Guia de arquitetura e gerenciamento de log de transações do SQL Server
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de dados SQL do Azure
Banco de dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Todo banco de dados do SQL Server tem um log de transações que registra todas as transações e as modificações do banco de dados feitas por cada transação. O log de transações é um componente essencial do banco de dados e, se houver uma falha no sistema, ele poderá ser necessário para que o banco de dados volte a um estado consistente. Este guia fornece informações sobre a arquitetura física e lógica do log de transações. A compreensão da arquitetura pode melhorar sua efetividade na administração de logs de transações.
Arquitetura lógica do log de transações
O log de transações do SQL Server opera logicamente como se fosse uma cadeia de registros de log. Cada registro de log é identificado por um número de sequência de log (LSN). Cada registro de log novo é gravado no final lógico do log com um LSN maior que o do registro antes da gravação. Registros de log são armazenados em uma sequência em série à medida que são criados, de modo que, se LSN2 for maior que LSN1, a alteração descrita pelo registro de log mencionado por LSN2 ocorreu após a alteração descrita pelo registro de log LSN1. Cada registro de log contém a ID da transação a que pertence. Para cada transação, todos os registros de log associados com a transação são vinculados individualmente em uma cadeia usando ponteiros de retrocesso que aceleram a reversão da transação.
A estrutura básica de um LSN é [VLF ID:Log Block ID:Log Record ID]. Para obter mais informações, consulte as seções VLF e bloco de logs.
Este é um exemplo de LSN: 00000031:00000da0:0001, em que 0x31 é a ID do VLF, 0xda0 é a ID do bloco de log e 0x1 é o primeiro registro de log nesse bloco de log. Para obter exemplos de LSNs, observe a saída do DMV sys.dm_db_log_info e examine a coluna vlf_create_lsn.
Os registros de log para modificações de dados registram a operação lógica realizada ou as imagens de antes e depois dos dados modificados. A imagem "antes" é uma cópia dos dados antes de a operação ser realizada; a imagem "depois" é uma cópia dos dados depois de a operação ter sido realizada.
As etapas para recuperar uma operação dependem do tipo de registro de log:
Log da operação lógica
- Para avançar a operação lógica, a operação é executada novamente.
- Para reverter a operação lógica, é executada a operação lógica inversa.
Log da imagem anterior e posterior
- Para avançar a operação, a imagem "depois" é aplicada.
- Para reverter a operação, a imagem "antes" é aplicada.
São registrados muitos tipos de operações no log de transações. Essas operações incluem:
O início e o término de cada transação.
Toda modificação de dados (inserção, atualização ou exclusão). As modificações incluem alterações feitas por procedimentos armazenados no sistema ou instruções de linguagem de definição de dados (DDL) em qualquer tabela, inclusive tabelas do sistema.
Toda extensão e alocação ou desalocação de página.
Criando ou descartando uma tabela ou um índice.
Operações de reversão também são registradas. Cada transação reserva espaço no log de transações para garantir que haja espaço suficiente no log para suportar uma reversão causada por uma instrução de reversão explícita ou se for encontrado um erro. A quantidade de espaço reservado depende das operações realizadas na transação, mas geralmente é igual à quantidade de espaço usada para registrar cada operação. Esse espaço reservado é liberado quando a transação é concluída.
A seção do arquivo de log originado do primeiro registro de log deve estar presente para que todo o banco de dados seja revertido com êxito para o registro de log da última gravação, chamada de parte ativa do log, log ativo ou base do log. Essa é a seção do log necessária para uma recuperação completa do banco de dados. Nenhuma parte do log ativo pode ter sido truncada. O LSN (número de sequência de log) desse primeiro registro de log é conhecido como LSN de recuperação mínima (MinLSN). Saiba mais sobre operações com suporte do log de transações em O log de transações.
O backup diferencial e o backup de log avançam o banco de dados restaurado para uma hora posterior que corresponde a um LSN mais alto.
