Gerir Espaços de Armazenamento Direto no VMM
Importante
Esta versão do Virtual Machine Manager (VMM) chegou ao fim do suporte. Recomendamos que atualize para o VMM 2022.
Este artigo fornece uma descrição geral do Espaços de Armazenamento Direto (S2D) e como é implementado nos recursos de infraestrutura do System Center – Virtual Machine Manager (VMM).
Espaços de Armazenamento Direto (S2D) foi introduzido no Windows Server 2016. Agrupa unidades de armazenamento físico em agrupamentos de armazenamento virtuais para fornecer armazenamento virtualizado. Com o armazenamento virtualizado, pode:
- Gerir múltiplas origens de armazenamento físico como uma única entidade virtual.
- Obtenha armazenamento barato, com e sem dispositivos de armazenamento externo.
- Recolher diferentes tipos de armazenamento num único agrupamento virtual de armazenamento.
- Aprovisione facilmente o armazenamento e expanda o armazenamento virtualizado a pedido ao adicionar novas unidades.
Nota
O VMM 2019 UR3 e posterior suporta a Infraestrutura Hiperconvergida do Azure Stack (HCI, versão 20H2).
Nota
O VMM 2022 suporta a Infraestrutura Hiperconvergida do Azure Stack (HCI, versão 20H2 e 21H2).
Como funciona?
O S2D cria agrupamentos de armazenamento a partir do armazenamento anexado a nós específicos num cluster do Windows Server. O armazenamento pode ser interno nos dispositivos de nó ou disco que estão diretamente ligados a um único nó. As unidades de armazenamento suportadas incluem o NVMe, SDD (ligado através de SATA ou SAS) e HDD. Saiba mais.
- Quando ativa o S2D num cluster do Windows Server, o S2D deteta automaticamente o armazenamento elegível e adiciona-o a um agrupamento de armazenamento para o cluster.
- O S2D também cria uma cache de armazenamento incorporada do lado do servidor para maximizar o desempenho. As unidades mais rápidas são utilizadas para colocação em cache e as restantes unidades para capacidade. Saiba mais sobre a cache.
- Os volumes são criados a partir de um agrupamento de armazenamento. Criar um volume cria o disco virtual (espaço de armazenamento), cria partições e formatação, adiciona-o ao cluster e converte-o num volume partilhado de cluster (CSV).
- Para especificar a forma como os discos virtuais são distribuídos pelos discos físicos no agrupamento, deve configurar diferentes níveis de tolerância a falhas de um volume, com o SMB 3.0. Pode configurar um volume sem resiliência ou com resiliência espelhada ou de paridade. Saiba mais.
Implementação convergida e não convergida
Um cluster com S2D pode ser implementado de duas formas:
- Implementação hiperconvergida: a computação Hyper-V e o armazenamento S2D são executados no mesmo cluster, sem separação entre eles. Isto fornece dimensionamento simultâneo de recursos de computação e armazenamento.
- Implementação desagregada: os recursos de computação são executados num cluster Hyper-V. O armazenamento S2D é executado num cluster diferente. Pode dimensionar os clusters separadamente para uma gestão otimizada.
Implementação hiperconvergida
Eis uma ilustração da implementação hiperconvergida
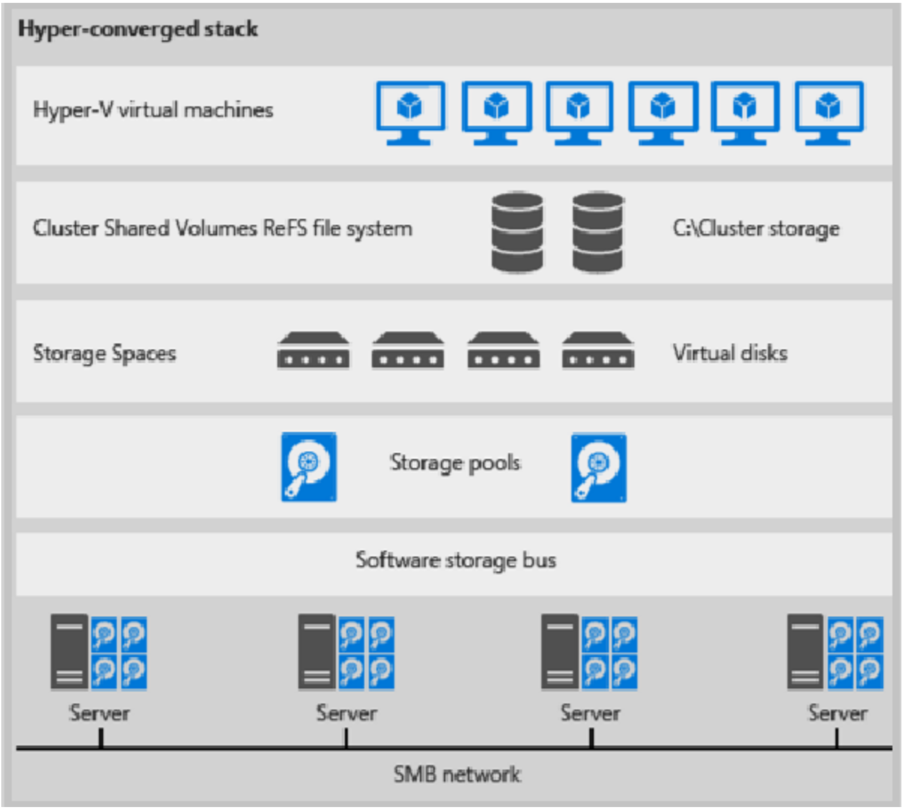
Figura 1: implementação hiperconvergida
- Os ficheiros de VM são armazenados em CSVs locais.
- As partilhas de ficheiros e SMB não são utilizadas.
- Depois de os volumes CSV S2D estarem disponíveis, aprovisione-os tal como faria com qualquer outra implementação do Hyper-V.
- Pode dimensionar o cluster de cálculo hyper-V juntamente com o respetivo armazenamento S2D.
Implementação desagregada
Eis uma ilustração para a implementação desagregada
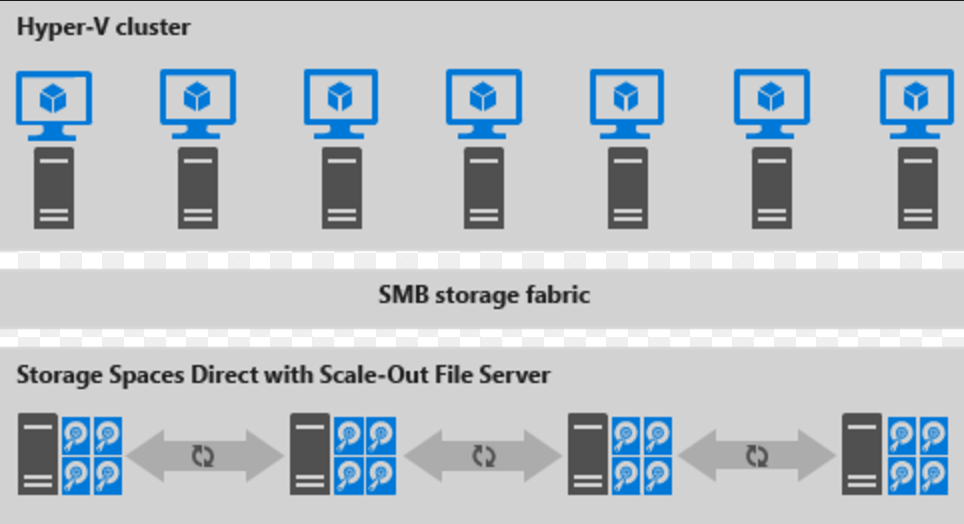
Figura 2: implementação desagregada
- As partilhas de ficheiros são criadas nos CSVs do S2D.
- As VMs hyper-V são configuradas para armazenar os respetivos ficheiros no servidor de ficheiros de escalamento horizontal (SOFS) e acedidas com o SMB 3.0.
- Os clusters Hyper-V e SOFS devem ser escalados separadamente para uma gestão otimizada. Por exemplo, os nós de computação podem estar perto da capacidade total para muitas VMs, mas os nós de armazenamento podem ter capacidade de disco e IOPS em excesso; para adicionar apenas nós de computação adicionais.
Passos seguintes
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários