Compreender os componentes do Azure Data Factory
Uma assinatura do Azure pode ter uma ou mais instâncias do Azure Data Factory. O Azure Data Factory é composto por quatro componentes principais. Estes componentes funcionam em conjunto para fornecer a plataforma na qual pode compor fluxos de trabalho orientados por dados com passos para mover e transformar dados.
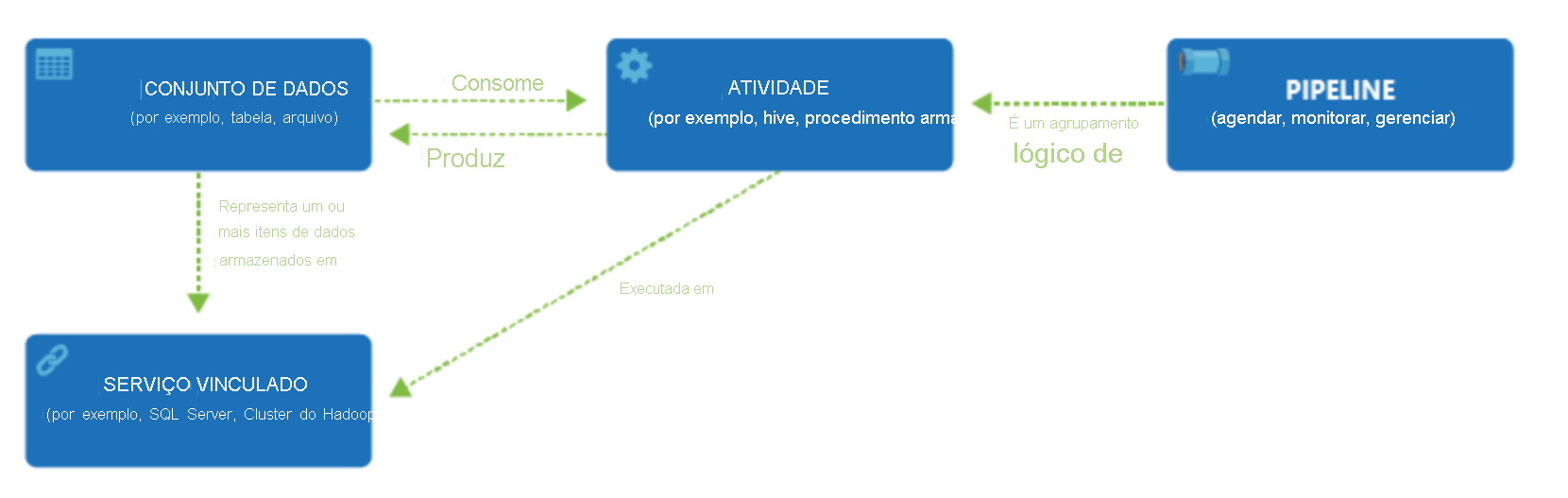
O Data Factory oferece suporte a uma ampla variedade de fontes de dados às quais você pode se conectar por meio da criação de um objeto conhecido como Serviço Vinculado, que permite ingerir os dados de uma fonte de dados em preparação para preparar os dados para transformação e/ou análise. Além disso, os Serviços Vinculados podem acionar serviços de computação sob demanda. Por exemplo, você pode ter um requisito para iniciar um cluster HDInsight sob demanda com a finalidade de apenas processar dados por meio de uma consulta do Hive. Portanto, os Serviços Vinculados permitem definir fontes de dados ou recursos de computação necessários para ingerir e preparar dados.
Com o serviço vinculado definido, o Azure Data Factory fica ciente dos conjuntos de dados que deve usar por meio da criação de um objeto Datasets . Os conjuntos de dados representam estruturas de dados dentro do armazenamento de dados que está sendo referenciado pelo objeto Serviço Vinculado. Os conjuntos de dados também podem ser usados por um objeto ADF conhecido como Activity.
As atividades normalmente contêm a lógica de transformação ou os comandos de análise do trabalho do Azure Data Factory. As atividades incluem a atividade de cópia que pode ser usada para ingerir dados de uma variedade de fontes de dados. Ele também pode incluir o fluxo de dados de mapeamento para executar transformações de dados sem código. Ele também pode incluir a execução de um procedimento armazenado, Hive Query ou script Pig para transformar os dados. Você pode enviar dados por push para um modelo de Aprendizado de Máquina para executar análises. Não é incomum que ocorram várias atividades que podem incluir a transformação de dados usando um procedimento armazenado SQL e, em seguida, executar análises com o Databricks. Nesse caso, várias atividades podem ser agrupadas logicamente com um objeto chamado de Pipeline, e elas podem ser agendadas para execução, ou um gatilho pode ser definido que determina quando uma execução de pipeline precisa ser iniciada. Existem diferentes tipos de acionadores para diferentes tipos de eventos.
O fluxo de controle é uma orquestração de atividades de pipeline que inclui atividades de encadeamento em uma sequência, ramificação, definição de parâmetros no nível de pipeline e passagem de argumentos ao invocar o pipeline sob demanda ou a partir de um gatilho. Ele também inclui contêineres de passagem e looping de estado personalizado e iteradores para cada um.
Os parâmetros são pares chave-valor de configuração somente leitura. Os parâmetros são definidos no pipeline. Os argumentos para os parâmetros definidos são transmitidos durante a execução a partir do contexto da instância criado por um acionador ou por um pipeline executado manualmente. As atividades dentro do pipeline consomem os valores dos parâmetros.
O Azure Data Factory tem um tempo de execução de integração que permite fazer a ponte entre a atividade e os objetos de Serviços vinculados. São referenciados pelo serviço ligado e fornecem o ambiente de computação em que a atividade é executada ou a partir do qual é distribuída. Desta forma, a atividade pode ser realizada na região mais próxima possível. Há três tipos de Tempo de Execução de Integração, incluindo Azure, Auto-hospedado e Azure-SSIS.
Quando todo o trabalho estiver concluído, você poderá usar o Data Factory para publicar o conjunto de dados final em outro serviço vinculado que poderá ser consumido por tecnologias como Power BI ou Machine Learning.