux a partir do SQL Server 2025 (17.x)) |
Conectar-se ao Azure Blob Storage ou ADLS Gen2
| Plataforma SQL | Opções de autenticação | Guide |
|---|---|---|
| SQL Server 2022 (16.x) e versões posteriores | Token SAS, chave de acesso, Identidade Gerida (a partir do SQL Server 2025 (17.x)) | Configure o PolyBase para aceder a dados externos no Azure Blob Storage |
| SQL Server 2019 (15.x) | Chave de acesso (via conector Hadoop) | Configure o PolyBase para aceder a dados externos no Azure Blob Storage |
| Base de Dados SQL do Azure | SAS Token, Identidade Gerida, Microsoft Entra pass-through | Virtualização de dados com a Base de Dados SQL do Azure (Pré-visualização) |
| Azure SQL Managed Instance | Token SAS, Identidade Gerida | Virtualização de dados com a Instância Gerenciada SQL do Azure |
No SQL Server 2022 (16.x), os prefixos de URI mudaram. Ao migrar do SQL Server 2019 (15.x) ou versões anteriores:
-
Azure Blob Storage: Alterar
wasb[s]://paraabs:// -
ADLS Gen2: Mudança
abfs[s]://paraadls://
Para mais informações, consulte Configurar PolyBase para aceder a dados externos no Azure Blob Storage.
Liga-se a armazenamento de objetos compatível com S3
O SQL Server 2022 (16.x) e versões posteriores suportam armazenamento compatível com S3, como Amazon S3, MinIO e Ceph.
Para obter mais informações, consulte Configurar o PolyBase para acessar dados externos no armazenamento de objetos compatível com o S3.
Exportar dados com CREATE EXTERNAL TABLE AS SELECT (CETAS)
O CETAS exporta os resultados da consulta para ficheiros externos (Parquet ou CSV) no Azure Blob Storage, ADLS Gen2 ou armazenamento compatível com S3.
| Plataforma SQL | Suportado | Formatos de exportação | Notes |
|---|---|---|---|
| SQL Server 2022 (16.x) e versões posteriores | Sim | Parquet, CSV | Requer configuração do servidor: permitir exportação de polybase |
| Azure SQL Managed Instance | Sim | Parquet, CSV | Desativado por defeito |
| Base de Dados SQL do Azure | No | Nenhum | Não disponível |
| Banco de dados SQL no Fabric | No | Nenhum | Não disponível |
Para a referência Transact-SQL, veja CRIAR TABELA EXTERNA COMO SELECT (CETAS).
Exemplos de arranque rápido
Exemplo 1: Consulta ad hoc num ficheiro Parquet (OPENROWSET)
Não é necessária mesa externa. Funciona no SQL Server 2022 (16.x) e versões posteriores, Azure SQL Database, Azure SQL Managed Instance e base de dados SQL em Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Exemplo 2: Tabela externa sobre CSV no Azure Blob Storage
Este exemplo funciona em todas as plataformas SQL que suportam PolyBase.
Passo 1: Crie uma chave mestra de base de dados (DMK). Este passo é necessário porque a credencial armazena um segredo de token SAS. No entanto, pode fazer este passo se usar Identidade Gerida ou autenticação Microsoft Entra.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Passo 2: Crie uma credencial com um token SAS. Omita o
?inicial.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Passo 3: Crie uma fonte de dados externa.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Passo 4: Crie um formato de ficheiro para o CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Passo 5: Crie a tabela externa.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Passo 6: Consulta a tabela externa.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Exemplo 3: Consultar uma tabela noutro SQL Server
Este exemplo funciona no SQL Server 2019 (15.x) e versões posteriores.
Passo 1: Crie uma chave mestra da base de dados (necessária porque a credencial armazena uma palavra-passe).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Passo 2: Crie uma credencial para a instância remota do SQL Server.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Passo 3: Crie a fonte de dados externa.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Passo 4: Crie a tabela externa (nome em três partes em
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Passo 5: Consulta entre servidores.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Exemplo 4: Exportar resultados para Parquet com CETAS
Funciona no SQL Server 2022 (16.x) e versões posteriores, Azure SQL Managed Instance.
Passo 1: Ativar o CETAS (apenas SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Passo 2: Criar credenciais e fonte de dados (reutilizar exemplos anteriores).
