Falhas e tolerância a falhas
No discurso quotidiano, tendemos a falar sobre os motivos pelos quais os sistemas falham. Uma falha, um "erro", um defeito. Estes termos tendem a ser utilizados de forma intercambiável. No datacenter, os profissionais nunca devem confundir estas palavras ou utilizar uma em vez de outra. Segue-se uma definição precisa dos termos relevantes para o debate sobre tolerância a falhas:
Um erro é uma anomalia na criação de um sistema que faz com que o seu comportamento difira consistentemente dos respetivos requisitos ou expectativas. Poderá ser, de certa forma, a falha do sistema ou do software em corresponder às expectativas, mas um erro não é uma falha do sistema. De facto, muitos erros são o resultado de sistemas a atuar exatamente da forma para a qual foram criados, ao contrário do que se pretendia. A palavra-chave aqui é "consistentemente". O comportamento de um bug pode ser reproduzido em todas as instâncias do sistema. A depuração é o ato de reengenharia do sistema para que os erros sejam eliminados.
Uma falha é uma anomalia num sistema que faz com que se comporte de forma contrária à sua criação ou que deixe de apresentar qualquer comportamento. Aqui, a estrutura do sistema pode não apresentar falhas, mas numa implementação ou instância dessa estrutura, poderá não funcionar corretamente. Uma falha conduz a um comportamento que não se pode esperar que seja reproduzido em qualquer outra instância do sistema. O ato de eliminar uma falha é conhecido como reparação. Uma falha do sistema pode manifestar-se de uma de três formas:
Uma falha permanente é uma interrupção de um sistema cuja causa é irreparável sem a substituição completa do componente responsável
Uma falha transitória é uma interrupção temporária, embora tipicamente não repetida, do sistema cuja causa pode ser reparada ou remediada no local ou que pode, em teoria, resolver-se sem intervenção
Uma falha intermitente é uma interrupção temporária, normalmente repetida, do sistema normalmente causada pela degradação ou estruturação inadequada de um componente e que pode conduzir a uma falha permanente se não for corrigida.
Uma falha é o colapso total de todo ou parte de um sistema, normalmente acionado por uma falha não resolvida. Aqui, a falha é a causa e a falha é o resultado. Um sistema tolerante a falhas (FT) é um sistema que se comporta conforme esperado ou de acordo com as expectativas do contrato de nível de serviço (SLA), em circunstâncias adversas e, como tal, evita falhas em caso de ocorrência de falhas.
Um defeito é uma anomalia no fabrico de um componente de hardware ou nas instâncias de um componente de software, que conduz a uma falha no seu funcionamento e, provavelmente, à falha de um sistema que implementa esse componente. Tal anomalia só poderá ser remediada através de substituição.
Um erro é o resultado de uma operação que produz um resultado indesejado ou incorreto. Num dispositivo de computação, um erro pode ser sintomático de um erro na sua criação ou de uma falha, na sua implementação, e pode ser um indicador efetivo de uma falha iminente.
A manutenção de sistemas tolerantes a falhas requer um especialista em TI, administrador ou operador que compreenda estes conceitos e as diferenças entre os mesmos. Uma plataforma de computação na cloud é, por definição, um sistema tolerante a falhas. É estruturada e criada para antecipar falhas e trabalha para evitar a falha do serviço. De um ponto de vista de engenharia, esta resiliência é a definição do conceito "cloud". Quando os engenheiros telefónicos utilizaram a forma da cloud pela primeira vez nos seus diagramas de sistema, representava os componentes da rede que não tinham de ser vistos ou compreendidos, mas cujos níveis de serviço eram suficientemente fiáveis para não terem de fazer parte do diagrama - podiam ser obscurecidos por uma cloud.
Quando um sistema de informação como uma rede de TI empresarial entra em contacto com uma plataforma de cloud pública, essa plataforma tem uma obrigação de se comportar como um sistema FT. No entanto, não torna e não pode tornar o sistema de comunicação associado mais tolerante a falhas do que já é. A tolerância a falhas não é imunidade nem é uma garantia contra a existência de falhas num sistema. Mais do que isso, um sistema FT não é necessariamente irrepreensível. Em vez disso, a tolerância a falhas, é a capacidade de um sistema de manter os níveis de serviço esperados quando as falhas estão presentes.
