Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O SQL Server Distributed Replay não está disponível com o SQL Server 2022 (16.x) e versões posteriores.
O recurso Microsoft SQL Server Distributed Replay ajuda a avaliar o efeito de futuras atualizações do SQL Server. Você também pode usá-lo para ajudar a avaliar o efeito das atualizações de hardware e do sistema operacional e do ajuste do SQL Server.
Descontinuação do Distributed Replay no SQL Server 2022
O Distributed Replay foi preterido a partir do SQL Server 2022 (16.x), conforme observado em Recursos preteridos do Mecanismo de Banco de Dados no SQL Server 2022 (16.x). O Distributed Replay tem uma dependência do SQL Server Native Client (SNAC), que foi removido do SQL Server 2022 (16.x). Essa alteração está documentada em Políticas de suporte para o SQL Server Native Client. Além disso, o Distributed Replay depende de .trc ficheiros, que são capturados com SQL Trace e SQL Server Profiler, ambos também preteridos.
O Distributed Replay Controller foi removido da Instalação do SQL Server 2022 (16.x) e o Distributed Replay Client não está mais disponível no SQL Server Management Studio (SSMS) a partir da versão 18. Para obter o Distributed Replay Controller, você deve instalar o SQL Server 2019 (15.x) ou uma versão anterior. Para obter o Distributed Replay Client, você deve instalar o SSMS 17.9.1.
Para os clientes do SQL Server 2022 (16.x), em vez disso, pode usar os utilitários da Replay Markup Language (RML), que incluem ostress, para reproduzir uma carga de trabalho.
Benefícios do Distributed Replay
Semelhante ao SQL Server Profiler, você pode usar o Distributed Replay para reproduzir um rastreamento capturado em um ambiente de teste atualizado. Ao contrário do SQL Server Profiler, o Distributed Replay não se limita a reproduzir a carga de trabalho de um único computador.
O Distributed Replay oferece uma solução mais escalável do que o SQL Server Profiler. Com o Distributed Replay, você pode reproduzir uma carga de trabalho de vários computadores e simular melhor uma carga de trabalho de missão crítica.
O recurso Distributed Replay pode usar vários computadores para reproduzir dados de rastreamento e simular uma carga de trabalho de missão crítica. Use o Distributed Replay para testes de compatibilidade de aplicativos, testes de desempenho ou planejamento de capacidade.
Quando deve utilizar o Distributed Replay
O SQL Server Profiler e o Distributed Replay fornecem alguma sobreposição de funcionalidades.
Você pode usar o SQL Server Profiler para reproduzir um rastreamento capturado em um ambiente de teste atualizado. Você também pode analisar os resultados do replay para procurar possíveis incompatibilidades funcionais e de desempenho. No entanto, o SQL Server Profiler só pode reproduzir uma carga de trabalho de um único computador. Ao reproduzir uma aplicação OLTP intensiva que tem muitas conexões simultâneas ativas ou alta taxa de transferência, o SQL Server Profiler pode se tornar um gargalo de recursos.
O Distributed Replay oferece uma solução mais escalável do que o SQL Server Profiler. Use o Distributed Replay para reproduzir uma carga de trabalho de vários computadores e simular melhor uma carga de trabalho de missão crítica.
A tabela a seguir descreve quando usar cada ferramenta.
| Ferramenta | Utilize quando... |
|---|---|
| SQL Server Profiler | Você deseja usar o mecanismo de reprodução convencional em um único computador. Em particular, você precisa de recursos de depuração linha por linha, como os comandos Step, Run to Cursor e Toggle Breakpoint . Você deseja reproduzir um rastreamento do Analysis Services. |
| Reprodução distribuída | Você deseja avaliar a compatibilidade do aplicativo. Por exemplo, você deseja testar cenários de atualização do SQL Server e do sistema operacional, atualizações de hardware ou ajuste de índice. A simultaneidade no rastreamento capturado é tão alta que um único cliente de repetição não pode simulá-la suficientemente. |
Conceitos de Reprodução Distribuída
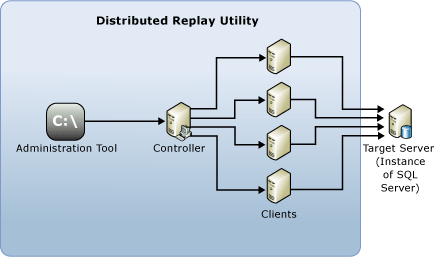
Os seguintes componentes compõem o ambiente do Distributed Replay:
Ferramenta de administração do Distributed Replay: uma aplicação de consola, DReplay.exe, usada para se comunicar com o controlador do Distributed Replay. Use a ferramenta de administração para controlar a reprodução distribuída.