Passo 3: Criar um formato de ficheiro para exportação do Parquet.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Passo 4: Exportar os resultados da consulta.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
Blocos de construção T-SQL para PolyBase
Antes de implementar qualquer cenário, compreenda os objetos T-SQL centrais que a PolyBase utiliza e como eles se encaixam:
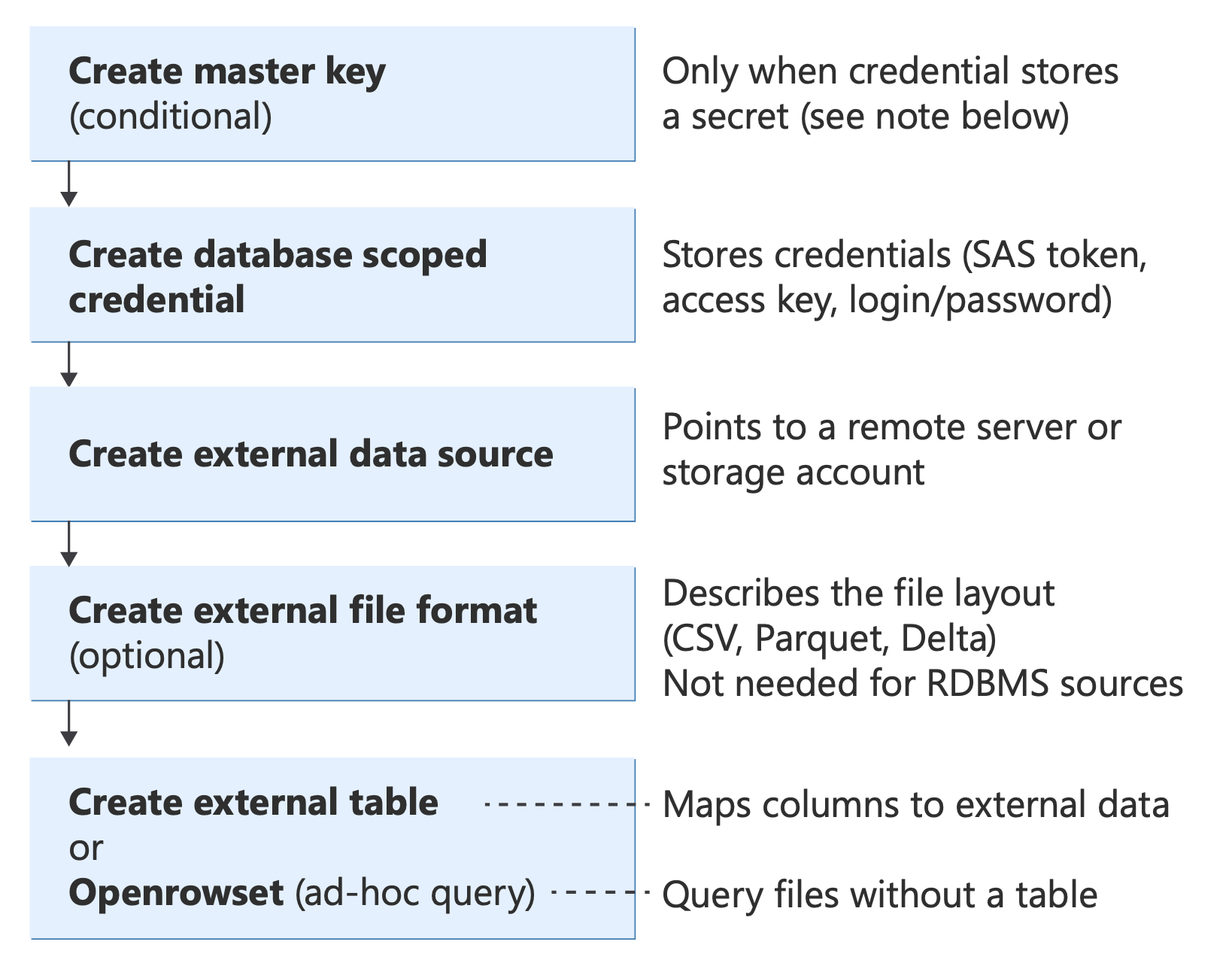
Diagrama que mostra os objetos PolyBase T-SQL e as suas relações, desde a autenticação (chave mestra da base de dados, credenciais) através de fontes de dados e formatos de ficheiro até aos métodos de consulta (External Table, OPENROWSET, BULK INSERT, CETAS).
