Serviços de recuperação após desastre
- 13 minutos
A recuperação de dados de cópia de segurança é, por motivos óbvios, uma funcionalidade padrão dos serviços de cópia de segurança. No entanto, um desastre não provoca apenas a perda de dados. Uma falha que impede a disponibilidade dos servidores de uma organização (sejam reais ou virtuais/no local ou baseados na cloud) afeta a mesma de forma negativa ou até catastrófica. A finalidade de um serviço de recuperação após desastre (DR) não é fornecer apenas uma cópia de segurança dos dados e dos recursos individuais, mas sim da totalidade do sistema. Deste modo, se o sistema for abaixo ou ficar offline, o serviço pode ser retomado ao redirecionar o tráfego para as réplicas de reserva prontas para assumir a carga.
A verdadeira finalidade da recuperação após desastre reside na cloud pública. É muito mais do que uma enorme unidade de banda. Dado que os recursos da cloud são virtuais, podem ser criadas réplicas de forma quase instantânea para substituir os recursos que desaparecerem. As réplicas até podem ser alojadas em partes diferentes dos sistemas que espelham para contornar falhas ao nível da área. Compare isso com a despesa envolvida na manutenção de réplicas físicas de sistemas de informações físicos (e fazê-lo em várias localizações geográficas) e o valor da cloud na manutenção da continuidade desses sistemas torna-se cada vez mais claro.
Os principais fornecedores de serviços cloud disponibilizam a Recuperação Após Desastre como Serviço (DRaaS), mas este tipo de serviço tem de ser cuidadosamente planeado e configurado, de modo a fornecer o suporte de ativação pós-falha pretendido pelos clientes. É por isso que vamos começar por analisar os objetivos e as métricas que são tidos em consideração nesse planeamento.
Objetivos e métricas
Durante um evento de desastre, uma organização e os respetivos clientes podem perder acesso a várias classes de recursos digitais em simultâneo. As classes mais importantes são:
Bancos de dados e armazenamentos de dados, que além de registrar informações vitais sobre clientes e bens e/ou serviços no estoque, mantêm o estado ativo das transações e processos comerciais para toda a organização
Dados em massa, incluindo documentos, arquivos de mídia e outros registros salvos que são produtos dos aplicativos que as pessoas usam
Comunicações e conectividade com pessoas e serviços empresariais, compreendendo assim a substância de qualquer atividade empresarial que possa ser desenvolvida
Aplicações que representam as vitrines da organização para clientes e patronos, bem como suas próprias partes interessadas
Embora a DR seja apresentada aos clientes como um serviço único, o processo de recuperação é único para cada classe. Na era cliente/servidor, muitas organizações realizavam as respetivas atividades comerciais em computadores pessoais. Teoricamente, se um PC for abaixo e existir uma cópia de segurança da imagem do armazenamento local do PC, o mesmo pode ser recuperado para um novo PC. Com os primeiros PCs com rede ligados por um sistema operativo LAN e um cabo Ethernet, é possível restaurar todos os PCs na rede a partir de uma cópia de segurança da imagem. Em seguida, a rede poderá ser retomada.
A cloud não funciona dessa forma. Mesmo uma máquina virtual que funciona como um servidor para as aplicações de uma organização não encapsula totalmente qualquer parte do trabalho realizado. Os serviços de cópia de segurança fornecem redes de segurança para os dados em massa, bem como para os dados transacionais e para as bases de dados (de forma limitada). No entanto, cada uma destas entidades é o seu próprio componente, pelo que o restauro das funções comerciais durante um desastre requer o restabelecimento da maior parte (ou totalidade) da funcionalidade de cada um dos componentes a partir de uma localização segura.
Assim, o processo de recuperação após desastre requer coordenação entre todos os procedimentos para que uma organização volte a ficar totalmente operacional. Além disso, o tipo de negócio realizado durante este período torna-se crítico devido à existência do próprio desastre. Um evento que afete a infraestrutura essencial pode danificar outros aspetos funcionais da empresa, como o armazenamento, o envio, o fabrico e a entrega. É provável que a empresa restaurada não possa voltar facilmente ao estado anterior ao evento de desastre.