Arquitetura física do log de transações
O log de transações do banco de dados é mapeado em um ou mais arquivos físicos. Conceitualmente, o arquivo de log é uma cadeia de caracteres de registros de log. Fisicamente, a sequência de registros de log é armazenada com eficiência no conjunto de arquivos físicos que implementam o log de transações. Deve haver, no mínimo, um arquivo de log para cada banco de dados.
VLFs (Arquivos de Log Virtual)
O Mecanismo de Banco de Dados do SQL Server divide cada arquivo de log físico internamente em vários arquivos de log virtuais (VLFs). Arquivos de log virtual não têm tamanho fixo, e não há um número fixo de arquivos de log virtual para um arquivo de log físico. O Mecanismo de Banco de Dados escolhe o tamanho dos arquivos de log virtuais dinamicamente enquanto cria ou amplia esses arquivos. O Mecanismo de Banco de Dados tenta manter alguns arquivos virtuais. O tamanho dos arquivos virtuais depois que um arquivo de log for estendido é a soma do tamanho do log existente com o tamanho do incremento do arquivo novo. O tamanho ou o número de arquivos de log virtual não pode ser configurado ou definido pelos administradores.
Criação de arquivos de log virtuais
A criação de VLF (arquivos de log virtuais) segue este método:
- No SQL Server 2014 (12.x) e versões posteriores, se o próximo crescimento for menor que 1/8 do tamanho físico do log atual, crie 1 VLF que abranja o tamanho do crescimento.
- Se o próximo crescimento for superior a 1/8 do tamanho atual do registro, use o método anterior a 2014, a saber:
- Se o crescimento for menor que 64 MB, crie 4 VLFs que abranjam o tamanho do crescimento (por exemplo, para um crescimento de 1 MB, crie 4 VLFs com tamanho de 256 KB).
- No Banco de Dados SQL do Azure, e começando com o SQL Server 2022 (16.x) (todas as edições), a lógica é ligeiramente diferente. Se o crescimento for menor que ou igual a 64 MB, o Mecanismo de Banco de Dados criará apenas um VLF para abranger o tamanho do crescimento.
- Se o crescimento for de 64 MB a 1 GB, crie 8 VLFs que abranjam o tamanho do crescimento (por exemplo, para um crescimento de 512 MB, crie 8 VLFs com tamanho de 64 MB).
- Se o crescimento for maior que 1 GB, crie 16 VLFs que abranjam o tamanho do crescimento (por exemplo, para um crescimento de 8 GB, crie 16 VLFs com tamanho de 512 MB).
- Se o crescimento for menor que 64 MB, crie 4 VLFs que abranjam o tamanho do crescimento (por exemplo, para um crescimento de 1 MB, crie 4 VLFs com tamanho de 256 KB).
Se os arquivos de log aumentarem para um tamanho grande em muitos incrementos pequenos, eles acabarão com muitos arquivos de log virtuais. Isso pode retardar a inicialização do banco de dados, registrar operações de backup e restauração de logs e causar replicação transacional/CDA e latência de refazer sempre ativada. Por outro lado, se os arquivos de log forem definidos para um tamanho grande com poucos ou apenas um incremento, eles conterão poucos arquivos de log virtuais muito grandes. Para obter mais informações sobre como estimar corretamente o tamanho necessário e a configuração de aumento automático de um log de transações, consulte a seção Recomendações em Gerenciar o tamanho do arquivo de log de transações.
Recomendamos criar os arquivos de log próximos ao tamanho final necessário, usando os incrementos necessários para obter uma distribuição de VLFs ideal, e ter um valor de growth_increment relativamente grande.
Consulte as dicas a seguir para determinar a distribuição ideal de VLFs para o tamanho atual do log de transações:
- O valor de size, definido pelo argumento
SIZEdeALTER DATABASEé o tamanho inicial do arquivo de log. - O valor de growth_increment (também conhecido como valor de autogrow), que o argumento
FILEGROWTHdeALTER DATABASEdefine é a quantidade de espaço adicionada ao arquivo todas as vezes que um novo espaço é necessário.
Para obter mais informações sobre os argumentos FILEGROWTH e SIZE de ALTER DATABASE, consulte Opções de arquivo e grupo de arquivos de ALTER DATABASE (Transact-SQL).
