Projetar padrões de ingestão para um armazém de dados moderno
A ingestão de dados pode ocorrer de várias maneiras diferentes. O principal componente do Azure Synapse Analytics para ingerir dados é usar a atividade Copiar Dados nos Pipelines do Azure Synapse. Esse tipo de atividade é normalmente realizada dentro de uma atividade de Pipeline de Execução com outros recursos, como uma operação de pesquisa ou uma atividade de dados divididos.
Como alternativa, você pode criar uma conexão dentro de um Fluxo de Dados que aponte para um banco de dados de origem usado como ponto de partida para a ingestão de dados e o uso dos dados em atividades de transformação adicionais.
Segue-se um exemplo de ambos.
Ingestão de dados
Selecione o hub Integrar .
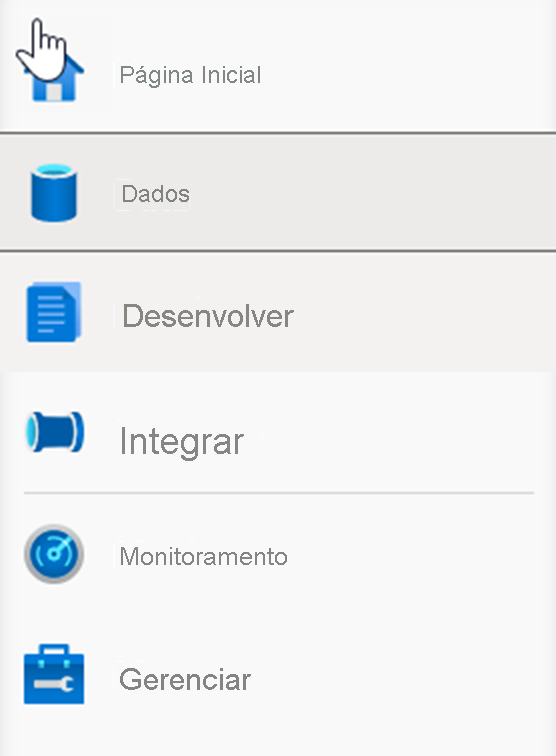
Expanda Pipelines e selecione 1 Master Pipeline (1). Aponte as Atividades (2) que podem ser adicionadas ao pipeline e mostre a tela do pipeline (3) à direita.
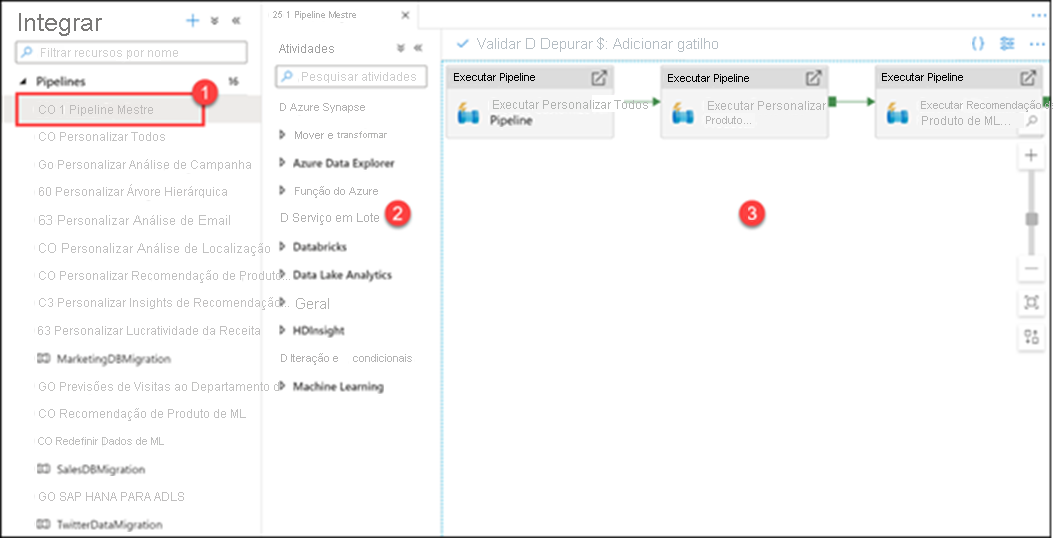
Nosso espaço de trabalho Synapse contém 16 pipelines que nos permitem orquestrar etapas de movimentação e transformação de dados sobre dados de várias fontes.
A lista Atividades contém um grande número de atividades que você pode arrastar e soltar na tela do pipeline à direita.
Aqui vemos que temos três pipelines de execução (filho):
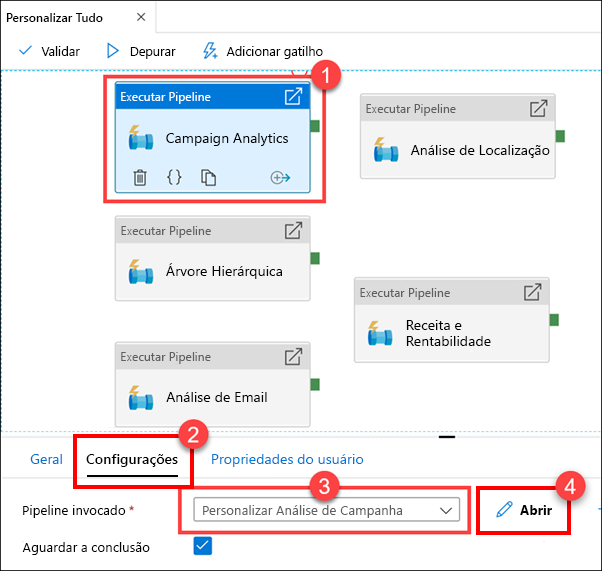
Selecione a atividade Executar personalizar todo o pipeline (1). Selecione a guia Configurações (2). Mostrar que o pipeline invocado é Personalizar tudo (3) e, em seguida, selecione Abrir (4).
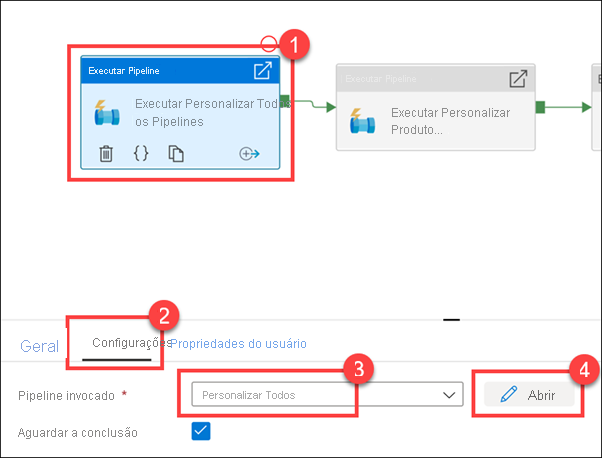
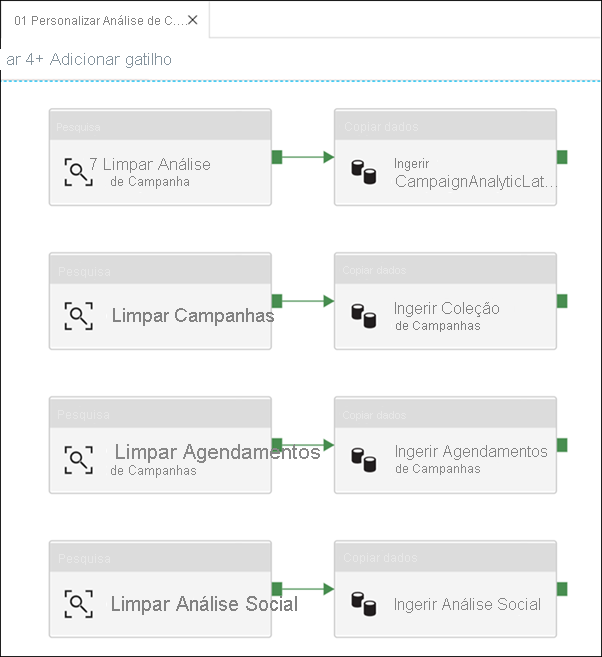
Como você pode ver, existem cinco pipelines filho. Esta primeira atividade de pipeline de execução limpa e ingere novos dados de campanha do fabricante para o relatório do Campaign Analytics.
Selecione a atividade do Campaign Analytics (1), selecione a guia Configurações (2), observe que o pipeline invocado está definido como Personalizar tudo (3) e selecione Abrir (4).
Observe como a limpeza e a ingestão acontecem na tubulação clicando em cada atividade.
Selecione o hub Revelar .
Expanda Fluxos de dados e, em seguida, selecione o ingest_data_from_sap_hana_to_azure_synapse fluxo de dados.