O que compõe estes procedimentos são os objetivos ao nível do serviço que têm em comum e que estão claramente definidos. Os serviços de DR do AWS e do Azure, bem como os serviços de terceiros criados no Google Cloud, reconhecem o seguinte:
Objetivo de ponto de recuperação (RPO) - A quantidade mínima permitida de dados necessária para ser entregue de volta aos clientes para que o serviço baseado nos ativos de backup seja considerado recuperado. Inversamente, esta quantidade pode ser considerada o nível máximo aceitável de perda de dados representada como uma percentagem subtraída de um total de 100.
Recovery Time Objetive (RTO) - A janela máxima de tempo permitida para que um processo de restauração ocorra, que também pode ser considerada uma medida de quanto tempo de inatividade a organização está disposta a pagar.
Período de retenção - O período máximo de tempo permitido para que um conjunto de backup seja retido antes de precisar ser atualizado e substituído.
O RTO e o RPO são opostos que se complementam e permitem aos clientes decidir se pretendem tempos de recuperação mais longos para alcançarem pontos de recuperação mais elevados. Se o tempo de recuperação for um problema para um cliente devido à largura de banda disponível ou ao risco de ocorrência de um período de indisponibilidade, esse mesmo cliente poderá não conseguir alcançar um RPO elevado.
É provável que um consultor de riscos profissional ou de continuidade comercial insista na utilização destas três variáveis para a formulação de uma política de recuperação após desastre. O RTO e o RPO são fundamentais para a maioria dos relatórios de análise de impacto comercial (BIA). São variáveis essenciais nas avaliações dos consultores sobre as potenciais perdas causadas por eventos de desastre. Alguns consultores usam uma variável agregada chamada objetivo de nível de serviço (SLO), embora uma única fórmula para atingir o SLO ainda não tenha surgido. Os CSPs podem especificar os respetivos níveis de serviço através de terminologia que os consultores de risco já conhecem, o que facilita o trabalho em conjunto. É assim que, muitas vezes, as organizações acabam por escolher os fornecedores de DR.
Metodologias e procedimentos
A unidade anterior abordou a forma mais básica de recuperação das informações do sistema, que envolve cópias de segurança de ficheiros relevantes, volumes de armazenamento e imagens de máquinas virtuais. Esta opção continua a ser apresentada como uma opção de serviço de DR. Contudo, na prática, aplica-se a cada vez menos organizações, especialmente porque os RTOs não podem ser mantidos de forma adequada.
Os serviços profissionais de DR oferecem várias metodologias de implementação e gestão, algumas das quais envolvem a manutenção do serviço antes de um evento de desastre. Estas metodologias encontram-se resumidas abaixo. As três metodologias baseiam-se em várias opções de cópia de segurança abordadas na unidade anterior e são igualmente aplicáveis a todos os fornecedores de serviços. Um cliente que pretenda ativar um dos modos de recuperação deve escolher as classes de replicação, geolocalização e armazenamento mais adequadas ao modo em questão.
Luz Piloto
Com esta metodologia (Figura 5), existe espaço para um datacenter completo de reserva. Certos serviços e aplicações principais, bem como os dados que os suportam, são mantidos num cluster de ativação pós-falha que pode ser "ligado" quando um evento de desastre é acionado (muitas vezes automaticamente). Entretanto, os servidores virtuais são implementados apenas com as funcionalidades básicas necessárias para se manterem ativos caso sejam necessários. Estes servidores limitados podem ter funcionalidades de e-mail e Web, o que permite a comunicação dentro da organização e com os clientes. A ativação do modo de recuperação Luz Piloto pode implicar a sincronização de arquivos de dados voláteis, como volumes de e-mails e bases de dados transacionais.
