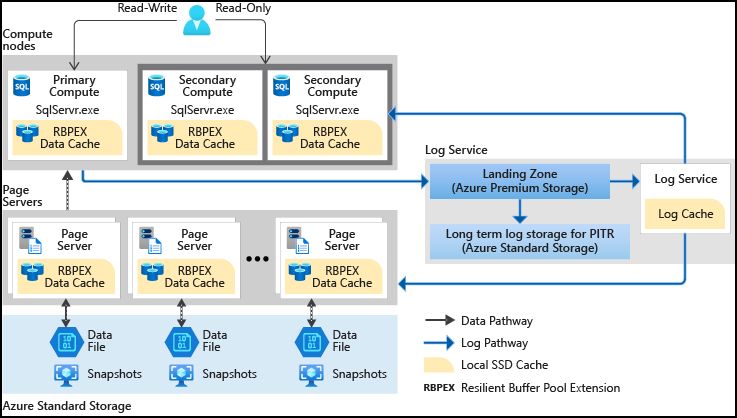
Compreender a hiperescala do banco de dados SQL
O Banco de Dados SQL do Azure era historicamente limitado a 4 TB de armazenamento por banco de dados devido a restrições de infraestrutura física. No entanto, a camada de serviço Hyperscale revoluciona isso, permitindo que os bancos de dados excedam 100 TB. O Hyperscale usa técnicas de dimensionamento horizontal para adicionar nós de computação à medida que os tamanhos dos dados aumentam. Embora o custo do Hyperscale seja semelhante ao Banco de Dados SQL do Azure, há um custo extra de armazenamento por terabyte. É importante observar que, depois que um banco de dados é convertido em Hyperscale, ele não pode ser revertido para um Banco de Dados SQL padrão do Azure.
O Hyperscale é ideal para a maioria das cargas de trabalho de negócios, oferecendo flexibilidade e alto desempenho com recursos de computação e armazenamento escaláveis de forma independente. Ele separa o mecanismo de processamento de consultas dos componentes, fornecendo armazenamento de longo prazo e durabilidade, permitindo que a capacidade de armazenamento seja dimensionada suavemente conforme necessário.
A camada de serviço Hyperscale, parte do modelo de compra baseado em vCore, é a opção mais recente e escalável, excedendo significativamente os limites das camadas de Uso Geral e Crítica de Negócios.
Benefícios
A camada de serviço Hyperscale elimina muitas das limitações práticas tradicionalmente associadas aos bancos de dados em nuvem. Os recursos de um único nó restringem a maioria dos bancos de dados, mas os bancos de dados Hyperscale não têm essas restrições. Com sua arquitetura de armazenamento flexível, o armazenamento se expande conforme necessário e não há tamanho máximo predefinido. Você é cobrado apenas pela capacidade usada. Para cargas de trabalho de leitura intensiva, o Hyperscale oferece expansão rápida provisionando mais réplicas para lidar com operações de leitura.
Além disso, o tempo necessário para backups de banco de dados ou operações de dimensionamento não depende mais do volume de dados. É possível fazer backup instantâneo de bancos de dados de hiperescala e você pode dimensionar um banco de dados com dezenas de terabytes para cima ou para baixo em minutos. Essa flexibilidade garante que suas opções de configuração iniciais não o constrangam. Além disso, o Hyperscale fornece restaurações rápidas de banco de dados, concluídas em minutos, em vez de horas ou dias.
O Hyperscale fornece escalabilidade rápida com base na sua demanda de carga de trabalho.
Escalando para cima/para baixo – Você pode aumentar ou diminuir os recursos de computação primários, como CPU e memória, de forma rápida e eficiente. Como o armazenamento é compartilhado, essas operações de dimensionamento não dependem do volume de dados do banco de dados.
Escalando para dentro/para fora – Você pode criar mais réplicas de computação para lidar com solicitações de leitura, descarregando efetivamente a carga de trabalho de leitura da computação primária. Essas réplicas também servem como hot standby, prontas para assumir o controle se houver uma falha de computação primária.
O provisionamento de mais réplicas de computação é uma operação rápida e on-line. Para se conectar a essas réplicas somente leitura, defina o argumento ApplicationIntent em sua cadeia de conexão como ReadOnly. As conexões com a intenção do aplicativo ReadOnly são roteadas automaticamente para uma das réplicas de computação somente leitura.
Considerações de segurança
A segurança para a camada de serviço Hyperscale oferece os mesmos recursos robustos que outras camadas do Banco de Dados SQL do Azure. Ele emprega uma abordagem de defesa em camadas profunda, fornecendo proteção abrangente das camadas mais externas para dentro.

A Segurança de Rede é a primeira camada de defesa, utilizando regras de firewall IP para controlar o acesso com base no endereço IP de origem. Além disso, as regras de firewall da Rede Virtual permitem a comunicação de sub-redes selecionadas dentro de uma rede virtual.
O Gerenciamento de Acesso é fornecido por meio dos seguintes métodos de autenticação para verificar a identidade do usuário:
- Autenticação SQL
- Autenticação do Microsoft Entra
- Autenticação do Windows para principais do Microsoft Entra
O Azure SQL Database Hyperscale também dá suporte à SegurançaRow-Level (RLS), permitindo que os clientes controlem o acesso a linhas específicas em uma tabela de banco de dados com base nas características do usuário, como associação a grupo ou contexto de execução.
A Proteção contra Ameaças inclui recursos robustos de auditoria e deteção de ameaças. A auditoria do Banco de Dados SQL e da Instância Gerenciada SQL rastreia as atividades do banco de dados e ajuda a manter a conformidade com os padrões de segurança registrando eventos em um log de auditoria em uma conta de armazenamento do Azure de propriedade do cliente. A Proteção Avançada contra Ameaças analisa os seus registos para detetar comportamentos incomuns e potenciais ameaças às suas bases de dados. Ele gera alertas para atividades suspeitas, como injeção de SQL, potencial infiltração de dados, ataques de força bruta e anomalias nos padrões de acesso que podem indicar escalonamentos de privilégios ou o uso de credenciais violadas.
A Proteção de Informações é fornecida das seguintes maneiras:
- Transport Layer Security (Encriptação em trânsito)
- Criptografia de dados transparente (criptografia em repouso)
- Gerenciamento de chaves com o Azure Key Vault
- Sempre criptografado (criptografia em uso)
- Máscara de dados dinâmica
Considerações de desempenho
A camada de serviço Hyperscale foi projetada para clientes com grandes bancos de dados SQL Server locais que desejam se modernizar migrando para a nuvem e para aqueles que já usam o Banco de Dados SQL do Azure que precisam expandir significativamente sua capacidade de banco de dados. Também é ideal para clientes que buscam alto desempenho e escalabilidade.
Os principais recursos de desempenho do Hyperscale incluem:
- Backups de banco de dados quase instantâneos usando instantâneos de arquivo armazenados no Azure Blob storage, sem afetar recurso de computação.
- Restaurações rápidas de banco de dados com base em instantâneos de arquivos, concluídas em minutos, em vez de horas ou dias, independentemente do tamanho dos dados.
- Desempenho geral aprimorado devido à maior taxa de transferência do log de transações e tempos de confirmação de transações mais rápidos, independentemente dos volumes de dados.
- Escalabilidade horizontal rápida, ao provisionar uma ou mais réplicas em modo somente leitura para aliviar as cargas de leitura e servir como standby quente.
- Escalonamento rápido, permitindo aumentar rapidamente os recursos de computação para lidar com cargas de trabalho pesadas e reduzi-las quando não forem necessárias.
Implantando o Hiperdimensionamento do Banco de Dados SQL do Azure
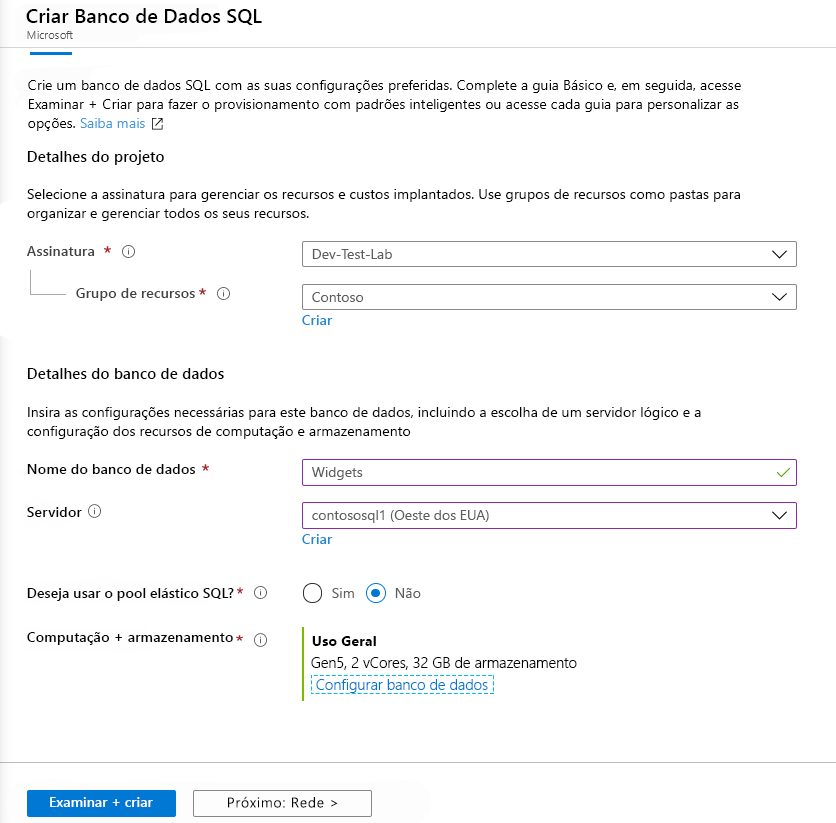
Para implantar um Banco de Dados SQL do Azure com a camada Hyperscale, siga o mesmo processo de implantação de um banco de dados SQL regular, com as seguintes diferenças:
Em Computação + armazenamento, selecione o link Configurar banco de dados .
Em Camada de serviço, selecione Hiperescala.
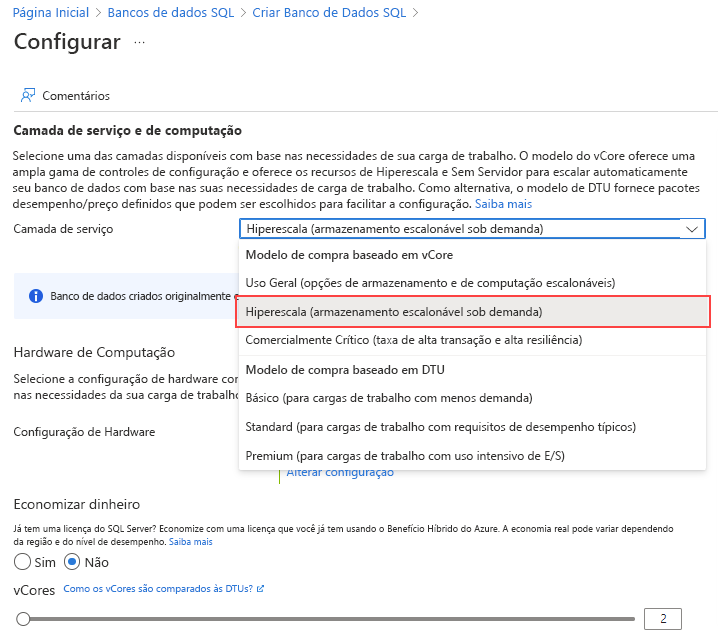
Revise as configurações de hardware disponíveis e selecione a configuração mais apropriada para seu banco de dados.
Opcionalmente, se necessário, revise as outras guias para fazer ajustes.
No separador Rever + criar , selecione Criar.