Para informações sobre estas instruções T-SQL, veja:
- CRIAR UMA ORIGEM DE DADOS EXTERNA
- CRIAR FORMATO DE FICHEIRO EXTERNO
- CRIAR TABELA EXTERNA
- OPENROWSET
- CRIAR TABELA EXTERNA COMO SELEÇÃO (CETAS)
Para uma referência Transact-SQL completa para todos os objetos, veja PolyBase Transact-SQL referência.
Importante
Verifique o mapeamento dos tipos de dados para o formato de ficheiro externo. Quando cria um formato de ficheiro externo, ou ficheiros de consulta usando OPENROWSET, o PolyBase mapeia automaticamente tipos de dados fonte (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) para tipos de dados SQL Server. Tipos desajustados podem causar truncamento silencioso, perda de precisão ou erros de consulta. Por exemplo, um Parquet DECIMAL(38,18) mapeia para DECIMAL(18,0). Revise as tabelas de mapeamento antes de definir colunas externas ou uma WITH cláusula. Para referência completa, veja Mapeamento de Tipos com PolyBase.
Quando é necessário criar chave mestra?
Uma chave mestra de base de dados (DMK) é criada usando CREATE MASTER KEY sintaxe. O DMK encripta os segredos armazenados nas credenciais com âmbito de base de dados. É exigido apenas quando a credencial contém um valor secreto, ou seja, quando armazena uma palavra-passe, token ou chave de acesso.
O DMK é obrigatório (a credencial guarda um segredo):
Tipo de autenticação IDENTITYvalorTem segredo DMK token de SAS 'SHARED ACCESS SIGNATURE'Sim Obrigatório Chave de acesso S3 'S3 ACCESS KEY'Sim Obrigatório Login SQL / autenticação básica '<username>'Sim Obrigatório Chave de acesso da conta de armazenamento '<storage_account_name>'Sim Obrigatório DMK não é obrigatório (sem segredo armazenado):
Tipo de autenticação IDENTITYvalorTem segredo DMK Identidade gerenciada 'Managed Identity'No Não obrigatório Microsoft Entra ID 'User Identity'ou'Managed Identity'No Não obrigatório
Sugestão
Se não houver segredo na tua CREATE DATABASE SCOPED CREDENTIAL declaração, não precisas de DMK. Identidade gerida e autenticação Microsoft Entra ID delegam confiança à plataforma. A base de dados não armazena palavras-passe nem tokens.
Exemplos:
Nesta consulta de exemplo, é necessário o DMK (Credencial armazena um token SAS).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
Neste exemplo de consulta, o DMK não é obrigatório (Identidade Gerida, sem segredo).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
Neste exemplo de consulta, o DMK não é necessário (Microsoft Entra pass-through, sem necessidade de segredo).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Acesso remoto a dados com OPENROWSET e tabelas externas
O SQL Server oferece três abordagens distintas para consultar dados remotos. Pode escolher a abordagem certa quando compreender as diferenças na sintaxe, autenticação e arquitetura.
| Abordagem | Sintaxe | Conecta-se a | Authentication | Serviços PolyBase | Plataformas |
|---|---|---|---|---|---|
| Consultas OLE DB | OPENROWSET(provider, connection, query) |
Qualquer fonte OLE DB via MSOLEDBSQL, SQLOLEDB ou outros fornecedores | Autenticação SQL, Autenticação Windows, Microsoft Entra ID (MSOLEDBSQL) | No | SQL Server (todas as versões suportadas) |
| Consultas a ficheiros | OPENROWSET(BULK ...) |
Ficheiros em disco local, rede ou cloud (Azure Blob, ADLS, S3, OneLake) | Token SAS, chave de acesso, Identidade Gerida, Microsoft Entra ID | Sim, para a cloud*; Não para local | SQL Server 2005; SQL Server 2022 (16.x) e versões posteriores (cloud); Azure SQL |
| Conectores PolyBase |
CREATE EXTERNAL TABLE com CREATE EXTERNAL DATA SOURCE usando sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Fontes do Remote SQL Server, Oracle, Teradata, MongoDB, ODBC | Somente autenticação SQL | Sim | SQL Server 2019 (15.x) e versões posteriores (Windows); SQL Server 2025 (17.x) e versões posteriores (Linux) |
Os serviços PolyBase são necessários para o acesso a ficheiros na cloud no SQL Server 2019 (15.x) e SQL Server 2022 (16.x). O SQL Server 2025 (17.x) e versões posteriores têm suporte nativo para ficheiros cloud e já não requerem PolyBase para CSV, Parquet ou Delta.
