Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
A E/S de uma instância do Mecanismo de Banco de Dados do SQL Server inclui leituras lógicas e físicas. Uma leitura lógica ocorre sempre que o Mecanismo de Banco de Dados solicita uma página do cache de buffer, também conhecido como pool de buffers. Se a página não estiver atualmente no cache do buffer, uma leitura física primeiro copiará a página do disco para o cache.
As solicitações de leitura geradas por uma instância do Mecanismo de Banco de Dados são controladas pelo mecanismo relacional e otimizadas pelo mecanismo de armazenamento. O mecanismo relacional determina o método de acesso mais eficaz (como uma verificação de tabela, uma verificação de índice ou uma leitura com chave). Os métodos de acesso e os componentes do gerenciador de buffer do mecanismo de armazenamento determinam o padrão geral de leituras a serem executadas e otimizam as leituras necessárias para implementar o método de acesso. O thread que executa o lote agenda as leituras.
Leitura antecipada
O Mecanismo de Banco de Dados oferece suporte a um mecanismo de otimização de desempenho chamado read-ahead. A leitura antecipada antecipa os dados e as páginas de índice necessárias para cumprir um plano de execução de consulta e traz as páginas para o cache do buffer antes de serem usadas pela consulta. Este processo permite que a computação e a E/S se sobreponham, tirando o máximo partido da CPU e do disco.
O mecanismo de leitura antecipada permite que o Mecanismo de Banco de Dados leia até 64 páginas contíguas (512 KB) de um arquivo. A leitura é realizada como uma única operação de scatter-gather para o número apropriado de buffers (provavelmente não contíguos) na cache de buffers. Se alguma das páginas na faixa já estiver presente no cache do buffer, a página correspondente será descartada quando a operação de leitura for concluída. O intervalo de páginas também pode ser "cortado" de ambas as extremidades se as páginas correspondentes já estiverem presentes no cache.
Existem dois tipos de read-ahead: um para páginas de dados e outro para páginas de índice.
Ler páginas de dados
As verificações de tabela usadas pelo Mecanismo de Banco de Dados para ler páginas de dados são eficientes. As páginas do mapa de alocação de índice (IAM) em um banco de dados do SQL Server listam as extensões usadas por uma tabela ou índice. O mecanismo de armazenamento pode ler o IAM para criar uma lista ordenada dos endereços de disco que devem ser lidos. Isso permite que o mecanismo de armazenamento otimize suas E/S como grandes leituras sequenciais que são executadas em sequência, com base em sua localização no disco. Para obter mais informações sobre páginas do IAM, consulte Gerenciar espaço usado por objetos.
Ler páginas de índice
O mecanismo de armazenamento lê páginas de índice em sequência na ordem das chaves. Por exemplo, esta ilustração mostra uma representação simplificada de um conjunto de páginas folha que contém um conjunto de chaves e o nó de índice intermediário mapeando as páginas folha. Para obter mais informações sobre a estrutura de páginas em um índice, consulte Índices clusterizados e não clusterizados.
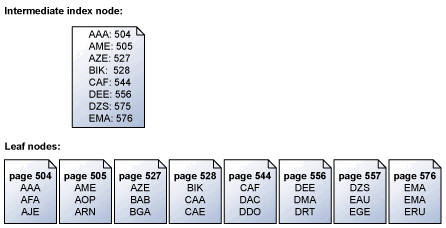
O mecanismo de armazenamento usa as informações na página de índice intermediário acima do nível de folha para agendar leituras seriais antecipadas para as páginas que contêm as chaves. Se for feita uma solicitação para todas as chaves de ABC a DEF, o motor de armazenamento primeiro lê a página de índice acima da página folha. No entanto, ele não lê apenas cada página de dados em sequência da página 504 à página 556 (a última página com chaves no intervalo especificado). Em vez disso, o mecanismo de armazenamento verifica a página de índice intermediária e cria uma lista das páginas folha que devem ser lidas. Em seguida, o mecanismo de armazenamento agenda todas as leituras em ordem de chave. O mecanismo de armazenamento também reconhece que as páginas 504/505 e 527/528 são contíguas e executa uma única leitura de dispersão para recuperar as páginas adjacentes em uma única operação. Quando há muitas páginas a serem recuperadas em uma operação serial, o mecanismo de armazenamento agenda um bloco de leituras de cada vez. Quando um subconjunto dessas leituras é concluído, o mecanismo de armazenamento agenda um número igual de novas leituras até que todas as leituras necessárias sejam agendadas.