Dica
Para determinar a distribuição ideal de VLFs para o tamanho atual do log de transações de todos os bancos de dados em uma determinada instância e os incrementos de crescimento necessários para atingir o tamanho necessário, consulte este script Fixing-VLFs no GitHub.
O que acontece quando você tem muitos VLFs?
Durante os estágios iniciais de um processo de recuperação de banco de dados, o SQL Server descobre todos os VLFs em todos os arquivos de log de transações e cria uma lista desses VLFs. Esse processo pode levar muito tempo, dependendo do número de VLFs presentes no banco de dados específico. Quanto mais VLFs, mais longo será o processo. Um banco de dados pode acabar com um grande número de VLFs se houver aumento automático ou manual frequente do log de transações em pequenos incrementos. Quando o número de VLFs atinge a faixa de várias centenas de milhares, você pode encontrar alguns ou a maioria dos seguintes sintomas:
- Um ou mais bancos de dados levam muito tempo para concluir a recuperação durante a inicialização do SQL Server.
- A restauração de um banco de dados leva muito tempo para ser concluída.
- As tentativas de anexar um banco de dados demoram muito tempo para serem concluídas.
- Ao tentar configurar o espelhamento do banco de dados, você encontra mensagens de erro 1413, 1443 e 1479, indicando um tempo limite.
- Você encontra erros relacionados à memória, como o 701, ao tentar restaurar um banco de dados.
- A replicação de transações ou a captura de dados de Alterações podem causar latência significativa.
Ao examinar o log de erros do SQL Server, você pode notar que uma quantidade significativa de tempo é gasta antes da fase de análise do processo de recuperação do banco de dados. Por exemplo:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
Além disso, o SQL Server pode registrar em log um erro MSSQLSERVER_9017 quando você restaurar um banco de dados que tenha um grande número de VLFs:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Para obter mais informações, consulte MSSQLSERVER_9017.
Corrigir bancos de dados com um número grande de VLFs
Para manter o número total de VLFs em uma quantidade razoável, como um máximo de vários milhares, é possível redefinir o arquivo de log de transações para conter um número menor de VLFs, executando as etapas a seguir:
Reduza os arquivos de log de transações manualmente.
Aumente os arquivos para o tamanho necessário manualmente em uma etapa usando o seguinte script T-SQL:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Observação
Essa etapa também é possível no SQL Server Management Studio, usando a página de propriedades do banco de dados.
Depois de definir o novo layout do arquivo de log de transações com menos VLFs, revise e faça as alterações necessárias nas configurações de aumento automático do log de transações. Essa validação de configuração garante que o arquivo de log evite encontrar o mesmo problema no futuro.
Antes de executar qualquer uma dessas operações, certifique-se de que você tenha um backup restaurável válido para o caso de encontrar problemas posteriormente.
Para determinar a distribuição ideal de VLF para o tamanho atual do log de transações de todos os bancos de dados em uma determinada instância e os incrementos de crescimento necessários para atingir o tamanho necessário, você pode usar o seguinte script do GitHub para corrigir VLFs.
Blocos de log
Cada VLF contém um ou mais blocos de logs. Cada bloco de log consiste nos registros de log (alinhados em um limite de 4 bytes). Um bloco de log tem tamanho variável e é sempre um múltiplo inteiro de 512 bytes (o tamanho mínimo do setor suportado pelo SQL Server), com um tamanho máximo de 60 KB. Um bloco de log é a unidade básica de E/S para logs de transações.
Em resumo, um bloco de log é um contêiner de registros de log usado como unidade básica de logs de transações ao gravar registros de log no disco.
Cada bloco de log em uma VLF é endereçado exclusivamente por seu deslocamento de bloco. O primeiro bloco sempre tem um deslocamento de bloco que aponta para além dos primeiros 8 KB no VLF.
Em geral, um VLF é sempre preenchido com blocos de log. É possível que o último bloco de logs em um VLF esteja vazio (por exemplo, não contenha nenhum registro de log). Isso acontece quando um registro de log a ser gravado não cabe no bloco de log atual e também quando o espaço restante no VLF é insuficiente para conter esse registro de log. Nesse caso, é criado um bloco de log vazio que preenche o VLF. O registro de log é inserido no primeiro bloco do próximo VLF.
Natureza circular do log de transações
O log de transações é um arquivo embrulhado. Por exemplo, considere um banco de dados com um arquivo de log físico dividido em quatro VLFs. Quando o banco de dados é criado, o arquivo de log lógico começa no início do arquivo de log físico. Novos registros de log são adicionados no final do log lógico e expandem para o final do log físico. O truncamento de logs libera quaisquer logs virtuais cujos registros apareçam todos na frente do número mínimo de sequência de recuperação do log (MinLSN). O MinLSN é o número de sequência de log do registro de log mais antigo que deve estar presente para o êxito de uma reversão de todo o banco de dados. O log de transações no banco de dados de exemplo pareceria semelhante ao apresentado na ilustração a seguir.
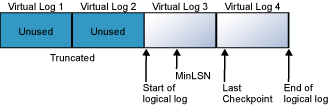
Quando o final do log lógico alcança o final do arquivo de log físico, os novos registros de log são adicionados no início do arquivo de log físico.
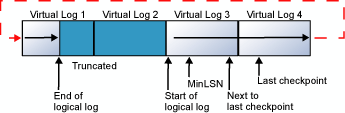
Esse ciclo repete-se indefinidamente, desde que o final do log lógico nunca alcance o início do log lógico. Se os registros de log antigos forem truncados com frequência suficiente para sempre deixar espaço suficiente para todos os registros de log novos criados através do próximo ponto de verificação, o log nunca estará completo. Contudo, se o final do log lógico não alcançar o início do log lógico, ocorrerá uma das duas coisas:
Se a configuração
FILEGROWTHestiver habilitada para o log e houver espaço disponível no disco, o arquivo será estendido pelo valor especificado no parâmetro growth_increment, e os novos registros de log serão adicionados à extensão. Para obter mais informações sobre a configuraçãoFILEGROWTH, consulte Opções de arquivo e grupo de arquivos de ALTER DATABASE (Transact-SQL).Se a configuração
FILEGROWTHnão estiver habilitada ou se o disco que estiver armazenando o arquivo de log tiver menos espaço livre do que a quantidade especificada em growth_increment, será gerado um erro 9002. Para obter mais informações, confira Solucionar problemas em um log de transações completo (Erro 9002 do SQL Server).
Se o log contiver vários arquivos de log físico, o log lógico percorrerá todos os arquivos de log físico antes de voltar ao início do primeiro arquivo de log físico.
Importante
Para obter mais informações sobre o gerenciamento de tamanho do log de transações, consulte Gerenciar o tamanho do arquivo de log de transações.
Truncamento de logs
O truncamento de log é essencial para impedir o preenchimento do log. O truncamento de log exclui arquivos de log virtual inativos do log de transações lógico de um banco de dados do SQL Server, liberando espaço no log lógico para reutilização pelo log de transações físico. Se um log de transações nunca for truncado, ele acabará preenchendo todo o espaço em disco alocado a seus arquivos de log físicos. No entanto, para que o log possa ser truncado, deve ocorrer uma operação ponto de verificação. Um ponto de verificação grava as páginas modificadas atuais na memória (conhecidas como páginas sujas) e as informações do log de transações da memória para o disco. Quando o ponto de verificação é executado, a porção inativa do log de transações é marcada como reutilizável. Depois disso, um truncamento de logs pode liberar a parte inativa. Para obter mais informações sobre pontos de verificação, consulte Pontos de controle do banco de dados (SQL Server).
As ilustrações seguintes mostram um log de transações antes e depois do truncamento. A primeira ilustração mostra um log de transações que nunca foi truncado. Atualmente, quatro arquivos de log virtuais estão em uso pelo log lógico. O log virtual inicia à frente do primeiro arquivo de log virtual e termina em log 4 virtual. O registro de MinLSN está em log 3 virtual. O log 1 virtual e o log 2 virtual contêm apenas registros de log inativos. Estes registros podem ser truncados. O log virtual 5 ainda não é usado e não faz parte do log lógico atual.