Quando usar cada abordagem
Use OLE DB OPENROWSET para:
- Consultas rápidas e pontuais, sem criar objetos persistentes
- Autenticação por Identidade Gerida ou Microsoft Entra ID (via MSOLEDBSQL)
- Evitar dependências do serviço PolyBase
- Ligação a qualquer fonte de dados com um fornecedor OLE DB
Use o ficheiro OPENROWSET(BULK) para:
- Exploração ad hoc de ficheiros e descoberta de esquemas
- Transformações rápidas e pré-visualizações antes de se comprometer com uma definição de tabela
- Transformações flexíveis de colunas em linha (casting, filtragem, colunas computadas)
- Dados que não mudam frequentemente e que não precisam de metadados persistentes
Use conectores PolyBase com a instrução CREATE EXTERNAL TABLE para:
- Definições de tabelas persistentes e reutilizáveis acedidas por múltiplos utilizadores ou aplicações
- Cargas de trabalho de produção que requerem estatísticas e otimização de planos de consulta
- Processamento por push para fontes remotas (filtros enviados para Oracle, SQL Server, etc.)
- Governação partilhada e segurança (uma vez criadas, os utilizadores só precisam
SELECTde permissão) - Quando tem autenticação SQL disponível para a fonte remota
OPENROWSET (OLE DB) - consultas remotas ad hoc (sem necessidade de serviços PolyBase)
A forma OLE DB de OPENROWSET liga-se a uma fonte de dados remota através de um fornecedor OLE DB, executa uma consulta pass-through e devolve os resultados como um conjunto de linhas. É uma alternativa pontual e ad hoc a um servidor ligado. Não são criados metadados persistentes. Esta sintaxe não requer serviços PolyBase, nem suporta ficheiros na cloud nem fontes de dados externas.
Esta consulta de exemplo liga-se a um SQL Server remoto via OLE DB (não PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - consultas baseadas em ficheiros (PolyBase)
A BULK forma de OPENROWSET lê dados diretamente de ficheiros. No SQL Server 2019 (15.x) e versões anteriores, lê a partir de caminhos de ficheiros locais ou UNC e requer um ficheiro de formatação. No SQL Server 2022 (16.x) e versões posteriores, pode ler do armazenamento na cloud usando os parâmetros DATA_SOURCE e FORMAT. Esta abordagem é a versão integrada no PolyBase, utilizada para virtualização de dados.
No contexto do PolyBase e da virtualização de dados, quando este guia menciona OPENROWSET, está a referir-se à sintaxe OPENROWSET(BULK ...) com uma cláusula FORMAT para consultas a ficheiros externos.
Exemplos:
Esta consulta de exemplo lê um ficheiro Parquet do Azure Blob Storage (SQL Server 2022 e versões posteriores).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Esta consulta de exemplo lê um ficheiro Parquet com um caminho inline (Azure SQL Database, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Quando usar OPENROWSET vs. tabelas externas
Tanto OPENROWSET(BULK ...) como as tabelas externas permitem consultar dados externos com T-SQL, mas foram criadas para diferentes casos de uso. A tabela seguinte resume as principais diferenças para o ajudar a decidir qual a abordagem que se adequa ao seu cenário.