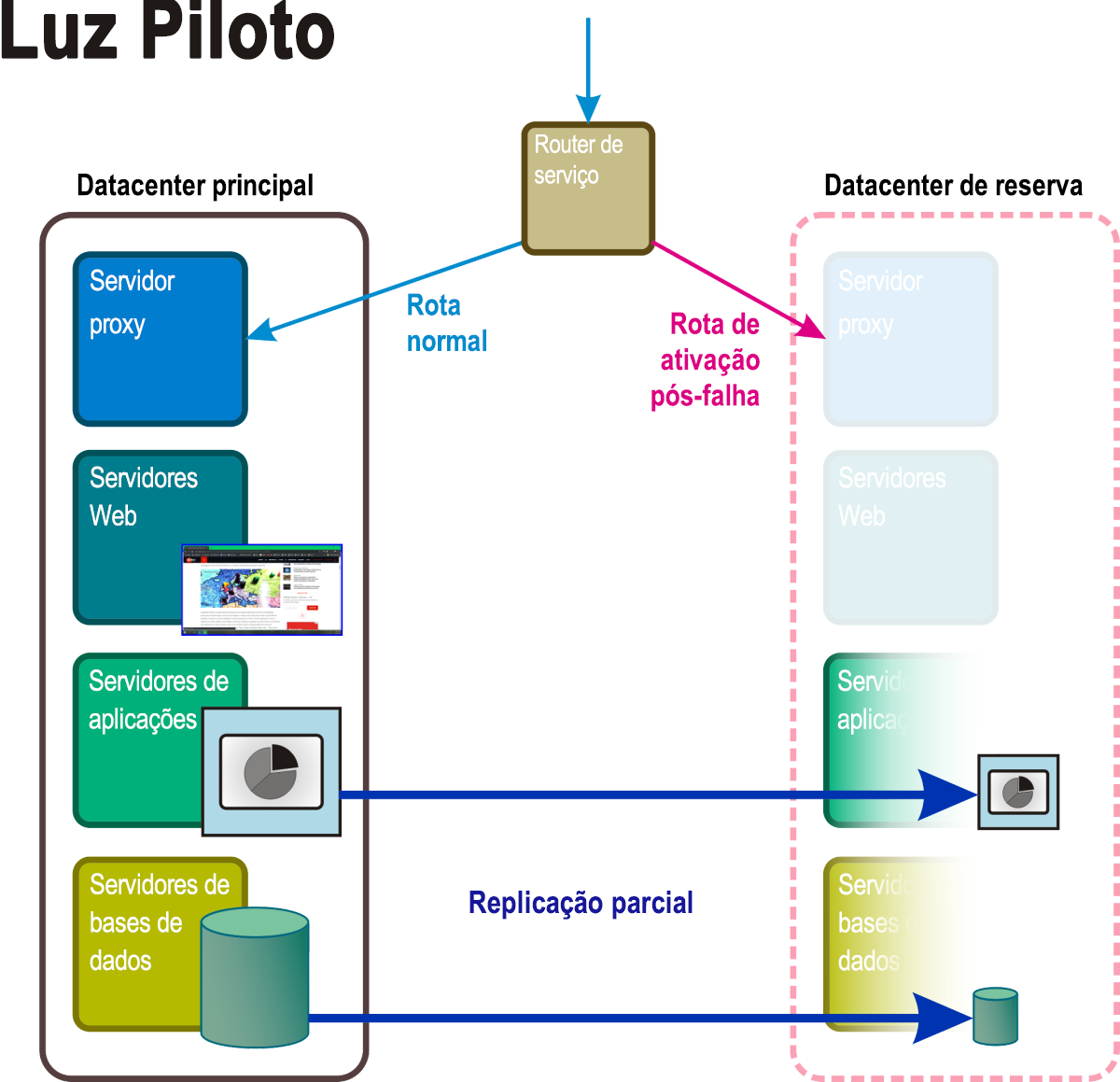
Figura 5: Os componentes ativos e passivos de um cenário de recuperação de luz piloto.
Reserva semiativa
Neste modo de recuperação, apresentado na Figura 6, as réplicas em execução contínua de todos os serviços e aplicações do sistema, assim como todos os dados empresariais críticos, são mantidos em pelo menos uma geolocalização separada. O acesso a esta réplica completa é ignorado pelo router ativo até que o evento de desastre acione uma regra que substitui o endereço da rede ativa por aquele na rota ignorada.