Controlador do Distributed Replay: um computador que executa o serviço do Windows chamado controlador do SQL Server Distributed Replay. O controlador Distributed Replay orquestra as ações dos clientes de reprodução distribuída. Só pode haver uma instância do controlador em cada ambiente do Distributed Replay.
Clientes do Distributed Replay: um ou mais computadores (físicos ou virtuais) que executam o serviço do Windows chamado cliente SQL Server Distributed Replay. Os clientes do Distributed Replay trabalham juntos para simular cargas de trabalho em uma instância do SQL Server. Pode haver um ou mais clientes em cada ambiente do Distributed Replay.
Servidor de destino: uma instância do SQL Server que os clientes do Distributed Replay podem usar para reproduzir dados de rastreamento. Recomendamos que o servidor de destino esteja localizado em um ambiente de teste.
A ferramenta de administração, o controlador e o cliente do Distributed Replay podem ser instalados em computadores diferentes ou no mesmo computador. Pode haver apenas uma instância do controlador ou serviço de cliente do Distributed Replay em execução no mesmo computador.
A figura a seguir mostra a arquitetura física do SQL Server Distributed Replay:
Tarefas de Replay Distribuído
| Descrição da Tarefa | Artigo |
|---|---|
| Descreve como configurar o Distributed Replay. | Configurar Distributed Replay |
| Descreve como preparar os dados de rastreamento de entrada. | Preparar dados de rastreamento de entrada |
| Descreve como reproduzir dados de rastreamento. | Reproduzir Dados de Rastreamento |
| Descreve como analisar os resultados dos dados de rastreamento do Distributed Replay. | Revise os resultados do Replay |
| Descreve como usar a ferramenta de administração para iniciar, monitorar e cancelar operações no controlador. | Opções de Linha de Comando da Ferramenta de Administração (Distributed Replay Utility) |
Requerimentos
Antes de usar o recurso Distributed Replay, considere os requisitos do produto descritos neste artigo.
Requisitos de rastreamento de entrada
Para reproduzir com êxito os dados de rastreamento, eles devem atender aos requisitos de versão e formato e conter os eventos e colunas necessários.
Versões de rastreamento de entrada
O Distributed Replay dá suporte a dados de rastreamento de entrada coletados nas seguintes versões do SQL Server:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (Atualização cumulativa 1 e versões posteriores - consulte Versões de compilação do SQL Server 2017)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formatos de rastreamento de entrada
Os dados de rastreamento de entrada podem estar em qualquer um dos seguintes formatos:
Um único arquivo de rastreamento que tem a
.trcextensão.Um conjunto de arquivos de rastreamento de rotação que seguem a convenção de nomenclatura de rotação de arquivo, por exemplo:
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Inserir eventos e colunas de rastreamento
Os dados de rastreamento de entrada devem conter eventos e colunas específicos a serem reproduzidos pelo Distributed Replay. O modelo de TSQL_Replay no SQL Server Profiler contém todos os eventos e colunas necessários, além de informações extras. Para obter mais informações sobre esse modelo, consulte Requisitos de repetição.
Advertência
Se você não usar o modelo de TSQL_Replay para capturar os dados de rastreamento de entrada ou se os requisitos de rastreamento de entrada não forem atendidos, você poderá receber resultados de repetição inesperados.
Você também pode criar um modelo de rastreamento personalizado e usá-lo para reproduzir eventos com o Distributed Replay, desde que contenha os seguintes eventos:
- Login de auditoria
- Logout de auditoria
- Conexão existente
- Parâmetro de saída RPC
- RPC:Concluído
- RPC:Início
- SQL:ConjuntoConcluído
- SQL:BatchStarting
Se você estiver reproduzindo cursores do lado do servidor, os seguintes eventos também serão necessários:
- CursorFechar
- CursorExecute
- CursorOpen
- CursorPrepare
- CursorDespreparado
Se você estiver reproduzindo instruções SQL preparadas do lado do servidor, os seguintes eventos também serão necessários:
- SQL preparado pela Exec
- Preparar SQL
Todos os dados de rastreamento de entrada devem conter as seguintes colunas:
- Classe do evento
- Sequência de Eventos
- TextData
- Nome da Aplicação
- Nome de login
- Nome da Base de Dados
- ID da Base de Dados
- Nome do Anfitrião
- Dados binários
- SPID
- Hora de Início
- Hora de término
- IsSystem
Combinações de rastreamento de entrada e servidor de destino suportadas
A tabela a seguir lista as versões com suporte de dados de rastreamento e, para cada uma, as versões com suporte do SQL Server contra as quais os dados podem ser reproduzidos.
| Versão dos dados de rastreio de entrada | Versões com suporte do SQL Server para a instância do servidor de destino |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Requisitos do sistema operacional
Os sistemas operacionais com suporte para executar a ferramenta de administração e os serviços de controlador e cliente são os mesmos da instância do SQL Server. Para obter mais informações sobre quais sistemas operacionais têm suporte para sua instância do SQL Server, consulte Requisitos de hardware e software para SQL Server 2016 e SQL Server 2017.
Os recursos do Distributed Replay são suportados em sistemas operacionais baseados em x86 e x64. Para sistemas operativos baseados em x64, apenas o modo Windows on Windows (WOW) é suportado.
Limitações de instalação
Qualquer computador só pode ter uma única instância de cada recurso do Distributed Replay instalado. A tabela a seguir lista quantas instalações de cada recurso são permitidas em um único ambiente de Distributed Replay.
| Recurso de reprodução distribuída | Máximo de instalações por ambiente de reprodução |
|---|---|
| Serviço de controlador do Distributed Replay do SQL Server | 1 |
| Serviço de cliente do SQL Server Distributed Replay | 16 (computadores físicos ou virtuais) |
| Ferramenta de administração | Ilimitado |
Observação
Embora apenas uma instância da ferramenta de administração possa ser instalada em um único computador, você pode iniciar várias instâncias da ferramenta de administração. Os comandos emitidos a partir de várias ferramentas de administração são resolvidos na ordem em que são recebidos.
Provedor de acesso a dados
O Distributed Replay oferece suporte apenas ao provedor de acesso a dados ODBC do SQL Server Native Client.
Requisitos de preparação do servidor de destino
Recomendamos que o servidor de destino esteja localizado em um ambiente de teste. Para reproduzir dados de rastreamento em uma instância do SQL Server diferente da que foi originalmente gravada, verifique se as seguintes etapas foram feitas no servidor de destino:
Todos os logins e usuários contidos nos dados de rastreamento devem estar presentes no mesmo banco de dados no servidor de destino.
Todos os logins e usuários no servidor de destino devem ter as mesmas permissões que tinham no servidor original.
Idealmente, os IDs do banco de dados no destino devem ser os mesmos que os da origem. No entanto, se não forem iguais, a correspondência pode ser realizada com base em DatabaseName caso esteja presente no rastreio.
O banco de dados padrão para cada logon contido nos dados de rastreamento deve ser definido (no servidor de destino) como o respetivo banco de dados de destino do login. Por exemplo, os dados de rastreamento a serem reproduzidos contêm atividade para o login, Fred, no banco de dados Fred_Db na instância original do SQL Server. Portanto, no servidor de destino, o banco de dados padrão para o login, Fred, deve ser definido como o banco de dados que corresponde a Fred_Db (mesmo que o nome do banco de dados seja diferente). Para definir o banco de dados padrão do login, use o procedimento armazenado do sistema
sp_defaultdb.
A repetição de eventos associados a logins ausentes ou incorretos resulta em erros de repetição, mas a operação de repetição continua.