| Capacidade | OPENROWSET(BULK ...) |
Tabela externa |
|---|---|---|
| Objetivo | Exploração ad hoc e consultas pontuais | Definição de tabela persistente e reutilizável |
| Metadados armazenados na base de dados | Não. Nada é guardado após a execução da consulta | Yes. A definição da tabela, a fonte de dados e o formato do ficheiro são armazenados como objetos da base de dados |
| Definição de esquema | Inferido automaticamente a partir do ficheiro (Parquet) ou especificado diretamente com uma |
Definido explicitamente na CREATE EXTERNAL TABLE afirmação |
| Permissões | Requer ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS |
Uma vez criada, a permissão padrão SELECT na tabela é suficiente |
| Colunas calculadas | Yes. Adicionar expressões e colunas calculadas na SELECT lista; funções de metadados como filename() e filepath() só estão disponíveis aqui. |
Não. Lista de colunas fixas; realizam transformações numa vista ou na consulta que lê a tabela externa |
| Estatísticas | Azure SQL: estatísticas manuais de coluna única via sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) e versões posteriores: criação automática de estatísticas em predicados (sem estatísticas manuais no SQL Server). Consulte as estatísticas do manual do OPENROWSET. |
Suporte total CREATE STATISTICS em todas as plataformas, além de criação automática no SQL Server 2022 (16.x) e versões posteriores. Consulte Estatísticas manuais de tabela externa. |
| Empurrão | Apoio limitado. O motor pode empurrar filtros para a análise de ficheiros, mas não há pressão para fontes remotas de RDBMS | Yes. Suporta cálculo pushdown para conectores RDBMS (SQL Server, Oracle, Teradata, MongoDB) |
| Melhor para | Exploração de dados, descoberta de esquemas, consultas de prototipagem, cargas de dados únicas, transformações flexíveis | Cargas de trabalho em produção, consultas repetidas, acesso partilhado entre utilizadores, dashboards e relatórios |
Usa o OPENROWSET quando precisares de flexibilidade
OPENROWSET Use para explorar um ficheiro, testar diferentes esquemas ou adicionar colunas computadas e transformações sem criar quaisquer objetos persistentes. Por exemplo, pode extrair o caminho do ficheiro como uma coluna, converter tipos de dados de forma integrada ou filtrar expressões calculadas numa única consulta.
Esta consulta de exemplo inclui colunas computadas e transformações:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Sugestão
As funções filepath() e filename() estão disponíveis no Azure SQL Database, Azure SQL Managed Instance e no SQL Server 2022 (16.x) e versões posteriores. Permitem-te filtrar partes do caminho do ficheiro (eliminação de partições) e expor o nome do ficheiro de origem como uma coluna, o que não é diretamente possível com tabelas externas.
Use tabelas externas quando precisar de persistência e governação
Use tabelas externas quando vários utilizadores ou aplicações precisam de consultar repetidamente os mesmos dados externos. Define o esquema, a fonte de dados e as credenciais uma vez e armazena-os na base de dados. Os consumidores só precisam SELECT de permissão na mesa.
Tabelas externas também suportam estatísticas, que o otimizador de consultas utiliza para construir melhores planos de execução. Pode criar estatísticas manualmente ou deixar o motor criá-las automaticamente (SQL Server 2022 (16.x) e versões posteriores).
Esta consulta de exemplo cria estatísticas numa tabela externa para melhores planos de consulta.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Para mais informações sobre estatísticas para ambas as abordagens, consulte Considerações de desempenho do PolyBase - Estatística.
BULK INSERT vs. OPENROWSET (BULK): Qual devo usar?
Tanto BULK INSERT quanto OPENROWSET(BULK ...) importam dados de ficheiros para o SQL Server usando o mesmo motor de carregamento em massa subjacente. No entanto, diferem na sintaxe, flexibilidade e no que pode fazer com os resultados. A tabela a seguir resume as principais diferenças:
Observação
BULK INSERT não está disponível na base de dados SQL no Fabric. Para o Fabric, usa OPENROWSET(BULK ...) com o OneLake.