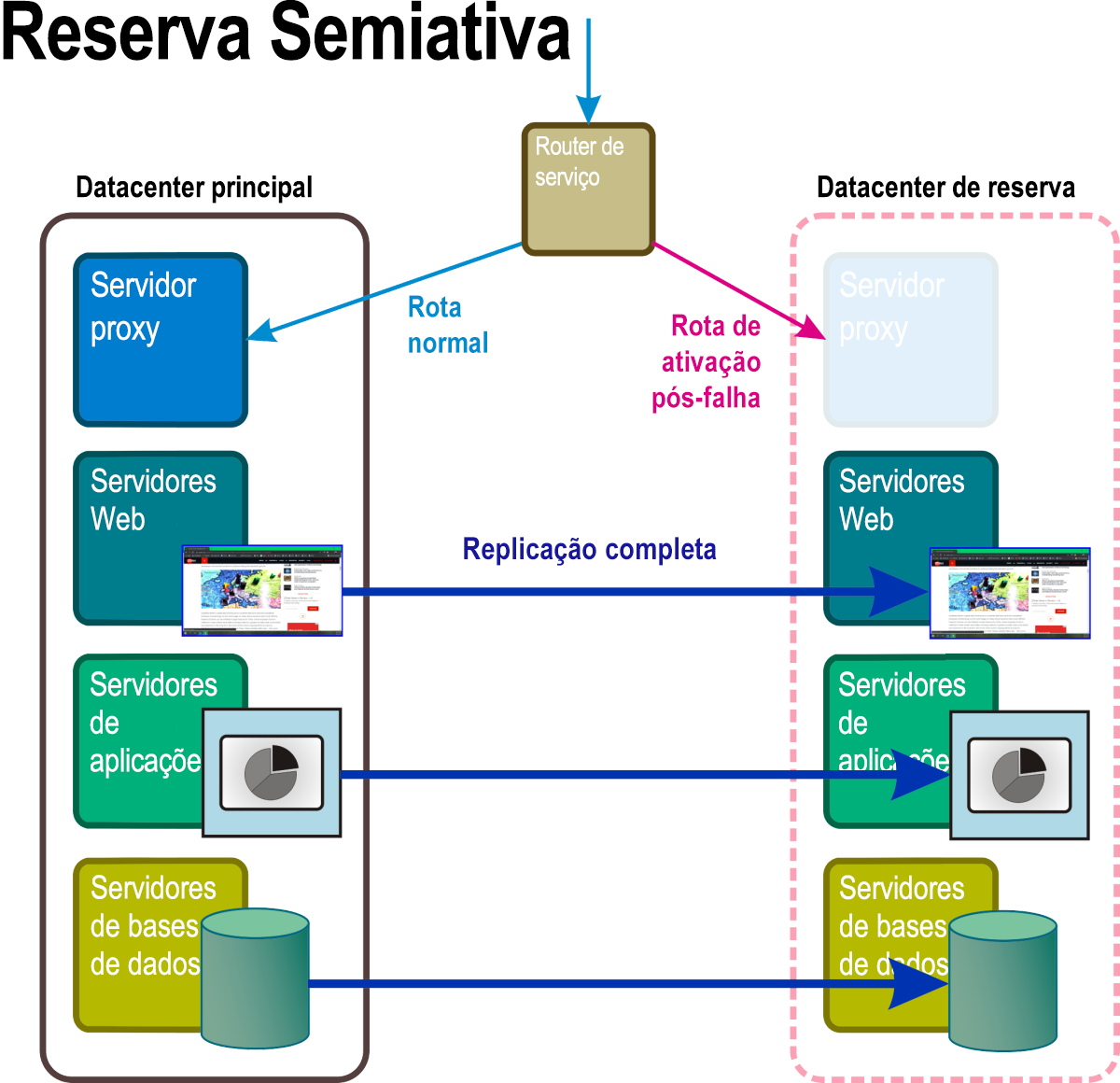
Figura 6: Um cenário de recuperação em espera ativa com alguns componentes no namespace em espera totalmente operacionais.
Reserva ativa
Neste cenário (Figura 7), pelo menos duas réplicas completas de todos os serviços e aplicações estão sempre em execução, com sincronização de dados completa e contínua entre as mesmas. O router principal serve como um tipo de balanceador de carga, que distribui pedidos para todas as localizações de servidores numa proporção aproximadamente igual. A ocorrência de um evento de desastre aciona um processo semelhante a uma firewall onde o endereço do sistema afetado é removido da tabela de encaminhamento.
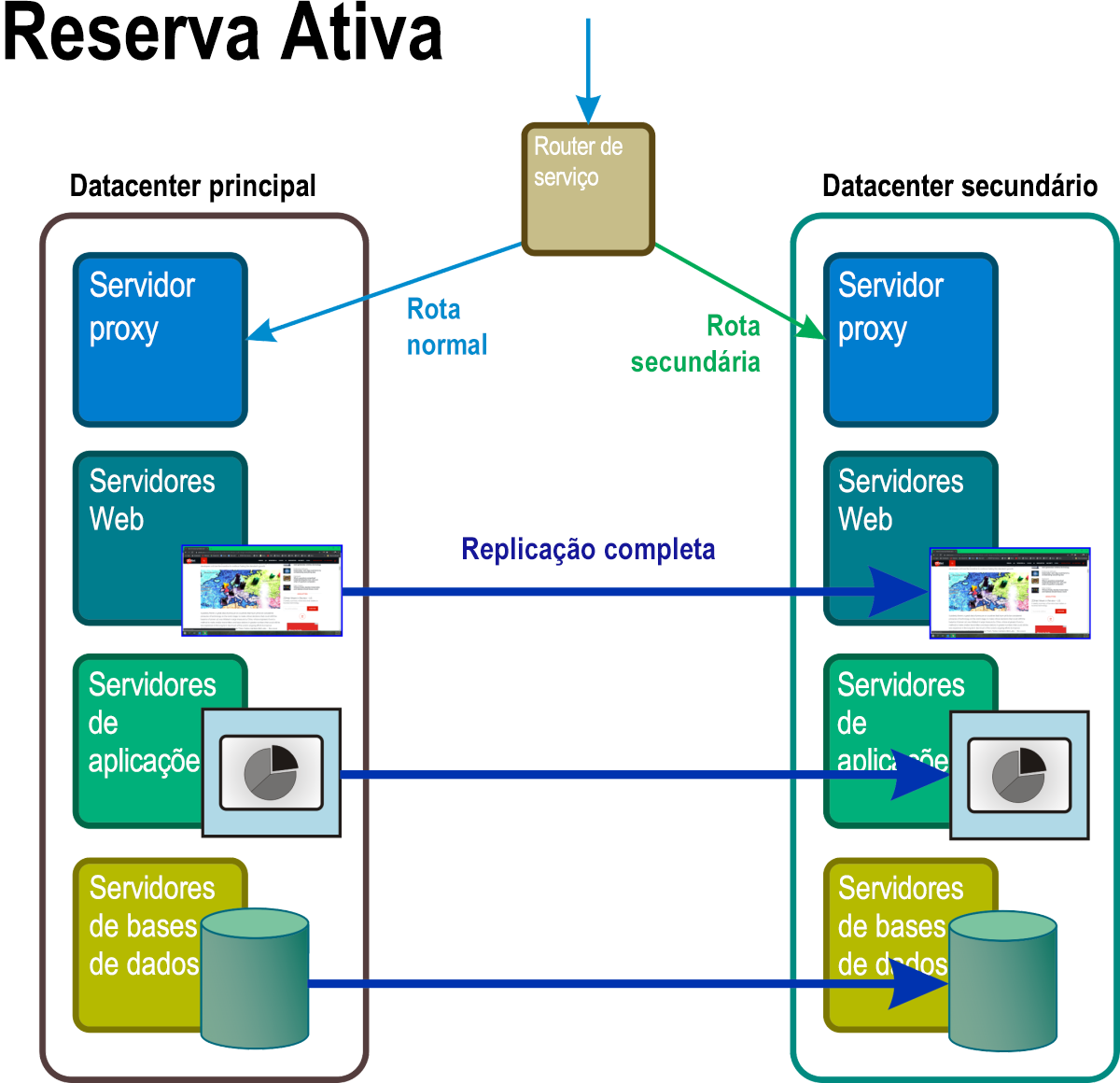
Figura 7: Com o Hot standby, todos os componentes no namespace do que normalmente seria a reserva, o espaço em espera, estão ativos, totalmente operacionais e processando réplicas dos dados primários em tempo real.