O objetivo de qualquer sistema de informação é automatizar as funções que utilizam a informação. A tolerância a falhas só pode, em si mesma, ser automatizada até um certo ponto. A própria Internet, na sua encarnação original como ARPANET, tinha a tolerância a falhas como um dos seus principais objetivos. Na eventualidade de um desastre, as comunicações digitais poderiam ser reencaminhadas para contornar um sistema cujo endereço já não era acessível. No entanto, a Internet não é uma máquina com manutenção autónoma. De facto, nenhum sistema de informação o é.
O esforço humano é sempre necessário para qualquer sistema de informação possa atingir e manter os seus objetivos de serviço. Os melhores sistemas tornam a intervenção humana e remediação simples, imediatas e de acordo com o plano.
Tolerância a falhas em plataformas da cloud
As primeiras plataformas de serviço na cloud eram, digamos de forma generosa, menos tolerantes a falhas do que os seus arquitetos pretendiam. Por exemplo, a capacidade de um cliente sobreaprovisionar recursos para serviços, tais como múltiplas instâncias de bases de dados ou caches de memória duplicadas, revelou ser ineficaz face à monitorização insuficiente, que por vezes levou a cópias de segurança ou réplicas indisponíveis em situações de desastre. Além disso, o sobreaprovisionamento vai contra um dos princípios básicos do modelo de negócios na cloud: pagar apenas pelos recursos de que se precisa. Uma organização não pode poupar em despesas operacionais se estiver a alugar instâncias adicionais de máquinas virtuais, caso a VM principal avarie.
Um sistema FT permite a redundância, mas de uma forma criteriosa e dinâmica, ajustando-se às necessidades e limites de disponibilidade de recursos do momento atual. Na era cliente/servidor, servidores inteiros foram sujeitos a cópia de segurança, incluindo o respetivo armazenamento de dados local e os volumes de armazenamento de rede a que foram anexados, em intervalos periódicos. "Fazer cópia de segurança de tudo" tornou-se em si numa ética empresarial. Uma vez que os serviços de nuvem pública se tornaram acessíveis e práticos, as organizações começaram a usá-los para "fazer backup de tudo". Com o tempo, eles perceberam que a nuvem poderia fazer mais do que perpetuar os métodos antigos. As plataformas na cloud poderiam ter sido criadas inicialmente para a tolerância a falhas, em vez de serem transformadas em tolerantes a falhas uma vez implementadas.
Técnicas reativas
Independentemente da forma ponderada com que um sistema possa ter sido criado, a maioria da sua tolerância a falhas irá depender da forma como o sistema e as pessoas que o gerem respondem perante o primeiro indício de uma falha. Seguem-se algumas das técnicas reativas que as organizações utilizam para mitigar falhas quando as mesmas ocorrem.
Migração de tarefas não preventiva
A técnica da migração de tarefas não preventiva certifica-se de que o anfitrião para uma carga de trabalho, que aparentemente sofreu uma falha, não é reatribuído para alojar a mesma carga de trabalho. Esta vantagem protege a "tarefa", apesar de poder obscurecer o sistema de conseguir recolher instâncias repetidas de um erro como evidência de uma falha, o que poderia ser mais fácil para localizar através de um caminho devidamente registado.
Replicação de tarefas
Muitos sistemas de informação distribuídos executam múltiplas instâncias (ou para a orquestração Kubernetes, réplicas) de uma tarefa simultaneamente. Os sistemas de gestão baseada em políticas podem ser orientados para replicar uma tarefa caso exista uma falha aparente ou suspeita do sistema.