| Capacidade | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Propósito básico | Carrega dados de um ficheiro diretamente para uma tabela de destino | Devolve um conjunto de linhas que usas numa SELECT instrução ou INSERT ... SELECT |
| Padrão de utilização | Declaração independente: BULK INSERT <table> FROM '<file>' |
Deve ser usado dentro de uma consulta: SELECT * FROM OPENROWSET(BULK ...) ou INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Requer uma tabela de alvo? | Yes. Escreve sempre diretamente numa tabela | Não. Podes SELECT fazer isso sem inserir em lado nenhum, ou inserir em qualquer tabela ou tabela temporária |
| Transformações de coluna durante a carga | Apoio limitado. Os dados fluem do ficheiro para a tabela tal como estão (mapeamento controlado pelo ficheiro de formato ou pela ordem das colunas) | Apoio total. Pode adicionar expressões, CAST, WHERE filtros, JOIN outras tabelas e colunas computadas ao redor SELECT |
| Dicas para a tabela | A WITH cláusula inclui suporte para BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, KEEPNULLS, TABLOCK, e mais |
Suporta dicas de tabela através da INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) sintaxe |
| Importação de valor único para objetos grandes (LOB) | Não suportado | Yes. Suporta SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB para importar um ficheiro inteiro como um valor varbinary(max), varchar(max) ou nvarchar(max) |
| Ficheiros de formato | Yes. Suportado via (XML e não-XML) | Yes. Suportado (XML e não XML) |
| Acesso a ficheiros na cloud (Azure Blob Storage, ADLS Gen2, S3) | Yes. Suportado via DATA_SOURCE parameter (SQL Server 2017 (14.x) e versões posteriores, Azure SQL) |
Yes. Suportado via DATA_SOURCE parâmetro ou URL inline com FORMAT cláusula (SQL Server 2022 (16.x) e versões posteriores, Azure SQL) |
| Arquivos de Parquet ou Delta | Não suportado. Apenas CSV/texto delimitado | Yes. Suportado com FORMAT = 'PARQUET' ou FORMAT = 'DELTA' (SQL Server 2022 (16.x) e versões posteriores, Azure SQL) |
| Permissão necessária |
ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS, mais INSERT na tabela alvo |
ADMINISTER BULK OPERATIONS ou ADMINISTER DATABASE BULK OPERATIONS |
| Registo mínimo | Yes. Suportado em modelos de recuperação simples ou logados em massa com TABLOCK |
Yes. Suportado quando usado com INSERT ... SELECT e TABLOCK |
Quando escolher BULK INSERT
Use BULK INSERT quando tiver um carregamento simples de ficheiro para tabela e não precisar de transformar, filtrar ou juntar dados durante a importação. Utiliza uma sintaxe mais simples para ficheiros CSV ou outros ficheiros delimitados:
Esta consulta de exemplo carrega um ficheiro CSV do Azure Blob Storage diretamente para uma tabela.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
Esta consulta de exemplo carrega um ficheiro local com um ficheiro de formato para mapeamento de colunas.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Quando escolher OPENROWSET(BULK)
Use OPENROWSET(BULK ...) quando precisar de uma ou mais das seguintes condições:
- Consulta ou pré-visualiza dados de ficheiros sem criar uma tabela primeiro.
- Transformar, filtrar ou juntar dados durante a importação.
- Carregar ficheiros Parquet ou Delta (só
OPENROWSETsuporta estes formatos). -
Importar um ficheiro inteiro como um único valor LOB (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
Esta consulta de exemplo pré-visualiza um ficheiro CSV do Azure Blob Storage sem inserir os dados em lado nenhum.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
Esta consulta de exemplo insere dados com transformação e filtragem.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Esta consulta de exemplo carrega um ficheiro Parquet (não possível com BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
Esta consulta de exemplo importa um ficheiro XML inteiro como um único valor varbinary(max ).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Sugestão
Uma abordagem é começar com OPENROWSET(BULK ...) em SELECT para explorar e validar dados de ficheiros, depois mudar para BULK INSERT para a carga de produção final, caso não necessite de transformações. Se precisar de suporte para Parquet ou Delta ou filtragem inline, permaneça com OPENROWSET.
Para mais informações, consulte os seguintes guias relacionados:
- Use BULK INSERT ou OPENROWSET(BULK...) para importar dados para o SQL Server: Um guia detalhado comparativo com considerações de segurança.
-
Importação e Exportação em Massa de Dados (SQL Server): Uma visão geral de todos os métodos de movimentação de dados em massa (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): Uma referência T-SQL completa.
- OPENROWSET BULK (Transact-SQL): Uma referência completa de T-SQL.
- Exemplos de acesso em massa a dados no Azure Blob Storage: Exemplos lado a lado usando ambos os métodos com Azure Storage.
-
Importação em massa de dados de objetos grandes com o OPENROWSET Bulk Rowset Rowset Provider (SQL Server):
SINGLE_BLOB,SINGLE_CLOB, eSINGLE_NCLOBexemplos. - Use um ficheiro de formatação para importar dados em massa (SQL Server): Formate o uso de ficheiros com ambos os métodos.
Funções úteis de metadados
Quando consulta ficheiros externos com OPENROWSET ou tabelas externas, pode usar várias funções e procedimentos incorporados para inspecionar metadados de ficheiros, descobrir esquemas e implementar consultas conscientes de partições.
filepath() e filename()
As filepath() funções e filename() retornam partes do caminho do ficheiro ou do nome do ficheiro para cada linha do conjunto de resultados. São especialmente úteis para:
Eliminação de partições: Filtre por segmentos de pasta (por exemplo, partições ano/mês/dia) para que o motor leia apenas os ficheiros correspondentes em vez de analisar tudo.
Exposição dos metadados de origem: Inclua o nome ou caminho do ficheiro de origem como uma coluna nos resultados da consulta, o que é útil para auditoria ou depuração.
| Função | Devoluções | Exemplo |
|---|---|---|
filename() |
O nome do ficheiro (incluindo extensão) do ficheiro fonte para cada linha | sales_2025_01.parquet |
filepath(N) |
O n-ésimo segmento da pasta a partir do coringa (*) no caminho BULK, onde N começa em 1 |
Para o caminho sales/2025/01/*.parquet, filepath(1) retorna 2025, filepath(2) retorna 01 |
Aplica-se a: Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) e versões posteriores, base de dados SQL em Fabric.
Esta consulta de exemplo serve filepath() para eliminação de partições e filename() para identificar ficheiros fonte. Só lê ficheiros na /2025/ pasta e só lê ficheiros na /06/ subpasta.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Sugestão
Coloque filepath() filtros na WHERE cláusula em vez de numa subconsulta ou CTE. Quando o filtro está na WHERE cláusula, o motor de processamento pode eliminar partições ao nível da leitura de ficheiro, o que reduz significativamente a entrada/saída.
sp_describe_first_result_set - descobrir os tipos de colunas do OPENROWSET
Quando utiliza OPENROWSET com ficheiros Parquet, o motor de processamento infere automaticamente os tipos de dados das colunas (inferência de esquema). Os tipos inferidos podem ser maiores do que o necessário. Por exemplo, as colunas de caracteres são frequentemente inferidas como varchar(8000) porque os metadados do Parquet não incluem um comprimento máximo. Esta escolha pode degradar o desempenho e consumir mais memória.
sp_describe_first_result_set Use para inspecionar o esquema inferido antes de finalizar a sua consulta. Depois de veres os tipos inferidos, especifica tipos mais restritos numa WITH cláusula para melhorar o desempenho.
Passo 1: Inspecionar o esquema inferido.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';A saída mostra o nome de cada coluna, tipo de dado inferido, comprimento máximo, precisão e escala. Se você vir varchar(8000) onde varchar(100) seria suficiente, substitua-o:
Passo 2: Use tipos explícitos para melhor desempenho.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
A inferência de esquema só funciona com ficheiros Parquet. Para ficheiros CSV, especifique sempre definições de coluna numa WITH cláusula (para OPENROWSET) ou na CREATE EXTERNAL TABLE instrução.
sp_describe_first_result_set é um procedimento geral de SQL Server e Azure SQL, mas é especialmente útil para OPENROWSET consultas. Para mais informações, consulte sp_describe_first_result_set.
Desempenho, resolução de problemas e melhores práticas
Depois de implementar a virtualização de dados, utilize estes guias para otimizar o desempenho, diagnosticar problemas e garantir a prontidão para produção:
| Area | Artigo | Detalhes |
|---|---|---|
| Desempenho do PolyBase | Considerações de desempenho no PolyBase para SQL Server | Estatísticas, pushdown, paralelismo e gestão de memória |
| Cálculo por empurramento | Cálculos de pushdown no PolyBase | Especifica quais operações são enviadas para a fonte remota |
| Como saber se houve um empurrão | Como saber se ocorreu um empurrão externo | Planos de consulta e Visões de Gestão Dinâmica (DMVs) |
| Troubleshooting | Monitorar e solucionar problemas do PolyBase | Erros comuns e resoluções |
| Conectividade Kerberos | Solucionar problemas de conectividade Kerberos do PolyBase | |
| Perguntas Frequentes | Perguntas frequentes da PolyBase | |
| Erros e soluções | erros do PolyBase e possíveis soluções |