Aplicações nativas na cloud
É teoricamente possível que uma organização escolha o serviço de recuperação após desastre de um fornecedor como uma rede de segurança para serviços alojados por outro fornecedor. Por outras palavras, dado o nível adequado de atenção por parte da equipa de TI, a infraestrutura de um CSP (por exemplo, da Google) pode servir como um destino de ativação pós-falha para um procedimento de reserva semiativa alojado na infraestrutura de outro CSP (por exemplo, do Azure). Este tipo de configuração pode ser necessário para gestão de contas ou se os recursos informáticos numa empresa estiverem a ser geridos por departamentos separados em diferentes partes do mundo.
Por agora, a presença da infraestrutura em contentores no datacenter no local, bem como na cloud, pode ter um impacto significativo em todas as metodologias de DR. Um chamado aplicativo nativo da nuvem, desenvolvido exclusivamente para uso em uma plataforma de nuvem pública, ou uma plataforma que funciona exatamente como ela (por exemplo, Microsoft Azure Stack), distribui funções em vários contêineres de réplica, alguns ou todos os quais podem ser funcionais simultaneamente. Não é tanto para permitir uma nova classe do cenário de DR, mas para distribuir cargas de trabalho entre processadores.
Outro aspeto das arquiteturas nativas na cloud é a capacidade das bases de dados cujos conteúdos já são replicados automaticamente serem contactadas através de um endereço de rede cujo mapa é exclusivo da aplicação em questão. (Em outras palavras, embora use o Protocolo Internet, seu endereço não é um local na Internet pública mais ampla.) Dessa forma, durante um evento de desastre, enquanto alguns nós anexados ao banco de dados podem cair, muitos persistirão e outros substituirão os nós indisponíveis. Pode não se qualificar como uma recuperação após desastre integrada, embora possa ser descrito como uma resistência a catástrofes.
Recuperação após Desastre como Serviço (DRaaS)
Para um fornecedor de serviços cloud pública, a recuperação após desastre é uma forma de utilizar os principais serviços de cópia de segurança e transferência de dados. Cada um dos principais CSPs implementa uma estratégia diferente para facilitar a DR nos serviços de cópia de segurança.
AWS CloudEndure
A migração de serviços refere-se à realocação de cargas de trabalho virtuais da infraestrutura privada local para a infraestrutura de nuvem pública. Esta recolocação é necessária para alguns serviços de recuperação após desastre que operam na cloud pública, para alcançar os objetivos de ativação pós-falha e recuperação dentro de alguns minutos após um evento de desastre.
Em janeiro de 2019, a Amazon comprou o serviço privado de migração de serviços CloudEndure, que já utilizava o AWS como o fornecedor de infraestrutura. Desde então, integrou o CloudEndure na sua linha de serviço principal e oferece migração de serviços para clientes da Amazon sem custos. Agora, o AWS implementa a migração de serviços como uma forma de permitir rapidamente um processo de reserva semiativa ou ativa. O AWS não cobra os clientes pelo processo de migração, mas cobra pelos recursos redundantes aprovisionados para cada cenário de DR. Ainda assim, o facto de não cobrar uma taxa extra torna o CloudEndure instantaneamente competitivo em relação a uma infinidade de serviços de DR de terceiros.
Recuperação de Sites do Azure
O serviço de DR da Microsoft, o Azure Site Recovery, é uma implementação gerida de um método de recuperação de reserva semiativa para ambientes baseados em VM e para servidores físicos (no local) a executar o Linux ou Windows. As VMs são replicadas ativamente para uma região secundária (Figura 9.8), onde pode ser iniciada uma ativação pós-falha ao clicar num botão. Os clientes recebem uma taxa mensal (atualmente cerca de US$ 25) por cada servidor ou VM protegido pelo Azure Site Recovery.
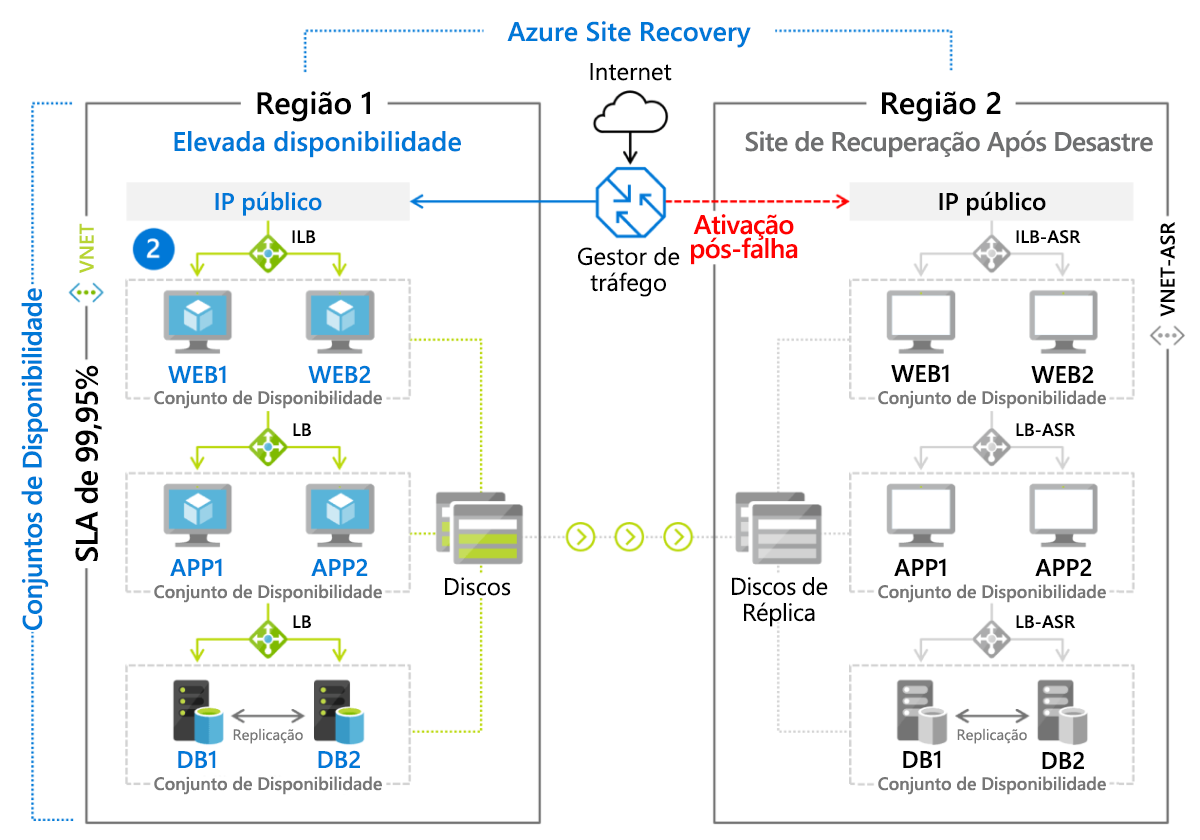
Figura 8: Cenário de failover implementado usando o Azure Site Recovery.
DR do Google Cloud
Como é o caso com a cópia de segurança, a Google não oferece um serviço de marca especificamente para a recuperação após desastre. Em vez disso, disponibiliza as ferramentas e recursos necessários para o armazenamento e transferência de dados, e oferece orientação aos clientes sobre a melhor forma de os utilizar em vários cenários de DR.
Como a Google oferece opções de armazenamento Coldline e aplica um desconto, o GCP é aplicável a uma grande variedade de cenários. O Coldline é uma opção apelativa para organizações que mantêm uma grande quantidade de dados em massa. Os discos magnéticos giratórios tornam-se recipientes pouco práticos para ficheiros de multimédia cujos tamanhos médios atingem as dezenas de gigabytes. Os componentes do Armazenamento Ligado à Rede (NAS) fornecem uma solução de acessibilidade e gestão para organizações que criam conteúdos multimédia, mas apenas a nível local. Têm uma redundância interna, mas não são resistentes a desastres. Um cenário de DR, como qualquer um dos três apresentados anteriormente, não seria prático (ou até mesmo acessível) para esta classe de clientes. O Coldline apresenta pelo menos uma forma viável para este cliente atingir um nível nominal de garantia de continuidade do negócio.