Pontos de verificação e pontos de restauro
Na sua forma mais simples, os pontos de verificação e pontos de restauro envolvem tirar instantâneos de um sistema em vários momentos e permitir aos administradores que "recuem" até a um determinado momento, caso o restauro se torne necessário. Esta estratégia torna-se mais complicada quando estão envolvidas transações. Por exemplo, quando uma aplicação realiza duas ou mais ações numa base de dados que tem de ter êxito ou falhar como unidade (uma "transação"). Um exemplo comum é a aplicação que credita dinheiro de uma conta enquanto debita dinheiro de outra. Estas operações têm de ter êxito ou falhar como unidade, de forma a evitar a criação ou destruição de ativos financeiros.
Num sistema de recuperação de ponto de verificação transacionado, os registos recuperáveis das transações são armazenados numa memória numa árvore de processos. Em determinados pontos durante a transação, os recursos de memória que utiliza são replicados e depositados num conjunto de restauro. Na eventualidade de uma análise de registo indicar uma falha, possivelmente por causa do software, a árvore de processos é bifurcada, o estado da transação volta para um ponto anterior e uma nova transação é experimentada. Se a nova transação produzir melhor resultado do que a defeituosa (por exemplo, se um teste de correção de erros se revelar limpo), então, o antigo ramo de processos é limpo e o novo ramo é seguido a partir desse ponto na árvore, naquilo que os engenheiros chamam uma alternância de contexto.1
Uma versão sofisticada desta metodologia implementa um sistema de rastreio na árvore de processos, para que quando um erro voltar a ocorrer, o sistema possa retroceder no processo e rastrear a causa do erro. Pode então selecionar um ponto de restauro apropriado ou "ponto de resgate", antes de o erro ser acionado.[2]
Outra implementação, denominada SGuard, foi criada por investigadores da Universidade de Washington e da Microsoft Research para o processo tolerante a falhas de grandes fluxos de dados. A SGuard tira partido do Sistema de Ficheiros Distribuído Hadoop (HDFS) para agendar a escrita simultânea de vários instantâneos de fluxos de dados durante o processamento. Estes instantâneos são divididos em porções menores, conforme necessário, subdividindo por sua vez o processamento do fluxo em segmentos menores. Os pontos de verificação são armazenados no HDFS. Este sistema tem a virtude de manter um registo de transações de dados de transmissão em fluxo, bem como múltiplas réplicas viáveis de dados de transmissão em fluxo em locais altamente distribuídos. Embora exista um trabalho de preparação considerável necessário para implementar a SGuard, é ainda assim considerada uma técnica reativa de tolerância a falhas, uma vez que a sua operação principal é acionada em resposta a um evento de falha.3
Técnicas proativas
Uma técnica proativa tolerante a falhas é realizada antes da revelação da existência de qualquer falha. Embora o seu objetivo seja a prevenção, na sua implementação moderna, esta técnica torna-se mais uma metodologia do que um princípio. Seguem-se algumas das técnicas atualmente utilizadas pelas plataformas da cloud modernas.
Replicação de recursos
A chave para uma estratégia eficaz de replicação de recursos pode não ser apenas "fazer backup de tudo". Um analista de sistemas deve ser capaz de determinar quais recursos em um sistema (por exemplo, um mecanismo de banco de dados, servidor Web ou roteador de rede virtual) podem se restaurar após um evento de falha e quais podem ser irrecuperáveis. A replicação inteligente pode ser a primeira linha de defesa num sistema tolerante a falhas.
Existem quatro estratégias comuns para implementar a replicação de recursos e estão todas ilustradas na Figura 1:
Replicação ativa – todos os recursos replicados estão ativos em simultâneo e mantêm o seu próprio estado de forma independente (os seus próprios dados locais que os tornam funcionais). Esta propriedade significa que o pedido de um cliente é recebido por todos os recursos replicados numa classe e que todos os recursos processam uma resposta. No entanto, é a resposta do recurso primário determinado nessa classe que é entregue ao cliente. Se um recurso falhar, incluindo o nó primário, é designado outro nó como o seu sucessor. Este sistema exige que o processamento entre o nó primário e o nó de réplica seja determinista, ou seja, que ocorra em conjunto e com um itinerário definido.
Replicação semiativa – a replicação semiativa é semelhante à replicação ativa. A diferença consiste no facto de os nós de réplica poderem processar pedidos de forma não determinista ou não estando em conjunto com o nó primário. Os resultados dos recursos secundários são suprimidos e registados, estando prontos para ser mudados assim que ocorrer uma falha do recurso primário.
Replicação passiva – apenas o nó do recurso primário processa pedidos, enquanto os outros (as réplicas) mantêm o estado e aguardam para ser designados como nós primários se ocorrer uma falha. O recurso primário com o qual o cliente está em contacto reencaminha qualquer alteração de estado a todas as réplicas. Todos os originais e réplicas que pertencem a uma classe são considerados "membros" de um grupo e um membro pode ser expulso do grupo se parecer ter falhado (mesmo que isso não tenha acontecido). Podem existir latências ou haver degradação da qualidade do serviço (QoS) durante uma falha, embora a replicação passiva consuma menos recursos quando está a funcionar normalmente.
Replicação semipassiva – esta metodologia tem o mesmo padrão de relação da replicação passiva, excetuando o facto de não haver um recurso primário permanente. Em vez disso, a função de coordenador é atribuída a cada um dos recursos e a coordenação dos turnos é determinada por um modelo de transmissão de tokens denominado paradigma de coordenador rotativo.
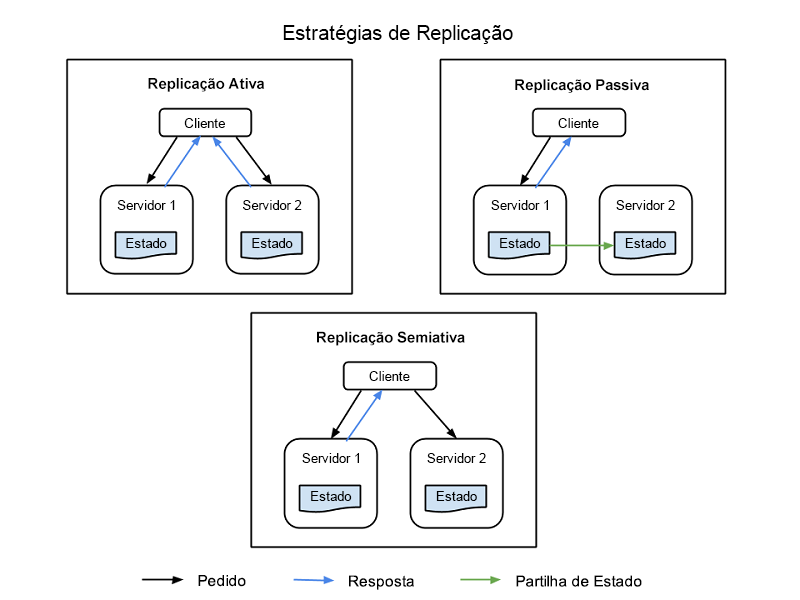
Figura 1: Nós cliente, nós primários e nós de réplica em um sistema de informações replicado.
Balanceamento de carga
Os balanceadores de carga distribuem pedidos de vários clientes entre vários servidores que executam a mesma aplicação, distribuindo a carga de trabalho e reduzindo o esforço dos componentes do sistema. Uma vantagem da utilização de balanceadores de carga é o facto de alguns destes desviarem automaticamente o tráfego de servidores que não respondem, reduzindo a probabilidade de ocorrerem falhas. No caso de produtos derivados mais modernos em que o software foi concebido para ser distribuído com uma plataforma da cloud (por exemplo, microsserviços), as cargas de trabalho são subdivididas em funções separadas que, por sua vez, são distribuídas por processadores do lado do servidor com o objetivo de igualar a distribuição e moderar os níveis de utilização.
A virtualização (o principal componente da computação na cloud) permite que as cargas de trabalho sejam distribuídas mais equitativamente nos processadores ao torná-las portáteis, para que possam ser movidas para o processador físico que pode otimizar a sua utilização. A contentorização melhora esta técnica ao separar as cargas de trabalho virtualizadas dos processadores virtuais, para que estas residam no nó de servidor cujo sistema operativo está melhor preparado para as receber. Este princípio é essencial na orquestração de cargas de trabalho demonstrada por sistemas como o Kubernetes.