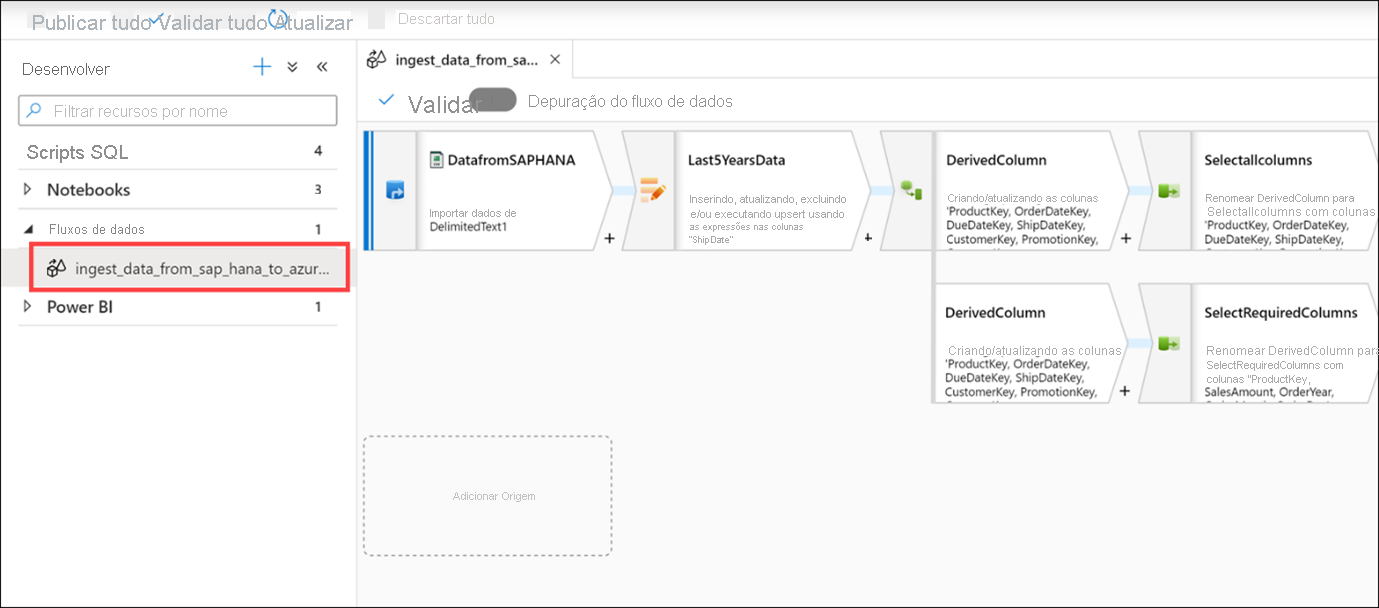
Como dito anteriormente, os fluxos de dados são fluxos de trabalho poderosos de transformação de dados que usam o poder do Apache Spark, mas são criados usando uma GUI livre de código. O trabalho que você faz na interface do usuário é transformado em código executado por um cluster Spark gerenciado, automaticamente, sem precisar escrever nenhum código ou gerenciar o cluster.
O fluxo de dados executa as seguintes funções:
- Extrai dados da fonte de dados do SAP HANA (etapa Select DatafromSAPHANA).
- Recupera apenas as linhas para uma atividade de upsert, onde o valor ShipDate é maior que 2014-01-01 (selecione a etapa Last5YearsData).
- Executa transformações de tipo de dados nas colunas de origem, usando uma atividade Coluna derivada (Selecione a atividade DerivedColumn superior).
- No caminho superior do fluxo de dados, selecionamos todas as colunas e, em seguida, carregamos os dados na tabela de pool AggregatedSales_SAPHANANew Synapse (Selecione a atividade Selectallcolumns e a atividade LoadtoAzureSynapse).
- No caminho inferior do fluxo de dados, selecionamos um subconjunto das colunas (Selecione a atividade SelectRequiredColumns).
- Em seguida, agrupamos por quatro colunas (Selecione a atividade TotalSalesByYearMonthDay) e criamos agregados de soma e média na coluna SalesAmount (Selecione a opção Agregados).
- Finalmente, os dados agregados são carregados na tabela de pool AggregatedSales_SAPHANA Synapse (Selecione a atividade LoadtoSynapse).