Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
No Service Manager, os dados presentes no data warehouse podem ser consolidados de várias fontes. Ele é apresentado por meio do Service Manager usando cubos de dados OLAP (Microsoft Online Analytical Processing) predefinidos e personalizados. Em resumo, a análise avançada no Service Manager consiste em publicar, exibir e manipular dados de cubo, geralmente no Microsoft Excel ou no Microsoft SharePoint. O Excel é usado principalmente por si mesmo para exibir e manipular dados. O SharePoint é usado principalmente como um meio de publicar e compartilhar dados de cubo.
O Service Manager inclui um armazém de dados em todo o System Center. Portanto, os dados do Operations Manager, do Configuration Manager e do Service Manager podem ser consolidados no data warehouse, onde você pode usar facilmente várias exibições de dados para obter as informações desejadas. Esta também é uma interface onde você pode colocar dados no mesmo data warehouse de suas próprias fontes personalizadas, como aplicativos SAP ou um aplicativo de recursos humanos de terceiros. Essa consolidação cria um modelo de dados comum e permite análises enriquecidas para ajudá-lo a criar um data warehouse em toda a sua organização de Tecnologia da Informação (TI) que pode atender a todas as suas necessidades de business intelligence e relatórios.
Quando seus dados estão em um modelo comum, você pode manipular informações e ter definições comuns e uma taxonomia comum para toda a sua empresa. Você pode fazer isso implantando cubos de dados OLAP e acessando as informações dos cubos, usando ferramentas padrão, como Excel e SharePoint. Isso possibilita que seus usuários empreguem habilidades que eles já conhecem. Você controla a definição da sua lógica de negócios de forma centralizada. Por exemplo, você pode definir indicadores-chave de desempenho, como os limites de tempo de resolução de incidentes, e quais valores para os limites são verde, amarelo ou vermelho. Você pode controlar essas escolhas de forma centralizada e capacitar seus usuários a usar facilmente os dados, mas fazer com que a definição comum apareça em seus relatórios do Excel ou painéis do SharePoint.
Sobre cubos OLAP do Service Manager
Os cubos OLAP (processamento analítico online) são um recurso do Service Manager que usa a infraestrutura de data warehouse existente para fornecer recursos de business intelligence de autoatendimento aos usuários finais.
Um cubo OLAP é uma estrutura de dados que supera as limitações dos bancos de dados relacionais fornecendo uma análise rápida dos dados. Os cubos podem exibir e somar grandes quantidades de dados, ao mesmo tempo em que fornecem aos usuários acesso pesquisável a quaisquer pontos de dados. Dessa forma, os dados podem ser acumulados, fatiados e cortados conforme necessário para lidar com a maior variedade de perguntas relevantes para a área de interesse de um usuário.
Fornecedores de software ou desenvolvedores de tecnologia da informação (TI) com um conhecimento prático de cubos OLAP podem criar pacotes de gerenciamento para definir seus próprios cubos OLAP extensíveis e personalizáveis que são criados na infraestrutura de data warehouse. Esses cubos são armazenados no SQL Server Analysis Services (SSAS). As ferramentas de business intelligence de autoatendimento, como o Excel e o SQL Server Reporting Services (SSRS), podem direcionar esses cubos no SSAS e você pode usá-los para analisar os dados de várias perspetivas.
Os bancos de dados que uma empresa usa para armazenar todas as suas transações e registros são chamados de bancos de dados OLTP (processamento de transações online). Esses bancos de dados geralmente têm registros que são inseridos um de cada vez e que contêm uma riqueza de informações que podem ser usadas por estrategistas para tomar decisões informadas sobre seus negócios. Os bancos de dados que são usados para armazenar os dados, no entanto, não foram projetados para análise. Portanto, recuperar respostas dessas bases de dados é dispendioso em termos de tempo e esforço. Os bancos de dados OLAP são bancos de dados especializados projetados para ajudar a extrair essas informações de business intelligence dos dados.
Os cubos OLAP podem ser considerados como a peça final do quebra-cabeça para uma solução de armazenamento de dados. Um cubo OLAP, também conhecido como cubo multidimensional ou hipercubo, é uma estrutura de dados no SQL Server Analysis Services (SSAS) que é criada, usando bancos de dados OLAP, para permitir a análise quase instantânea de dados. A topologia deste sistema é mostrada na ilustração a seguir.