O mecanismo de armazenamento usa pré-carregamento para acelerar pesquisas nas tabelas base através de índices não clusterizados. As linhas de folha de um índice não clusterizado contêm ponteiros para as linhas de dados que contêm cada valor de chave específico. À medida que o mecanismo de armazenamento lê as páginas folha do índice não clusterizado, ele também começa a agendar leituras assíncronas para as linhas de dados cujos ponteiros já foram recuperados. Isso permite que o mecanismo de armazenamento recupere linhas de dados da tabela subjacente antes de concluir a verificação do índice não clusterizado. A pré-busca é usada independentemente de a tabela ter um índice clusterizado. O SQL Server Enterprise Edition usa mais pré-busca do que outras edições do SQL Server, permitindo que mais páginas sejam lidas antecipadamente. O nível de pré-busca não é configurável em nenhuma edição. Para obter mais informações sobre índices não clusterizados, consulte Índices clusterizados e não clusterizados.
Digitalização avançada
No SQL Server Enterprise Edition, o recurso de verificação avançada permite que várias tarefas compartilhem verificações de tabela completas. Se o plano de execução de uma instrução Transact-SQL exigir uma verificação das páginas de dados em uma tabela e o Mecanismo de Banco de Dados detetar que a tabela já está sendo verificada para outro plano de execução, o Mecanismo de Banco de Dados associará a segunda verificação à primeira, no local atual da segunda verificação. O Mecanismo de Banco de Dados lê cada página uma vez e passa as linhas de cada página para ambos os planos de execução. Isso continua até que o final da tabela seja alcançado.
Nesse ponto, o primeiro plano de execução tem os resultados completos de uma verificação. No entanto, o segundo plano de execução ainda deve recuperar as páginas de dados que foram lidas, antes de ingressar na verificação em andamento. Em seguida, a verificação para o segundo plano de execução é quebrada de volta para a primeira página de dados da tabela e verifica para onde ele se juntou à primeira verificação. Qualquer número de varreduras pode ser combinado desta forma. O Mecanismo de Banco de Dados continua fazendo looping pelas páginas de dados até concluir todas as verificações. Esse mecanismo também é chamado de "merry-go-round scanning" e demonstra por que a ordem dos resultados retornados de uma SELECT declaração não pode ser garantida sem uma ORDER BY cláusula.
Por exemplo, suponha que você tenha uma tabela com 500.000 páginas.
UserA Executa uma instrução Transact-SQL que requer uma verificação da tabela. Quando essa verificação tiver processado 100.000 páginas, UserB executará outra instrução Transact-SQL que verifica a mesma tabela. O Mecanismo de Banco de Dados agenda um conjunto de solicitações de leitura para páginas após 100.001 e passa as linhas de cada página de volta para ambas as verificações. Quando a verificação atingir a página 200.000, UserC executa outra instrução Transact-SQL que verifica a mesma tabela. A partir da página 200.001, o motor da base de dados transfere as linhas de cada página que lê para todas as três varreduras. Depois de ler a 500.000ª linha, a verificação para UserA é concluída, e as leituras para UserB e UserC voltam e começam a ler as páginas começando pela página 1. Quando o Mecanismo de Banco de Dados chega à página 100.000, a verificação para UserB é concluída. A varredura para UserC então continua sozinha até ler a página 200,000. Neste ponto, todas as varreduras foram concluídas.
Sem a verificação avançada, cada usuário teria que competir por espaço de buffer e causar contenção de braço de disco. As mesmas páginas seriam então lidas uma vez para cada utilizador, em vez de lidas uma vez e partilhadas por vários utilizadores, diminuindo o desempenho e sobrecarregando os recursos.