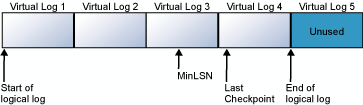
A segunda ilustração mostra como o log aparece depois de ser truncado. Log 1 virtual e log 2 virtual foram liberados para reutilização. O log lógico agora inicia no começo do log 3 virtual. O log virtual 5 ainda não é usado e não faz parte do log lógico atual.
O truncamento de log ocorre automaticamente após os seguintes eventos, exceto quando atrasado por alguma razão:
- No modelo de recuperação simples, depois de um ponto de verificação.
- No modelo de recuperação completa ou bulk-logged, depois de um backup de log, se um ponto de verificação tiver acontecido desde o backup prévio.
O truncamento do log pode ser atrasado por vários fatores. No caso de uma demora longa em truncamento de log, o log de transações pode ficar cheio. Para obter informações, consulte Fatores que podem atrasar o truncamento do log e Solução de problemas em um log de transação completo (Erro 9002 do SQL Server).
Log de transações com gravação antecipada
Esta seção descreve a função do log de transações write-ahead no registro de modificações de dados no disco. O SQL Server usa um algoritmo de logs write-ahead (WAL), que garante que nenhuma modificação de dados seja gravada no disco antes que o registro de log associado seja gravado no disco. Isso mantém as propriedades ACID de uma transação.
Para obter mais informações sobre WAL, consulte Fundamentos de E/S do SQL Server.
Para entender como o log write-ahead funciona em relação ao log de transações, é importante saber como os dados modificados são gravados no disco. O SQL Server mantém um cache de buffer (também chamado de pool de buffers) no qual lê páginas de dados quando os dados precisam ser recuperados. Quando uma página é modificada no cache do buffer, não é gravada imediatamente de volta no disco. Em vez disso, a página é marcada como suja. Uma página de dados pode ter mais de uma gravação lógica feita antes de ser gravada fisicamente no disco. Para cada gravação lógica, um registro de log de transações é inserido no cache de log que registra a modificação. Os registros de log devem ser gravados no disco antes de a página suja associada ser removida do cache do buffer e gravada no disco. O processo de ponto de verificação examina o cache do buffer periodicamente para buffers com páginas de um banco de dados especificado e grava todas as páginas sujas no disco. Os pontos de verificação economizam tempo durante uma recuperação posterior, pois criam um ponto em que todas as páginas sujas são gravadas no disco.
A gravação de uma página de dados modificada do cache do buffer no disco é chamada de liberação de página. O SQL Server tem uma lógica que impede que uma página suja seja liberada antes que o registro de log associado seja gravado. Os registros de log são gravados em disco quando os buffers do log são liberados. Isso ocorre sempre que uma transação é confirmada ou que os buffers de log ficam cheios.
Backups do log de transações
Esta seção apresenta conceitos sobre como fazer backup e restaurar (aplicar) logs de transações. Nos modelos de recuperação completa e de recuperação com log de operações em massa é necessário fazer backups de rotina de logs de transações (backups de log) para recuperar dados. É possível fazer backup do log enquanto qualquer backup completo está em execução. Para obter mais informações sobre os modelos de recuperação, consulte Fazer backup e restaurar bancos de dados do SQL Server.
Para poder criar o primeiro backup de log, você deve criar um backup completo, como um backup de banco de dados ou o primeiro de um conjunto de backups de arquivo. A restauração de um banco de dados usando apenas backups de arquivo pode tornar-se complexa. Portanto, recomendamos que, assim que possível, você inicie com um backup de banco de dados. Assim, é necessário fazer backup de log de transações regularmente. Isto não só minimiza a exposição à perda de trabalho, como também habilita o truncamento do log de transações. Normalmente, o log de transações é truncado após todos os backups de log convencionais.