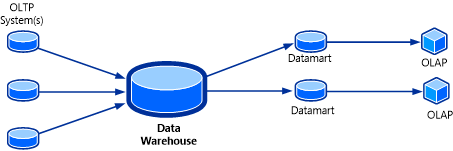
O recurso útil de um cubo OLAP é que os dados no cubo podem ser contidos em um formulário agregado. Para o usuário, o cubo parece ter as respostas com antecedência porque sortimentos de valores já estão pré-calculados. Sem ter que consultar o banco de dados OLAP de origem, o cubo pode retornar respostas para uma ampla gama de perguntas quase instantaneamente.
O principal objetivo dos cubos OLAP do Service Manager é dar aos fornecedores de software ou desenvolvedores de tecnologia da informação (TI) a capacidade de realizar análises quase instantâneas de dados para fins de análise histórica e tendências. O Gestor de Serviços faz isso ao:
- Permitindo que você defina cubos OLAP em pacotes de gerenciamento que serão criados automaticamente no SSAS quando o pacote de gerenciamento for implantado.
- Manutenção automática do cubo sem intervenção do usuário, executando tarefas como processamento, particionamento, traduções e localização e alterações de esquema.
- Permitindo que os usuários usem ferramentas de business intelligence de autoatendimento, como o Excel, para analisar os dados de várias perspetivas.
- Salvar relatórios gerados do Excel para referência futura.
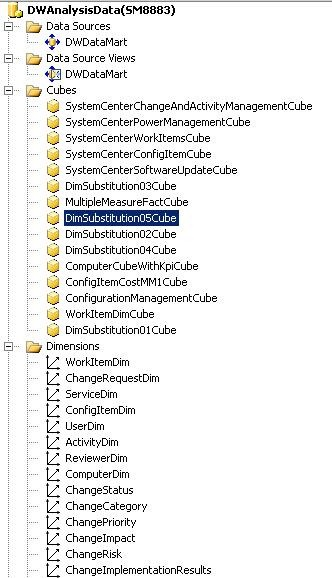
Para ver como os cubos de data warehouse são representados no Console do Service Manager, navegue até ao espaço de trabalho Data Warehouse e selecione Cubos.
Cubos OLAP do Service Manager
A ilustração a seguir mostra uma imagem do SQL Server Business Intelligence Development Studio (BIDS) que mostra as partes principais necessárias para cubos OLAP (processamento analítico online). Essas partes são a fonte de dados, a exibição da fonte de dados, os cubos e as dimensões. As seções a seguir descrevem as partes do cubo OLAP e as ações que os usuários podem executar usando-as.
Fonte de dados
Uma fonte de dados é a origem de todos os dados contidos em um cubo OLAP. Um cubo OLAP se conecta a uma fonte de dados para ler e processar dados brutos para executar agregações e cálculos para suas medidas associadas. A fonte de dados para todos os cubos OLAP do Service Manager são os data marts, que incluem os data marts do Operations Manager e do Configuration Manager. As informações de autenticação sobre a fonte de dados devem ser armazenadas no SQL Server Analysis Services (SSAS) para estabelecer o nível correto de permissões.
Exibição da fonte de dados
A exibição da fonte de dados (DSV) é uma coleção de exibições que representam as tabelas de dimensão, fato e outrigger da fonte de dados, como os data marts do Service Manager. O DSV contém todas as relações entre tabelas, como chaves primária e estrangeira. Em outras palavras, o DSV especifica como o banco de dados SSAS será mapeado para o esquema relacional e fornece uma camada de abstração sobre o banco de dados relacional. Usando essa camada de abstração, as relações podem ser definidas entre tabelas de fatos e dimensões, mesmo que não existam relações dentro do banco de dados relacional de origem. Cálculos nomeados, medidas personalizadas e novos atributos também podem ser definidos no DSV que podem não existir nativamente no esquema dimensional do data warehouse. Por exemplo, um cálculo nomeado que define um valor booleano para Incidentes Resolvidos calcula o valor como verdadeiro se o estado de incidente estiver como resolvido ou fechado. Usando o cálculo nomeado, o Service Manager pode definir uma medida para exibir informações úteis, como a porcentagem de incidentes resolvidos, o número total de incidentes resolvidos e o número total de incidentes que não foram resolvidos.
Outro exemplo rápido de um cálculo nomeado é ReleasesImplementedOnSchedule. Esse cálculo nomeado fornece uma verificação rápida do status de integridade no número de registros de liberação em que a data de término real é menor ou igual à data de término agendada.
Cubos OLAP
Um cubo OLAP é uma estrutura de dados que supera as limitações dos bancos de dados relacionais fornecendo uma análise rápida dos dados. Os cubos OLAP podem exibir e somar grandes quantidades de dados e, ao mesmo tempo, fornecer aos usuários acesso pesquisável a quaisquer pontos de dados para que os dados possam ser acumulados, fatiados e cortados conforme necessário para lidar com a maior variedade de perguntas relevantes para a área de interesse de um usuário.
Dimensões
Uma dimensão no SSAS faz referência a uma dimensão do data warehouse do Service Manager. No Service Manager, uma dimensão é aproximadamente equivalente a uma classe de pacote de gerenciamento. Cada classe de pacote de gerenciamento tem uma lista de propriedades, enquanto cada dimensão contém uma lista de atributos, com cada atributo mapeado para uma propriedade em uma classe. As dimensões permitem filtrar, agrupar e rotular dados. Por exemplo, você pode filtrar computadores pelo sistema operacional instalado e agrupar pessoas em categorias por sexo ou idade. Os dados podem então ser apresentados num formato em que os dados são categorizados naturalmente nestas hierarquias e categorias para permitir uma análise mais aprofundada. As dimensões também podem ter hierarquias naturais para permitir que os utilizadores "detalhem" para níveis mais detalhados. Por exemplo, a dimensão Data tem uma hierarquia que pode ser detalhada por Ano, Trimestre, Mês, Semana e Dia.
A ilustração a seguir mostra um cubo OLAP que contém as dimensões Data, Região e Produto.

Por exemplo, os membros da equipe da Microsoft podem querer um resumo rápido e simples das vendas do console de jogos Xbox One na versão aplicável. Eles podem detalhar ainda mais para obter números de vendas para um período de tempo mais focado. Os analistas de negócios podem querer examinar como as vendas dos consoles Xbox One foram afetadas pelo lançamento do novo design do console e do Kinect para Xbox One. Isso os ajuda a determinar quais tendências de vendas estão ocorrendo e quais possíveis revisões da estratégia de negócios são necessárias. Ao filtrar a dimensão de data, essas informações podem ser rapidamente entregues e consumidas. Esse fatiamento e corte de dados só é habilitado porque as dimensões foram projetadas com atributos e dados que podem ser facilmente filtrados e agrupados pelo cliente.
No Service Manager, todos os cubos OLAP compartilham um conjunto comum de dimensões. Todas as dimensões utilizam o data mart do data warehouse principal como fonte, mesmo em vários cenários com múltiplos data marts. Em vários cenários de data mart, isso pode levar a erros de chave de dimensão durante o processamento do cubo.
Grupo de medidas
Um grupo de medidas é o mesmo conceito de um fato na terminologia do data warehouse. Assim como os fatos contêm medidas numéricas em um data warehouse, um grupo de medidas contém medidas para um cubo OLAP. Todas as medidas em um cubo OLAP que derivam de uma única tabela de fatos em uma exibição da fonte de dados também podem ser consideradas um grupo de medidas. Pode haver casos, no entanto, em que haverá várias tabelas de fatos das quais derivam as medidas em um cubo OLAP. Medidas do mesmo nível de detalhe são unidas em um grupo de medidas. Os grupos de medidas definem quais dados serão carregados no sistema, como os dados são carregados e como os dados são vinculados ao cubo multidimensional.
Cada grupo de medidas também contém uma lista de partições, que contêm os dados reais em seções separadas e não sobrepostas. Os grupos de medidas também contêm design de agregação, que define os conjuntos de dados pré-resumidos que são calculados para cada grupo de medidas para melhorar o desempenho das consultas do usuário.
Medidas
Medidas são os valores numéricos que os usuários desejam fatiar, segmentar, agregar e analisar; eles são uma das razões fundamentais pelas quais você gostaria de criar cubos OLAP usando a infraestrutura de armazenamento de dados. Usando o SSAS, você pode criar cubos OLAP que aplicarão regras de negócios e cálculos para formatar e exibir medidas em um formato personalizável. Grande parte do tempo de desenvolvimento do cubo OLAP será gasto determinando e definindo quais medidas serão exibidas e como elas serão calculadas.
Medidas são valores que geralmente são mapeados para colunas numéricas numa tabela de factos num data warehouse, mas também podem ser criadas em atributos de dimensão e dimensão degenerada. Essas medidas são os valores mais importantes de um cubo OLAP que são analisados e o principal interesse para os usuários finais que navegam no cubo OLAP. Um exemplo de uma medida que existe no data warehouse é ActivityTotalTimeMeasure. ActivityTotalTimeMeasure é uma medida de ActivityStatusDurationFact que representa o tempo que cada atividade está em um determinado status. O nível de detalhe de uma medida é composto por todas as dimensões que são referenciadas. Por exemplo, o nível de detalhe do fato de relacionamento ComputerHostsOperatingSystem opera nas dimensões Computador e Sistema Operacional.
As funções de agregação são calculadas em medidas para permitir uma análise mais aprofundada dos dados. A função de agregação mais comum é Soma. Uma consulta de cubo OLAP comum, por exemplo, resume o tempo total para todas as atividades que estão Em Progresso. Outras funções de agregação comuns incluem Min, Max e Count.
Depois que os dados brutos tiverem sido processados em um cubo OLAP, os usuários poderão executar cálculos e consultas mais complexos usando expressões multidimensionais (MDX) para definir suas próprias expressões de medida ou membros calculados. MDX é o padrão do setor para consultar e acessar dados armazenados em sistemas OLAP. O SQL Server não foi projetado para trabalhar com o modelo de dados suportado por bancos de dados multidimensionais.
Exploração detalhada
Quando um usuário detalha os dados em um cubo OLAP, ele está analisando os dados em um nível diferente de sumarização. O nível de detalhe dos dados muda à medida que o usuário faz drill down, examinando os dados em diferentes níveis na hierarquia. À medida que os usuários fazem drill down, eles passam de informações resumidas para dados com um foco mais restrito. Seguem-se exemplos de detalhamento:
- Detalhando dados para analisar informações demográficas da população dos Estados Unidos, depois do estado de Washington, depois da área metropolitana da cidade de Seattle, depois da cidade de Redmond e, finalmente, da população da Microsoft.
- Detalhando os números de vendas dos consoles Xbox One para o ano civil de 2015, depois o quarto trimestre do ano, depois o mês de dezembro, depois a semana antes do Natal e, finalmente, a véspera de Natal.
Detalhamento
Quando os usuários dados de detalhados, eles querem ver todas as transações individuais que contribuíram para os dados agregados do cubo OLAP. Em outras palavras, o usuário pode recuperar os dados em um nível mais baixo de detalhe para um determinado valor de medida. Por exemplo, quando recebe os dados de vendas de um determinado mês e categoria de produto, pode analisar esses dados mais detalhadamente para ver uma lista de cada linha da tabela contida nessa célula da tabela.
É comum confundir os termos detalhar e perfurar entre si. A principal diferença entre eles é que um detalhamento funciona numa hierarquia predefinida de dados - por exemplo, Estados Unidos, depois em direção a Washington, depois em direção a Seattle - dentro do cubo OLAP. Uma análise detalhada vai diretamente para o nível mais detalhado dos dados e recupera um conjunto de linhas da fonte de dados que foram agregadas em uma única célula.
Indicador-chave de desempenho
As organizações podem usar indicadores-chave de desempenho (KPIs) para avaliar a saúde de sua empresa e seu desempenho, medindo seu progresso em direção às metas. Os KPIs são métricas de negócios que podem ser definidas para monitorar o progresso em direção a determinados objetivos e metas predefinidos. Um KPI tem um valor alvo e um valor real, que representa um objetivo quantitativo que é crítico para o sucesso da organização. Os KPIs são exibidos em grupos numa folha de avaliação para mostrar a saúde geral da empresa num instantâneo.
Um exemplo de KPI é concluir todas as solicitações de alteração dentro de 48 horas. Um KPI pode ser usado para medir a porcentagem de solicitações de alteração que são resolvidas dentro desse período. Você pode criar painéis para representar KPIs visualmente. Por exemplo, talvez queira definir um valor alvo de KPI para que 75% de todas as solicitações de alteração sejam concluídas dentro de 48 horas.
Divisórias
Uma partição é uma estrutura de dados que contém alguns ou todos os dados em um grupo de medidas. Cada grupo de medidas é dividido em partições. Uma partição define um subconjunto dos dados de fato que são carregados no grupo de medidas. O SSAS Standard Edition permite apenas uma partição por grupo de medidas, enquanto o SSAS Enterprise Edition permite que um grupo de medidas contenha várias partições. As partições são um recurso transparente para o usuário final, mas têm um grande impacto no desempenho e na escalabilidade dos cubos OLAP. Todas as partições para um grupo de medidas sempre existem no mesmo banco de dados físico.
As partições possibilitam que um administrador gerencie melhor um cubo OLAP e melhore o desempenho de um cubo OLAP. Por exemplo, você pode remover ou reprocessar os dados em uma partição de um grupo de medidas sem afetar o restante do grupo de medidas. Quando você carrega novos dados em uma tabela de fatos, somente as partições que devem conter os novos dados são afetadas.
O particionamento também melhora o processamento e o desempenho da consulta para cubos OLAP. O SSAS pode processar várias partições em paralelo, levando a um uso muito mais eficiente dos recursos de CPU e memória no servidor. Enquanto executa uma consulta, o SSAS busca, processa e agrega dados de várias partições também, apenas as partições que contêm os dados relevantes para uma consulta são verificadas, o que reduz a quantidade geral de entrada e saída.
Um exemplo de uma estratégia de particionamento é colocar os dados de fato de cada mês em uma partição mensal. No final de cada mês, todos os novos dados entram em uma nova partição, o que leva a uma distribuição natural de dados com valores não sobrepostos.
Agregações
As agregações em um cubo OLAP são conjuntos de dados pré-resumidos. Eles são análogos a uma instrução SQL SELECT com uma cláusula GROUP BY. O SSAS pode usar essas agregações quando responde a consultas para reduzir a quantidade de cálculos necessários, retornando as respostas rapidamente ao usuário. As agregações internas no cubo OLAP reduzem a quantidade de agregação que o SSAS precisa executar no momento da consulta. A criação das agregações corretas pode melhorar drasticamente o desempenho da consulta. Isso geralmente é um processo em evolução ao longo da vida útil do cubo OLAP à medida que suas consultas e uso mudam.
Normalmente, é criado um conjunto base de agregações que será útil para a maioria das consultas no cubo OLAP. As agregações são criadas para cada partição de um cubo OLAP dentro de um grupo de medidas. Quando uma agregação é criada, certos atributos de dimensões são incluídos no conjunto de dados pré-resumidos. Os usuários podem consultar rapidamente os dados com base nessas agregações quando navegam no cubo OLAP. As agregações devem ser projetadas com cuidado porque o número de agregações potenciais é tão grande que a construção de todas elas levaria uma quantidade excessiva de tempo e espaço de armazenamento.
O Service Manager usa as duas opções a seguir quando cria e projeta agregações em cubos OLAP do Service Manager:
- Alcance do ganho de desempenho
- Otimização baseada no uso
A opção Performance Gain Reaches define qual porcentagem de agregações é construída. Por exemplo, definir essa opção para o valor padrão e recomendado de 30% significa que as agregações serão criadas para dar ao cubo OLAP um ganho de desempenho estimado de 30%. No entanto, isso não significa que 30% das agregações possíveis serão construídas.
A otimização baseada no uso possibilita que o SSAS registre as solicitações de dados para que, quando uma consulta for executada, as informações sejam alimentadas no processo de design de agregação. Em seguida, o SSAS analisa os dados e recomenda quais agregações devem ser criadas para obter o melhor ganho de desempenho estimado.
Particionamento de cubo do Service Manager
Cada grupo de medidas em um cubo é dividido em partições, onde uma partição define uma parte dos dados de fato que são carregados em um grupo de medidas. O SQL Server Analysis Services (SSAS) no SQL Server Standard Edition permite apenas uma partição por grupo de medidas, enquanto várias partições são permitidas no Enterprise Edition. As partições são completamente transparentes para o utilizador final, mas têm um impacto importante no desempenho e na escalabilidade. Por exemplo, as partições podem ser processadas separadamente e em paralelo. Eles podem ter diferentes designs de agregação. Você pode reprocessar uma partição sem afetar todas as outras partições em um grupo de medidas. Além disso, o SSAS verifica automaticamente apenas as partições que contêm os dados necessários para uma consulta, o que pode melhorar consideravelmente o desempenho da consulta.
O particionamento de cubo é realizado em cada tarefa de manutenção de data warehouse, que ocorre a cada hora por padrão. O módulo de processo específico que é executado é chamado ManageCubePartitions. É sempre executado após a etapa CreateMartPartitions. Esses dados de dependência são armazenados na tabela infra.moduletriggercondition.
A principal biblioteca de vínculo dinâmico (DLL), que lida com particionamento, está na DLL do utilitário de depósito, Microsoft.EnterpriseManagement.Warehouse.Utility, na classe PartitionUtil. Especificamente, há um método ManagePartitions() na classe que lida com toda a manutenção de partição. A DLL de manutenção do data warehouse, Microsoft.EnterpriseManagement.Warehouse.Maintenance e a DLL de processamento analítico online (OLAP) do data warehouse, Microsoft.EnterpriseManagement.Warehouse.Olap, chamam Microsoft.EnterpriseManagement.Warehouse.Utility para lidar com partições durante a manutenção e a implantação do cubo. É por isso que a manipulação de partição real está na DLL do utilitário de armazém comum para evitar a duplicação de lógica ou código.
A Manutenção de Particionamento de Cubo executa as seguintes tarefas:
- Criar partições
- Excluir partições
- Atualizar limites de partição
Para fazer isso, a tabela SQL (Structured Query Language) etl.TablePartition é lida para determinar todas as partições de factos que foram criadas para um grupo de medidas. As seguintes ações ocorrem:
- Iniciar o processamento do cubo para cada grupo de medidas no cubo
- Obtenha todas as partições da tabela etl.TablePartition para o grupo de medidas
- Exclua todas as partições que existem no grupo de medidas, mas que não estão presentes na tabela etl.TablePartition.
- Adicione quaisquer novas partições que tenham sido criadas e que existam apenas na tabela etl.TablePartition
- Atualize qualquer partição que possa ter sido alterada, correspondendo cada partição com RangeStartDate e RangeEndDate na etl.TablePartition.
Lembre-se do seguinte sobre o processamento de cubos:
- Somente grupos de medidas direcionados a fatos contêm várias partições no SQL Server Standard Edition. Por padrão, todos os grupos de medidas e dimensões contêm apenas uma partição. Portanto, a partição não tem condições de limite.
- Os limites da partição são definidos por uma associação de consulta baseada em datekeys que correspondem às datekeys para a partição de fato correspondente na tabela etl.TablePartition.
Implantação do cubo OLAP do Service Manager
A implantação de cubo OLAP (processamento analítico online) usa a infraestrutura de implantação do Service Manager para criar cubos OLAP no banco de dados do SQL Server Analysis Services (SSAS).
Para resumir, um elemento implantável retorna um implantador com uma coleção de recursos que são serializados e que são usados para criar o cubo OLAP no banco de dados SSAS. Para cubos OLAP, o nome do objeto implantável é CubeDeployable para o elemento SystemCenterCube e CubeExtensionDeployable para o elemento CubeExtension. O implantador para ambos os elementos é CubeDeployer.
A tabela dbo.Selector no banco de dados DWStagingAndConfig contém uma entrada para os elementos do pack de gestão SystemCenterCube e CubeExtension. O mecanismo de implantação usa esses metadados se for necessário um processamento de implantação adicional para um elemento do pacote de gerenciamento quando o pacote de gerenciamento for importado para o data warehouse usando o trabalho MPSync.
As implantações usam a interface de programação de aplicativo (API) do Analysis Management Objects (AMO) para criar e modificar todos os componentes do cubo no banco de dados do SSAS. Especificamente, o AMO no modo desconectado é usado porque o elemento CubeDeployable não terá uma conexão com o banco de dados do SSAS. Trabalhar com AMO no modo desconectado torna possível criar toda a árvore de objetos AMO sem estabelecer uma conexão com o servidor. Em seguida, o Service Manager serializa a hierarquia de objetos como recursos de fluxo e os anexa ao objeto do implantador que é passado de volta para a infraestrutura de implantação. O objeto deployer é então desserializado, estabelece uma conexão com o banco de dados SSAD e cria os objetos enviando as solicitações apropriadas para o servidor.
Somente os objetos principais podem ser serializados. No AMO, os objetos principais são considerados classes que representam um objeto completo como uma entidade completa e não como parte de outro objeto. Por exemplo, os objetos principais incluem Server, Cube e Dimension, que são todas entidades autônomas. O DimensionAttribute, no entanto, não é um objeto principal porque só pode ser criado como parte de um objeto principal pai de Dimension. DimensionAttribute, portanto, é um objeto secundário. O design do cubo OLAP se concentra na criação de todos os objetos principais necessários para cubos, juntamente com quaisquer objetos secundários dependentes. Esses objetos principais são os objetos que serão serializados e, eventualmente, desserializados antes que os objetos sejam criados no banco de dados SSAS.
Os recursos que encapsulam objetos principais devem ser criados em uma ordem específica para que a implantação seja concluída com êxito e satisfaça os requisitos de dependência dos elementos de cubo OLAP. As duas listas a seguir ilustram a sequência de implantação para os elementos SystemCenterCube e CubeExtension, respectivamente:
- Elementos DataSourceView
- elementos de dimensão
- elemento de dimensão de data
- elemento cubo
- Elementos DataSourceView
- elemento cubo
Processamento de cubo OLAP do Service Manager
Quando um cubo OLAP (processamento analítico online) foi implantado e todas as suas partições foram criadas, ele está pronto para ser processado para que seja visível. O processamento de um cubo é a etapa final após a execução dos processos de extração, transformação e carregamento (ETL). Essas etapas ocorrem da seguinte maneira:
- Extrair: extrair dados do sistema de origem
- Transformar: Aplicar funções para conformar dados a um esquema dimensional padrão
- Carregar: Carregue os dados no data mart para consumo
- Processo: Carregue os dados do data mart no cubo OLAP para navegar
O processamento de um cubo OLAP ocorre quando todas as agregações para o cubo são calculadas e o cubo é carregado com essas agregações e dados. As tabelas de dimensões e fatos são lidas e os dados são calculados e carregados no cubo. Quando você projeta um cubo OLAP, o processamento deve ser cuidadosamente considerado devido ao efeito potencialmente significativo que o processamento pode ter em um ambiente de produção onde milhões de registros podem existir. Um processo completo de todas as partições em tal ambiente pode levar de dias a até semanas, o que pode tornar a infraestrutura e os cubos do Service Manager inutilizáveis para os usuários finais. Uma recomendação é desativar o cronograma de processamento de quaisquer cubos que não estejam sendo usados para reduzir a sobrecarga no sistema.
O processamento do cubo OLAP consiste em duas tarefas separadas:
- Processamento de dimensões
- Processamento de partições
Cada cubo OLAP tem um trabalho de processamento correspondente no Service Manager Console e é executado em uma agenda configurável pelo usuário. Cada tipo de tarefa de processamento é descrito nas seções a seguir.
Processamento de dimensões
Sempre que uma nova dimensão é adicionada ao banco de dados do SQL Server Analysis Server (SSAS), um processo completo deve ser executado na dimensão para levá-la a um estado totalmente processado. Depois que uma dimensão for processada, no entanto, não há garantia de que ela será processada novamente quando outro cubo direcionado à mesma dimensão for processado. Ao não reprocessar automaticamente a dimensão, impede-se que o Service Manager reprocesse todas as dimensões de cada cubo. Isso é especialmente verdadeiro se a dimensão tiver sido processada recentemente, porque é improvável que existam novos dados que ainda não tenham sido processados. Para otimizar a eficiência de processamento, há uma classe singleton, que é definida no pacote de gerenciamento Microsoft.SystemCenter.Datawarehouse.OLAP.Base, chamado Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval. Segue-se um exemplo desta classe:
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Essa classe singleton contém uma propriedade, IntervalInMinutes, que descreve a frequência de processamento de uma dimensão. Por defeito, esta propriedade é definida como 60 minutos. Por exemplo, se uma dimensão foi processada às 15h05 e outro cubo destinado à mesma dimensão é processado às 15h45, a dimensão não será reprocessada. Uma desvantagem desta abordagem é o aumento da probabilidade de erros de chave de dimensão. Um mecanismo de repetição lida com erros de chaves de dimensão para reprocessar a dimensão e, em seguida, a partição do cubo. Para obter mais informações sobre falhas de processamento, consulte a seção "Problemas comuns com depuração e solução de problemas".
Depois que uma dimensão tiver sido totalmente processada, o processamento incremental com ProcessUpdate será executado. A única outra vez que ProcessFull é executada é quando um esquema de dimensão muda, porque resulta no retorno da dimensão a um estado não processado. Lembre-se de que, se ProcessFull for executado numa dimensão, todos os cubos afetados e suas partições ficarão em um estado de não processado e terão que ser totalmente processados na sua próxima execução programada.
Processamento de partições
O processamento de partições deve ser cuidadosamente considerado porque o reprocessamento de uma partição grande é lento e consome muitos recursos da CPU no servidor que hospeda o SSAS. O processamento de partições geralmente leva mais tempo do que o processamento de dimensão. Ao contrário do processamento de dimensão, o processamento de uma partição não tem efeitos colaterais em outros objetos. Os dois únicos tipos de processamento que são executados em cubos OLAP do System Center - Service Manager são ProcessFull e ProcessAdd.
Semelhante às dimensões, a criação de novas partições em um cubo OLAP requer uma tarefa ProcessFull para que a partição esteja em um estado em que possa ser consultada. Como uma tarefa ProcessFull é uma operação cara, você deve executar uma tarefa ProcessFull somente quando necessário; por exemplo, quando você cria uma partição ou quando uma linha foi atualizada. Em cenários nos quais linhas foram adicionadas e nenhuma linha foi atualizada, o Service Manager pode executar uma tarefa ProcessAdd. Para fazer isso, o Service Manager usa marcas d'água e outros metadados. Especificamente, a tabela etl.cubepartition e a tabela etl.tablepartition são consultadas para determinar o tipo de processamento a ser executado.
O diagrama seguinte ilustra como o Service Manager determina que tipo de processamento realizar com base nos dados de marcas d'água.

Quando uma tarefa ProcessAdd é executada, o Service Manager limita o escopo da consulta usando marcadores. Por exemplo, se o valor InsertedBatchId for 100 e o valor WatermarkBatchId for 50, a consulta apenas carregará dados do data mart onde o InsertedBatchId for maior que 50 e menor que 100.
Por fim, é importante observar que o Service Manager não oferece suporte ao processamento manual de cubos OLAP usando SSAS ou Business Intelligence Development Studio. O processamento de cubos fora dos métodos fornecidos no System Center - Service Manager, incluindo o Console do Service Manager e os cmdlets do Service Manager, não atualizará as tabelas de marca d'água. Portanto, é possível que ocorram problemas de integridade de dados. Se você acidentalmente reprocessou o cubo manualmente, uma solução possível é desprocessar o cubo OLAP manualmente da mesma maneira. Em seguida, da próxima vez que o Service Manager processar o cubo, ele executará automaticamente uma tarefa ProcessFull porque as partições estarão em um estado não processado. Isso atualizará todas as marcas d'água e metadados corretamente para que quaisquer possíveis problemas de integridade de dados sejam corrigidos.
Manter os cubos OLAP do Service Manager
As informações nas seções a seguir descrevem as práticas recomendadas de manutenção para cubos OLAP (processamento analítico online).
Reprocessar periodicamente as dimensões do Analysis Services
As práticas recomendadas do SQL Server Analysis Services (SSAS) recomendam que as dimensões do SSAS sejam totalmente processadas periodicamente. O processamento completo das dimensões reconstrói índices e otimiza o armazenamento de dados multidimensionais, o que melhora o desempenho de consultas e cubos que podem se degradar com o tempo. Isso é semelhante a desfragmentar periodicamente um disco rígido em um computador.
No entanto, uma desvantagem de processar totalmente uma dimensão SSAS é que todos os cubos OLAP afetados ficam sem processamento e também devem ser totalmente processados para retorná-los ao estado em que você pode consultá-los. O Service Manager não processa as dimensões do SSAS de forma totalmente explícita. Portanto, você deve decidir quando executar essa tarefa de manutenção.
Considerações sobre memória
Se você executar todas as operações de extração, transformação e carregamento (ETL) do data warehouse e as funções de cubo OLAP em um servidor, considere cuidadosamente as necessidades de memória do sistema operacional, do data warehouse e do SSAS para garantir que o servidor possa lidar com todas as operações com uso intensivo de dados que podem ser executadas simultaneamente. Isso é especialmente importante porque o processamento de cubos OLAP é uma operação que consome muita memória.