Rejuvenescimento e reconfiguração
Nos sistemas de informação em que as instâncias de software são implementadas por grandes períodos, poderá ser necessário reiniciar esse software. Enquanto algumas plataformas da cloud anteriores tentaram efetuar a amostragem dos níveis de serviço de instâncias de software ao longo do tempo para determinar quando o reinício se torna necessário, as plataformas mais recentes recorreram a um método mais simples: o agendamento de reinícios periódicos. Durante estas fases de reinício, os ficheiros de configuração de arranque podem ser automaticamente ajustados para terem alterações das circunstâncias do sistema em conta ou evitarem uma potencial falha após o arranque.
Migração preventiva
Quando a virtualização se tornou fundamental para os datacenters, a migração preventiva foi sugerida como método para igualar o esforço do hardware do servidor ao alternar as atribuições de cargas de trabalho aos processadores, talvez através do método round robin. As plataformas da cloud redistribuem as cargas de trabalho em infraestruturas virtuais com tanta frequência que este método se tornou praticamente desnecessário. No entanto, este tópico surgiu novamente em debates recentes, em conjunto com métodos de inteligência artificial para prever o esforço de cargas de trabalho em diversos sistemas de informação. Tais sistemas podem criar as suas próprias regras para desviar cargas de trabalho mais críticas de nós do servidor com maior probabilidade de falharem.
Autorrecuperação
Num sistema de informação largamente distribuído, como uma rede de entrega de conteúdos (CDN) ou uma rede social, as funções dos servidores individuais podem ser distribuídas por vários endereços, normalmente em diferentes localizações ou datacenters. Uma rede de autorrecuperação consulta as várias ligações regularmente (como uma plataforma de gestão do desempenho) para obter o fluxo do tráfego e a capacidade de resposta. Sempre que há um erro de correspondência do desempenho, os routers podem desviar os pedidos de componentes suspeitos e, potencialmente, parar o fluxo de tráfego nesses componentes. Em seguida, o estado de funcionamento desse componente pode ser testado para verificar sinais de erro. O componente pode ser reiniciado para ver se o comportamento continua e só volta ao estado ativo se o diagnóstico não revelar a probabilidade de falha. Este tipo de capacidade de resposta transacional automatizada é um exemplo moderno da autorrecuperação em datacenters largamente distribuídos.4
Agendamento de processos baseado na troca direta
Uma plataforma da cloud (que inclui serviços públicos com base na cloud, mas também pode incluir infraestruturas no local) é capaz de comunicar o seu próprio estado. Quando a Amazon começou a implementar um modelo de SaaS revisto em 2009, os seus engenheiros criaram um conceito denominado agendamento de instâncias de ponto. Neste sistema, um proxy silencioso que age em nome do cliente anuncia os requisitos de recursos para um determinado trabalho e transmite um tipo de pedido para licitações, especificamente de nós de servidor na plataforma da cloud. Cada nó comunica a sua própria capacidade de satisfazer os requisitos da licitação em termos de tempo e recursos gastos. O licitador com a proposta mais baixa vence o contrato e é-lhe atribuída a instância de ponto (SI) do trabalho. Atualmente, este método de agendamento é uma opção para o Amazon Elastic Compute Cloud.5
Referências
Ioana, Cristescu. A Record-and-Replay Fault Tolerant System for Multithreading Applications. Technical University of Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios, et al.ASSURE: Autorrecuperação automática de software usando pontos de resgate. Universidade de Columbia, 2009.
Kwon Yong-Chul, et al. Processamento de fluxo tolerante a falhas usando um sistema de arquivos distribuído e replicado. Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Ponto de verificação e restauração de micro-serviço em contêineres Docker. Escola de Engenharia de Segurança da Informação, Shanghai Jiao Tong University, China, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Solicitações de instâncias spot Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.