Importante
Recomendamos fazer backups de log com frequência suficiente para dar suporte a seus requisitos empresariais, especificamente, a tolerância à perda de trabalho que pode ser causada por um armazenamento de log danificado.
A frequência apropriada para fazer backups de log depende de tolerância à exposição à perda de trabalho, equilibrada por quantos backups de log é possível armazenar, administrar e, potencialmente, restaurar. Pense no objetivo de tempo de recuperação (RTO) e no objetivo de ponto de recuperação (RPO) necessários ao implementar sua estratégia de recuperação e, especificamente, na cadência do backup de logs. Fazer um backup de log a cada 15 a 30 minutos deve ser o bastante. Se o seu negócio requer que você reduza ao mínimo a exposição à perda de trabalho, considere fazer backups de log com mais frequência. Backups de log mais frequentes têm a vantagem adicional de aumentar a frequência de truncamentos de log, resultando em arquivos de log menores.
Para limitar o número de backups de log que você precisa restaurar, é essencial fazer backup dos dados com frequência. Por exemplo, convém programar um backup de banco de dados completo por semana e backups de diferenciais de banco de dados diariamente.
Pense no RTO e RPO necessários ao implementar sua estratégia de recuperação e, especificamente, na cadência de backup completo e diferencial de banco de dados.
Para obter mais informações sobre backups de logs de transações, consulte Backups de logs de transações (SQL Server).
A cadeia de logs
Uma sequência contínua de backups de log é denominada cadeia de logs. Uma cadeia de logs começa com um backup completo do banco de dados. Normalmente, uma nova cadeia de logs só é iniciada quando é feito o backup do banco de dados pela primeira vez ou depois que o modelo de recuperação é alterado de recuperação simples para recuperação completa ou com logs em massa. A menos que você decida substituir os conjuntos de backup existentes quando criar um backup de banco de dados completo, a cadeia de logs existente permanecerá intacta. Com a cadeia de logs intacta, é possível restaurar o banco de dados a partir de qualquer backup de banco de dados completo do conjunto de mídias, seguido por todos os backups de logs subsequentes até o ponto de recuperação. O ponto de recuperação pode estar no fim do último backup de log ou em um ponto de recuperação específico em qualquer dos backups de log. Para obter mais informações, confira Backups de logs de transações (SQL Server).
Para restaurar um banco de dados até o ponto de falha, a cadeia de logs deve estar intacta. Isto é, uma sequência ininterrupta de backups de log de transações deve se estender até o ponto de falha. O início dessa sequência de logs depende do tipo de backup de dados que você está restaurando: banco de dados, parcial ou de arquivo. Para um backup de banco de dados ou backup parcial, a sequência de backups de log deve se estender do final de um banco de dados ou backup parcial. Para um conjunto de backups de arquivos, a sequência de backups de log deve se estender desde o início de um conjunto completo de backups de arquivos. Para obter mais informações, confira Aplicar backups de log de transações (SQL Server).
Restaurar backups de logs
A restauração de um backup de log transfere as alterações que foram registradas no log de transações para recriar o estado exato do banco de dados no momento em que a operação de backup de log foi iniciada. Ao restaurar um banco de dados, será necessário restaurar os backups de log criados após o backup completo do banco de dados restaurado ou a partir do início do primeiro backup de arquivo restaurado. Normalmente, depois de restaurar o backup de dados ou diferencial mais recente, será necessário restaurar uma série de backups de log até alcançar o seu ponto de recuperação. Em seguida, o banco de dados é recuperado. Isso rola para trás todas as transações que estavam incompletas quando a recuperação começou e coloca o banco de dados online. Depois que o banco de dados for recuperado, você não poderá restaurar mais nenhum backup. Para obter mais informações, confira Aplicar backups de log de transações (SQL Server).
Pontos de controle e a parte ativa do log
Os pontos de verificação liberam para o disco páginas de dados sujas do cache do buffer do banco de dados atual. Isso minimiza a parte ativa do log que deve ser processada durante a recuperação completa de um banco de dados. Durante uma recuperação completa, são executados os seguintes tipos de ações:
- Os registros de log de modificações não liberados para disco antes de o sistema parar são rolados para frente.
- Todas as modificações associadas a transações incompletas, como transações para as quais não há registro de log COMMIT ou ROLLBACK, são revertidas.
Operação de ponto de verificação
Um ponto de verificação executa os seguintes processos no banco de dados:
Escreve um registro no arquivo de log, marcando o início do ponto de verificação.
Armazena informações registradas para o ponto de verificação em uma cadeia de registros de log de ponto de verificação.
Uma informação registrada no ponto de verificação é o número de sequência de log (LSN) do primeiro registro de log que deve estar presente para o êxito de uma reversão de todo o banco de dados. Esse LSN é chamado de LSN de recuperação mínima (MinLSN). O MinLSN é o mínimo do:
- LSN do início do ponto de verificação.
- LSN do início da transação ativa mais antiga.
- LSN do início da transação de replicação mais antiga que ainda não foi entregue ao banco de dados de distribuição.
Os registros de ponto de verificação também contêm uma lista de todas as transações ativas que modificaram o banco de dados.
Se o banco de dados usar o modelo de recuperação simples, ele marca para reutilização o espaço que precede o MinLSN.
Grava todo o log sujo e páginas de dados no disco.
Grava um registro marcando o final do ponto de verificação no arquivo de log.
Grava o LSN do início dessa cadeia na página de inicialização de banco de dados.
Atividades que causam ponto de verificação
Os pontos de verificação ocorrem nas seguintes situações:
- Uma instrução CHECKPOINT é executada explicitamente. Um ponto de verificação ocorre no banco de dados atual para a conexão.
- Uma operação de log mínimo é executada no banco de dados; por exemplo, uma operação de cópia em massa é executada em um banco de dados que está usando o modelo de recuperação bulk-logged.
- Os arquivos de banco de dados foram adicionados ou removidos usando ALTER DATABASE.
- Uma instância do SQL Server é interrompida por uma instrução SHUTDOWN ou pela interrupção do serviço do SQL Server (MSSQLSERVER). Qualquer ação causa um ponto de verificação em cada banco de dados na instância do SQL Server.
- Uma instância do SQL Server gera periodicamente pontos de verificação automáticos em cada banco de dados para reduzir o tempo que a instância levaria para recuperar o banco de dados.
- É realizado um backup de banco de dados.
- É executada uma atividade que requer um desligamento de banco de dados. Isso pode acontecer quando a opção AUTO_CLOSE é ON e a última conexão do usuário com o banco de dados é encerrada. Outro exemplo é quando é feita uma alteração nas opções do banco de dados que exige a reinicialização desse banco de dados.
Pontos de verificação automáticos
O mecanismo de banco de dados do SQL Server gera pontos de verificação automáticos. O intervalo entre pontos de verificação automáticos baseia-se na quantidade de espaço do log usado e o tempo decorrido desde o último ponto de verificação. O intervalo de tempo entre pontos de verificação automáticos pode ser muito variável e longo se forem feitas algumas modificações no banco de dados. Pontos de verificação automáticos também podem ocorrer com frequência se forem modificados muitos dados.
Use a opção de configuração de servidor intervalo de recuperação para calcular o intervalo entre pontos de verificação automáticos para todos os bancos de dados em uma instância do servidor. Essa opção especifica o tempo máximo que o Mecanismo do Banco de Dados deve usar para recuperar um banco de dados durante um reinício do sistema. O Mecanismo do Banco de Dados calcula quantos registros de log podem ser processados no intervalo de recuperação durante uma operação de recuperação.
O intervalo entre pontos de verificação automáticos também depende do modelo de recuperação:
Se o banco de dados estiver usando o modelo de recuperação em partes ou completa, será gerado um ponto de verificação automático sempre que o número de registros de log atingir o número de estimativas do Mecanismo do Banco de Dados que ele pode processar durante o tempo especificado na opção de intervalo de recuperação.
Se o banco de dados estiver usando o modelo de recuperação simples, é gerado um ponto de verificação automático sempre que o número de registros de log atingir o menor destes dois valores:
- O log se torna 70% completo.
- O número de registros de log atinge o número de estimativas do Mecanismo do Banco de Dados que ele pode processar durante o tempo especificado na opção de intervalo de recuperação.
Para obter informações sobre como definir o intervalo de recuperação, consulte Configurar o intervalo de recuperação (min) (opção de configuração do servidor).
Dica
A opção de configuração avançada -k do SQL Server permite que um administrador de banco de dados limite o comportamento de E/S do ponto de verificação com base na taxa de transferência do subsistema de E/S para alguns tipos de pontos de verificação. A opção de configuração -k se aplica a pontos de verificação automáticos e a quaisquer outros pontos de verificação não limitados.
Pontos de verificação automáticos truncarão a seção não utilizada do log de transações se o banco de dados estiver usando o modelo de recuperação simples. No entanto, se o banco de dados estiver usando os modelo de recuperação bulk-logged, o log não será truncado por pontos de verificação automáticos. Para obter mais informações, consulte O log de transações.
A instrução CHECKPOINT agora fornece um argumento checkpoint_duration opcional que especifica o intervalo de tempo necessário, em segundos, para a conclusão dos pontos de verificação. Para obter mais informações, consulte CHECKPOINT.
Log ativo
A seção do arquivo de log desde o MinLSN até o último registro de log gravado é chamada de parte ativa do log ou log ativo. Essa é a seção do log necessária para fazer uma recuperação completa do banco de dados. Nenhuma parte do log ativo pode ter sido truncada. Todos os registros de log devem ser truncados das partes do log antes do MinLSN.
A ilustração a seguir mostra uma versão simplificada de um log de término de uma transação com duas transações ativas. Os registros de ponto de verificação foram compactados em um único registro.

LSN 148 é o último registro no log de transação. No momento em que o ponto de verificação gravado em LSN 147 foi processado, Tran 1 havia sido confirmada e Tran 2 era a única transação ativa. Isso torna o primeiro registro de log para Tran 2 o registro de log mais antigo para uma transação ativa no momento do último ponto de verificação. Isso torna LSN 142 o registro Iniciar transação para Tran 2, o MinLSN.
Transações de longa execução
O log ativo deve incluir todas as partes de todas as transações não confirmadas. Um aplicativo que inicia uma transação e não a confirma nem a reverte impede que o Mecanismo de Banco de Dados avance o MinLSN. Essa situação pode causar dois tipos de problemas:
- Se o sistema for desligado após a transação realizar muitas modificações não confirmadas, a fase de recuperação do reinício subsequente poderá demorar muito mais do que o tempo especificado na opção intervalo de recuperação .
- O log pode ficar muito grande, porque não pode ser truncado após o MinLSN. Isso ocorre mesmo que o banco de dados esteja usando o modelo de recuperação simples, no qual o log de transações é truncado em cada ponto de verificação automático.
A recuperação de transações de longa duração e os problemas descritos neste artigo podem ser evitados com o uso da Recuperação acelerada de banco de dados, um recurso disponível a partir do SQL Server 2019 (15.x) e no Banco de Dados SQL do Azure.
Transações de replicação
O Log Reader Agent monitora o log de transações de cada banco de dados configurado para replicação transacional e copia as transações marcadas para replicação do log de transações no banco de dados de distribuição. O log ativo deve conter todas as transações marcadas para replicação, mas que ainda não foram entregues ao banco de dados de distribuição. Se essas transações não forem replicadas em tempo hábil, elas poderão impedir o truncamento do log. Para obter mais informações, consulte Replicação transacional.
Conteúdo relacionado
- O log de transações
- Gerenciar o tamanho do arquivo de log de transações
- Backups de log de transações (SQL Server)
- Pontos de verificação de banco de dados (SQL Server)
- Configure the recovery interval (min) (opção de configuração do servidor)
- Recuperação acelerada de banco de dados
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Noções básicas sobre registro em log e recuperação no SQL Server, por Paul Randal
- Gerenciamento de log de transações do SQL Server, por Tony Davis e Gail Shaw
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários